
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 분류 (classification) 실습을 해보았습니다. 이번 실습에서 다룬 중점적인 부분은 class imbalance 문제를 해결하기 위한 샘플링 및 class weight 하이퍼 파라미터 튜닝 과정입니다.
이전 2번째 미니 프로젝트 (당뇨 환자 재방문 예측)과 다른 미니 프로젝트 등에서 class weight를 조작하거나 over-sampling 혹은 under-sampling 실습을 해본 경험이 있었습니다. 이번 미니 프로젝트에서 다른 점이 있다면 이전 미니 프로젝트에서는 이진 분류 문제에서의 클래스 불균형 문제를 해결하고자 했던 것과 달리, 다중 클래스 중 한 클래스의 불균형으로 인한 잠재적인 모델링 성능 저하 문제를 해결하고자 했습니다.
그렇다면 이번 실습에서는 어떻게 클래스 불균형 문제를 해결했는지 Data Processing 과정과 모델링 과정을 다루어보겠습니다.
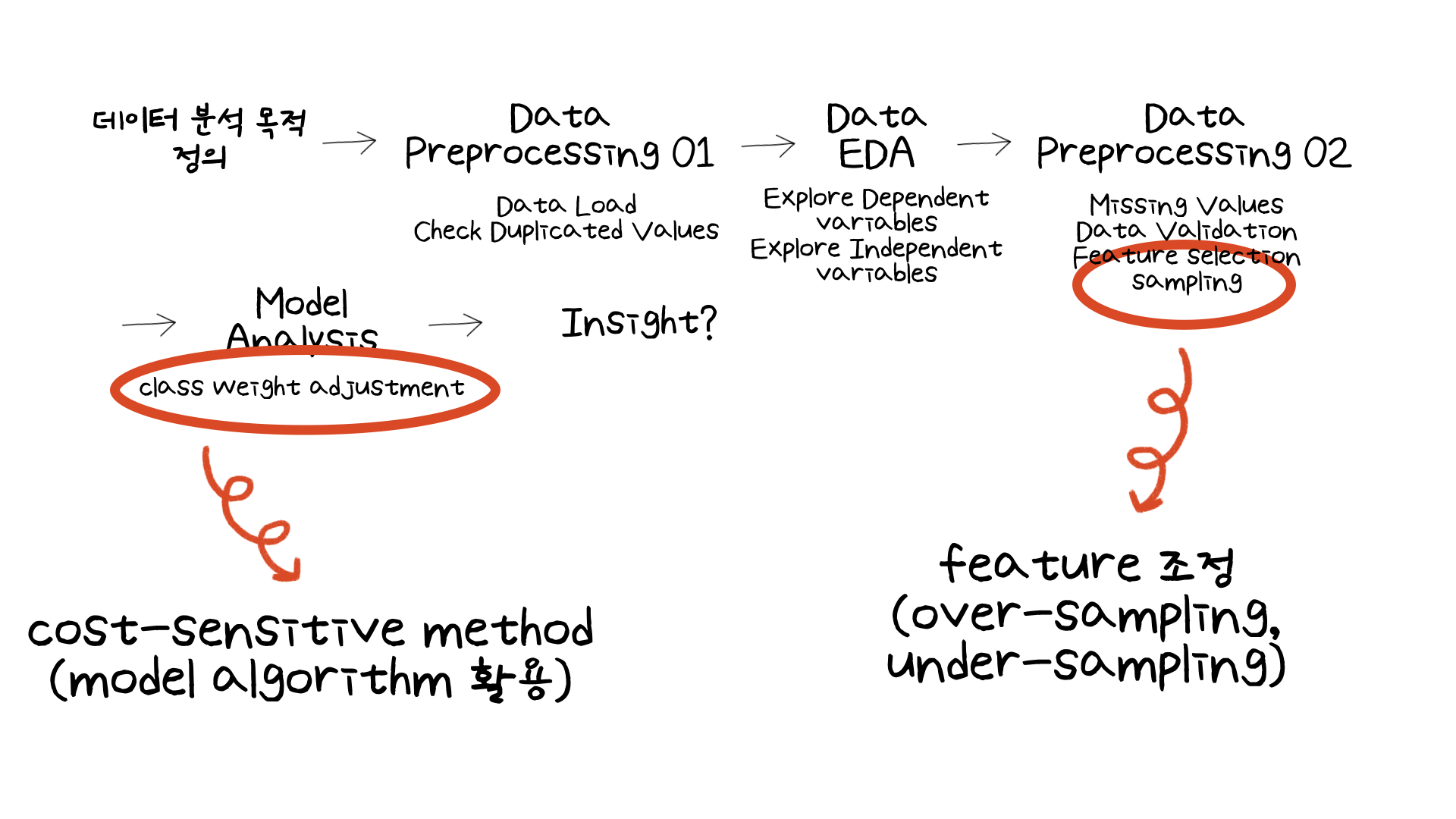
02. what have I learned?
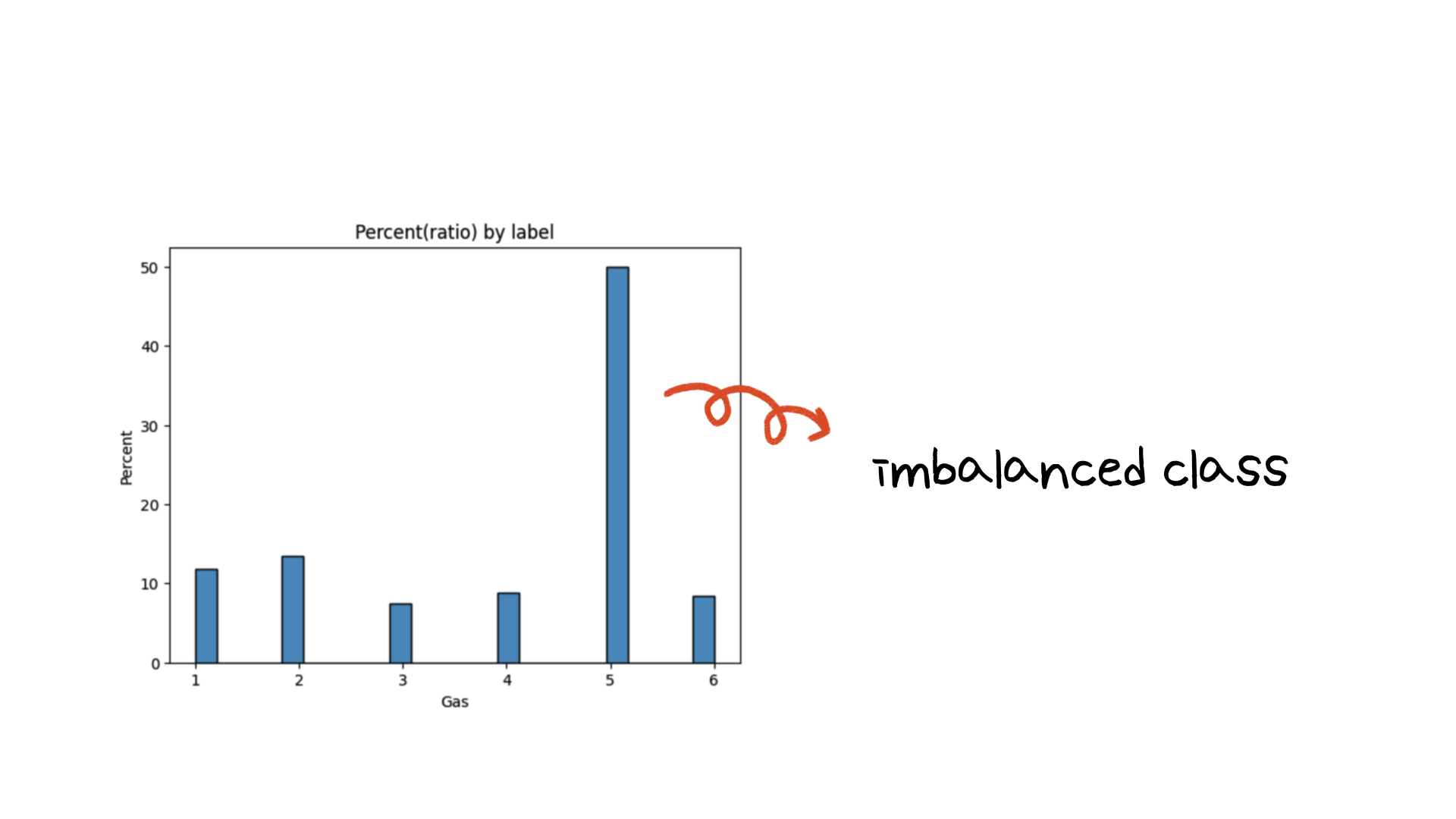
첫번째로 class imbalance를 해결하기 위해 Data Processing 단계에서 feature를 가공했습니다.
under-sampling을 위해서는 imblearn 라이브러리의 NearMiss를 사용했고 over-sampling을 위해서는 imblearn 라이브러리의 SMOTE를 사용했습니다.
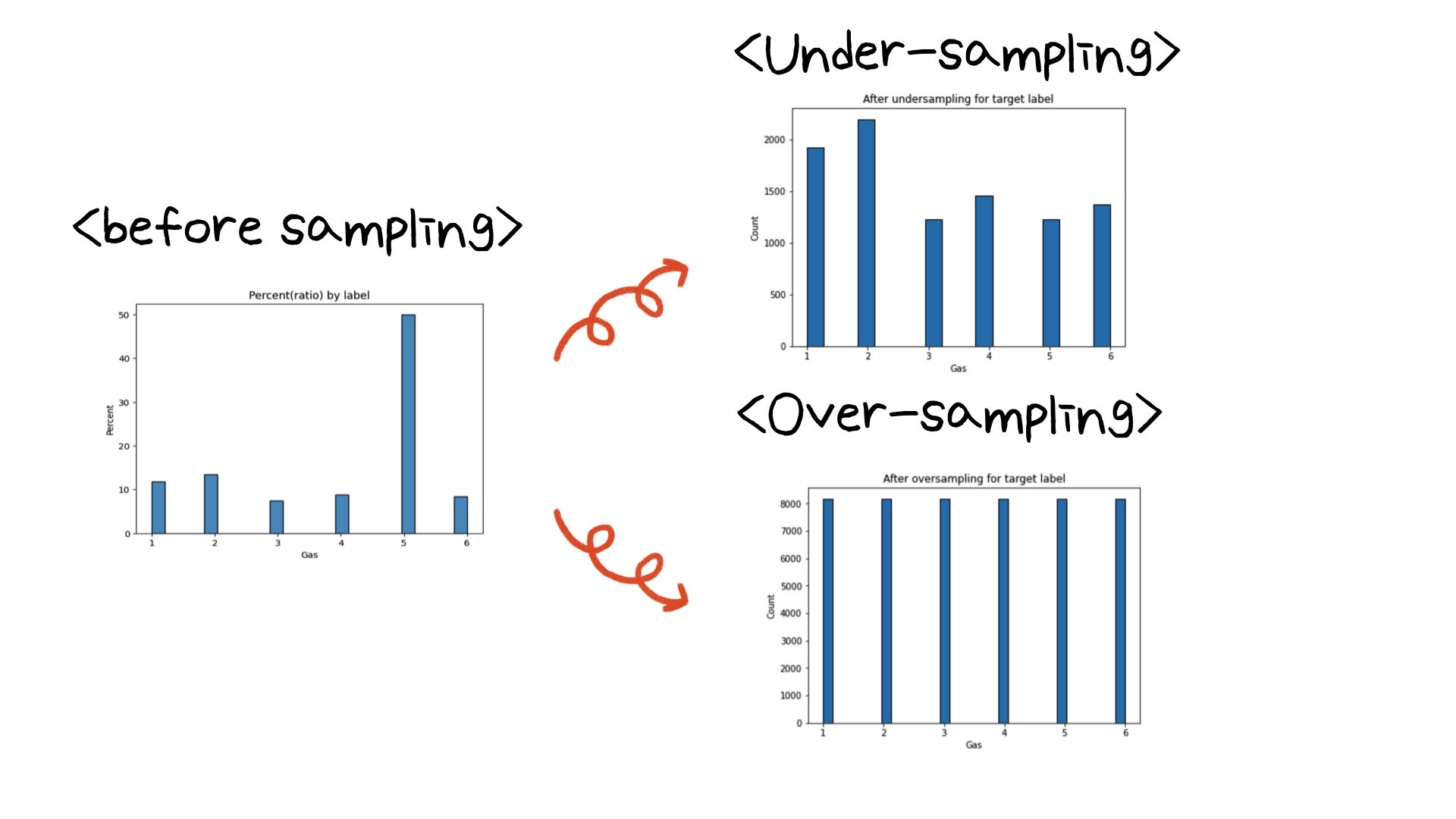
under-sampling 결과와 over-sampling의 결과 타겟 클래스의 분포는 위와 같습니다. under-sampling의 결과 클래스 5의 데이터가 많이 줄어든 것을 확인할 수 있었습니다. over-sampling의 경우는 클래스 5의 데이터 개수에 맞춰 모든 클래스가 같은 레이블 갯수를 가지고 있는 것을 확인할 수 있습니다. 이제 이 데이터를 가지고 모델링의 결과를 확인해보겠습니다. (변수가 너무 많아 이 과정 직후에 PCA를 통해 차원을 줄여주었습니다)

모델의 결과 놀랍게도(?) class weight, over-sampling, under-sampling을 조절하지 않은 원래의 데이터를 사용한 base model이 가장 좋은 성능을 보여주었습니다 (성능은 roc_auc_score 점수로 판단했습니다). 원래 실습에서는 RandomForestRegressor를 사용했으나, 모델 학습에 시간이 너무 오래걸려 LGBMClassifier로 변경하여 모델링을 했습니다. class_weight, over-sampling을 한 모델과 성능의 큰 차이는 없었습니다. 하지만 어떤 모델의 성능이 가장 좋은가 한다면 기본 모델의 성능이 가장 좋은 것을 확인할 수 있었습니다.
03. 마무리하며
이전 미니 프로젝트에서도 데이터를 가공하거나 모델의 class weight 하이퍼 파라미터를 튜닝하였음에도 모델의 성능이 base model보다는 올라가지 않았었습니다. 물론 제가 실습을 한 데이터가 class imbalance를 해결하기 위한 방법이 효과가 없었을 수도 있습니다. 하지만 다시 한번 class imbalance를 해결하기 위한 과정을 경험하며 복습을 할 수 있는 시간이었습니다.
안타깝게도 데이터의 피처들이 마스킹되어 샘플링 혹은 class weight를 조절하는 방법으로 class imbalance를 해결할 수 밖에 없었습니다. 하지만 마스킹되어있지 않은 데이터였다면 컬럼을 가공하여 (이미 충분히 좋은 성능이 나왔지만) 다른 방법으로 클래스 불균형 문제를 해결할 수 있지 않았을까하는 생각이 드는 시간이었습니다.
부족한 글 읽어주셔서 감사합니다:)
