
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 미니 프로젝트 실습의 목적은 이전 미니 프로젝트들과 결이 달랐습니다. 이전 미니 프로젝들을 정리한 것을 보면 대부분 알고리즘을 사용한 모델링을 활용하여 예측 결과 및 분석을 했었습니다. 하지만 이번 미니 프로젝트에서는 모델링이 목적이 아닌 인사이트 제공을 목적으로 하고 있습니다.
이러한 차이로 Feature Engineering에서 Modeling 까지의 과정이 달랐습니다. 가장 큰 차이점은 Feature Engineering에서 알고리즘에 사용하기 위해 Feature들을 가공하는 것이 아니라, 어떤 지표를 사용할지 정하는 과정을 거쳤습니다. 이 부분은 데이터 분석가 Job Description 부분에 "KPI를 개발 및 모니터링하는 업무" 부분과 상당히 유사했습니다.
그렇다면 해당 미니 프로젝트가 어떻게 진행되었는지 진행과정부터 이야기해보겠습니다.
02. 프로젝트 진행과정
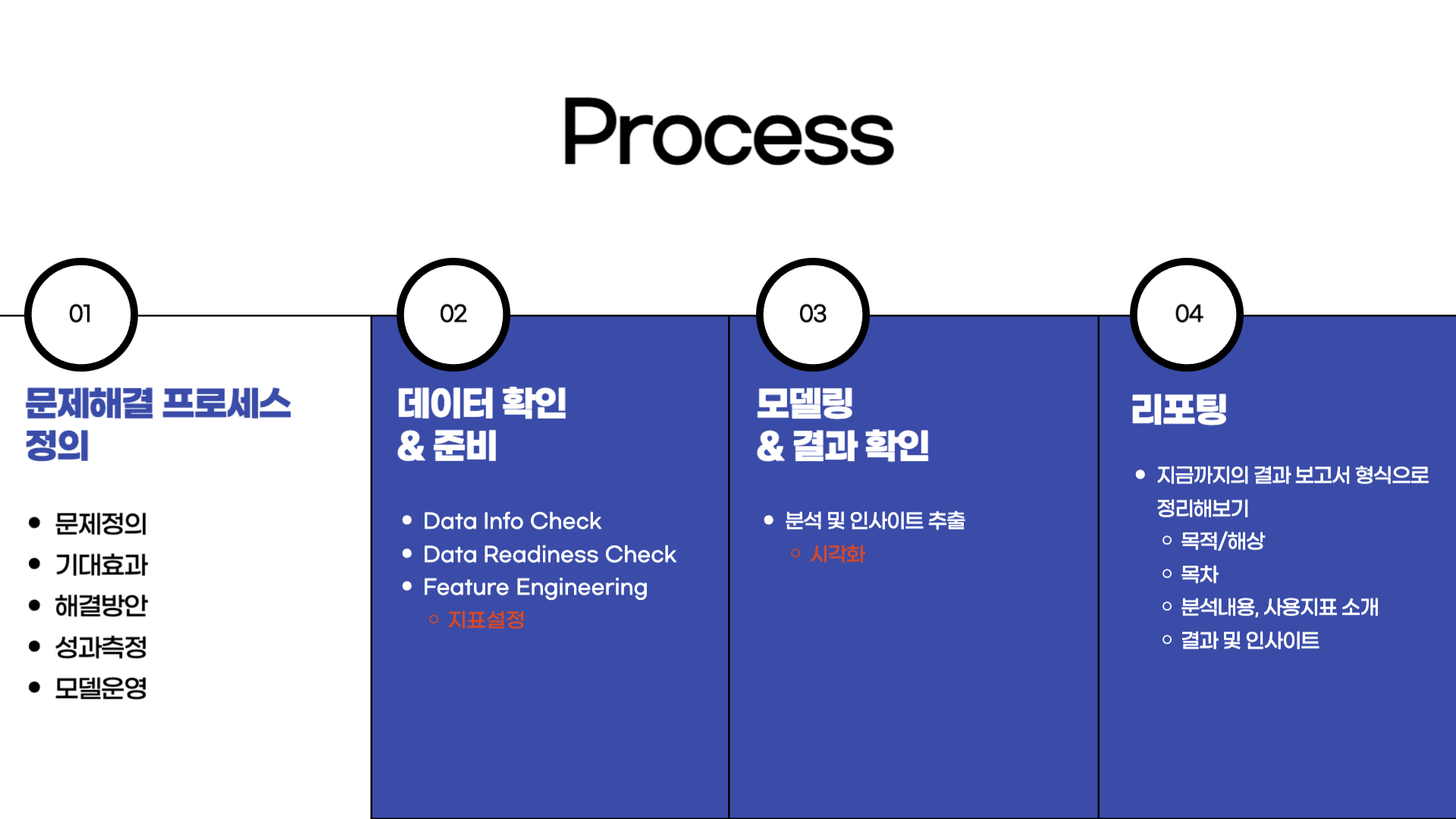
프로젝트의 전체적인 진행과정은 이전 프로젝트들과 다르지 않습니다. 문제해결 프로세스를 정의하고, 데이터를 확인하며, 정제된 데이터를 이용하여 모델링을 하고 결과를 확인하는 과정은 같습니다. 하지만, 서두에서 다루었던 것처럼 Feature Engineering 과정에서 (새로운) 지표를 설정하는 것과, Modeling 부분에서 시각화를 하며 인사이트를 추출하는 과정, 마지막으로 리포팅을 하는 것은 이전 프로젝트들과는 다른 부분이었습니다.
이전 프로젝트들도 리포팅을 하는 과정이 원래 있었어야 하지만, 모델링과 데이터 부분에 더 집중을 하다보니 다루지를 못했던 것 같습니다. 그래서 이번 미니 프로젝트에서는 마지막에 리포팅을 한다면 어떻게 할 수 있을지 간단하게 정리해보겠습니다.
본격적으로 Feature Engineering 부분과 Modeling 부분, 리포팅 과정을 어떻게 했는지 시작하기에 앞서 이번 미니 프로젝트에서 다루었던 문제에 대해 더 자세히 소개해드리고자 합니다.
이번 미니 프로젝트의 문제는 제목에서 유추할 수 있듯이 지하철 배차 스케줄 오류로 인해 러시아워 (Rush Hour)의 발생입니다. 이는 시민 불편 및 안전사고 건수가 증가하는 위험을 초래할 수 있으며, 결국 피해보상금액 증가로 운영을 하는데 있어 큰 타격이 될 수 있습니다.
해당 문제를 해결하므로서 얻을 수 있는 기대효과로는 러시아워 (혼잡시간) 때 승객들의 밀집도를 저하시킴으로서 고객 만족도 상승 및 안전사고 건수 감소로 피해보상금액을 감소입니다. 하지만 지하철 정거장마다 승하차하는 고객의 수가 다르므로 각 역마다의 분석이 필요할 것입니다.
해결방안으로는 주어진 데이터를 활용하여 지하철 상,하차 시간 분석을 통해 러시아워 시간대를 탐색하는 것과 더불어 상,하차 Seasonality 분석을 통해 계절별 배차 스케줄을 설계하는 것이 있을 것입니다.
그럼 다음으로 Feature Engineering 부분이 이전 미니 프로젝트들과 어떤 차이가 있었는지 더 자세히 다루어보겠습니다.
03. Feature Engineering
기존의 Feature Engineering 단계에서는 변수들을 모델링에 더 도움이 될만한 변수로 가공하거나 혹은 노이즈를 없애기 위한 Feature Selection 단계를 주로 했었습니다. 하지만 이번 미니 프로젝트의 목표는 인사이트 제공입니다. 때문에 이번 Feature Engieering 단계에서는 분석에 사용될 지표를 정하는 과정을 거쳤습니다.
그 두가지는 각각 호선별 밀집도와 시간별 밀집도 입니다.
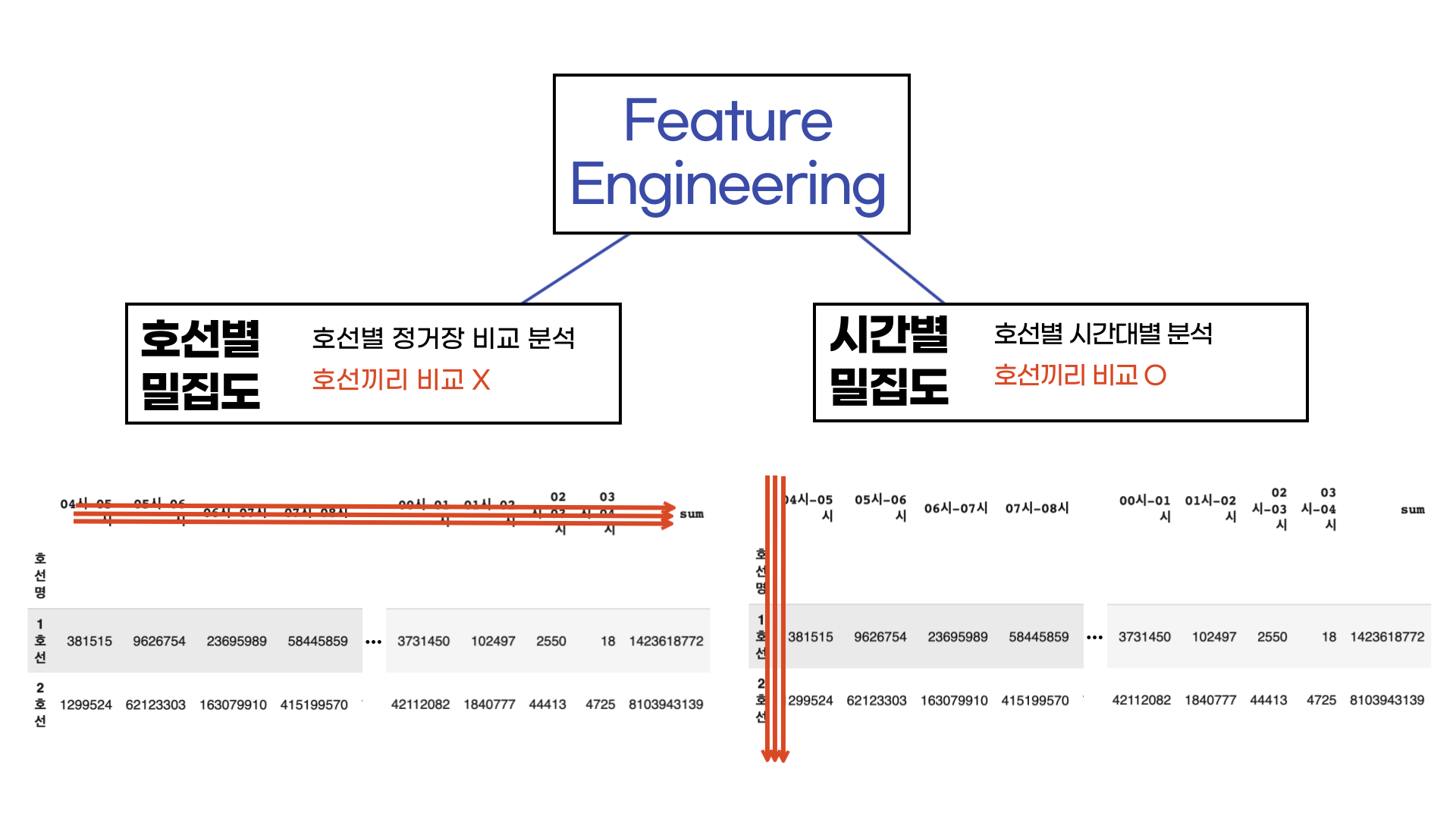
호선별 밀집도는 각 호선의 전체 상하차 인원에 시간대별 상하차 인원을 나눈 지표입니다. 이 지표는 각 호선별로 합계 (sum)을 따로 구하여 나눈 지표이기 때문에 호선끼리의 비교는 불가능합니다. 호선별로 스케일링이 다르게 되었기 때문에 여기서는 각 호선의 시간대별 밀집도가 어느정도인지만 어느정도 파악할 수 있습니다. 하지만 각 호선별로 여러장의 정거장들이 있습니다. 그래서 호선마다 정거장별로의 비교 분석은 가능합니다.
두번째 지표는 시간별 밀집도입니다. 이 지표는 호선간 비교 분석이 가능합니다. 왜냐하면 이때는 MinMaxScaler를 사용하여 스케일링을 진행할텐데, 시간대별 (컬럼별)로 스케일링이 이루어지기 때문에 호선별로 시간대별 분석이 가능합니다.
이렇게 두가지 지표를 정했으니 모델링 과정에서 해당 지표를 활용하여 어떻게 분석을 진행했는지 다루어보겠습니다.
04. Modeling
모델링과정에서는 새로 설정한 지표를 활용하여 시각화를 통해 분석을 진행했습니다.
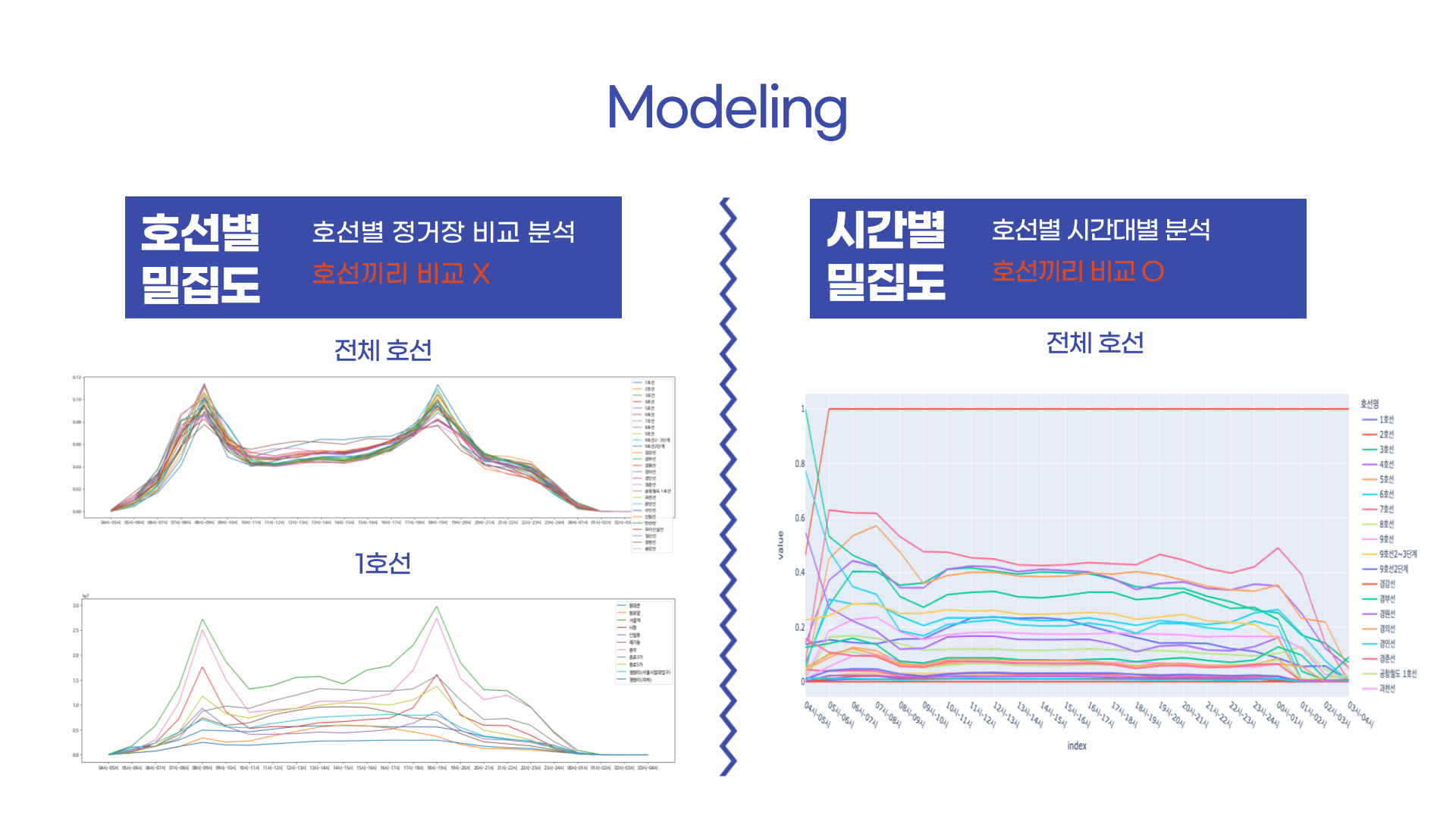
먼저 호선별 밀집도를 보면 예상이 되었듯 출근 시간과 퇴근시간에 밀집도가 가장 높은 것을 확인할 수 있습니다. 그 아래에는 1호선만 따로 분석한 그래프입니다. 해당 그래프를 보면 출근시간보다 퇴근시간에 밀집도가 더 높은 정거장이 있는 반면 퇴근시간보다 출근시간에 밀집도가 더 높은 정거장이 있는 것을 확인할 수 있었습니다. 하지만 한 정거장에는 한 호선뿐만 아니라 다른 호선도 지나가는 정류장들이 있습니다. 때문에 이에 대한 부분도 잘 고려하여 분석을 하는 것이 중요할 것입니다.
다음으로 호선별로 비교가 가능한 시간별 밀집도를 보겠습니다. 2호선의 경우는 모든 시간대에서 가장 높은 밀집도를 기록했습니다. 다음으로는 7호선, 5호선 순서대로 밀집도가 가장 높았습니다. 2호선 다음은 1호선이 될 것이라 예상했었지만 밀집도 부분에서는 7호선이 더 높은만큼 어떤 정거장 때문에, 혹은 어떤 이유때문에 해당 결과가 나왔는지 추후에 확인을 해봐야할 것 같습니다. (제가 개인적으로 궁금하기 때문입니다!)
05. 결과 및 리포팅
사실 이번 실습에서는 호선별 & 시간대별 밀집도에 대하여 1년 단위의 데이터가 주어졌습니다. 그래서 Seasonality 분석을 위해 이전 프로젝트에서 진행했던 시계열 분석은 어려웠습니다 (최소 2년 이상의 데이터가 있었다면 트렌드 분석이 가능했을 것 같습니다).
때문에 1년 정도의 데이터에서 최근 지하철 밀집도의 추이는 어떻게 되는지 인사이트를 제공할 정도의 분석이 가능했습니다. 그래서 해당 미니 프로젝트의 과정은 여기까지였습니다. 너무 간단하게 끝나버린 것 같아 아쉬움이 가능했었지만, 밀집도에 영향을 줄만한 다른 변수들이 있었다면 더 깊은 분석이 가능했을 것 같습니다.
그렇다면 제가 이전까지 다루어본적이 없는 리포트를 작성하는 전체적인 과정을 배웠는데, 이 부분에 대해서 간략하게 정리하고 마무리하고자 합니다.

이 부분은 제가 블로그 등을 보며 더 자세히 알아보는 시간을 가져야할 것 같습니다. 위의 표는 너무 간단하게 정리가 되어있어 전체적인 리포팅 과정만 머리에 심어(?)두고, 나중에 정리하면 velog에 다시 정리해볼 예정입니다!
여기까지 읽어주셨다면 감사드립니다:) 피드백은 언제나 환영입니다:)
