
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 각색하여 복습을 위해 작성하였습니다.
개요
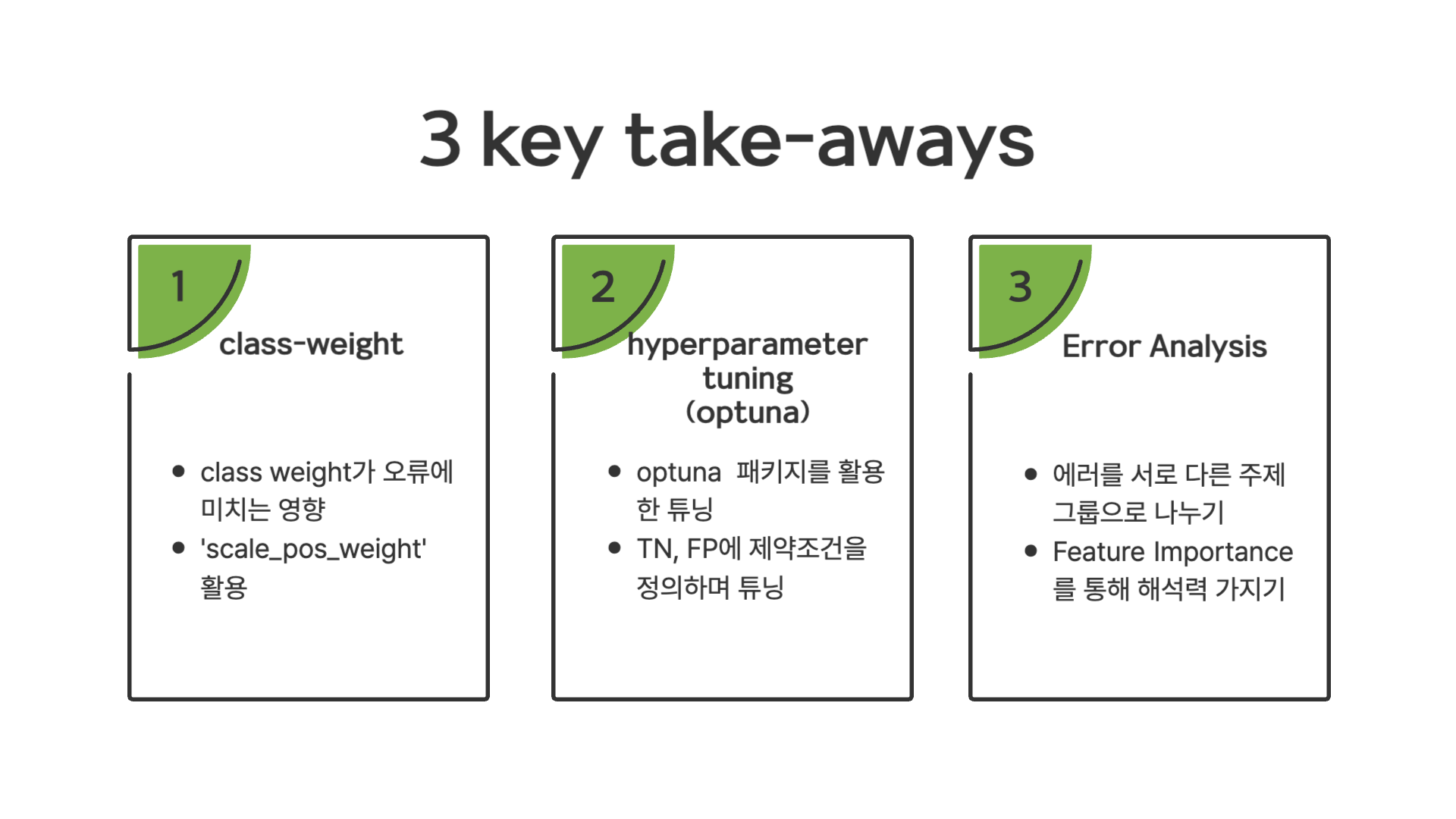
이번 미니 프로젝트를 진행하며 중요하게 배운 내용 크게 3가지를 정리하면
- class weight를 조절하며 confusion matrix에서 오류가 어떻게 변하는지를 확인할 수 있었고,
- optuna 패키지를 통해 baseline 모델의 하이퍼 파라미터 튜닝법과 True Negative, False Positive에도 제약 조건을 같이 주며 튜닝하는 방법과,
- baseline 모델에서 groupby를 통해 그룹별로 나누며 각 그룹 내에서의 모델 성능 및 오류는 어떻게 변하는지와 feature들이 모델에 끼치는 영향을 분석하는 방법
이 3가지를 배웠습니다.
다음 파트부터는 전체적인 미니 프로젝트를 진행하며 해당 take-aways들을 어떻게 활용했는지 소개해드리겠습니다.
프로젝트 진행과정
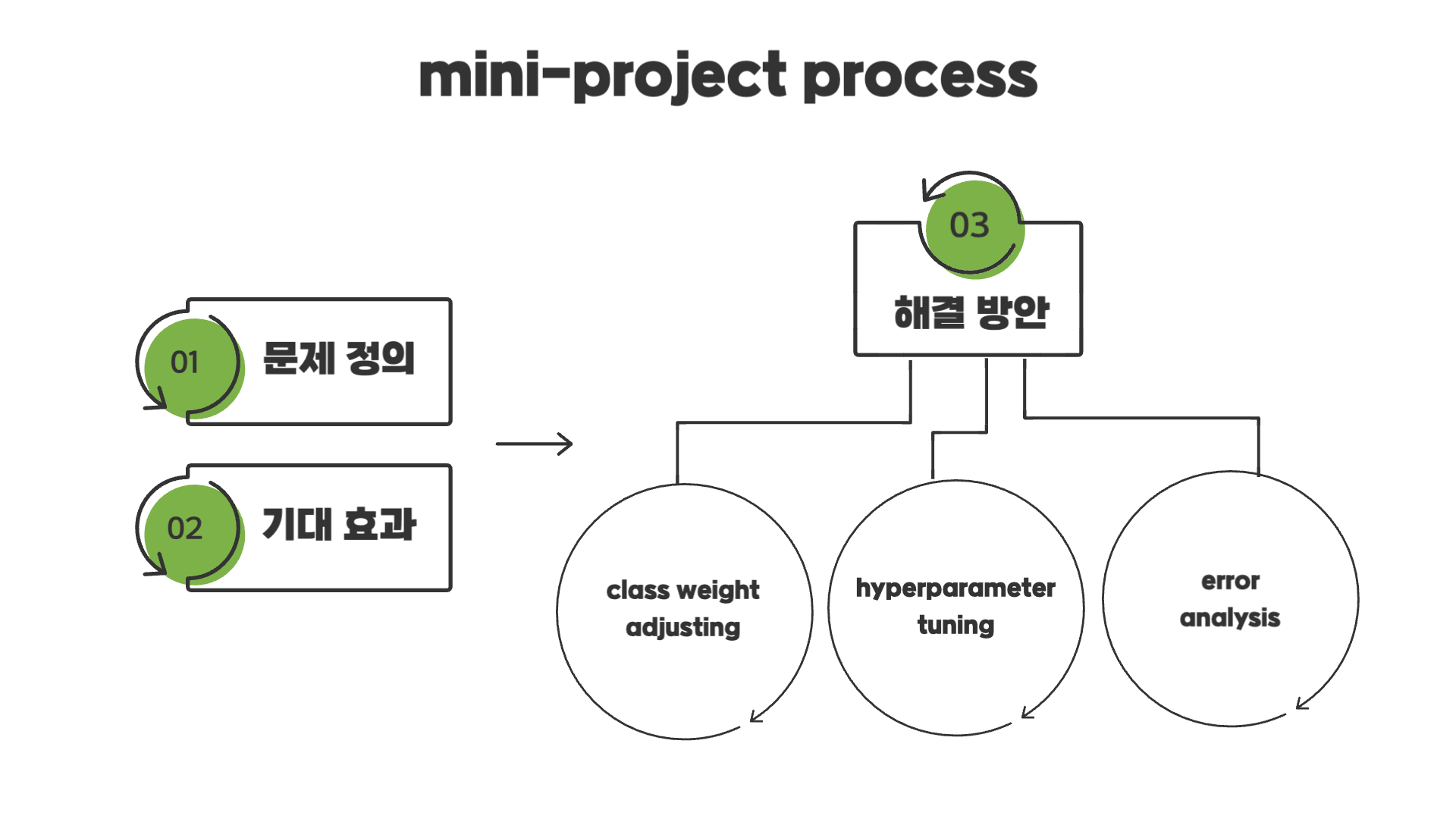
먼저 문제 정의와 문제 해결에 따른 기대효과에 대한 부분을 간략하게 소개할 예정입니다. 그 다음 위에서 언급했던 class weight, hyperparameter tuning, error anlaysis가 어떻게 해결방안으로서 작동하는지 소개하고자 합니다.
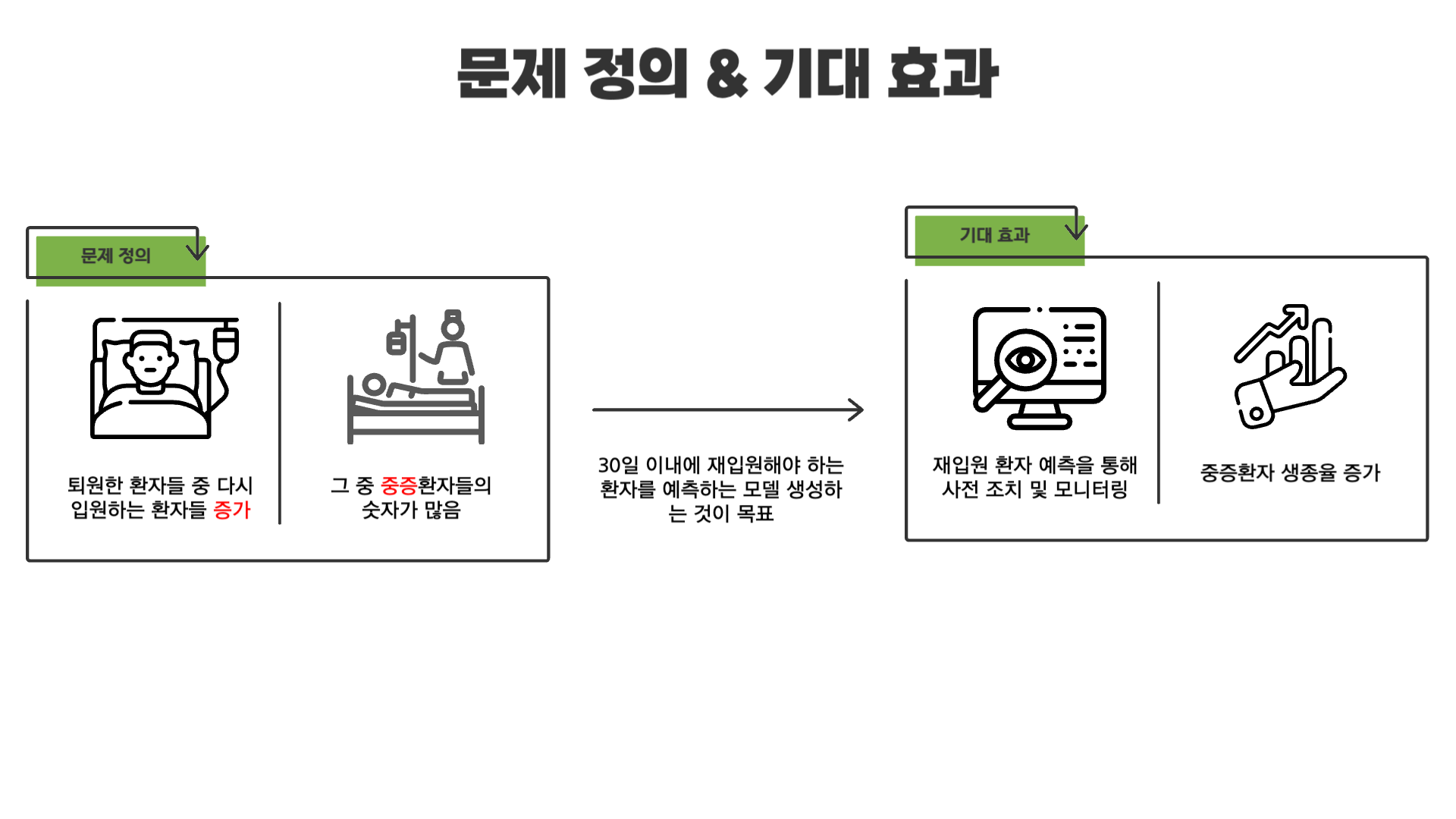
01. 문제 정의 및 기대효과
02. Class Weight Adjustment
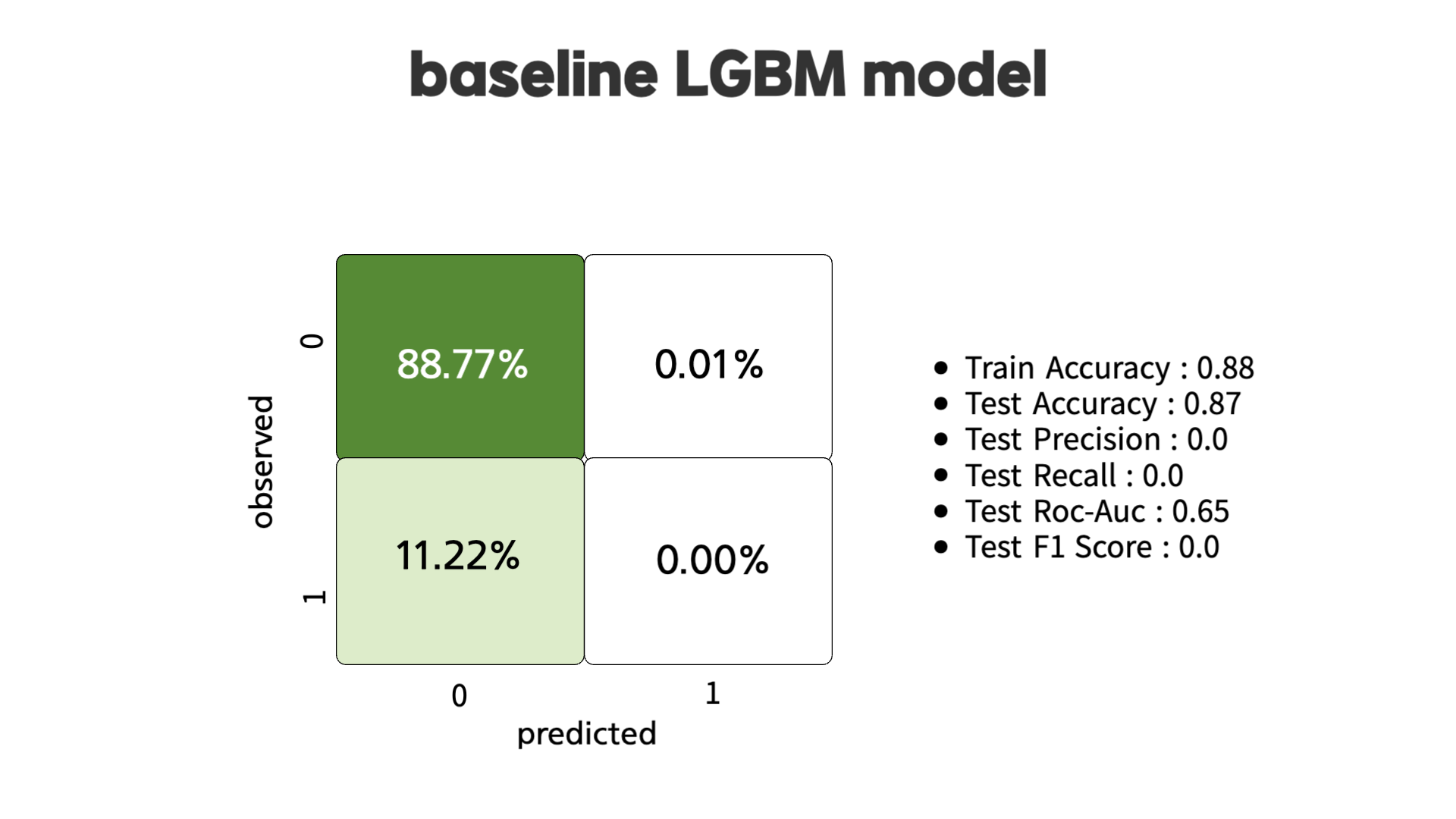
class weight에 들어가기 앞서 먼저 baseline 모델의 경우 (LightGBM) 정확도는 약 88%로 좋은 성능을 보입니다. 하지만, Precision이나 Recall 점수는 매우 낮아 전반적인 성능은 떨어진다. 때문에 sample weight조절하여 Precision과 Recall 점수를 높이고자 합니다.
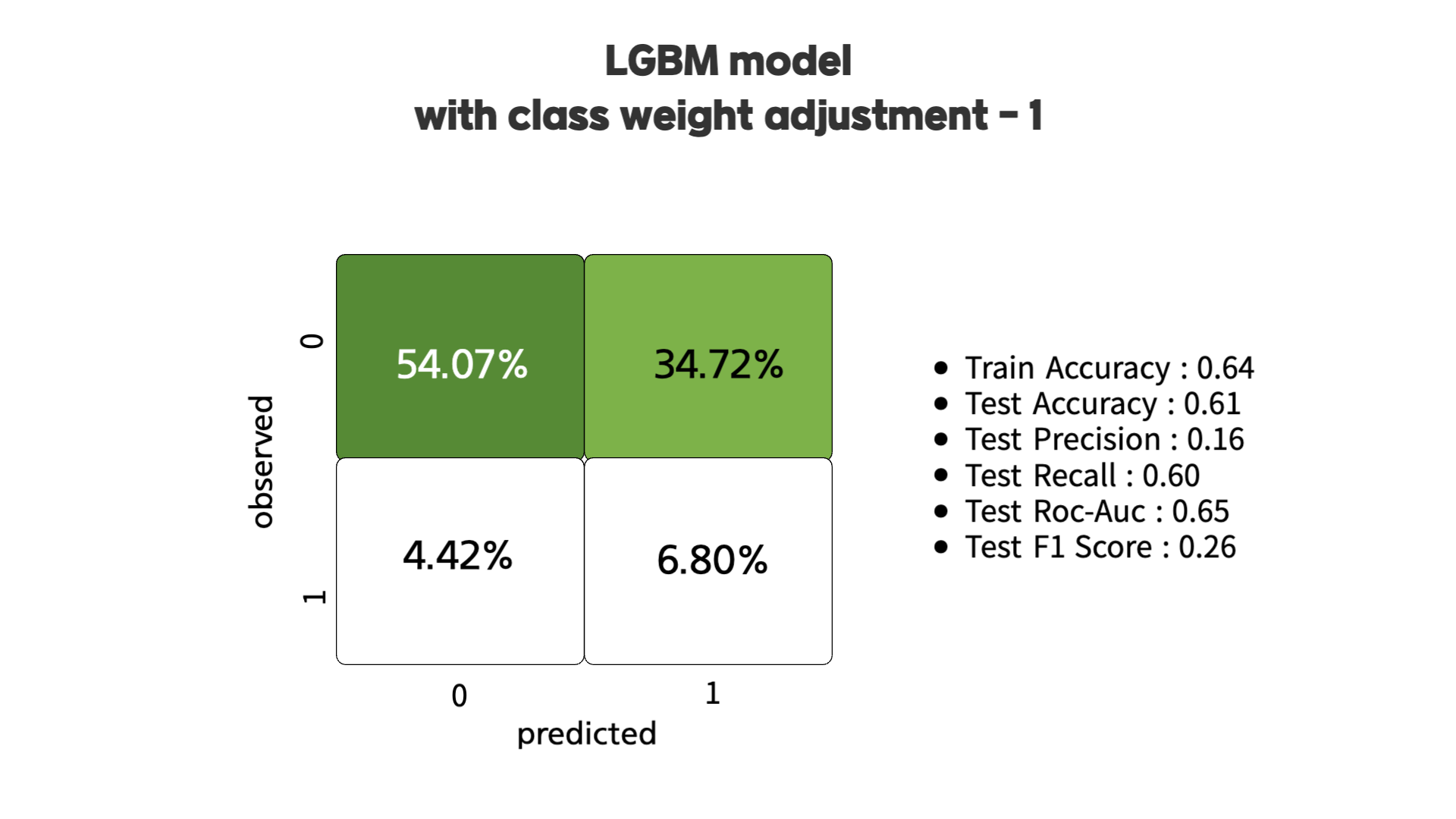
모델은 기본적으로 positive 클래스를 예측할 때 보수적인 접근 방식을 활용해 모델을 생성하여 너무 많은 위험을 감수하지 않는다고 합니다. 이에 대한 해결책은 positive 클래스에 더 많은 비중을 두도록 강제하는 hyperparameter를 활용하는 것이라고 합니다. 그 중 하나인 'scale_pos_weight'를 활용할 수 있습니다.
보통 많이 사용하는 수식은 아래와 같습니다.
(# of negative samples) / (# of positive samples)해당 내용을 적용하면 위의 그림과 같이 confusion matrix가 나오는데, Precision & Recall 점수가 향상된 것을 확인할 수 있습니다. 하지만 상당한 수준의 오탐지가 존재하는 것 또한 발견할 수 있습니다.
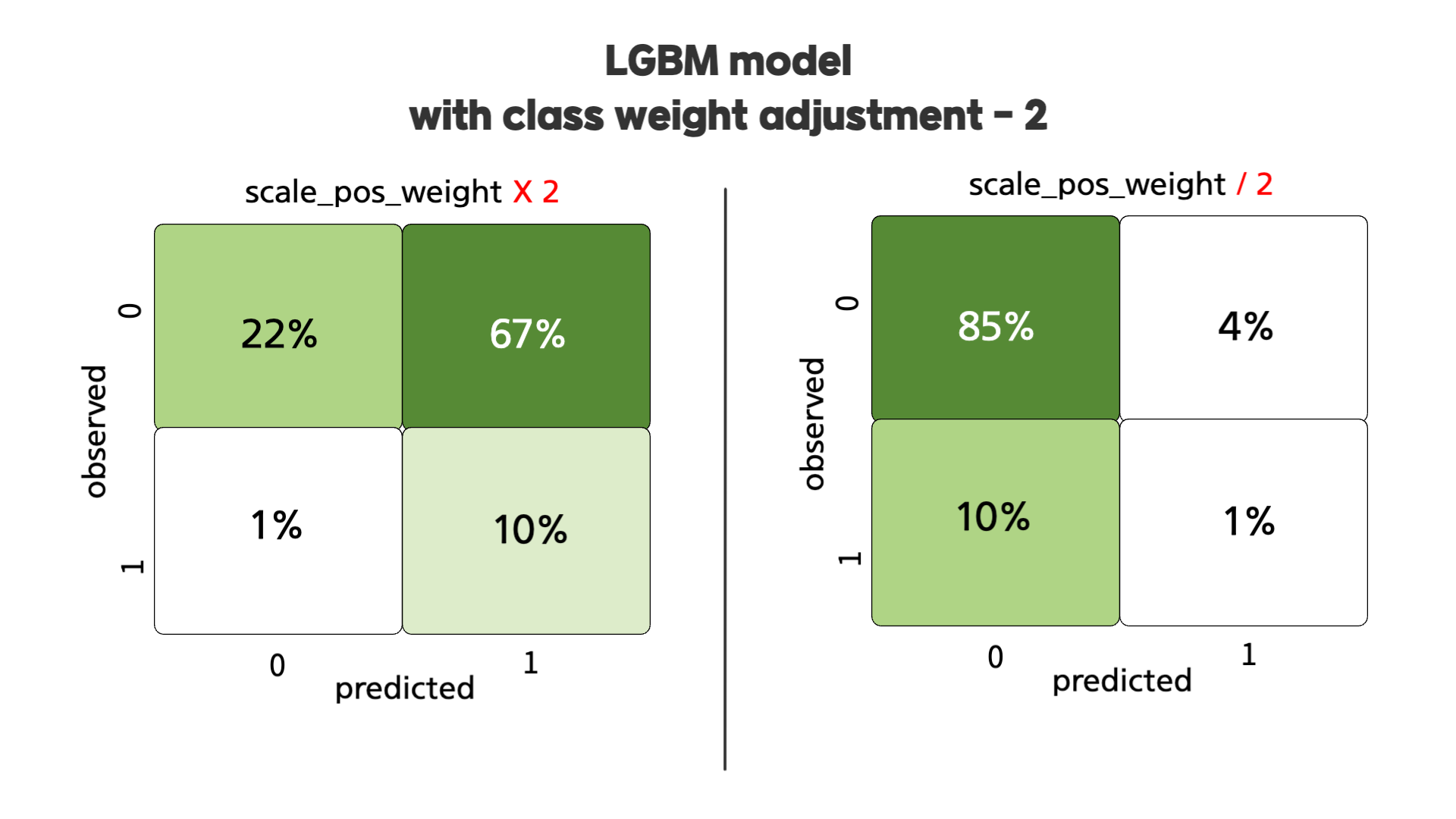
다음으로, 위의 confusion matrix는 'scale_pos_weight'를 두배 혹은 반으로 줄였을 때의 값을 나타냅니다. 두배로 늘렸을 때는 오탐지도 두배가 늘어나는 것을 확인할 수 있었습니다. 반대로, 반으로 줄였을 때는 첫번째 baseline 모델과 비슷하게 모델이 더 보수적으로 바뀌는 것을 확인할 수 있었습니다.
다음으로는 class weight를 포함하여 hyperparameter tuning이 어떻게 진행되었는지 소개해드리겠습니다.
03. Hyperparameter tuning
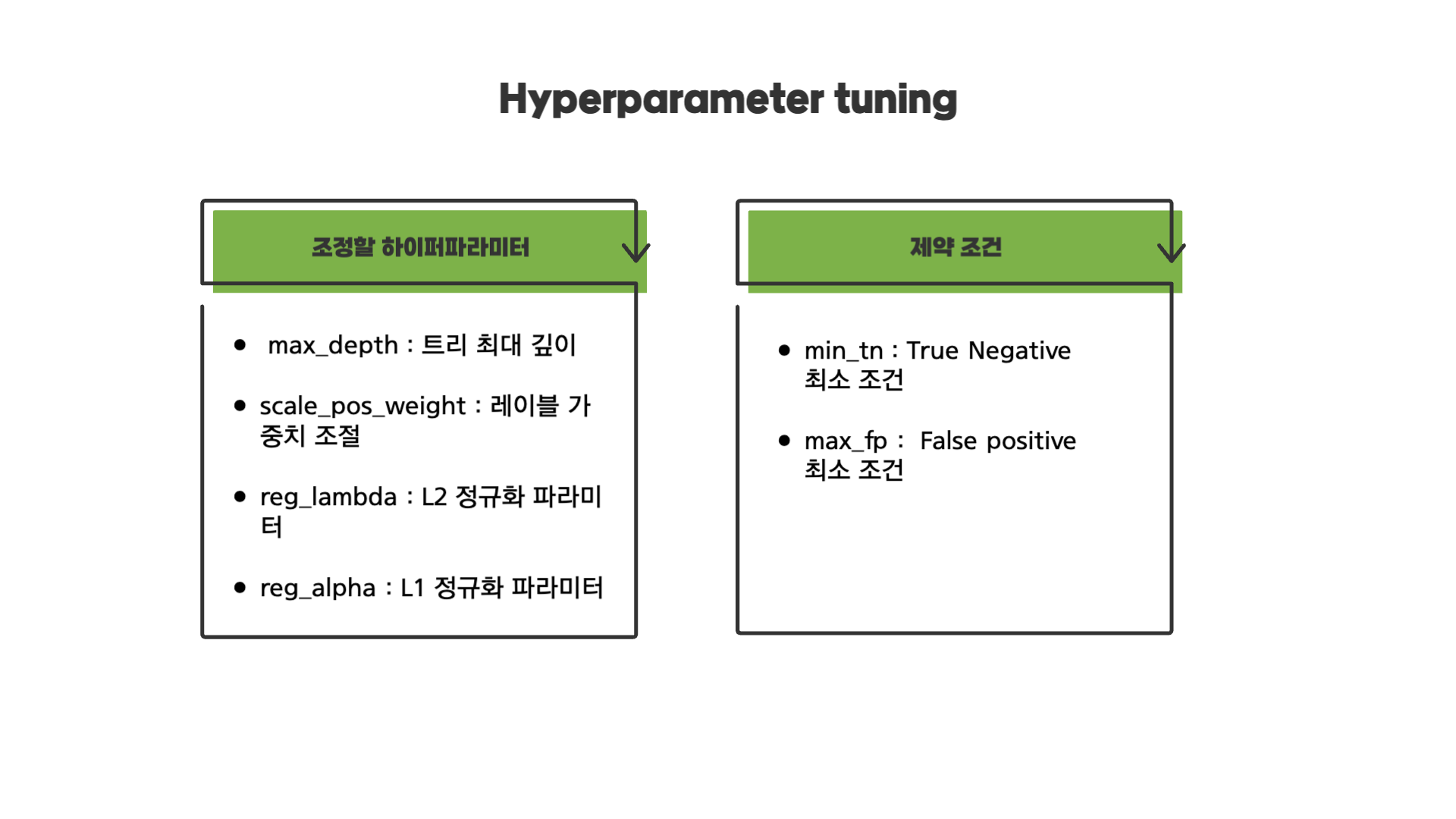
해당 미니 프로젝트에서 조절한 하이퍼 파라미터는 위와 같이 4개를 조정하였습니다. optuna 패키지를 사용하여 최적화를 실행하였습니다.
이와 동시에 True Negative와 False Positive 제약조건을 주어 하이퍼 파라미터 최적화를 했습니다. 제약 조건을 준 이유는 보수적으로 모델은 True Positive(정탐)을 최대화하고 False Positive(미탐)을 최소화하도록 훈련을 합니다. 그렇다면 이 방법은 거의 모든 것이 Positive 클래수에 속할 것으로 예상되는 문제가 있습니다.
이 문제를 해결하기 위해 재입원하지 않은 모든 데이터를 포함할 수 있도록 충분한 True Negative(정음성)이 있어야 한다고 합니다. 또한 30일이 지나서 재입원한 환자도 False Positive에 포함되도록 비율을 조정했습니다.
그래서, 실제 재입원을 하지 않은 사람들의 비율 (해당 미니 프로젝트에서는 53.91%)를 True Negative의 최소조건으로 설정하고, 30일이 지나서 재입원을 한 환자도 False Positive의 최대조건 (34.93%)으로 설정하여 하이퍼 파라미터 튜닝을 했습니다.
(참고로 30일 이내로 재입원한 환자의 레이블은 1, 재입원하지 않았거나 30일 이후에 재입원을 한 환자들의 레이블은 0 입니다.)
그에 대한 결과를 아래와 같습니다.

하지만 여기가 마지막 단계는 아닙니다. 현재까지의 결과가 최선일까라는 질문과 함께 에러 분석을 실시하였습니다.
04. Error Analysis by Group
모델 전체적으로 보면 True Positive는 7%이지만, 그룹별로 나누었을 때 어떻게 나오는지 확인해보겠습니다.
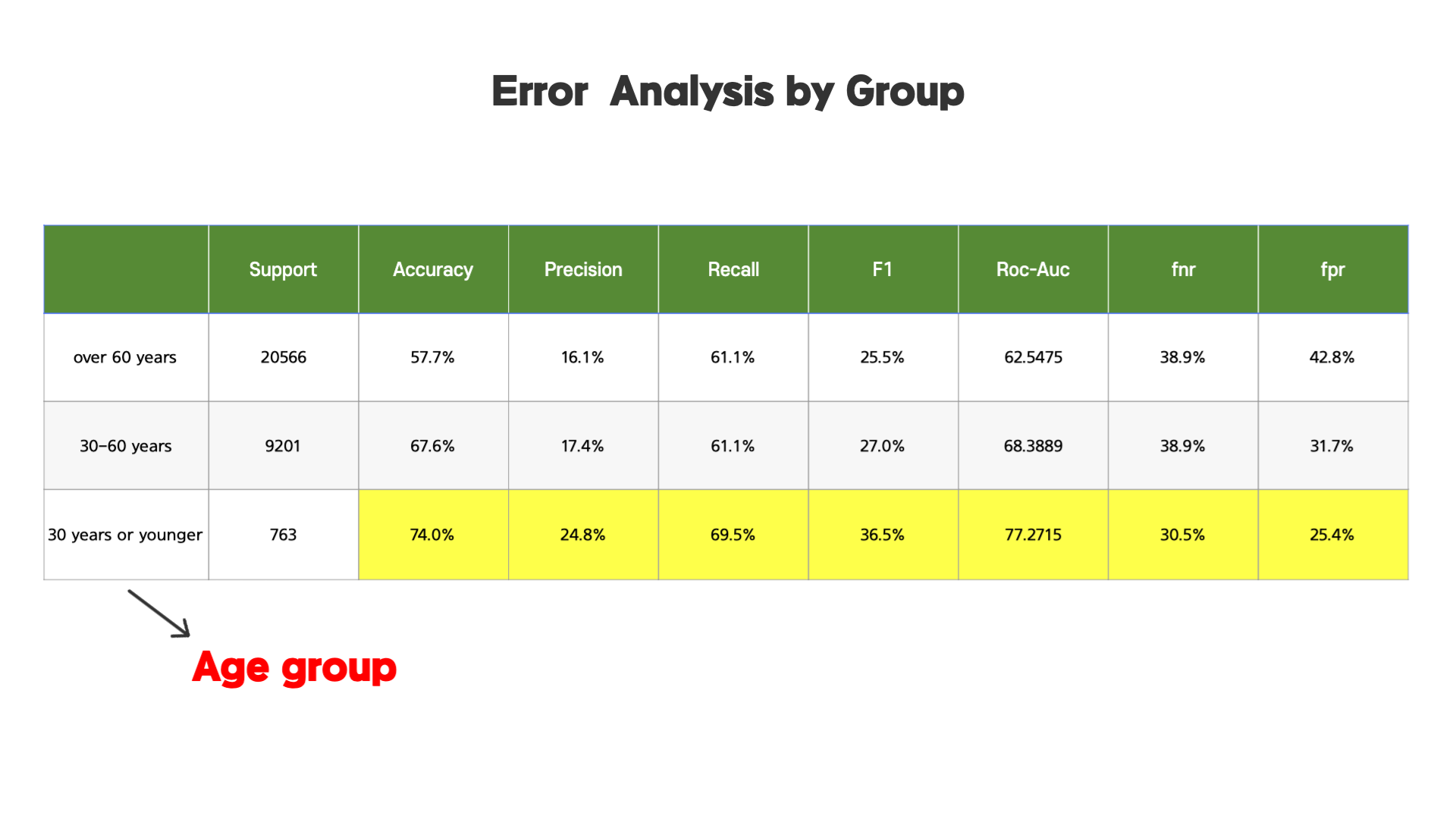
나이 그룹으로 나누었을 때, 30대이거나 젋은 그룹에 대해서 모델의 정확도, 정밀도 등등이 더 높은 것으로 나타났습니다. 이 결과를 통해 해당 모델을 특정 그룹에만 적용하는 것을 고려해볼 수 있습니다.
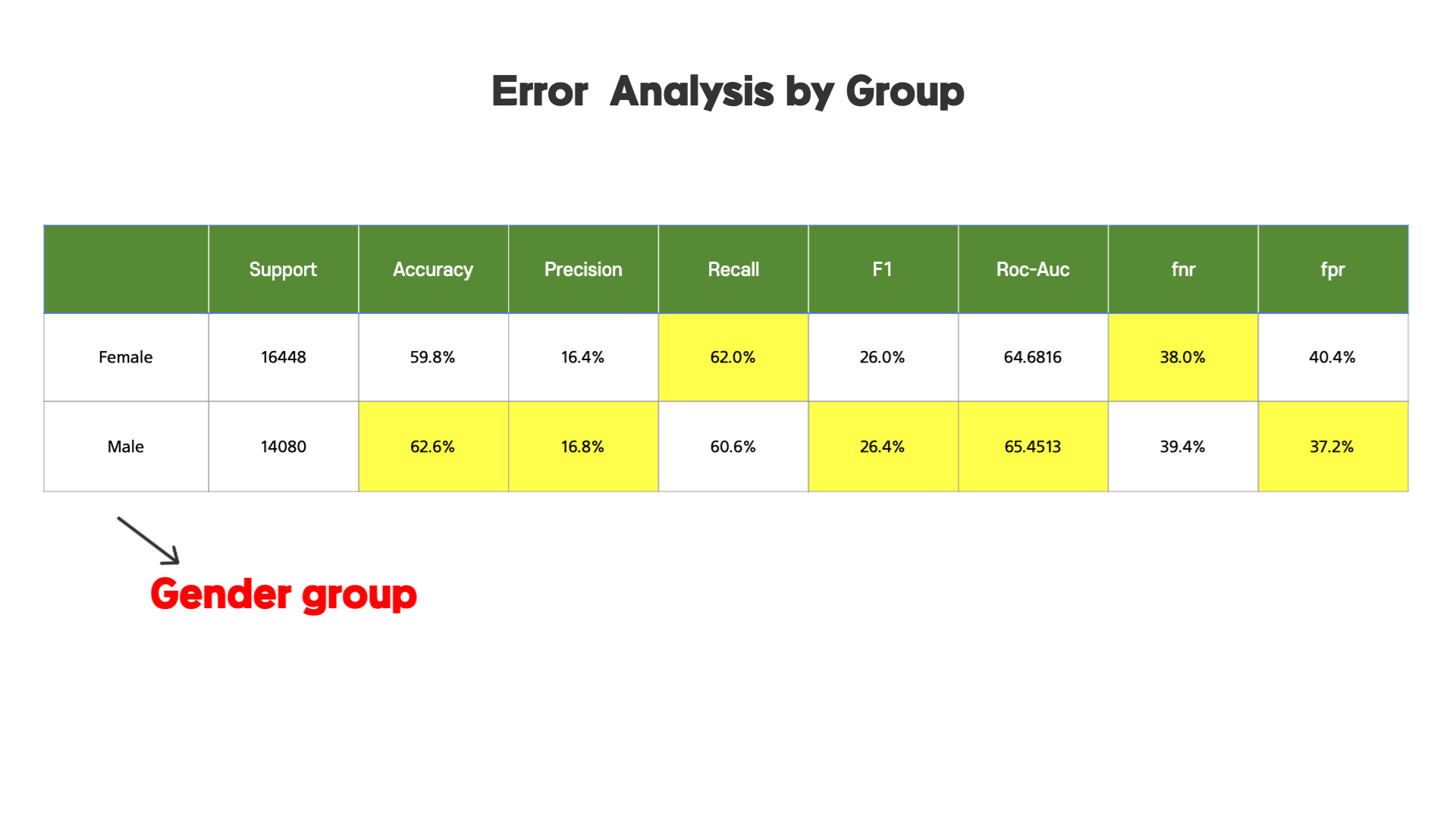
다음으로 성별 그룹으로 나누었을 때, 서로 높은 수치가 있긴 하지만 큰 차이는 없어보입니다. 이 부분을 confusion matrix로 비교하면 아래와 같습니다.
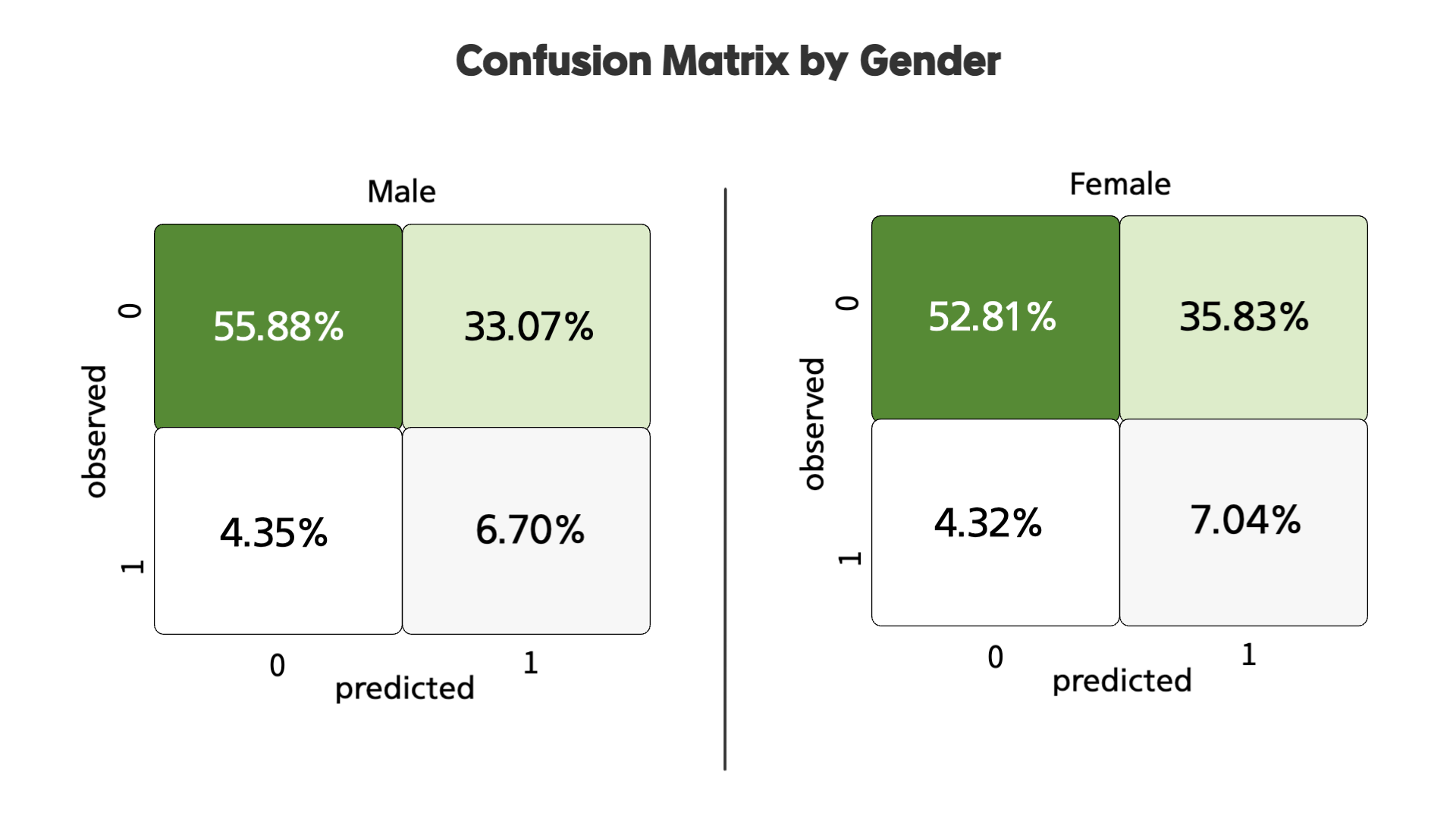
서로 큰 차이가 없는 것을 확인할 수 있습니다. 이를 통해 남녀 사이에는 유의미한 차이가 있지 않다는 것을 알 수 있습니다.
다음으로 도메인 지식 기준, 즉 몇가지 의학적 특징을 통한 분석을 보도록 하겠습니다.
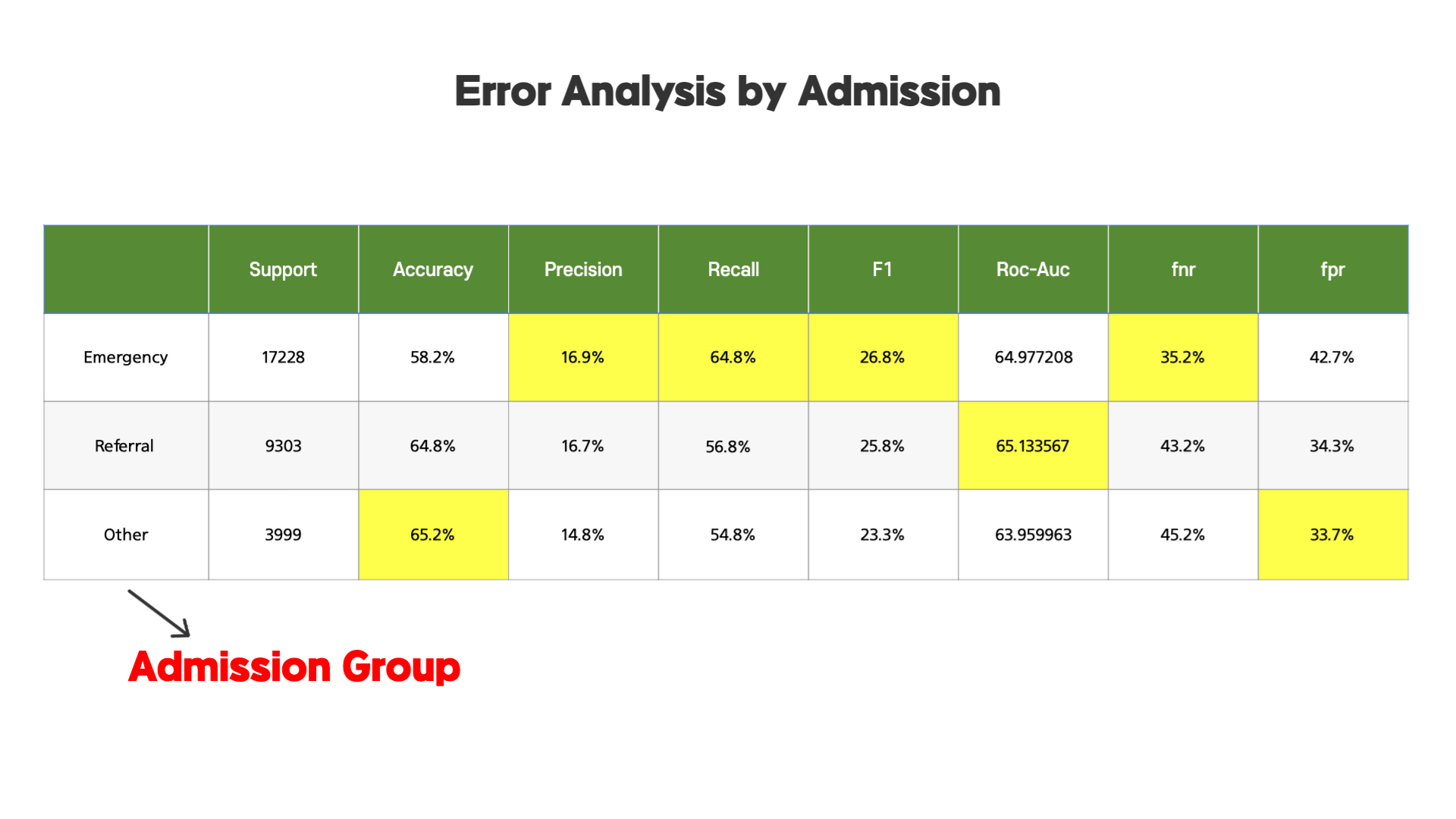
첫번째로 병원 접수 종류에 따라 구분된 그룹 Error Analysis 입니다. Emergency는 응급, Referral 다른 병원에서 온 2차 진료 환자들, Other은 다른 접수 종류들입니다.
해당 표를 보면, 응급 환자들의 경우에 Precision, Recall, F1 Score 등이 높은 것으로 보아, 해당 모델을 응급 환자들의 경우에 적용하면 더 좋은 성능을 보일 수 있다는 것을 확인할 수 있었습니다.
두번째로, 병원에서 입원을 했는지에 대한 유무에 따른 그룹으로 나누어 Error Analysis를 해보면,
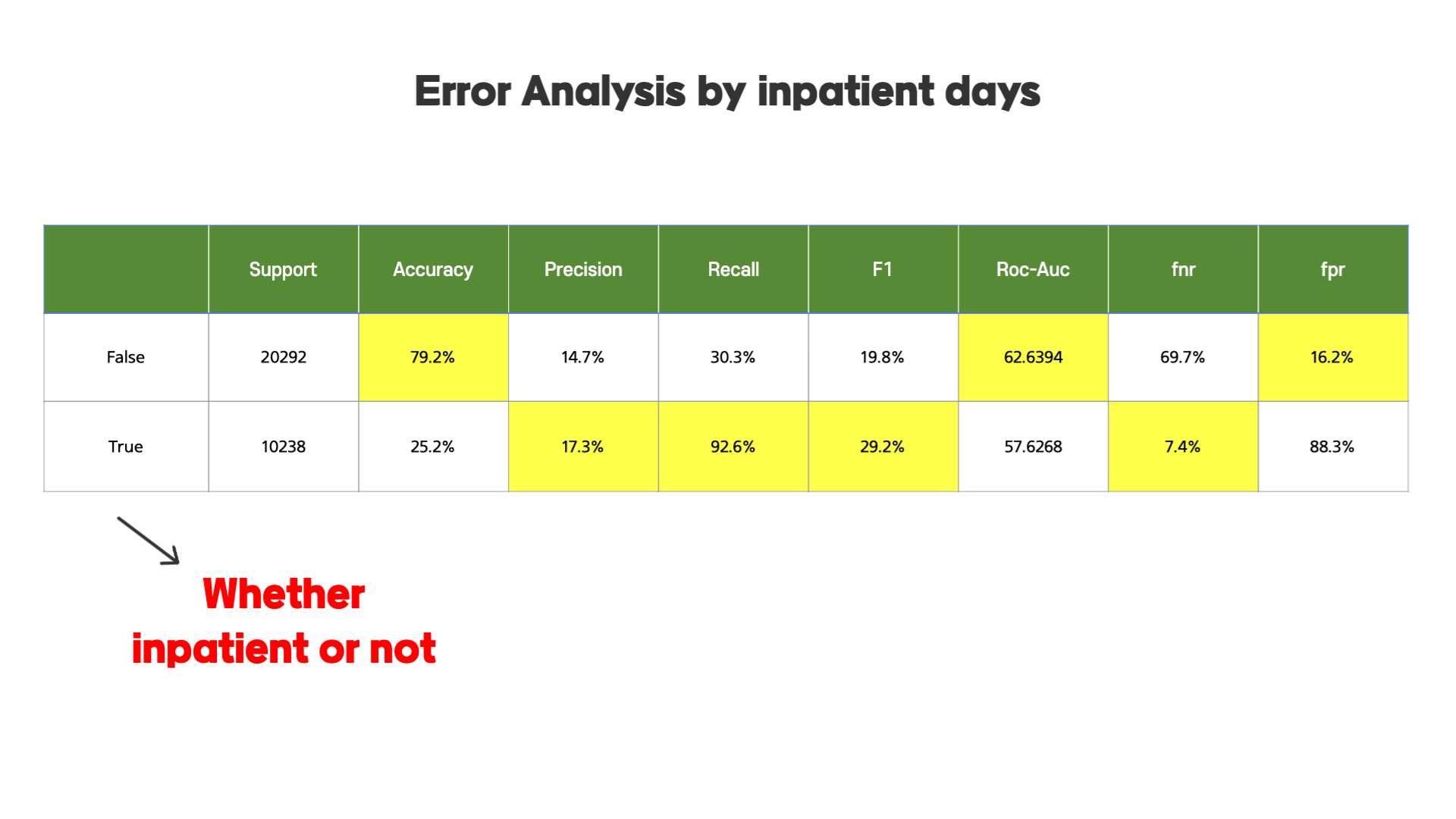
두 그룹의 차이가 꽤 명확하게 나타나는 것을 확인할 수 있습니다. 이 두 그룹에 대한 confusion matrix를 그려보면,
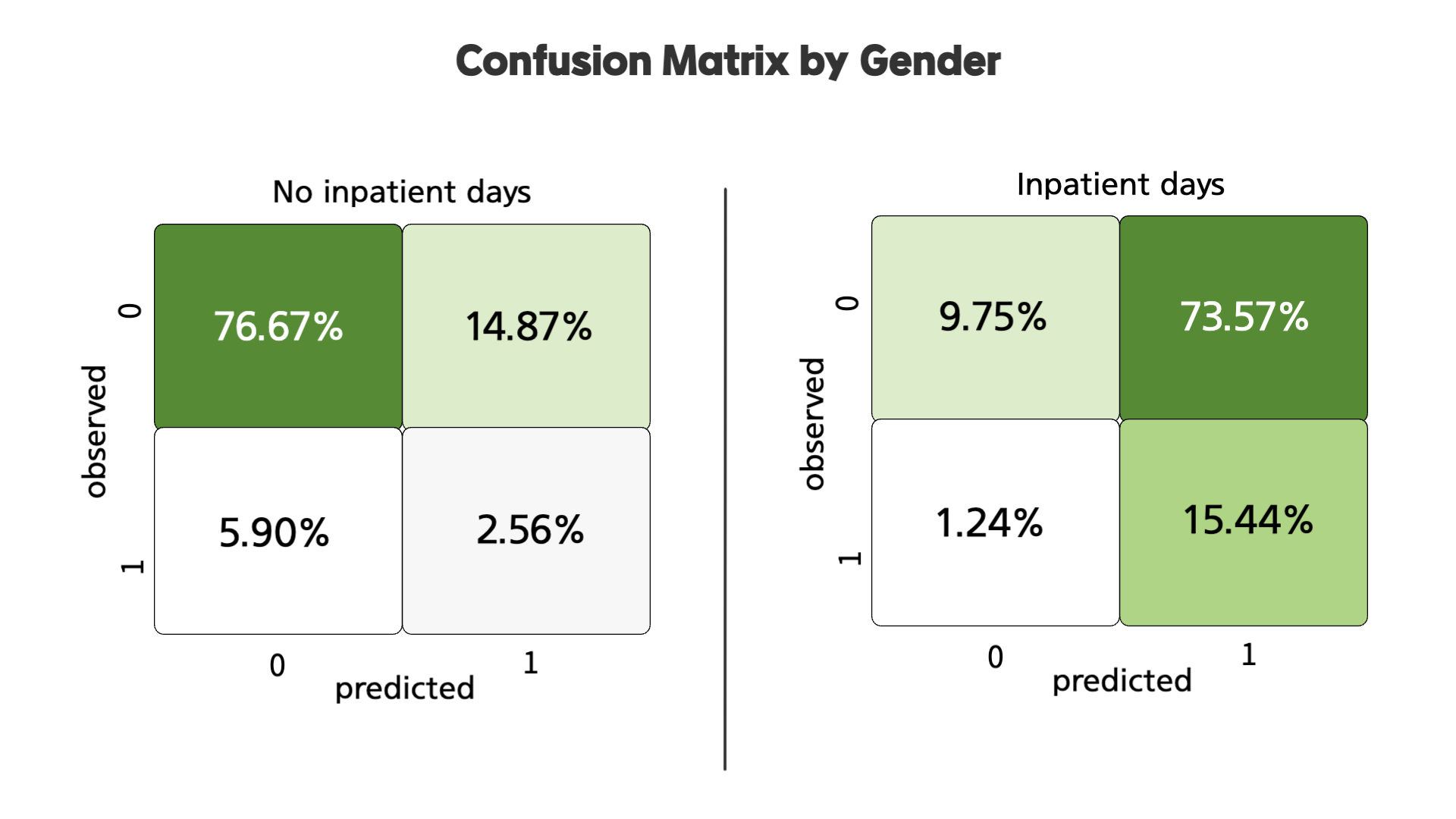
두 그룹의 차이가 크다는 것을 확인할 수 있습니다.
05. Feature Importance
다음으로 Shapley value를 통해 feature importance를 보았습니다.
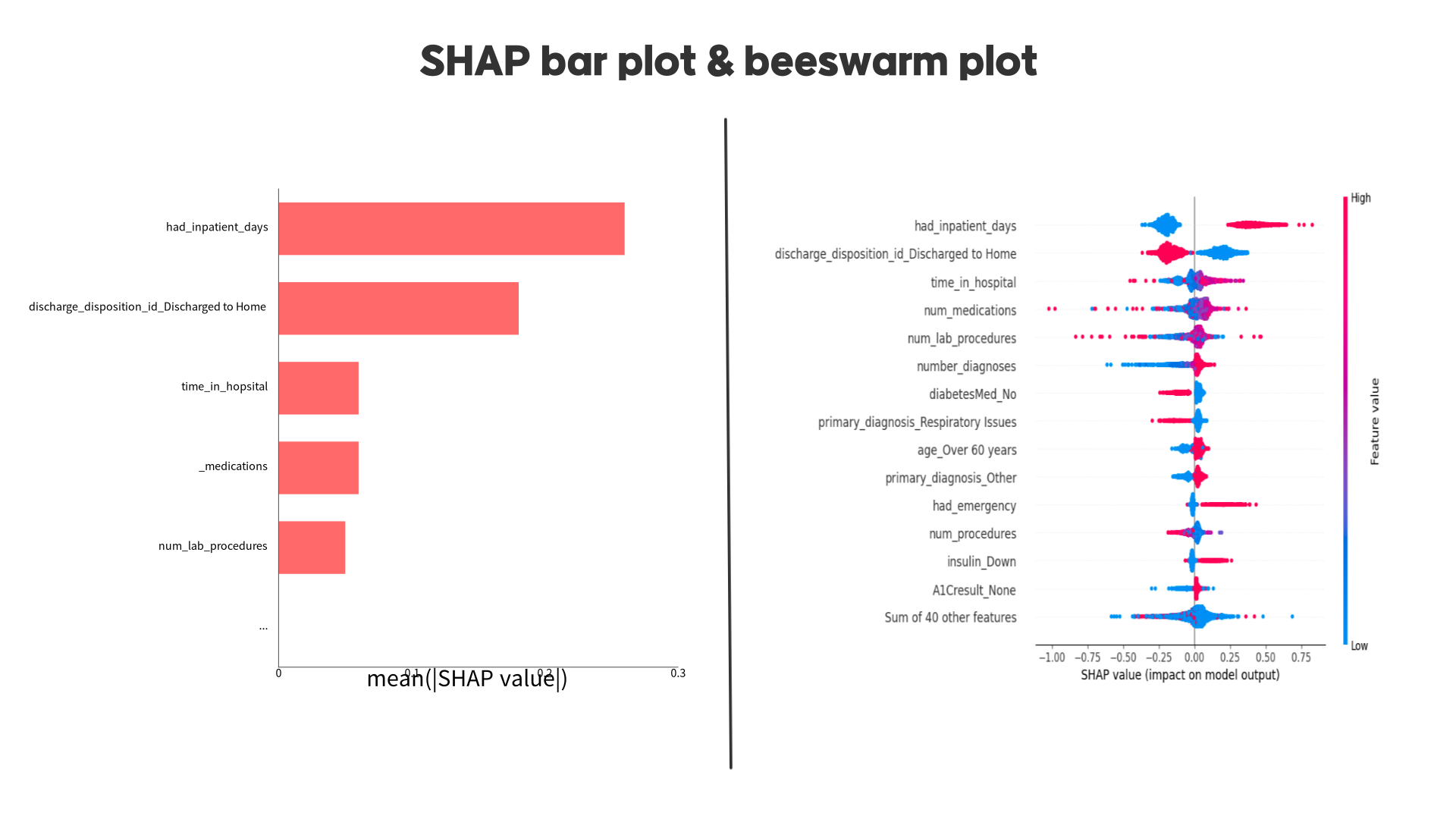
왼쪽 barplot을 통해서 알 수 있는 점은 had_inpatient_days 컬럼이 모델에 가장 큰 영향을 끼치고 있다는 것입니다.
그리고 오른쪽 beesswarm plot을 보면 빨간색일수록 높은 값이고 파란색일수록 낮은 값을 의미하는데, had_inpatient_days 컬럼의 경우 값이 높아지면 모델의 예측값이 높아지는 것을 확인할 수 있습니다. 반대로 두번째로 높은 영향을 끼치는 컬럼인 discharge_disposition_id_Discharged to Home 의 경우 값이 높아질수록 모델의 예측값은 낮아진다는 것을 알 수 있습니다.
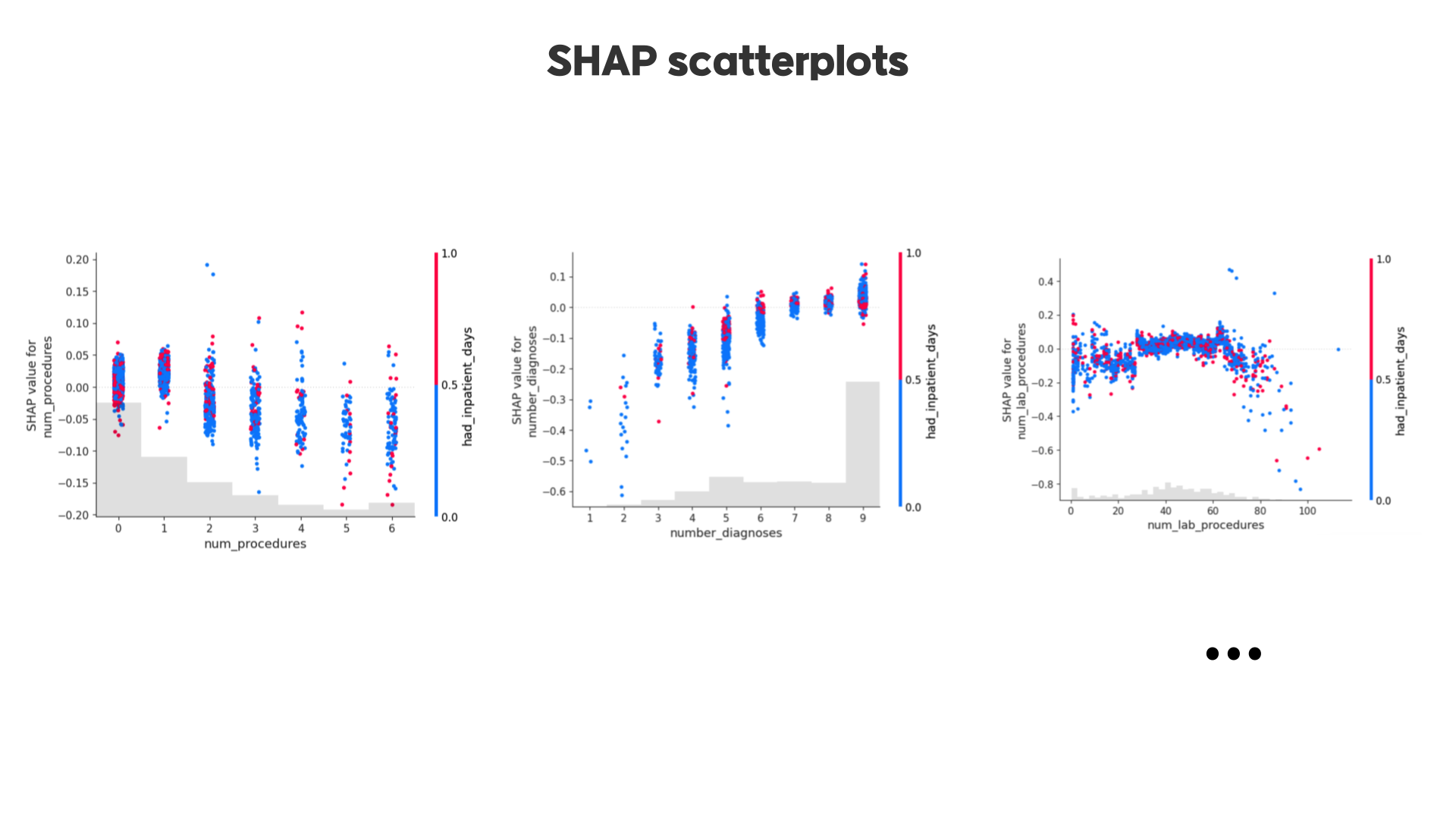
이외에도 위와 같이 feature마다 scatterplot을 그리며 feature의 값이 변화할수록 SHAP value가 어떻게 변하는지, 그리고 다른 컬럼과의 관계는 어떻게 되는지 등을 확인할 수 있습니다.
06. 이외에 에러를 줄이는 몇가지 전략
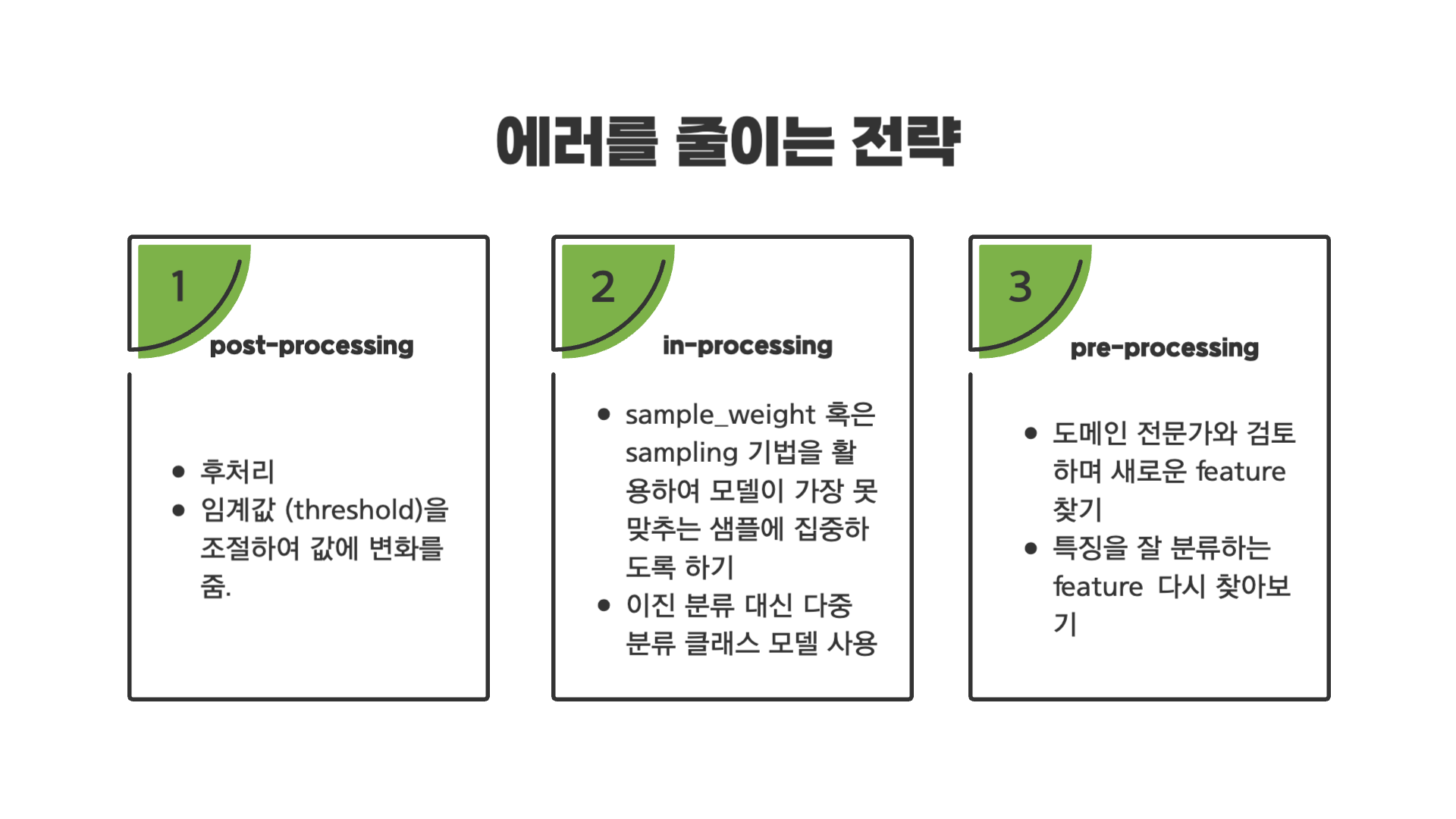
첫번째로 post-processing의 경우 모델링을 다 한 후에 positive 클래스를 예측하는 임계값을 조정하는 방법이다. 일종의 편법으로 보일 수 있지만, positive 클래스를 예측하는 경우에 대한 임계값을 조정하는 일은 일반적인 일이라고 합니다. 때문에 이때 임계값은 일관적으로 0.5일 필요가 없습니다.
하지만 임계값을 바꾸는 것만 해도 결과가 크게 달라지기 때문에, 아래 3가지를 고려하여 임계값을 조정해야합니다.
- 데이터의 분포를 보는 것은 매우 중요
- 데이터의 분포를 반영하는 나의 모델은 어떤 분포를 보여주는 지
- 데이터 자체가 밸러스가 어떻게 생겼는지
위 세가지를 고려하여 임계값을 결정해야 한다고 합니다.
두번째로 in-processing은 모델링을 할 때 사용할 수 있는 에러를 줄이는 방법입니다. sample_weight나 sampling 기법을 활용하여 모델이 잘 못맞추는 샘플에 더 집중하도록 하는 방법입니다.
다음으로는 다중 클래스 모델을 사용하는 경우인데, 해당 미니 프로젝트의 경우 0 (Negative) 클래스에 입원을 하지 않은 경우와 30일 '이후'에 입원한 경우가 같이 있습니다. 그래서 이 클래스도 같이 분류하는 다중 클래스 분류 모델을 만들어 에러를 줄이는 방법이 있습니다.
마지막으로 pre-processing의 경우 도메인 전문가와의 커뮤니케이션을 통해 새로운 Feature를 찾아 모델이 에러를 줄일 수 있도록 해주는 방법입니다.
그 다음으로는, 엔지니어링 과정에서 특징을 잘 분류하는 일부 feature가 사라졌을 수도 있는데 그 feature들을 다시 찾아 모델링에 활용하는 방법입니다.
07. 정리하며
이번 미니 프로젝트를 통해 얻을 수 있었던 점을 다시 정리해보면
- optuna를 활용한 하이퍼파라미터 튜닝
- confusion matrix를 전체적으로만 보는 것이 아니라 주제 그룹으로 나누어 보는 방법
크게 두가지를 배울 수 있었습니다.
단순히 모델 정확도가 85%이다~ 90%이다 하는 것이 아니라, 여러 다른 지표들을 참고하고 여러 그룹으로 나누어 분석하면서 해당 모델을 어떻게 활용하고 에러는 어떻게 줄여나가는 것이 좋은 것인가에 대한 것을 배울 수 있었습니다.
여기까지 읽어주신 분이 계시다면 부족하지만 감사드립니다:)

많은 도움이 되었습니다, 감사합니다.