
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 미니 프로젝트에서는 분류 문제가 아닌 회귀 (Regression) 문제를 통해 실습을 진행했습니다. 예측하고자 하는 타겟변수는 Followers gained (팔로워수 증가)로서 어떤 변수들이 팔로워수 증가에 영향을 끼치는지 알아보았습니다.
하지만 결론부터 말씀드리면 모델의 결과가 썩 좋지는 않았습니다. 회귀 문제이기 때문에 측정항목을 R2-score (결정계수)와 RMSE (평균제곱근오차)로 설정하고 3가지 다른 작동 방식의 알고리즘 (Logistic Regression, RandomForest, LightGBM)을 사용하여 모델링을 했습니다. 하지만 테스트셋에 대한 R2-score는 약 50 정도밖에 되지 않았고 (모델이 분산을 50% 정도밖에 설명을 못함), RMSE의 경우 테스트셋에 대하여 190000이 넘는 결과(너무 큼)를 보여주었습니다. 하이퍼파라미터 튜닝을 통해 성능을 좀 더 높일 수도 있겠지만
때문에 해당 모델은 실무에서는 사용하기 어려운 모델이 될 것 같습니다.
해당 원인은 데이터의 수가 적은 것도 있지만 (1000개의 rows) 사용한 변수들이 모델을 설명하는데 부족했기 때문이라고 예상이 됩니다. 예시로 아래 사용한 변수들을 보면 Channel 별로 (Channel은 가렸습니다!) 시청시간, 방송시간 등등이 집계되어있습니다.

하지만 이전 미니 프로젝트에서도 이야기를 해본 것과 마찬가지로 이미 데이터가 집계되어있는 상태입니다. 즉, 어느 정도의 기간동안의 데이터를 이미 집계했기 때문에 저는 언제부터 언제까지 집계된 데이터인지, 특정 어느 시간대에 사용자수가 급감했는지 등등은 확인하기 어렵습니다. 또한 어느 장르 혹은 어떤 카테고리의 채널들 분석 결과인지 알 수가 없었습니다. 때문에 모델링을 하여 현재 있는 데이터로 얻을 수 있는 결과를 얻었습니다. 이 결과는 해당 글의 마지막 부분에 말씀드리겠습니다!
그렇다면 본격적으로 시작하기에 앞서 전체 프로젝트 과정은 어떻게 되고, 문제해결 프로세스 정의는 어떻게 되는지 다루어보겠습니다.
02. 프로젝트 전체 과정 & 문제해결 프로세스 정의
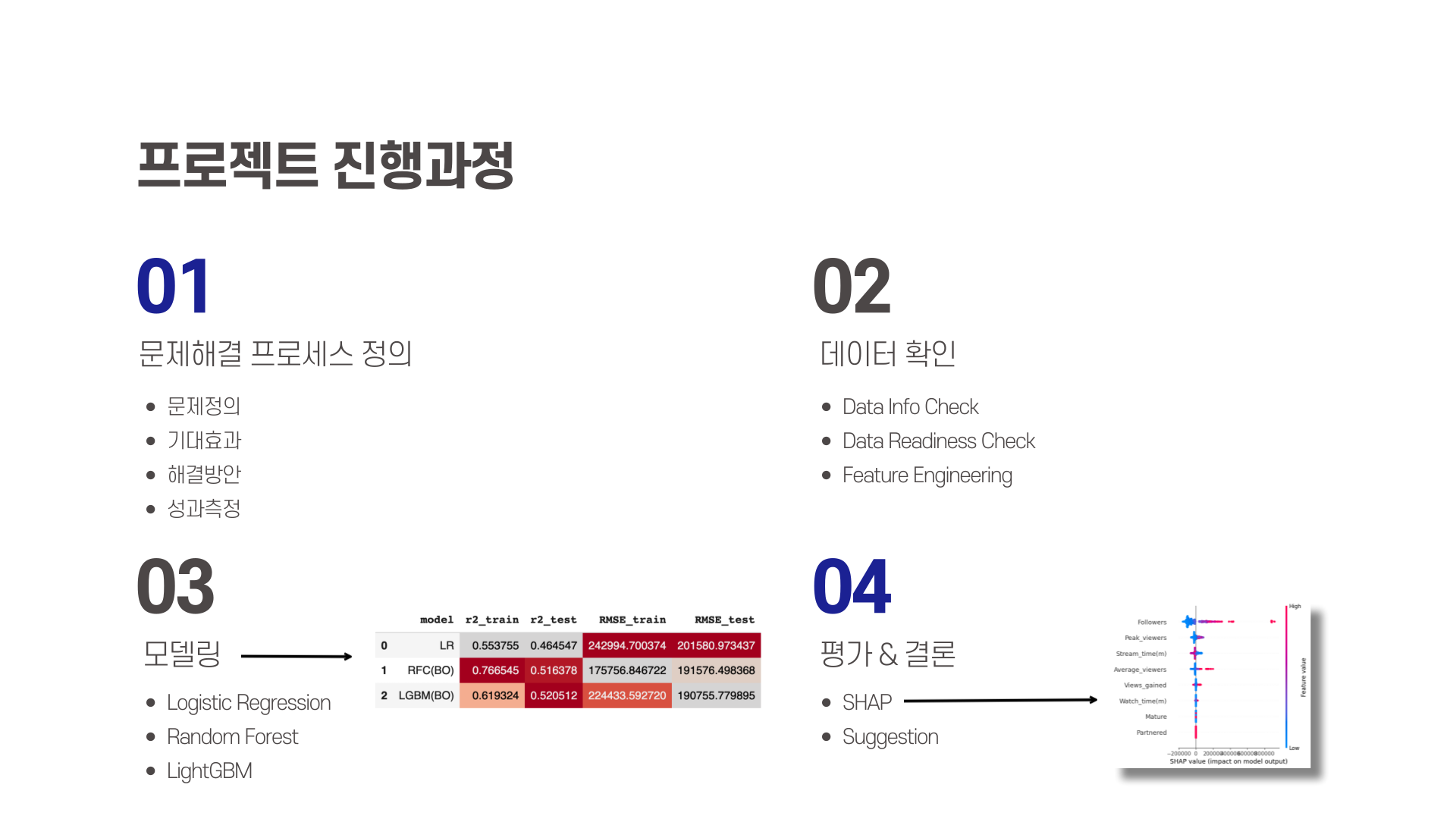
이전 다른 프로젝트들과 마찬가지로 4가지 단계를 통해서 미니 프로젝트를 진행했습니다. 이 글에서 제가 다루어 볼 부분은 먼저 어떤 문제를 해결할지 알아야 하기 때문에 문제해결 프로세스 정의와 모델링, 그리고 결론 부분을 다루어보겠습니다.
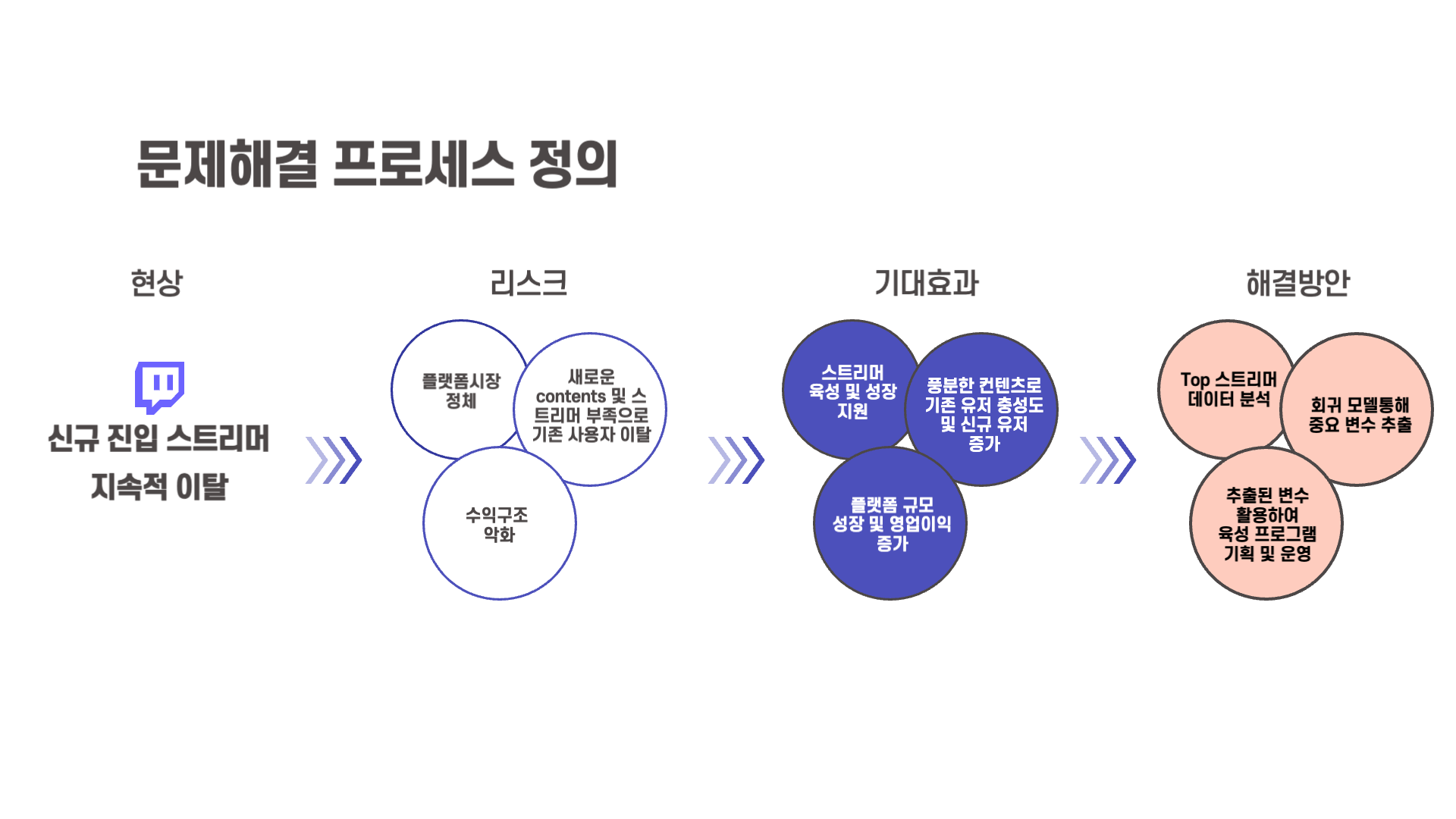
문제해결 프로세스를 보면, 먼저 나타나는 현상은 신규 스트리머의 지속적인 이탈입니다. 위의 이미지와 같이 3가지 리스크 및 문제가 발생하게 됩니다. 때문에 신규 스트리머 육성 프로그램을 기획 및 운영하여 위와 같이 3가지의 기대효과를 예상해볼 수 있습니다. 이에 대한 해결방안으로 많은 팔로워 수와 시청자 수를 보유하고 있는 top 스트리머들의 데이터를 가져와 분석을 하는데, 회귀 모델을 통한 모델링을 통해 결과 및 중요 변수를 추출했습니다. 이때 모델링의 결과는 SHAP 라이브러리를 통해서 볼 건데, 중요 변수들이 타겟값(팔로워수 증가)에 어떤 영향을 끼치는지를 확인해 결론을 내렸습니다.
그러면 다음으로, 모델링을 한 결과를 보겠습니다.
03. 모델링 결과 및 평가&결론
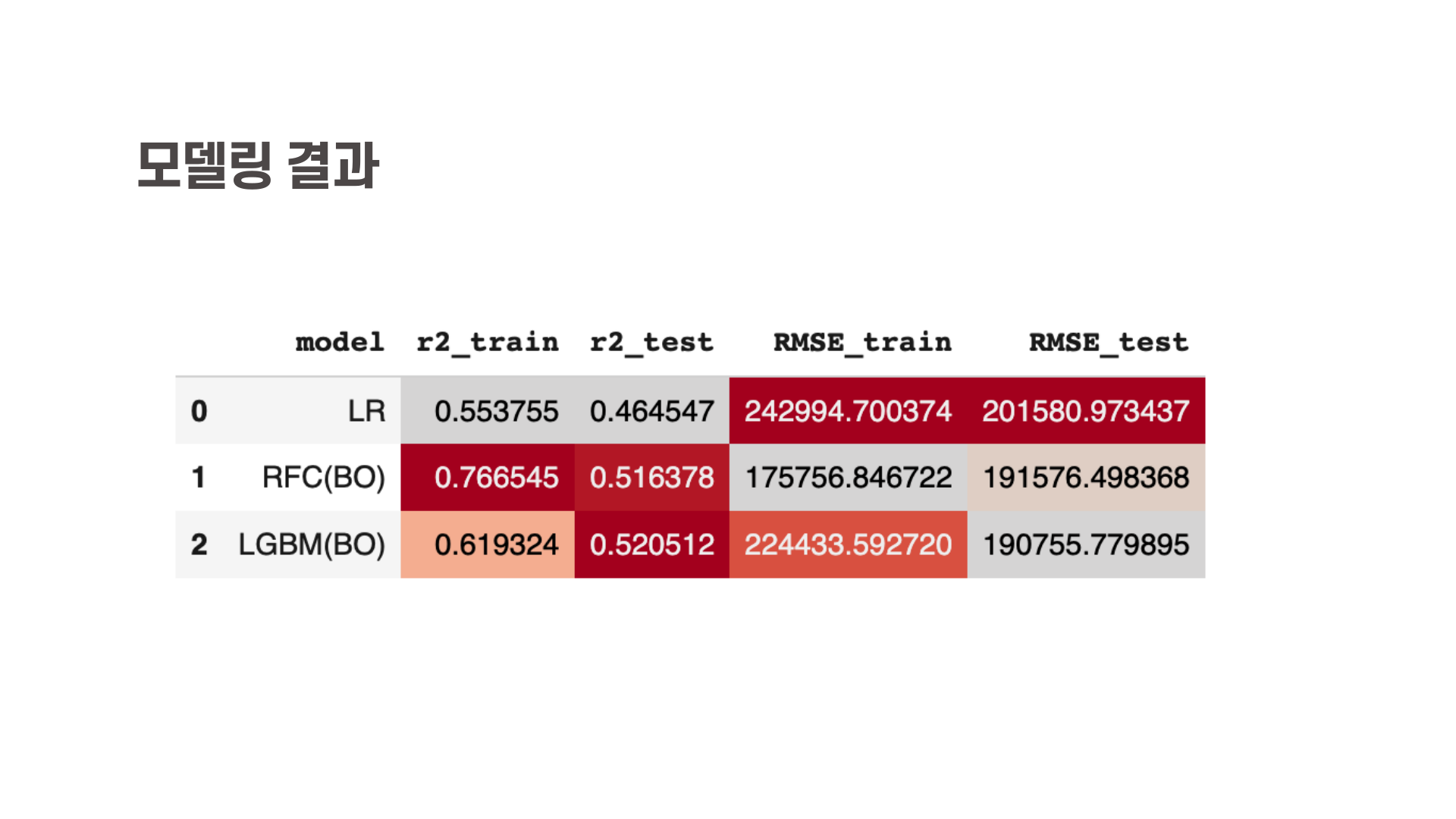
모델링 결과는 위와 같습니다. 물론 기본적인 하이퍼파라미터 튜닝을 하여 결과를 더 높일 수는 있겠지만, r2-score와 RMSE가 너무 낮을 것을 보니 데이터를 다시 수집해야 할 것으로 보입니다.
그래도 테스트셋에서 그나마 좋은 결과를 보였던 BayesianOptimization을 수행한 LightGBM 모델로 SHAP 라이브러리를 사용하여 해석한 결과는 아래와 같습니다.
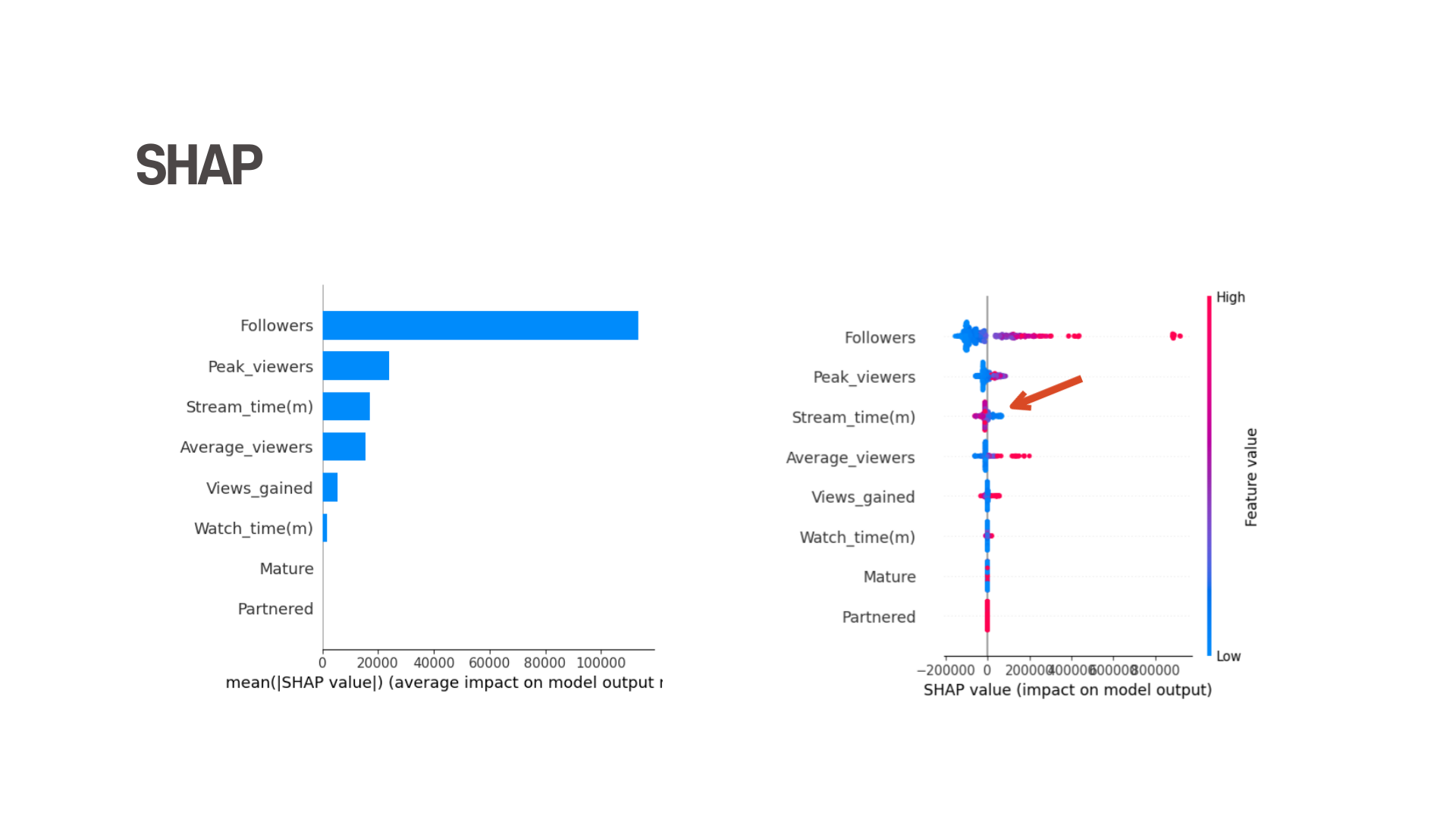
가장 중요한 변수는 Follower (팔로워 수)였습니다. 하지만 이 결과는 누구나 알만한 결과입니다. 팔로워 수가 많으니 팔로워 증가 수가 많기 때문입니다!
다음 변수 Peak_viewers (최고 시청자수)를 보면, 오른쪽 summary_plot에서 최고 시청자수가 높을수록 팔로워수가 증가하는 것을 알 수 있습니다. 이 결과는 모델링이 아니어도 어느 정도 짐작은 할 수 있었지만, 결론을 내릴 때 활용할 수 있을 것으로 보입니다.
마지막으로 Stream_time(m)을 보면, 오른쪽 summary_plot에서 스트리밍 시간이 적을수록 팔로워수 증가에 영향을 끼치는 것을 알 수 있습니다. 그렇다면 팔로워 수 증가에 영향을 끼치는 hidden factor는 스트리밍 시간이 적은것과 팔로수 증가에 관련성이 있다는 것입니다.
그렇다면 이러한 결과를 통해 어떠한 결론을 낼 수 있을까요? 스트리밍 시간이 길다고 팔로워 수가 증가하는 것이 아닙니다. 때문에 최고 시청자수를 늘릴 수 있는 새로운 컨텐츠를 개발하는 것에 중점을 두는 것이 좋을 것입니다. 라는 결론을 결과를 통해 내릴 수 있습니다.
04. 마무리하며
사실 많은 분들은 이미 해당 결과를 어느 정도 예상하셨을 거라고 생각합니다. 하지만 이러한 결과를 데이터를 통해 분석할 수 있는 경험을 할 수 있어 좋은 기회였습니다.
앞에서도 이야기한것처럼 어느 장르, 카테고리의 스트리밍 채널들인지, 데이터 수집 기간은 어떻게 되는지 등의 더 자세한 정보가 있으면 더 구체적인 분석결과를 가질 수 있을 것으로 예상이 됩니다.
여기까지 수업의 거의 반 정도를 들었습니다. 다음 글에서는 지금까지 배운 내용의 간단한 총평을 해보도록 하겠습니다!
부족하지만 읽어주셔서 감사합니다:) 피드백은 언제나 환영입니다:)
