
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며

이번 미니 프로젝트는 이전에 진행했던 2개 정도의 미니 프로젝트와 동일하게 목표와 문제정의에 맞게 수집된 데이터를 통해 인사이트를 찾아내는 실습을 진행했습니다.
사실 지금에 와서 말하는 것이지만, 모델링 과정에 비하면 해당 작업은 간단한 작업이라고 생각했었습니다. 하지만 강의에서 데이터 사이언티스트가 좀 더 기술적인 부분에 집중한다면, 분석가는 현업가와의 커뮤니케이션, 현업가들이 유용하게 사용할 수 있는 대시보드 개발 및 리포팅에 더 집중한다는 것을 배웠습니다.
이러한 내용을 배우니 모델링이 전부라고 생각했던 제가 너무 부끄(?)러웠습니다. 또한 해당 데이터에는 연도별로 설문조사에 대한 응답률이 있는데, 단순히 연도간 비교를 하면 되겠지? 라고 생각한 것이 짧은 생각이었다는 것 또한 배울 수 있었습니다.
본격적으로 시작하기 전에, 항상 거치는 과정인 프로젝트 진행과정을 간단하게 소개하고 문제해결 프로세스 정의 단계로 넘어가겠습니다.
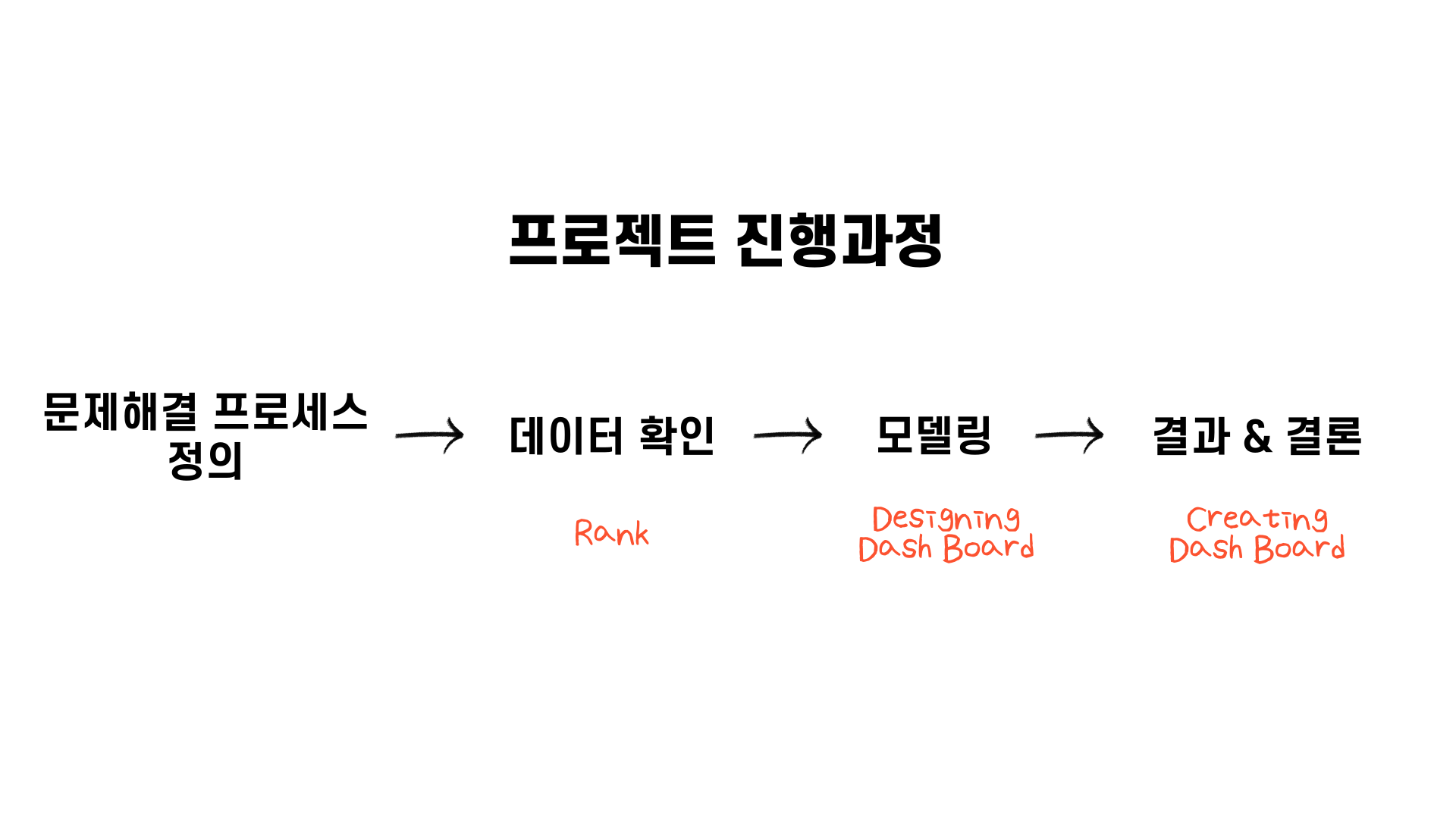
먼저 문제정의, 기대효과, 해결방안을 문제해결 프로세스 정의 단계에서 정리했습니다. 다음으로 데이터 확인 단계, 특히 Feature Engineering 단계에서 pandas의 rank 함수를 써서 연도별 응답률 순위를 매겼습니다. 왜 rank를 썼는지에 대한 이유는 본 단계에서 조금 더 자세히 다루겠습니다. 그 다음으로는 모델링 단계로 넘어가는데, 여기서는 데이터 분석 후 대시보드를 제작하는 것이 목표이기 때문에 대시보드를 기획하는데 집중했습니다. 마지막으로 대시보드를 기획한 것을 바탕으로 대시보드를 생성하면서 해당 미니 프로젝트를 마무리했습니다.
대시보드의 경우는 low-level로 matploblib을 통해 생성했습니다. 더 깔끔하게 만들기 위해 BI tools, 예를 들어 tableau나 streamlit 등을 사용할 수 있으나, 이 부분은 제가 개인적으로 진행해보도록 하겠습니다!
그럼 문제해결 프로세스 정의 부터 시작해보겠습니다.
02. 문제해결 프로세스 정의
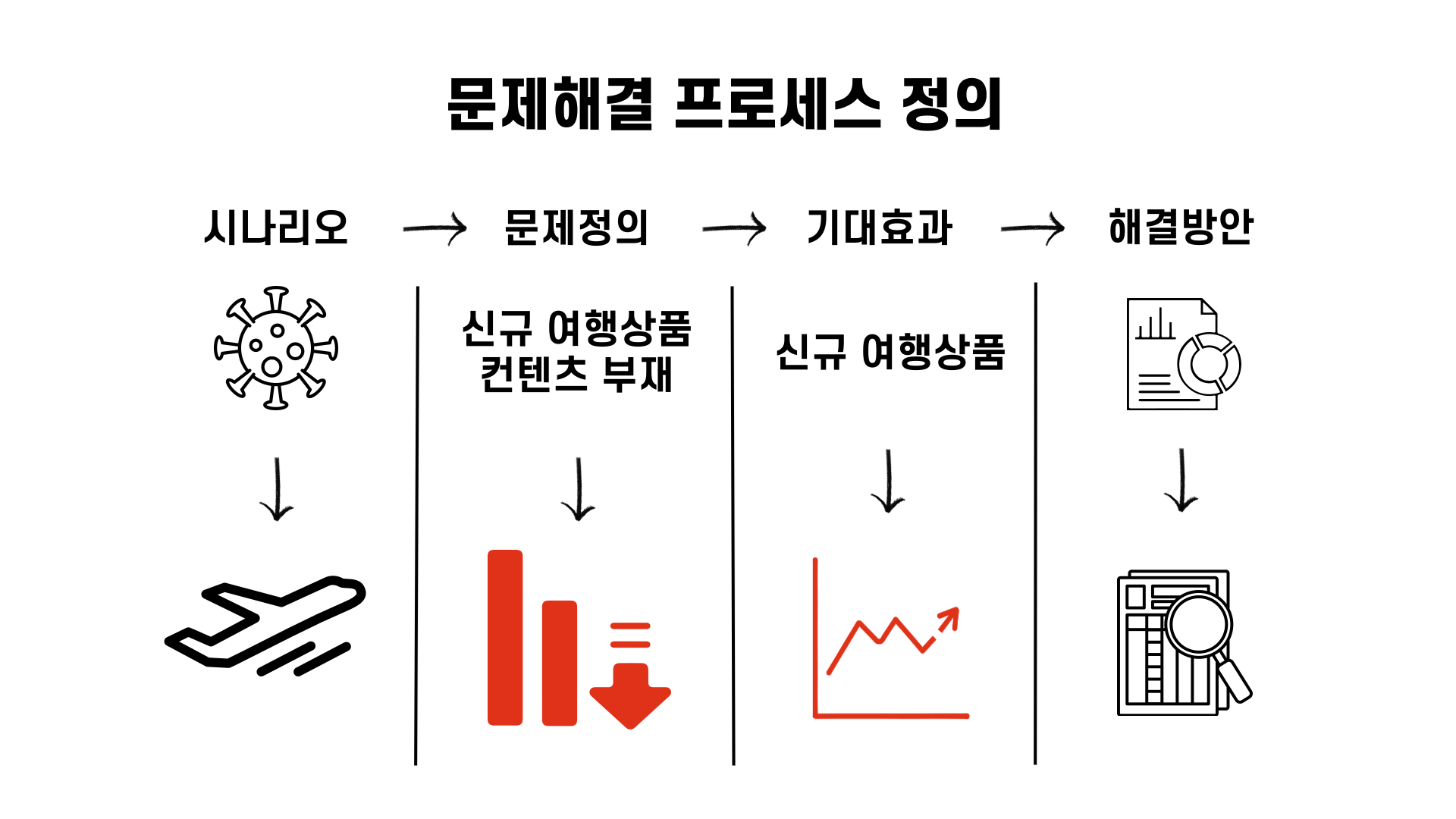
이 미니 프로젝트의 배경(시나리오)부터 설명드리면, 신규 여행상품을 개발하는 역할을 하는 C부서가 있습니다. 코로나로 인해 여행 수요가 급감했었으나, 최근 코로나 감염세가 축소되어 다시 여행 수요가 늘어나고 있음을 확인했습니다. 그래서 C부서는 코로나 이전, 코로나 시기에 선호되었던 여행 현황을 분석하여 신규 여행상품 개발에 반영하고자 합니다.
그래서 이 미니 프로젝트에서 해결하고자 하는 문제는 신규 여행상품으로 런치에 필요한 컨텐츠의 부재입니다. 신규 여행상품 개발이 지연되거나 없다면 최근 코로나 감소세로 늘어나는 여행 수요를 대응하지 못해 영업이익이 감소될 것으로 예상이 됩니다.
이 문제를 해결함으로서 얻는 기대효과는 신규 여행상품 개발로 여행 성수기 수요를 대응하여 매출 상승의 효과를 얻는 것입니다.
해결방안으로는 여행 선호도 조사를 통하여 수집된 데이터를 활용하여, 데이터 분석을 통해 발견된 인사이트를 신규 여행 상품개발에 반영하는 것입니다.
데이터는 2018, 2019, 2020년도 3개 년도의 데이터로 프로젝트를 진행했습니다. 최근 2021, 2022, 2023 상반기 데이터를 없지만, 해당 미니 프로젝트를 통해서 여행상품을 개발하는 현업가들의 니즈가 무엇일지, 어떻게 분석을 해야 현업가들이 실제 사용할 수 있을지 알아볼 수 있는 시간이었습니다.
그럼 다음으로 제가 서두에서 말했던 연도별 데이터를 단순히 비교 & 분석하면 왜 안되고 pandas의 rank 함수를 통해서 연도간 비교를 하려고 했는지 다음 단계에서 알아보겠습니다.
03. 데이터 확인 - Feature Engineering
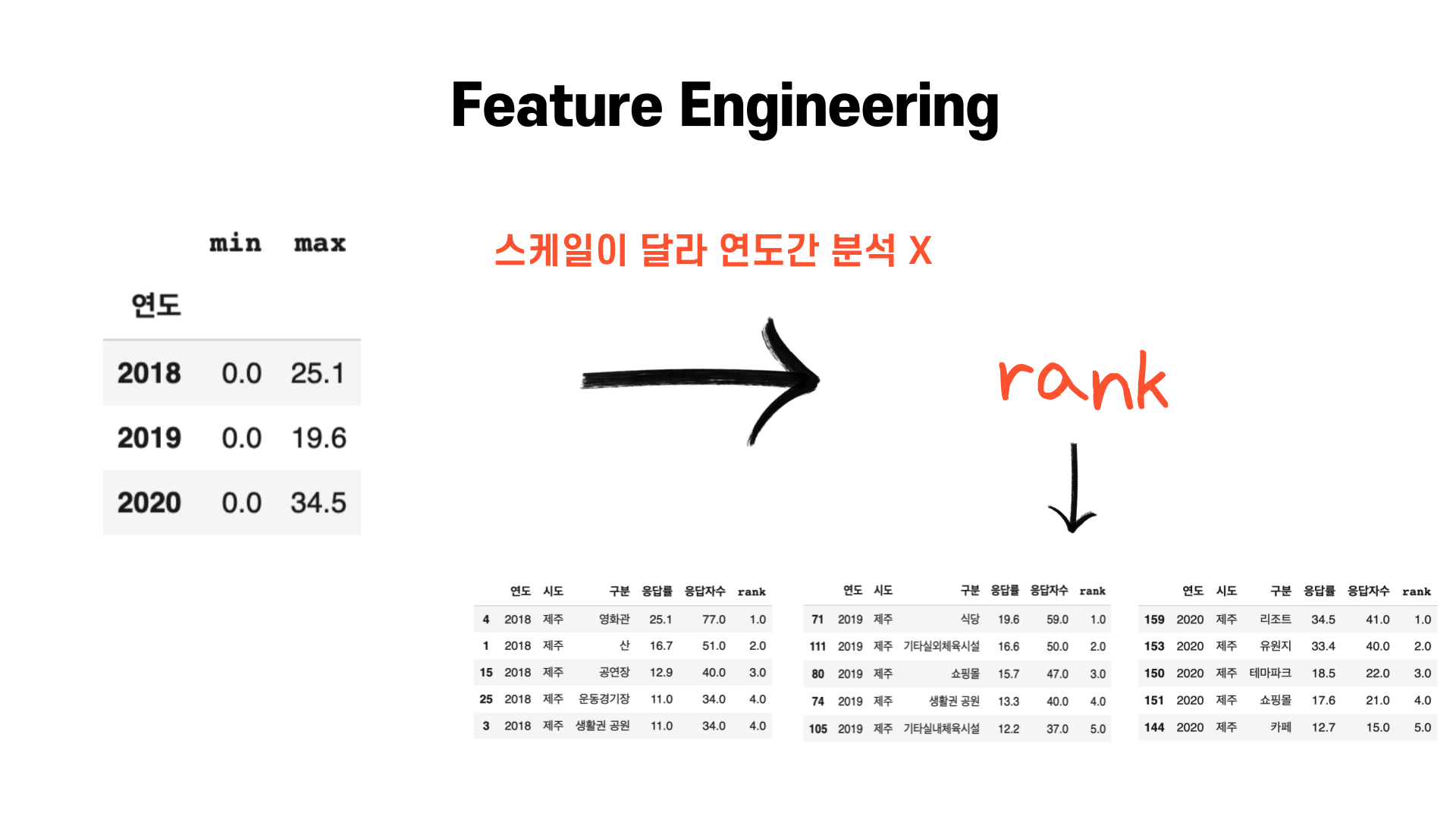
먼저 결론부터 말씀드리면 스케일이 달라서입니다!
위의 이미지를 보면 연도별로 응답률의 최솟값(min)과 최댓값(max)이 다른 것을 볼 수 있습니다. 이렇게 스케일이 다르다면 연도간 비교를 하기 어렵습니다. 예를 들어, 응답률이 10.0이라고 할 때, 2018, 2019, 2020년도에서 응답률 10.0의 위치는 다 다릅니다.
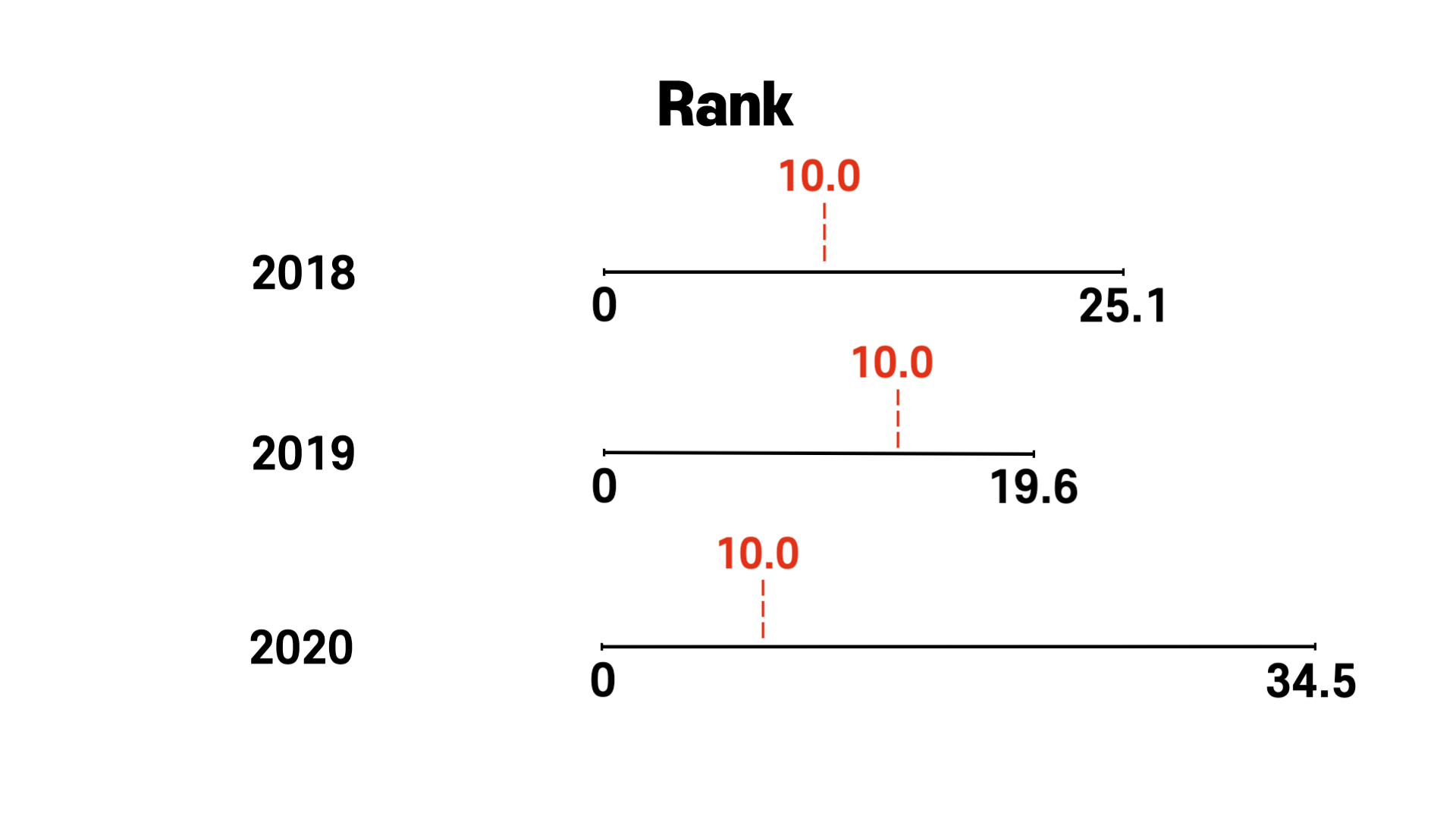
위 이미지에서 볼 수 있듯이 10.0의 위치는 다를 것입니다. 어떻게 연도간 비교를 해야할까요? 예상하셨듯이 rank를 통해서입니다. 10.0의 위치는 각각 연도별 스케일에서 위치하는 ranking이 다를 것입니다. 이 ranking의 비교를 통해서 객관적으로 10.0의 위치를 비교 & 분석이 가능할 것입니다.
혹은 rank가 아닌 MinMaxScaler를 통해서도 비교가 가능할 것입니다. 서로간의 스케일을 맞춰 비교 & 분석이 가능한 상태로 만드는 것입니다! 하지만 여기 미니 프로젝트에서는 ranking을 알아보기 위해 rank를 사용하여 대시보드를 만들때 활용할 컬럼으로 만들었습니다.
그럼 다음으로 대시보드 기획 단계로 넘어가보겠습니다.
04. 모델링 - 대시보드 기획
대시보드를 기획하며 중점에 둔 사항은 3가지 입니다.
첫번째는 응답률에 기반하여 연도별로 선호되는 여가 장소를 ranking으로 나타내기, 두번째는 연도 간의 선호 여가 장소를 ranking을 통해 비교 & 분석하기, 마지막으로는 외부 데이터를 가져와 비교 & 분석하는 것입니다.
여기서는 여행에 영향을 많이 끼치는 날씨 데이터를 가져와 분석한 데이터와 비교 & 분석을 했습니다. 날씨는 어떤 영향을 끼쳤을까요? 마지막 대시보드 생성 단계에서 알아보겠습니다.
05. 평가 - 대시보드 생성
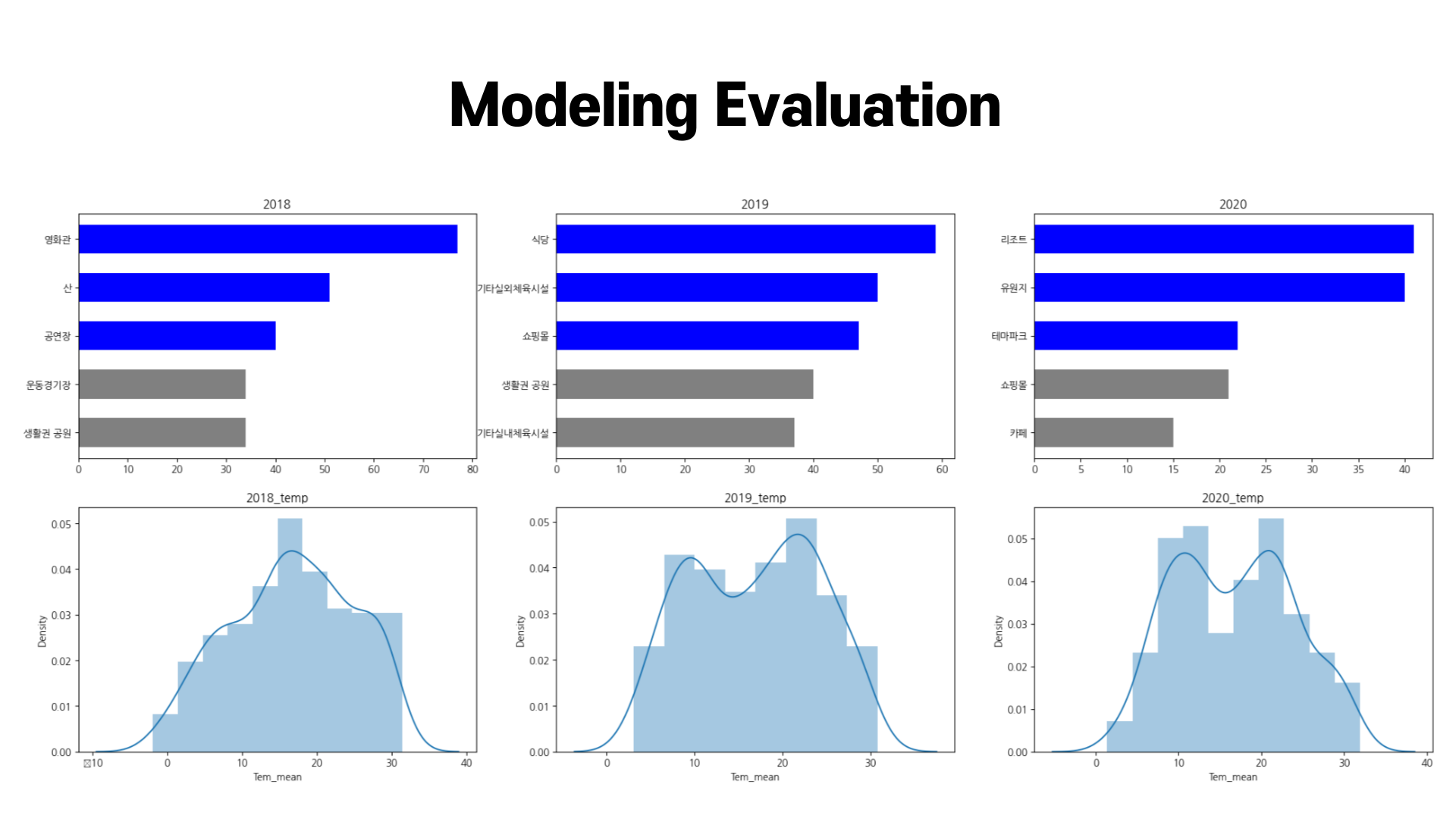
마지막으로 대시보드를 생성하여 내린 결과는 다음과 같습니다.
- 2018년도에서 2020년도로 갈수록 top 1에 위치해있는 선호 여가 장소는 영화관 식당 리조트 로 변해갔습니다.
- 2020년도 코로나 상황을 고려했을 때, 사람들의 선호 여가 장소는 밀집도가 높은 공간에서 낮은 공간으로 이동하는 것을 확인할 수 있습니다.
- 2018년도에 날씨의 분포는 2019년, 2020년도와 비교하여 완만했었습니다. 그래서인지 사람들의 선호 여가 장소는 야외 4곳, 실내 1곳으로 야외가 더 많았습니다. 이는 2019년 (야외 - 2곳, 실내 - 3곳) , 2020년 (야외 - 2곳, 실내 - 3곳)과 비교했을 때 선호 여가 장소가 날씨의 영향을 많이 받는다는 것을 발견할 수 있었습니다.
이를 통해 내릴 수 있는 결론은 아래와 같습니다.
- (2021년도에 어떤 일이 일어나는지 모른다는 전제하에) 2021년도에도 코로나의 상황이 나아질 것으로 보이지 않으니, 패키지를 연결지어서 실내 공간에서 안전하게 놀 수 있는 프로그램을 같이 넣기
- 2021년도 예상 날씨를 고려하여, 야외에서 놀기 좋은 날씨가 예상되는 때에는 야외 액티비티를 즐길 수 있는 실내 공간을 패키지에 같이 연결짓기
비록 간단한 결과 및 결론이었지만, 현재 주어진 데이터안에서 발견할 수 있는 인사이트였습니다! 이를 잘 대시보드화 및 리포팅하여 현업가들이 사용할 수 있도록 만드는 것이 마지막 작업일 것입니다.
06. 마무리하며
3번째로 데이터를 분석하여 대시보드화하는 실습을 하니 실제 일을 한다면 어떻게 할지 감을 잡을 수 있었습니다. 하지만 대시보드를 한 부분이 너무 low-level로 되어있어 마음에 걸립니다. 이 부분은 streamlit 혹은 다른 BI tool을 통해 더 보기 좋게 만들어보겠습니다!
부족하지만 읽어주셔서 감사합니다:) 피드백은 언제나 환영입니다:)
