
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 각색하여 복습을 위해 작성하였습니다.
프로젝트 진행과정
- 수업내용에서 배운 6 steps을 토대로 진행과정을 작성
(원래 7 steps 이지만 여기서 마지막 부분인 Model Operation 부분 생략)
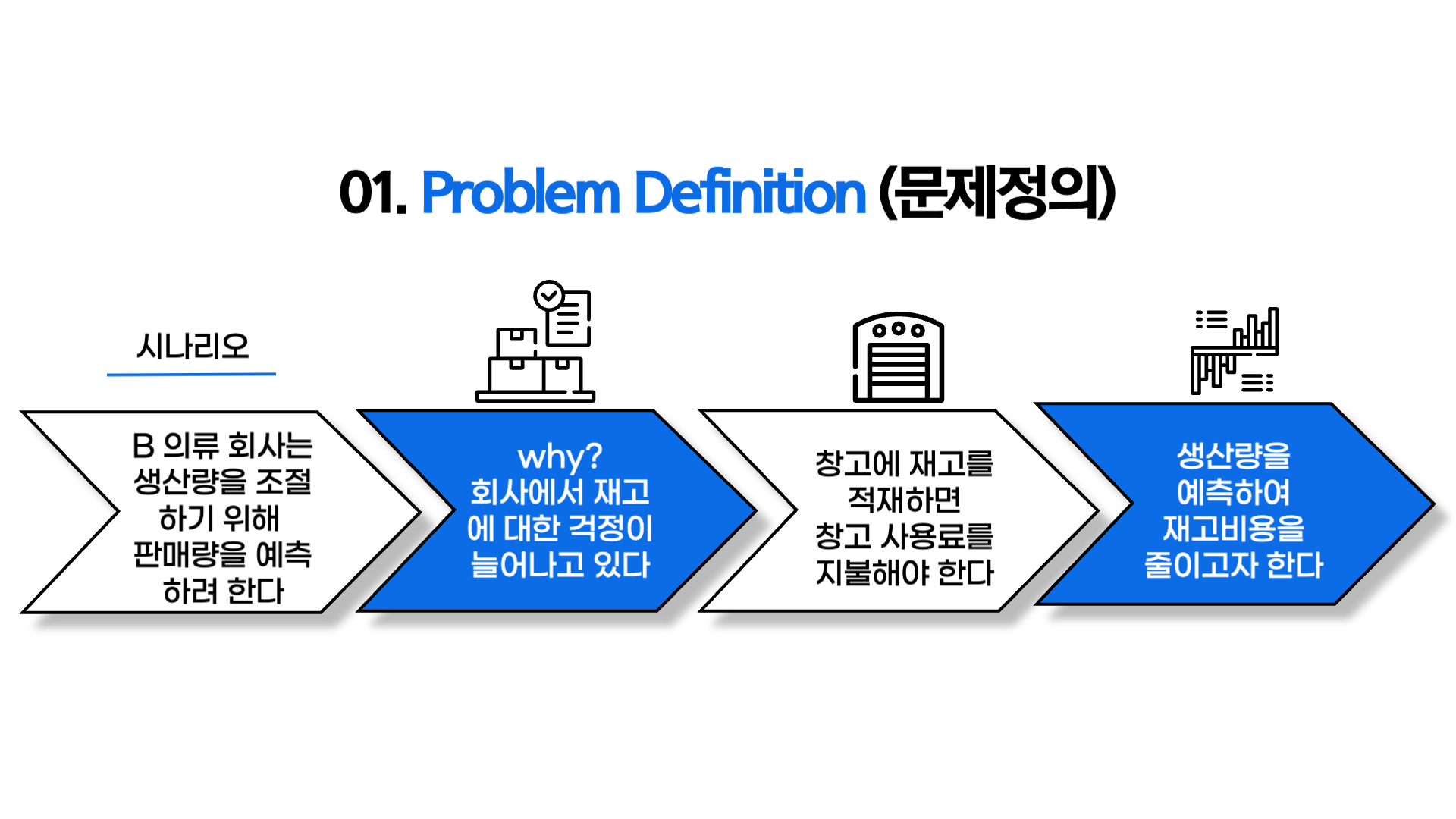
01. Problem Definition (문제정의)
- 의류를 생산할 때 대략 8주 정도의 lead time이 있는데, 이 lead time을 고려하여 생산량을 조절하여 재고비용을 줄이고자 함
- 해당 미니 프로젝트에서는 반팔옷의 생산량을 예측하는 것에 중점을 둠
02. Expected Effects (기대효과)
- 정량적으로 어떤 효과를 기대할 수 있을지 표현하고 싶었지만 더 자세한 데이터가 주어지지 않아 정성적으로만 기대효과 표현
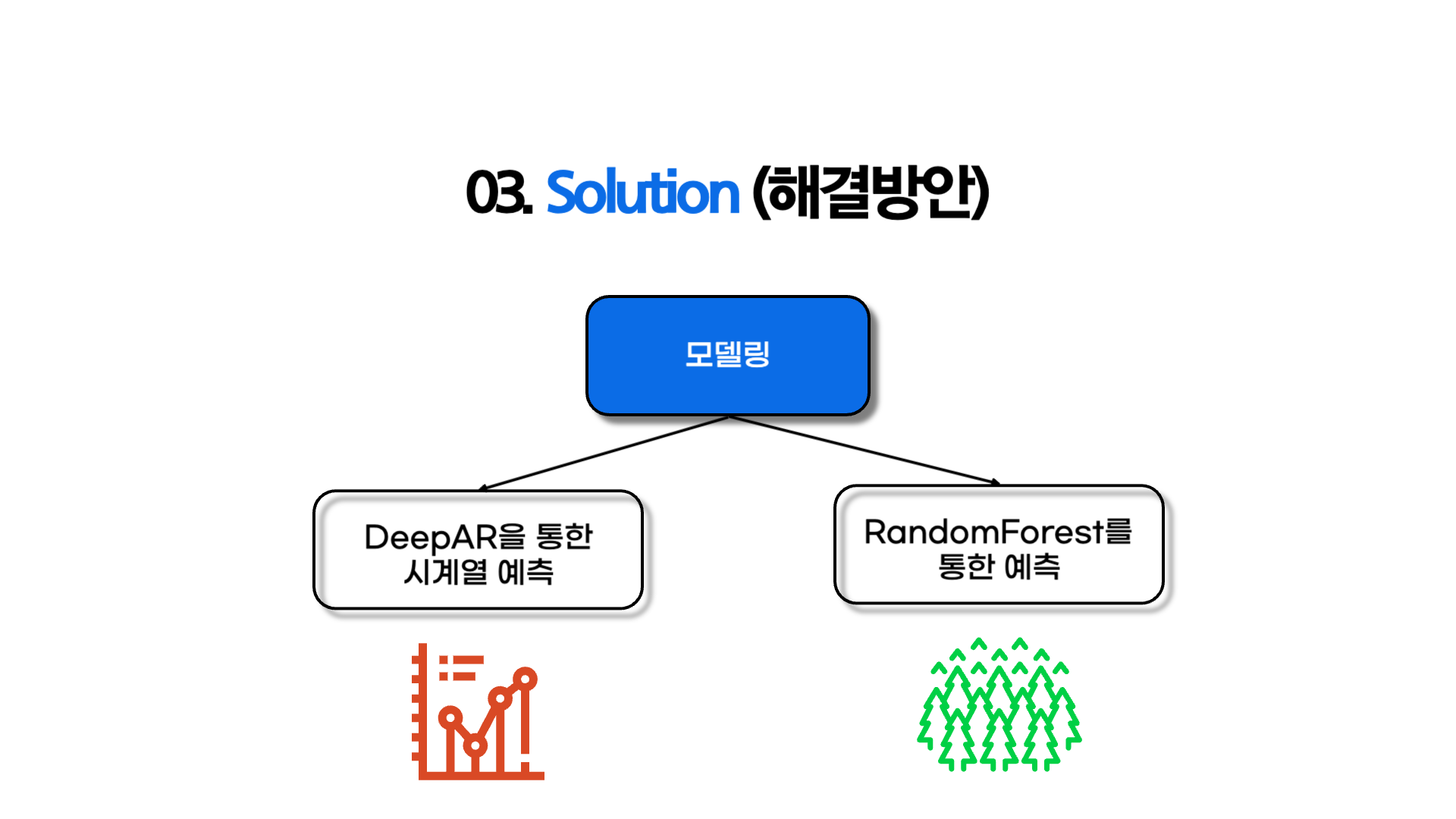
03. Solution (해결방안)
- 두가지 방식의 모델링을 통해 적정 생산량 예측
04. Priority (우선순위 결정)
- 먼저, DeepAR 모델을 통해서 시계열 분석을 진행
- 이후, 더 많은 feature들을 통해 모델링이 가능한 RandomForest를 통해 분석 진행
05. Data Analysis (데이터 분석)
- Data Check : 먼저 data를 보고 (EDA 과정) 데이터 분포 및 특징을 파악
- DeepAR Modeling : 시즌별 판매량을 예측할 수 있도록 데이터 변형 및 outlier 확인, 이후 모델을 통하여 판매량 예측
- RandomForest Modeling : 단변량 데이터를 window slice를 통해 여러개의 다변량 데이터로 변형, 이후 모델을 통하여 판매량 예측
05-1. Data Check
- Data Info Check : data의 shape, type, null values 확인
- Data Readiness Check : 시즌별 (16SS, 17SS, etc)로 groupby를 하여 시즌별 판매량을 target label로 선정
- Data sampling : 데이터가 적거나 혹은 많을 때 데이터를 수를 조정하는 단계지만, 해당 미니 프로젝트의 데이터의 수는 약 1460개로 (날짜기준) 적당하여 해당 과정은 스킵
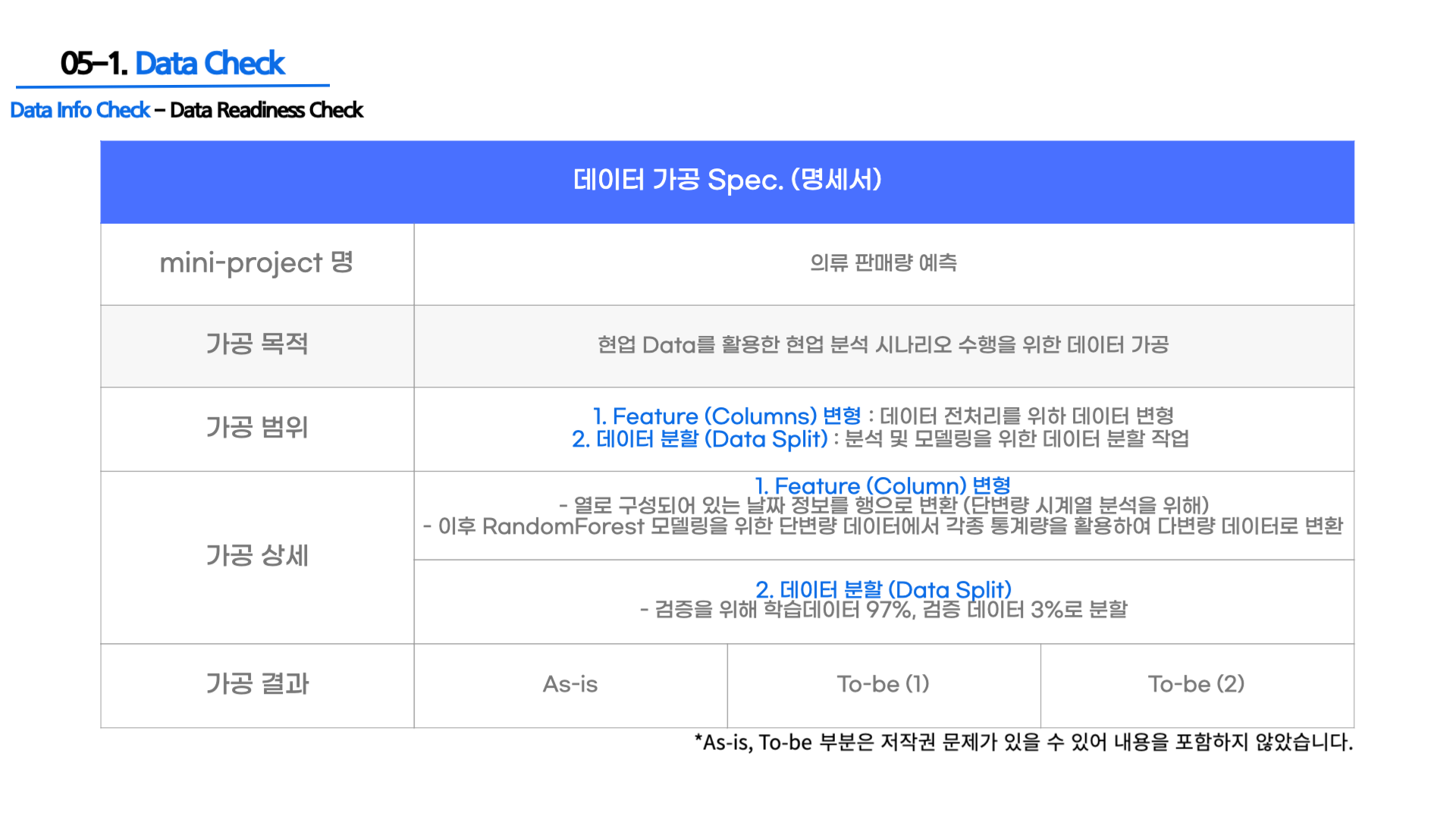
- 데이터 명세서
05-2. DeepAR Modeling
- 시계열 분석을 위해 사용할 데이터 형태 (단변량 데이터)
- 예측하고자 하는 부분 갑자기 판매량이 뚝 떨어지는 부분
- 이 부분을 예측해야 생산량을 조절하여 재고비용 축소 가능

- 그런데 outlier가 있는 경우 이 미니 프로젝트에서는 '큰손'들이 물건을 대량으로 구매 후 몇개만 구매하고 다시 대량으로 환불하는 경우 전처리 필요
- 해당 부분 처리 후 데이터 모양이 안정화 되는 것 확인
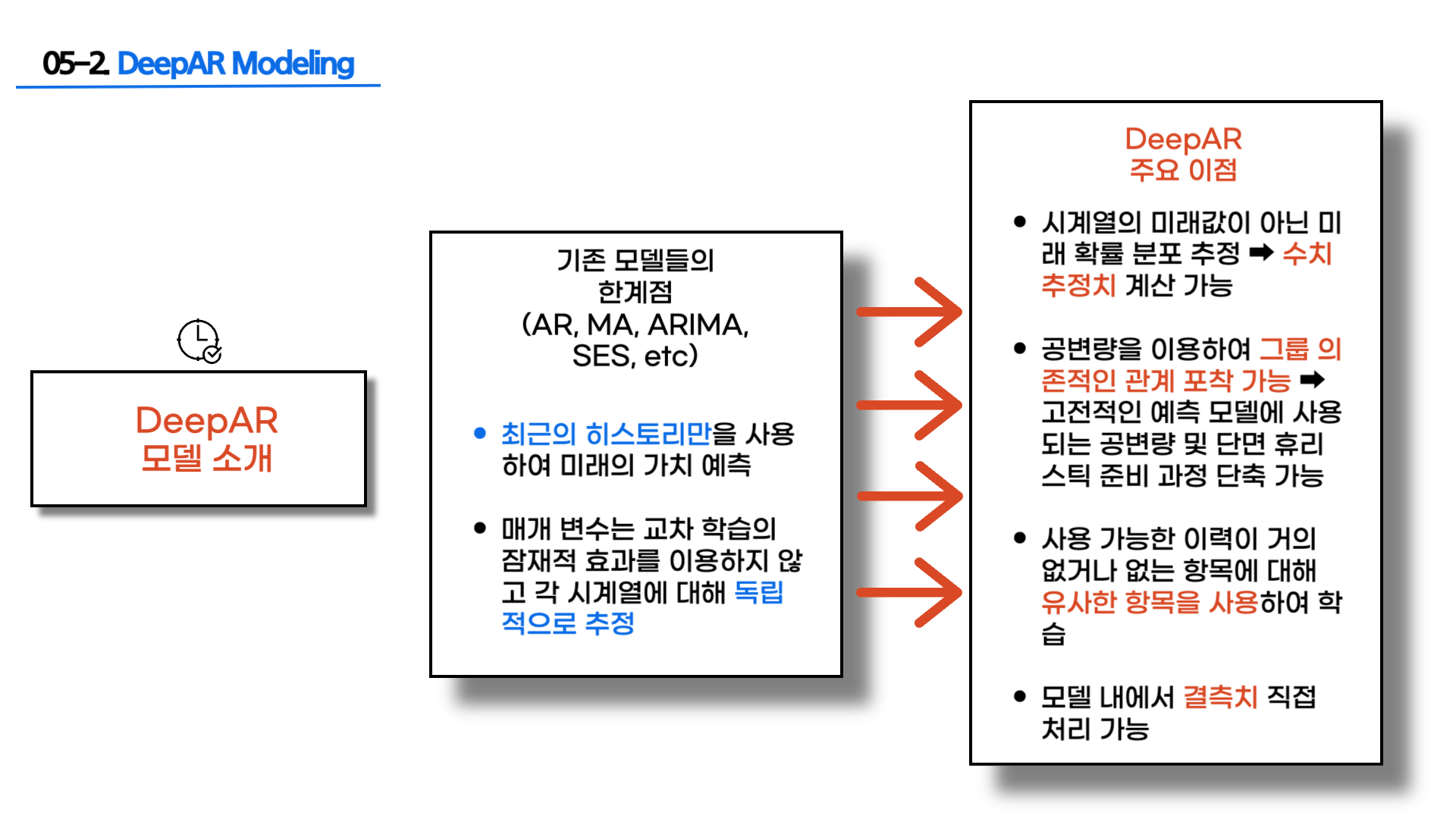
- DeepAR 모델
LSTM 기반의 확률론적 시계열 예측 딥러닝 모델
기존 통계에 기반한 모델들과 달리 수백, 수천만개의 방대한 다중 시계열 데이터 기반 예측 가능
- 사용 패키지, 진행 과정, 코드

05-3. RandomForest Modeling
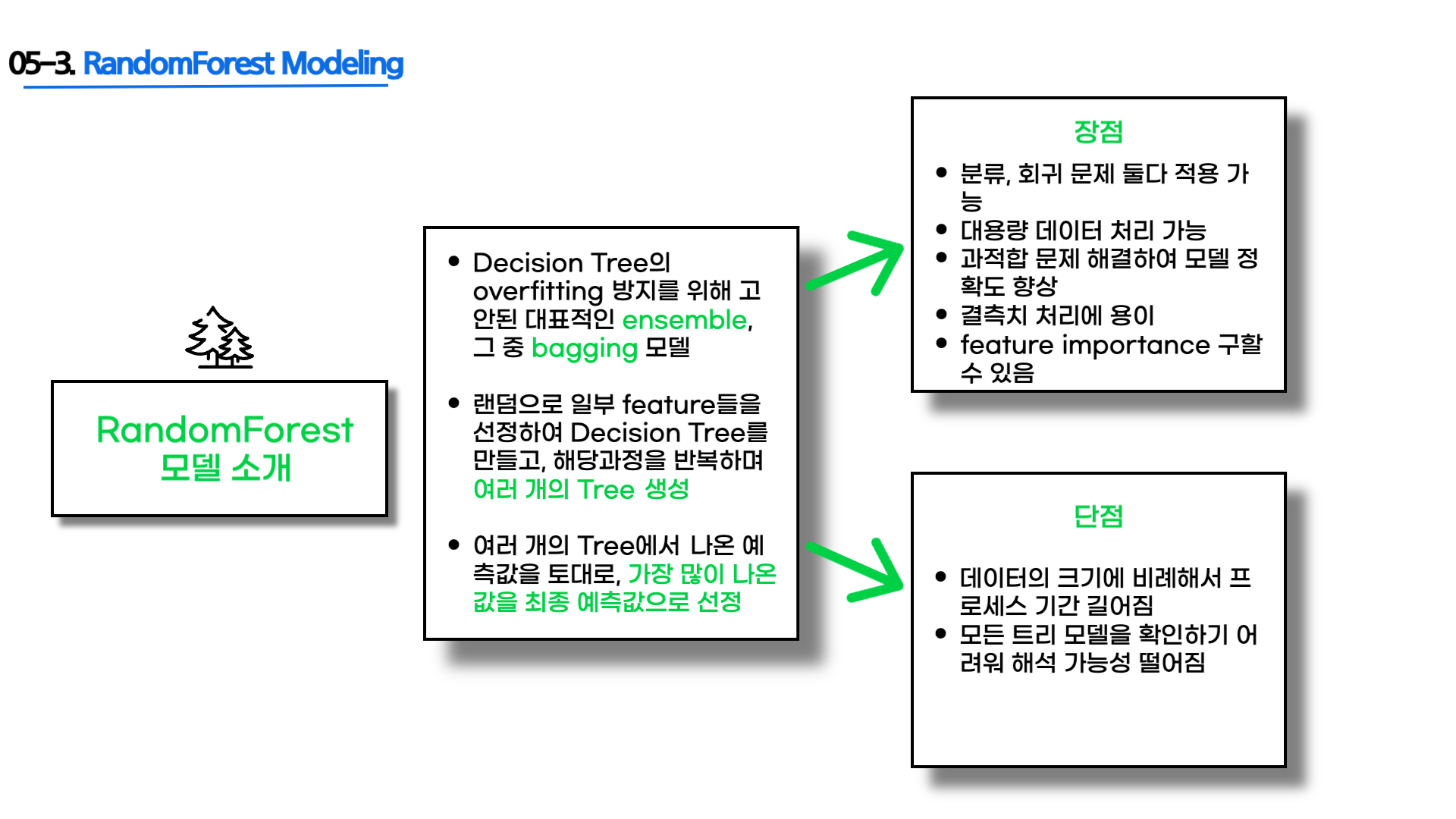
- RandomForest 모델 소개
- 모델링 이전 데이터 변환
단변량의 데이터로는 RandomForest 모델을 통해 좋은 성능을 얻기 어렵기 때문에, 다변량 데이터로 변환
기울기, 표준편차, 평균, 왜도, 첨도, 최소값, 최대값 등의 통계 기반의 feature 추출

- 사용 패키지, 진행 과정, 코드

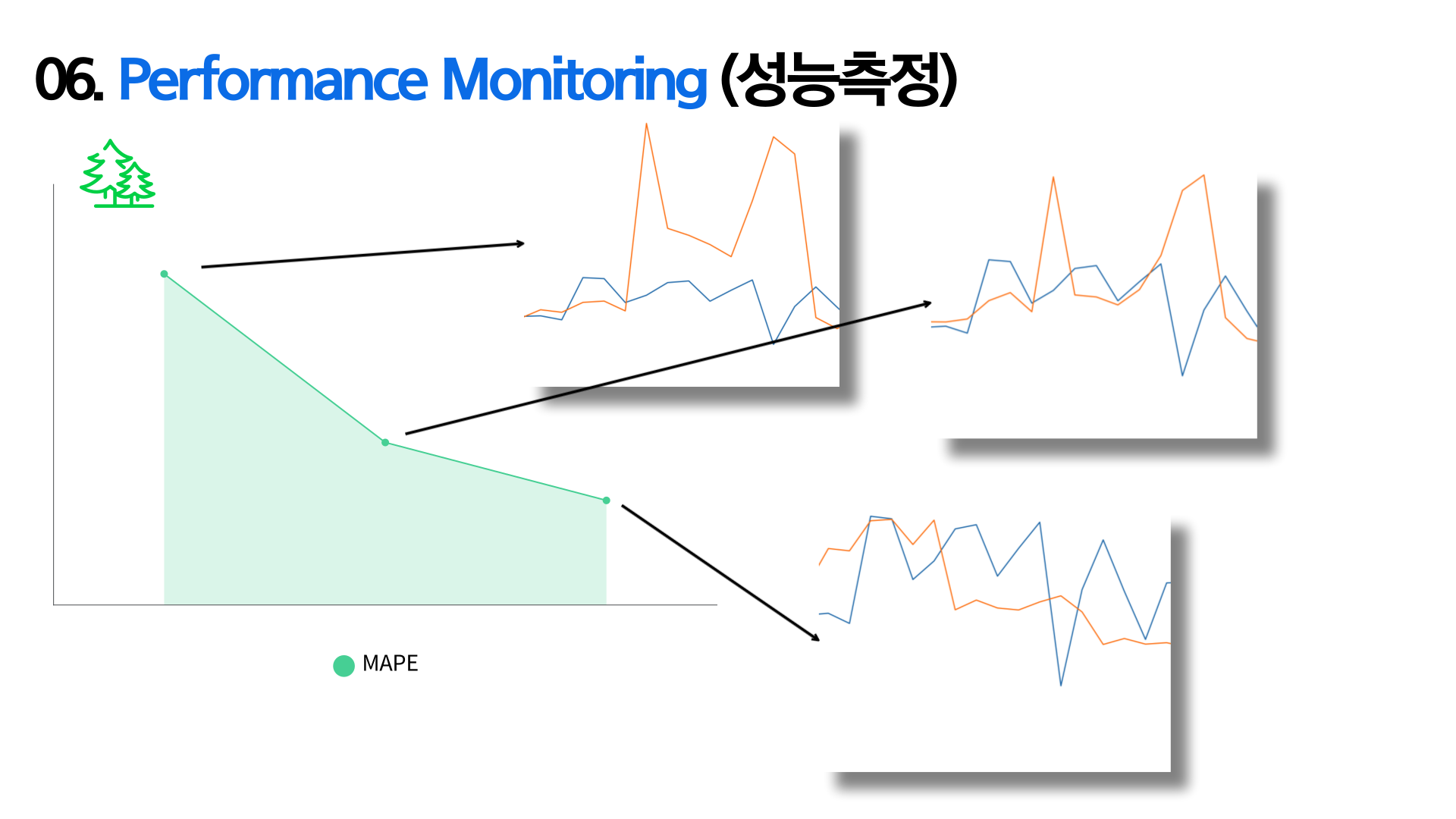
06. Performance Monitoring (성능 측정)
- RandomForest 모델 기준으로, hyper-parameter를 조절했을 때, loss가 점점 줄어드는 것을 확인 가능
- 또한, 직접 그래프로 나타냈을 때 주황색 (예측값)이 점점 파란색 선 (label 값)에 가까워지는 것을 확인
06. Lesson Learned
- 시계열 분석에서 가장 중요한 부분
- 데이터 확인이 무엇보다 중요한 분석이 시계열 분석
- 날짜형 데이터 타입을 다룰 때, 날짜 형식이 다를 수 있으므로 확인 필요 (UTC, KST) 현업에서 이러한 기본적인 것이 중요
- 날짜 사이에 결측치가 있는지 확인필요 결측치 있으면 다 틀어질 수 있음
- 모델링을 할 때, 데이터의 특성을 가장 잘 반영할 수 있는 hyper-parameter 세팅 필요
- 단변량 데이터만으로 시계열 특성이 충분히 반영되지 않을 때
- 단변량 데이터를 window size를 기준으로 다변량 feature 생성
- 요일별로 특성을 나타내는 경우 효과가 좋은 경우가 있음
- Feature를 추가할 때는 어떠한 이유 혹은 목적으로 추가하게 되었는지 설명할 수 있어야 함
- GMT, UTC, KST 정리
- GMT (Greenwich Mean Time)
- 영국의 그리니치 천문대를 기준으로 태양의 위치를 측정하여 만든 표준시
- UTC (Coordinated Universal Time)
- 세계 표준시 (GMT는 주로 영국 등 일부 국가에서만 이용하는 시간대)
- KST (Korean Standard Time)
- UTC + 9:00
- ex) UTC 9:00 ➡ KST 18:00
- UTC + 9:00
- GMT (Greenwich Mean Time)
*참고자료
- 시계열 예측을 위한 딥러닝 : DeepAR 모델 설명 자료
- deepar_fit_impl: GluonTS DeepAR Modeling Function (Bridge) : DeepAR hyper-parameter 설명 자료
- 3주차 DeepAR 논문 리뷰 : (by tobigsts1617) DeepAR 작동과정에 관한 논문 리뷰
- RandomForest : (by ehlim@insilicogen.com) RandomForest 모델 설명 자료
- 랜덤포레스트 모델(Random Forest Model) : RandomForest 모델 설명 자료
여기까지 읽어주신 분이 계시다면 부족하지만 감사드립니다:)

차가운 머리와 따뜻한 마음