
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 코멘트 수에 따른 블로그 인기도를 예측하는 모델링 실습을 진행했습니다. 여러 블로그들이 있는데, 각각의 블로그마다 게시물들의 평균 코멘트수를 활용하여 블로그 인기도를 예측함으로 전체 블로그를 관리하는데 해당 모델을 사용할 수 있을 것입니다.
데이터를 정제하기 전 변수의 개수는 278개로서 굉장히 많은 변수가 있었습니다. base time을 기준으로 24시간 전 코멘트 수, 이후의 코멘트 수, 코멘트 수 평균값, 최소값, 최대값, 표준편차, 중간값 등과 base time의 기준 요일 (월화수목금토일 중 하나) 등 많은 변수들이 합해져있었습니다. 이 변수들을 활용하여 데이터 정제과정을 거쳐 모델링까지 진행한 과정을 이 글에 담아보고자 합니다.
이 글을 시작하기에 앞서 다룰 내용은 이전 미니 프로젝트에서 다루었던 과정과 조금 다릅니다.
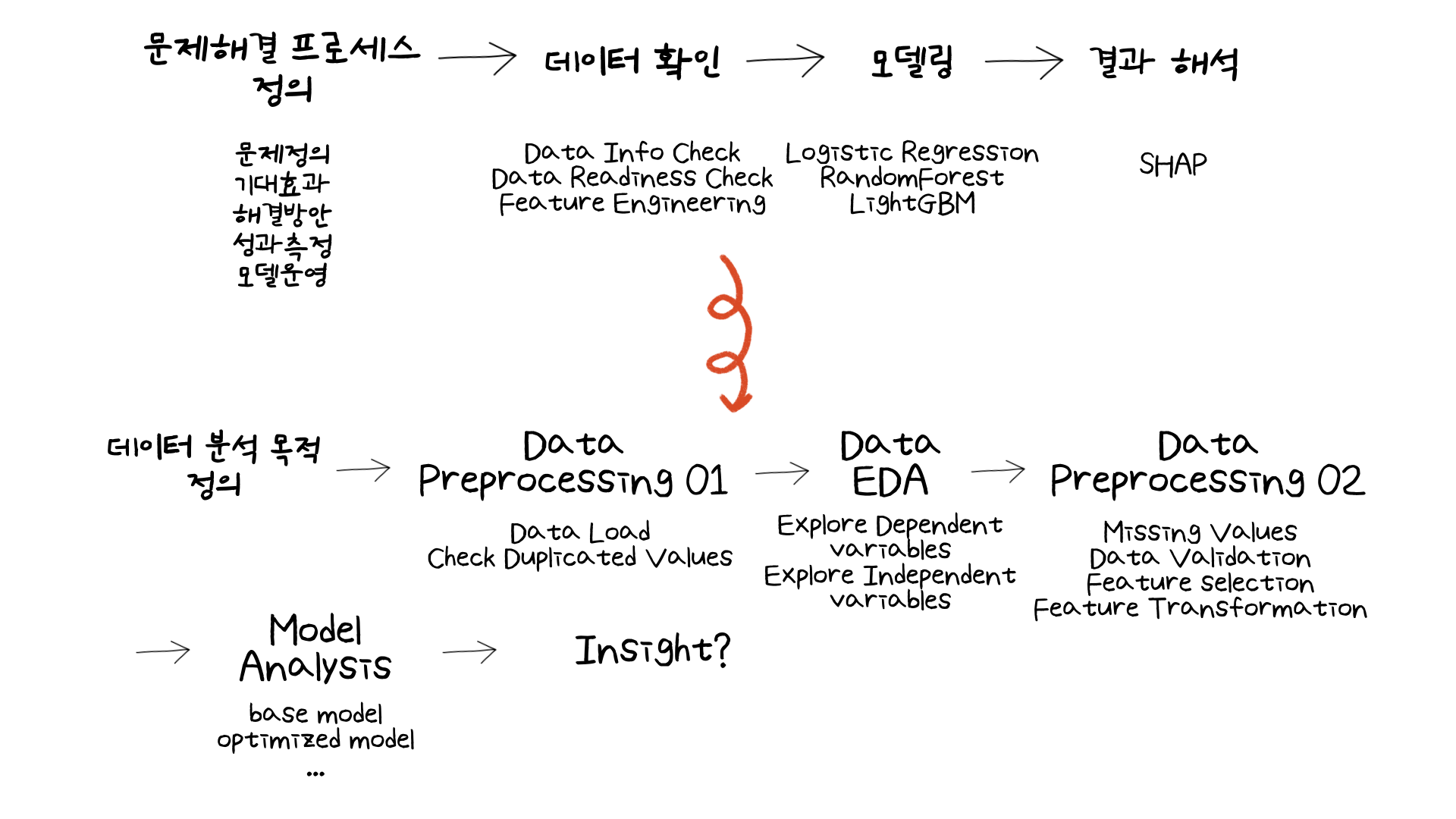
기존 분석과정과는 크게 다르지 않지만 다른 부분이라면 data preprocessing 과정이 두번 들어간다는 점입니다. 기존 미니 프로젝트 실습과정에서는 순차적으로 문제해결 프로세스 정의, 데이터를 확인하는 과정, 모델링, 결과 해석을 진행했습니다. 하지만 이번 미니 프로젝트에서는 실제 현업과 비슷할 수 있는 preprocessing EDA 과정을 거치고 필요한 부분을 다시 preprocessing하는 작업을 했습니다. 아무래도 실제로는 순차적으로 과정이 진행되는 경우가 거의 없을 것이기 때문에, 해당 과정은 실제로 분석 일을 할 때와 비슷한 과정으로 진행되었습니다 (비록 실제 현업에서는 해당 과정이 더 많이 반복될 것 같기는 하지만 말입니다).
그렇다면 조금 달라진 (하지만 전체적으로 보면 이전에 진행했던 과정에 다 포함되는) 분석 과정에서 어떤 것을 배웠는지 다루어보겠습니다.
02. what have I learned?
첫번째로 다루어볼 내용은 EDA 과정입니다.

이전 미니 프로젝트들에서도 EDA 과정이 포함되어있었지만, 이번 실습에서는 조금 더 자세히 배울 수 있었습니다. 먼저 독립 변수 (independent variable) 중 numeric 변수들에 관해서 correlation을 구할 때 p-value를 확인하는 습관이 필요하다는 것을 배웠습니다. correlation 값을 신뢰할 수 있는지 확인이 필요하기 때문입니다.
예를 들어, 분석을 진행하면서 활용한 변수들 중에서는 타겟 변수와 상관관계가 0.9가 넘는 변수들이 많았습니다. 해당 변수들은 다중 공선성으로 인해 삭제가 필요했지만 해당 변수들의 계수가 정말 0.9가 넘는지 확인을 해봤습니다. scipy.stats.pearsonr을 활용하여 p-value를 확인한 결과 모두 0.05보다 낮았습니다. 결과를 통해 상관관계가 0.9라는 귀무가설을 기각하고 0.9보다 크다는 대조가설의 손을 들어줄 수 있었습니다. 하지만 해당 변수들을 삭제할 시 너무 많은 변수가 사라지게 되어 우선 모델링을 위해 삭제하지는 않았습니다.
다음으로 categorical 변수들에 대해서는 ANOVA test (일원분산분석)과 Kruskall-Wallis test (크루스칼 왈리스 검정-비모수 검정)을 진행했습니다. ANOVA test를 하려고 했으나, 전제조건인 정규성 검정을 만족하지 못했습니다. 그래서 비모수 검정인 크루스칼 왈리스 검정을 통해 타겟값과 유의미한 관계를 가지는 변수들을 찾았습니다. 그 결과 214개 중 130개의 변수들이 타겟 변수와 유의미한 관계를 가지고 있는 것을 발견했습니다.
결과적으로 Data EDA 과정에서는 타겟변수와 유의미한 관계를 가지는 변수를 선택하거나 상관관계가 너무 높은 변수는 삭제를 하는 등 feature selection을 위해 사전 작업을 하는 과정이었습니다.
다음으로 종속 변수 (dependent variable) EDA 과정에서는 skew (왜도)와 kurtosis (첨도)를 확인했습니다. 타겟 변수의 분포를 확인함으로서 모델링을 했을 때 결과가 어떻게 될지 어느 정도 짐작해볼 수 있었습니다. 예를 들어 타겟 변수가 너무 편향되어있다면, 모델링을 했을 때 일반화가 되어 예측 성능이 좋지 않을 수 있다는 것을 예상해볼 수 있습니다. 그리고 타겟값이 어느 범위에 많이 분포되어 있는지 확인했습니다. 이번 실습의 데이터에서는 대략 92%의 데이터가 10 이하에 분포되어 있었습니다. 이는 이후에 모델링의 결과가 좋지 않을 시 값의 범위를 바꾸어 다시 모델링을 해볼 수 있도록 해주었습니다.
다음으로 다루어볼 내용은 EDA 과정 이후의 Data Preprocessing 단계입니다.
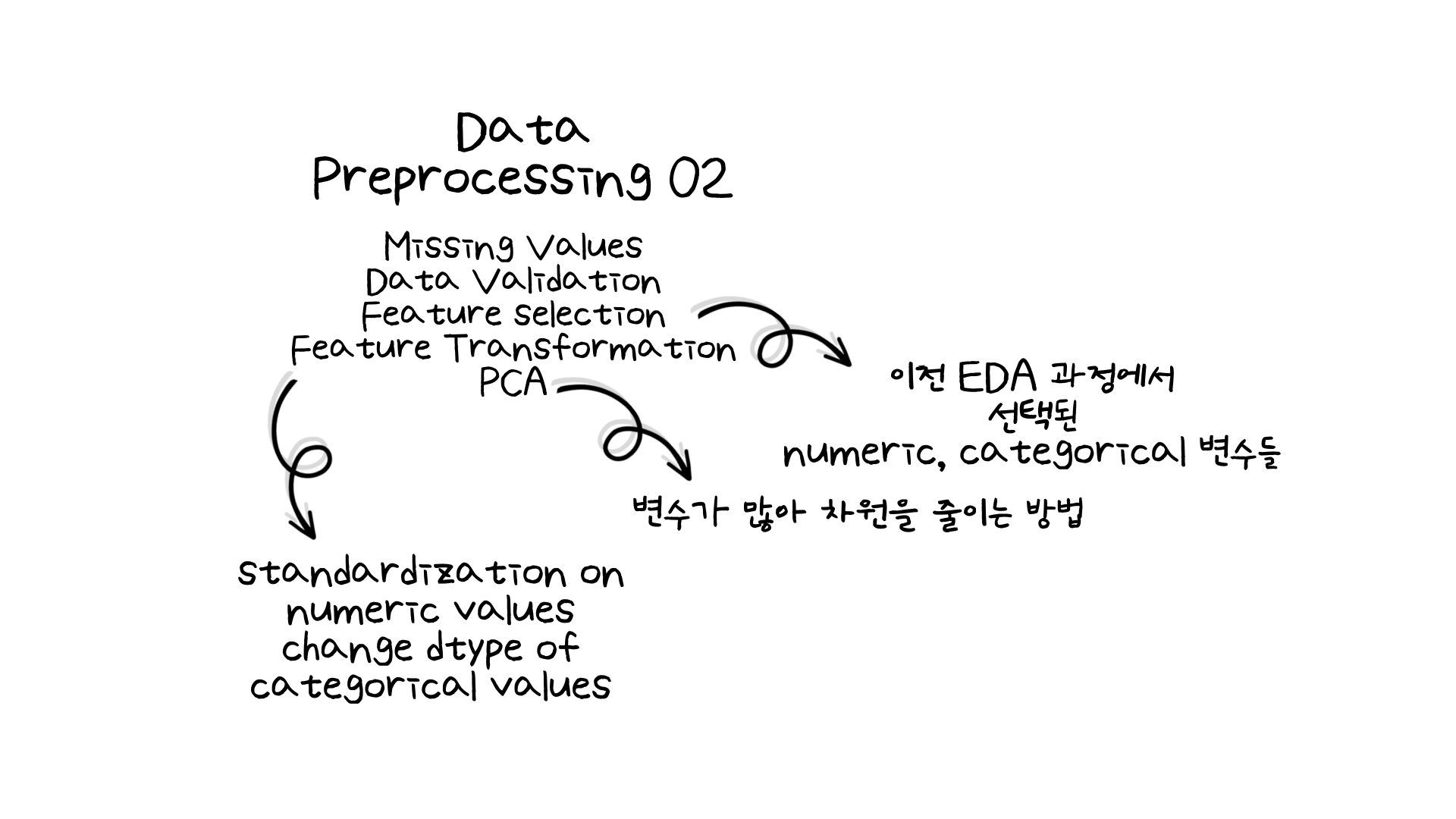
간략하게 배운 내용을 정리해보면 Feature Selection과정에서는 이전 EDA에서 필터링 된 변수들을 실제 데이터에 반영했습니다. 그래서 최종적으로 278 189개의 변수가 모델링을 위해 선택되었습니다.
다음으로 Feature Transformation 단계에서는 변수들을 변형하는 과정을 거쳤습니다. numeric 값들의 경우는 값의 스케일을 맞춰주기 위해 standardization을 적용했습니다. 이는 이후의 PCA 과정을 위해서도 필요한 단계였습니다. 그리고 categorical 변수들의 값은 전부 0과 1로 이루어져 있었습니다. 그래서 레이블 인코딩 혹은 원핫 인코딩을 해줄 필요 없이 데이터 타입을 float에서 int로 변형했습니다.
마지막으로 PCA (주성분분석)을 통해서 데이터의 차원을 줄여주는 단계를 거쳤습니다. 변수의 개수가 너무 많다보니 차원이 너무 높아졌습니다. 그래서 데이터의 분포를 95% 정도까지 설명해주면서 차원의 수를 줄였습니다. 그 결과 약 50개의 차원으로 줄일 수 있었고, 이는 이후 모델링에 활용했습니다.
03. 마무리하며
이외에도 배운 내용이 많았으나 이전 미니 프로젝트들에서는 다루어보지 않은 내용들을 위주로 다루어보았습니다. 이번 글에서 몇가지 분석 기법을 다루었는데, 분석기법과는 별개로 저에게 데이터 마트 개발과 관련한 아이디어를 불어넣어주었습니다.
국비지원 교육을 들을 당시 번개장터 사이트의 데이터를 크롤링하여 예측 모델링을 만들어보고자 시도했었습니다. 하지만 데이터를 어떻게 구성할지 몰라 결국 크롤링까지만 하고 모델링은 하지 못했습니다. 그런데 이번 미니 프로젝트의 데이터 마트를 보니 데이터를 어떻게 구성할지에 관한 아이디어를 얻을 수 있었습니다. base time을 설정하고 여러 feature들을 생성한다면 어떤 상품이 팔릴지 혹은 더 많은 좋아요 수를 얻을 지에 관한 모델링을 해볼 수 있을 것 같습니다. 해당 미니 프로젝트를 진행하고 결과를 얻는다면 velog에 공유를 해보고자 합니다. 이상입니다!
부족한 글 읽어주셔서 감사합니다:)
