
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 미니 프로젝트에서는 안테나 불량율을 예측하는 모델링 실습을 했습니다. 이전 20번째 프로젝트에서 진행했던 시설예지보전과 매우 비슷하게 불량율을 예측하기 위해 Classification 문제로 분석을 진행했습니다.
하지만 시설예지보전 프로젝트에서 타겟데이터가 처음부터 0,1 Binary로 되어있던것과 다르게 해당 프로젝트의 타겟 변수는 14개였고 (안테나에 대해 14개의 기능검사를 실시하기 때문입니다) 연속형으로 되어있었습니다. 때문에 해당 프로젝트에는Regression (회귀) 분석 방식으로 진행했어야 합니다.
하지만 Regression 분석 방식으로 했을 때, 모델링 결과로 나오는 loss의 결과를 어떻게 해석할지에 대한 어려움 등으로 Classification 분석 방식으로 해당 문제를 변경하여 실습을 진행했습니다. 때문에 연속형 변수로 되어있던 타겟 데이터를 Binary (0,1)로 바꾸어주고 모델링에 사용할 타겟 변수 하나를 선택하여 모델링을 진행했습니다.
하지만 모델링의 결과는 처참했었습니다. 뒤에서 더 자세히 다루겠지만 class imbalance로 인해 f1-score가 잘 오르지 않았습니다. 그래서 대안으로 threshold를 조절하여 결과를 조정하는 과정을 거쳤습니다.
위의 두가지 내용 모두 실제 현업이라고 가정했다면, 현업가들과 상세한 내용을 통해 조정을 해야하는 부분입니다. 그 이유에 대해서는 뒤에서 더 자세히 다루어보도록 하겠습니다.
서두가 너무 길었습니다! 본격적으로 해당 미니 프로젝트는 어떻게 진행했는지, 어떤 점이 이전 미니 프로젝트와 다르게 진행되었을지 알아보도록 하겠습니다.
02. 프로젝트 진행과정

프로젝트 진행과정은 이전 미니 프로젝트들에서 진행했던 부분과 동일하므로 빠르게 데이터 확인 과정으로 넘어가 서두에서 다루었던 데이터를 어떻게 Regression 문제에서 Classification 문제로 바꾸었는지 이야기해보겠습니다!
03. 데이터 확인 과정

해당 미니 프로젝트에서는 14개의 Y 레이블들이 있었습니다. 안테나 완제품을 생산 한 후 14개의 기능검사들을 진행했기 때문입니다. 하지만 해당 타겟 변수들은 연속형 변수들로 되어있었습니다.
그래서 해당 문제를 Classification 문제로 변형하기 위해 Y 타겟변수들을 특정 기준으로 0과 1로 나누었습니다. (해당 기준은 임의로 변경 가능합니다) 위의 이미지는 14개 타겟 변수 중 3개만을 예시로 뽑아 보여드린 예시입니다.
그렇다면 어떤 변수를 타겟으로 모델링을 진행해야할까요?

해당 실습에서는 불량률이 가장 높았던 Y_07 (안테나 Gain 평균)을 타겟 변수로 모델링 방향을 잡았습니다. 하지만 해당 기준은 현업가와의 대화를 통해 언제나 변할 수 있습니다.
어떤 현업가의 경우는 불량율이 높은 상위 3개의 변수에 대하여 모델링을 해달라고 요구할 수 있습니다. 그렇다면 레이블링을 다시하여 Y_07, Y_01, Y_04 불량을 1로 하고 나머지를 0으로 하여 모델링을 진행해야 할 것입니다. 혹은, 미니 프로젝트에 14에서 진행했던 것처럼 Y_07, Y_01, Y_04 레이블을 한개의 레이블로 합친 뒤, point별로 나누어 구분을 줄 수도 있을 것입니다 (해당 부분은 미니 프로젝트 14를 참고바랍니다!).
때문에 해당 부분은 실제 일을 한다면 현업가와 긴밀한 커뮤니케이션을 통해 정해야 할 것입니다. 그래서 서두에서 이야기했던 실제 현업일 때 중요시해야 하는 포인트 중 하나가 해당 Target을 정하는 Data Readiness Check 부분이었습니다.
다음으로 현업가와의 대화가 중요한 다른 부분인 모델링 결과에 대해 다루어보겠습니다.
04. 모델링
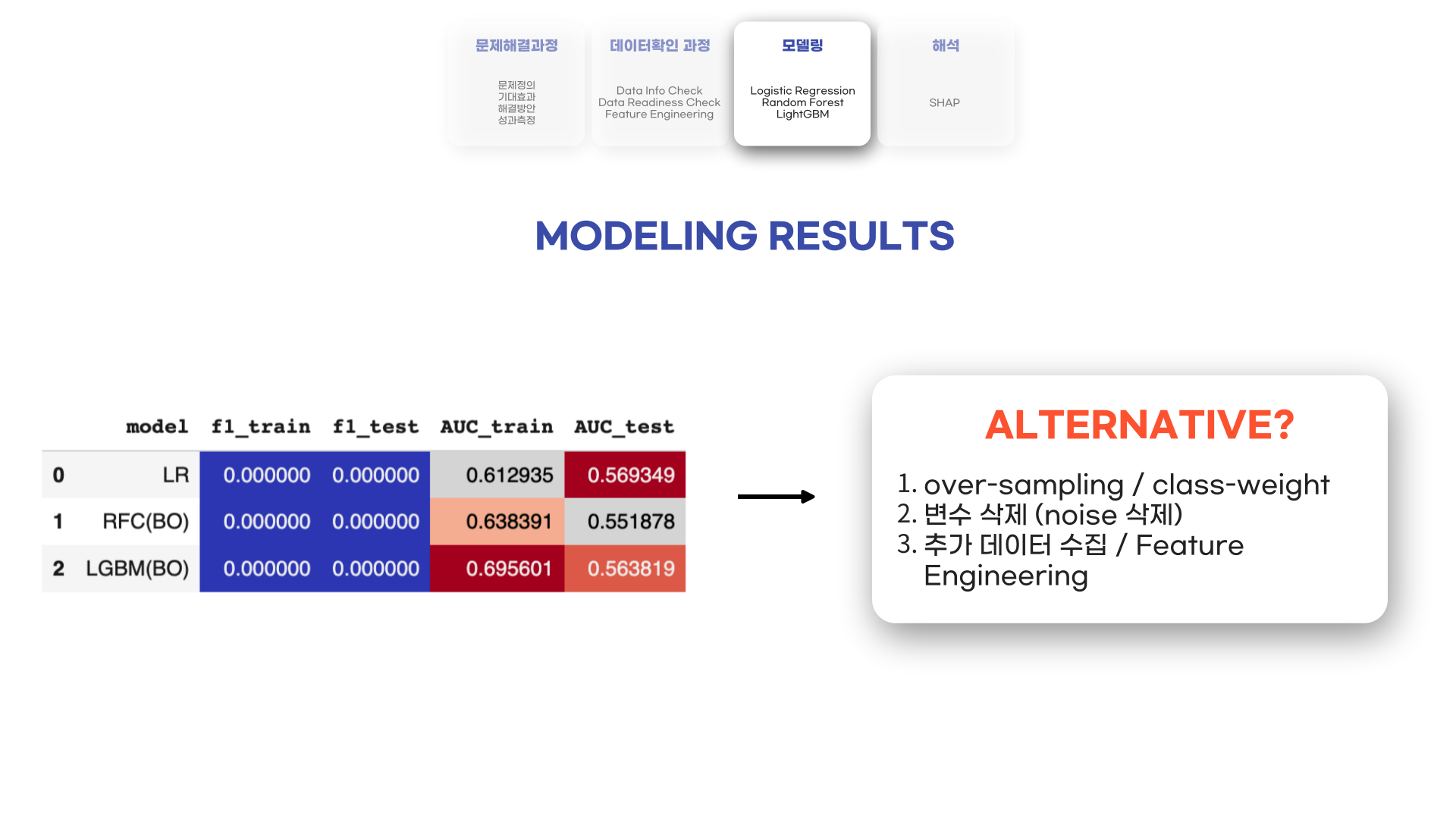
먼저 모델링 결과를 알려드리면, 굉장히 처참했습니다..! Class imbalance가 있는 것은 알고 있었지만, 그래도 4% 정도였기 때문에 f1-score가 어느정도 나올 것이라 예상했지만 점수가 거의 0에 수렴했습니다.
때문에 이를 해결하기 위해 이전 프로젝트와 마찬가지로 over-sampling을 통해 class imbalance 문제를 해결하여 학습을 하거나, 혹은 Tree 계열의 모델들에서 class-weight를 조정하여 다시 학습을 시켜야함을 느꼈습니다. 두번째로, IV (Information Value)나 Feature Importance에 기반하여 Feature Selection (중요도가 낮은 변수 삭제)를 하고나서 다시 모델링을 하며 결과를 다시 봐야할 것 같습니다. 그래도 결과가 잘 나오지 않는다면 해당 데이터로는 유의미한 결과를 도출하기 어렵기 때문에 추가 데이터를 수집하거나 데이터를 더 가공하여 모델링을 하는 방법을 모색해야 할 것 같았습니다.
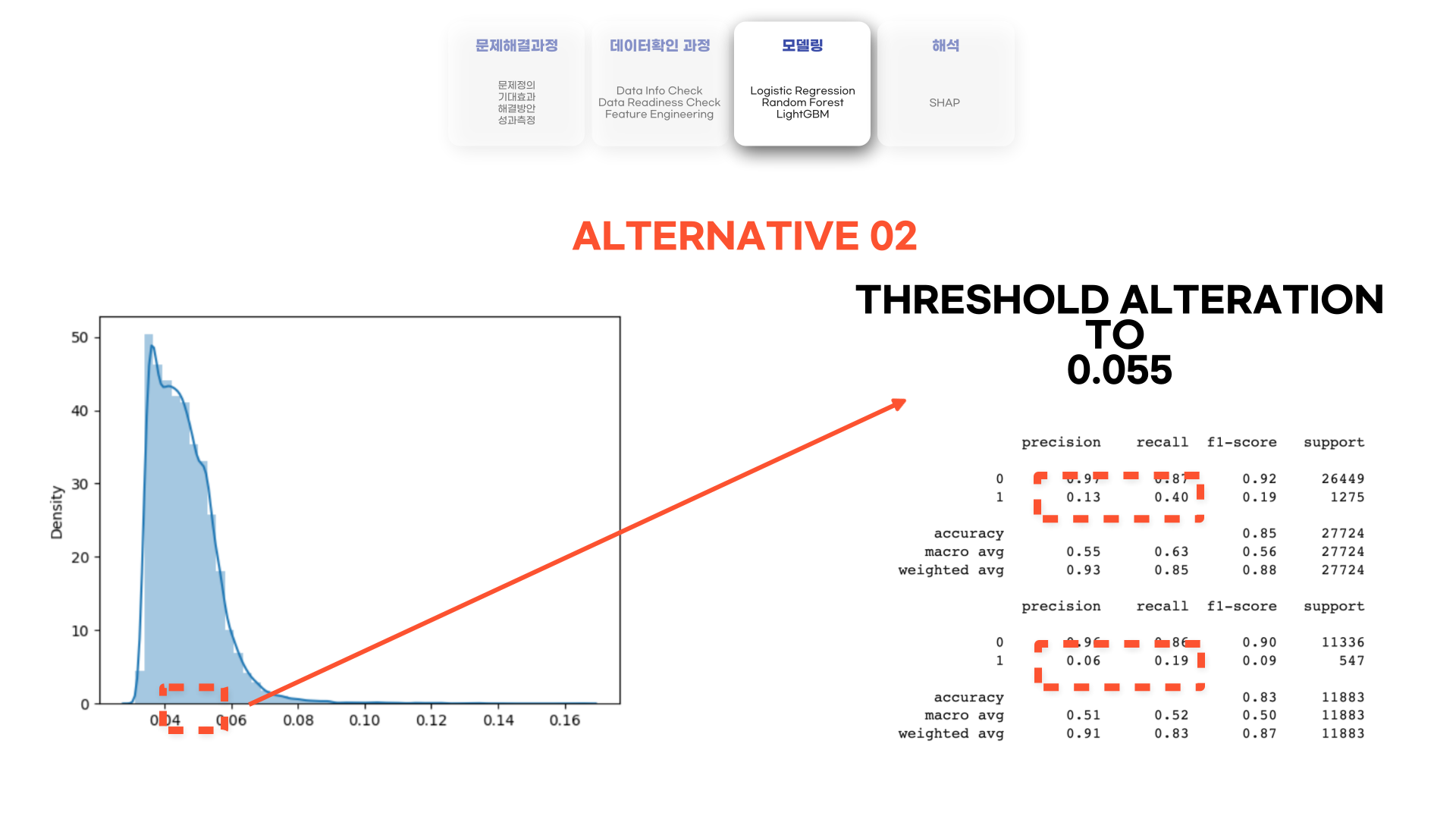
다른 방법으로는 threshold를 조정하는 방법이 있습니다. Binary Classification의 경우 0.5의 확률을 기준으로 0, 1을 나눕니다. 때문에 해당 데이터에서는 많은 변수들이 0.5의 확률 및으로 떨어져 0으로 구분이 되었을 것입니다.
먼저 predict_proba로 나온 결과를 봤을 때, 대부분의 예측확률이 평균이 대략 0.05인 분포를 나타내고 있었습니다. 그래서 scikit-learn의 Binarizer를 활용하여 threshold (임계값)을 조정해봤습니다. 그 결과 거의 0에 수렴했던 precision과 recall 점수가 조금씩 올라갔습니다. 하지만 해당 모델을 실제로 쓰기에는 precision 점수와 recall 점수가 너무 낮아 어려울 것으로 예상이 됩니다.
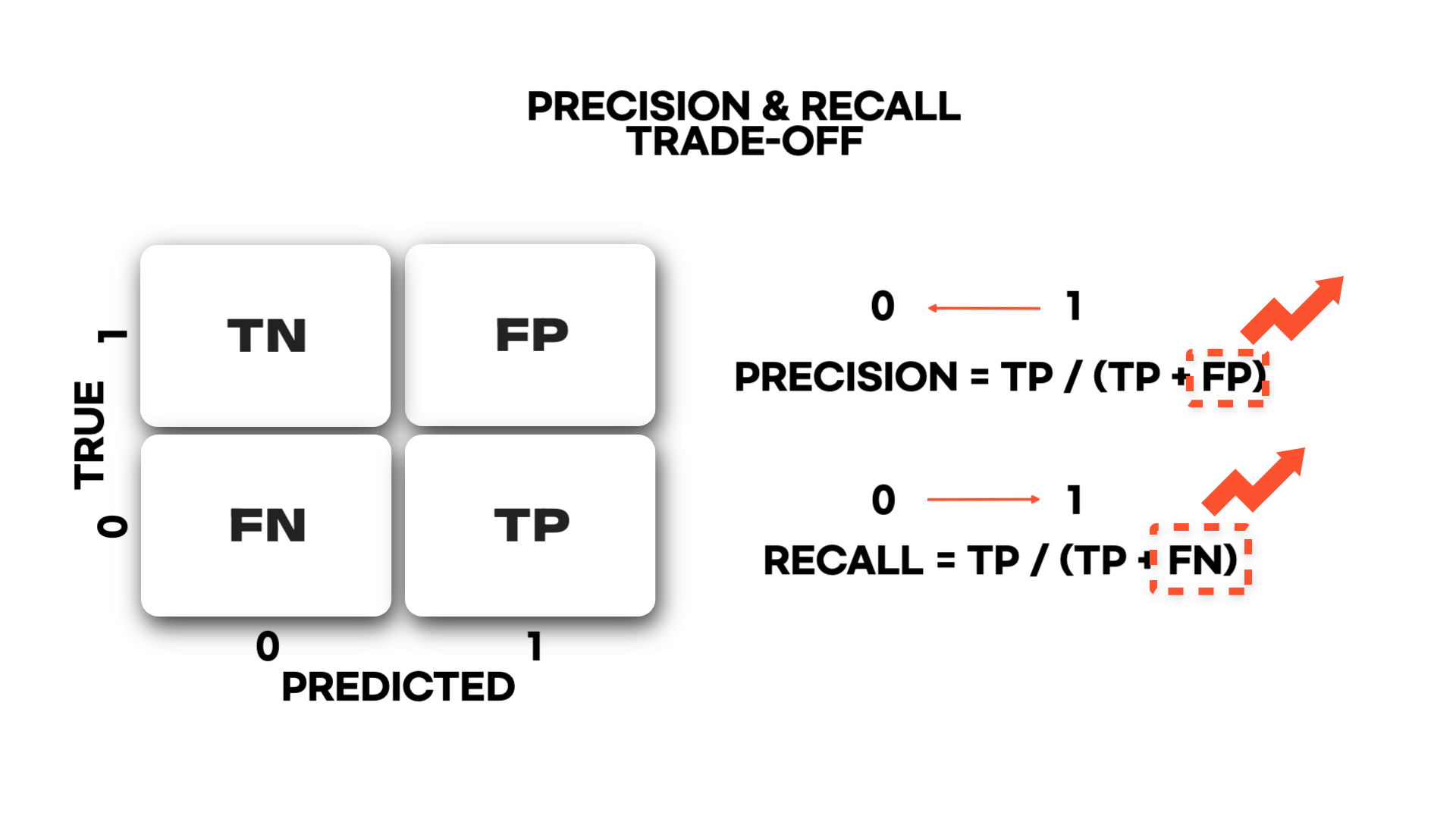
만약 성능이 어느정도 나왔다면 임계값 또한 현업가와의 커뮤니케이션을 통해 조정을 할 수 있습니다.
Recall (재현율)를 높이고 싶다면 임계값을 0에 더 가깝게 높이면 될 것입니다. 하지만 이는 Precision (정밀도)이 낮아지는 trade-off의 관계에 있습니다. 이유는 임계값이 0에 가까워짐에 따라 0의 오차건수가 많아져 Precision은 낮아지기 때문입니다.
이와 반대로 임계값을 1에 더 가깝게 높이면 Precision은 높아지고, 반대로 Recall은 낮아질 것입니다.
결과적으로 현업가가 어떤 성능을 높이고 싶은지에 따라 임계값을 조정할 수 있습니다!
05. 마무리하며
이번 글을 마무리하고 모델의 성능을 높이기 위해 언급했던 세가지 방법 (over-sampling or class-weight, 변수 제거, feature engineering)을 활용해야 할 것 같습니다. 이 후 저 혼자만의(?) 시나리오를 써서 threshold 값을 조절하며 결과값이 어떻게 변하는지 확인해볼 예정입니다.
이번 미니 프로젝트에서는 다른 데이터로 이전에 했던 내용을 계속 복습하는 것도 있었지만, 실제 현업이었다면 어느 부분에서 현업가와의 커뮤니케이션을 통해 문제를 해결해야 할까에 대한 생각을 해볼 수 있는 시간이었습니다. 실제로 현업에서 많은 부분을 차지하는 것이 커뮤니케이션이라는 것을 들었(?)습니다. 그래서 분석도 중요하지만 어떻게 커뮤니케이션을 해야지 더 좋은 분석가가 될 수 있을지 공부를 해야겠습니다. 이상입니다!
부족하지만 읽어주셨다면 감사합니다:) 피드백은 언제나 환영입니다:)
