
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 online news의 공유 수를 예측하는 회귀 모델링 실습을 진행했습니다. 모델링 후 SHAP 라이브러리를 통해 각각의 변수들이 공유 수에 어떤 영향을 끼치는지까지 확인을 한 후 실습을 마무리하였습니다.
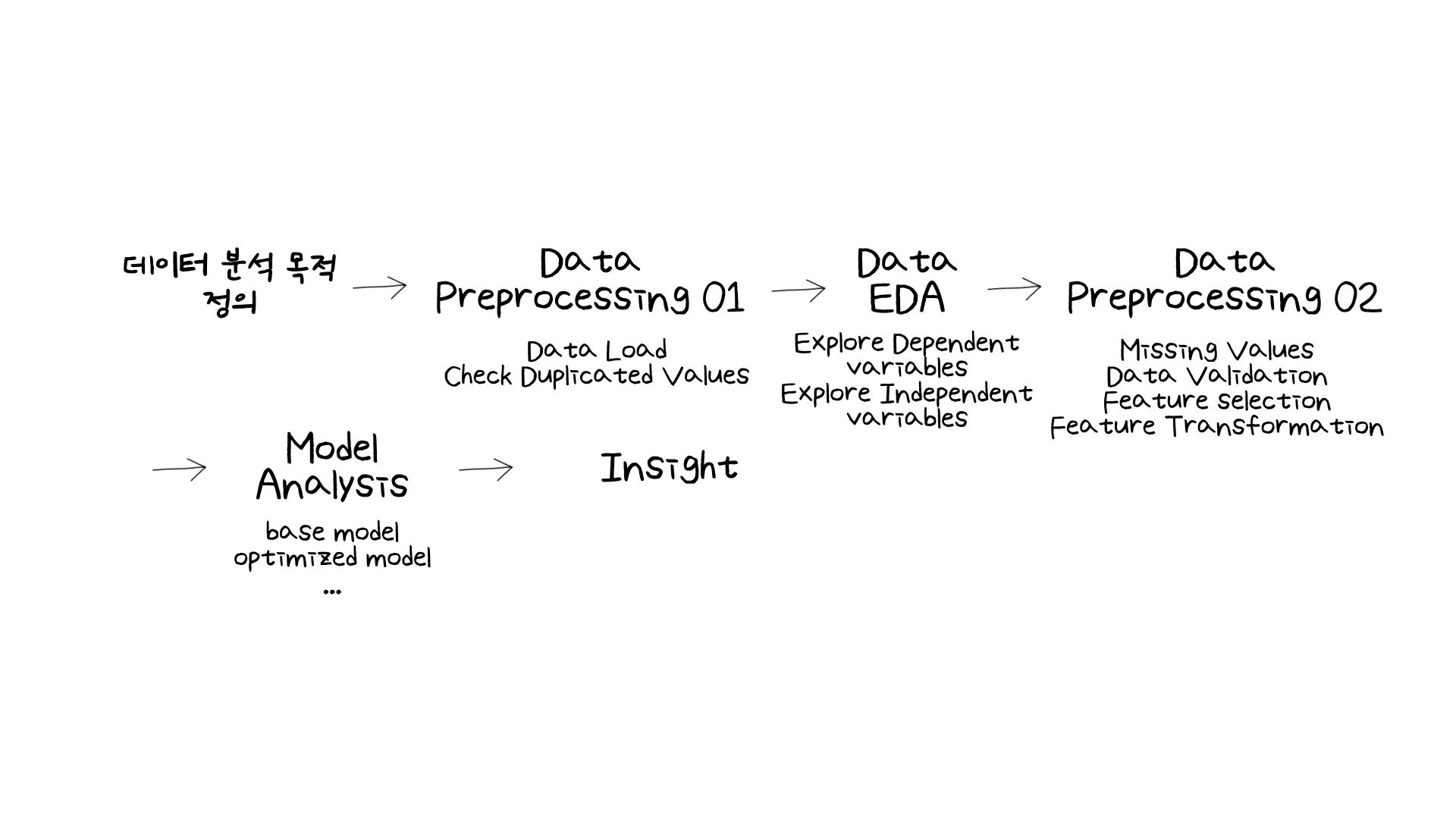
그런데 이제 이쯤 오니 전체 분석 프로세스를 어느 정도 파악하게 되었습니다. 물론 더 깊은 분석을 하면서 시간이 더 오래 걸릴 수 있으나, 전체적으로 어떻게 분석이 이루어지는 감을 잡을 수 있게 되었습니다.
그래서 이번 글에서는 실습 과정 중 효과가 잘 보이지 않아 활용하지는 않았지만, 차원 축소의 방법으로 LDA와 PCA에 대해 좀 더 알아보는 시간을 가져보려고 합니다.
02. What Have I Learned?
아래의 LDA와 PCA의 주요 차이점은 PCA vs LDA Differences, Plots, Examples 글을 참조하여 알아보았습니다. 그 차이를 정리하면 아래와 같습니다.
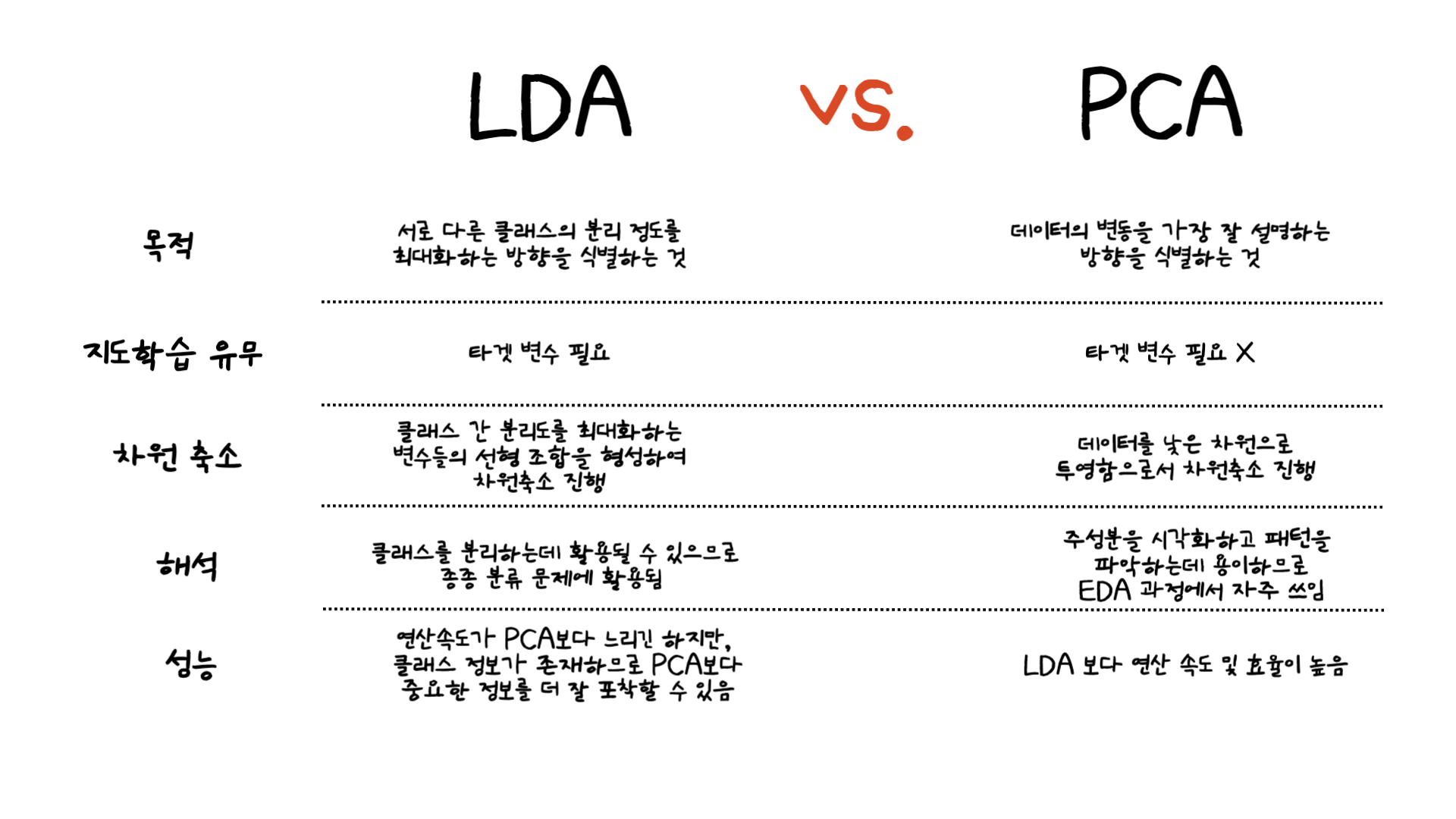
사실 LDA (Linear Discriminant Analysis)의 경우는 이전 미니 프로젝트에서 분류 문제에 쓰이는 알고리즘 중 하나로 알고있었는데 차원 축소로도 활용된다는 것을 처음 알게 되었습니다. 가장 큰 차이점으로 LDA는 타겟 클래스를 사용하다보니 차원 축소를 할 때 클래스간 분리도에 중점을 두는 것을 확인할 수 있었습니다.
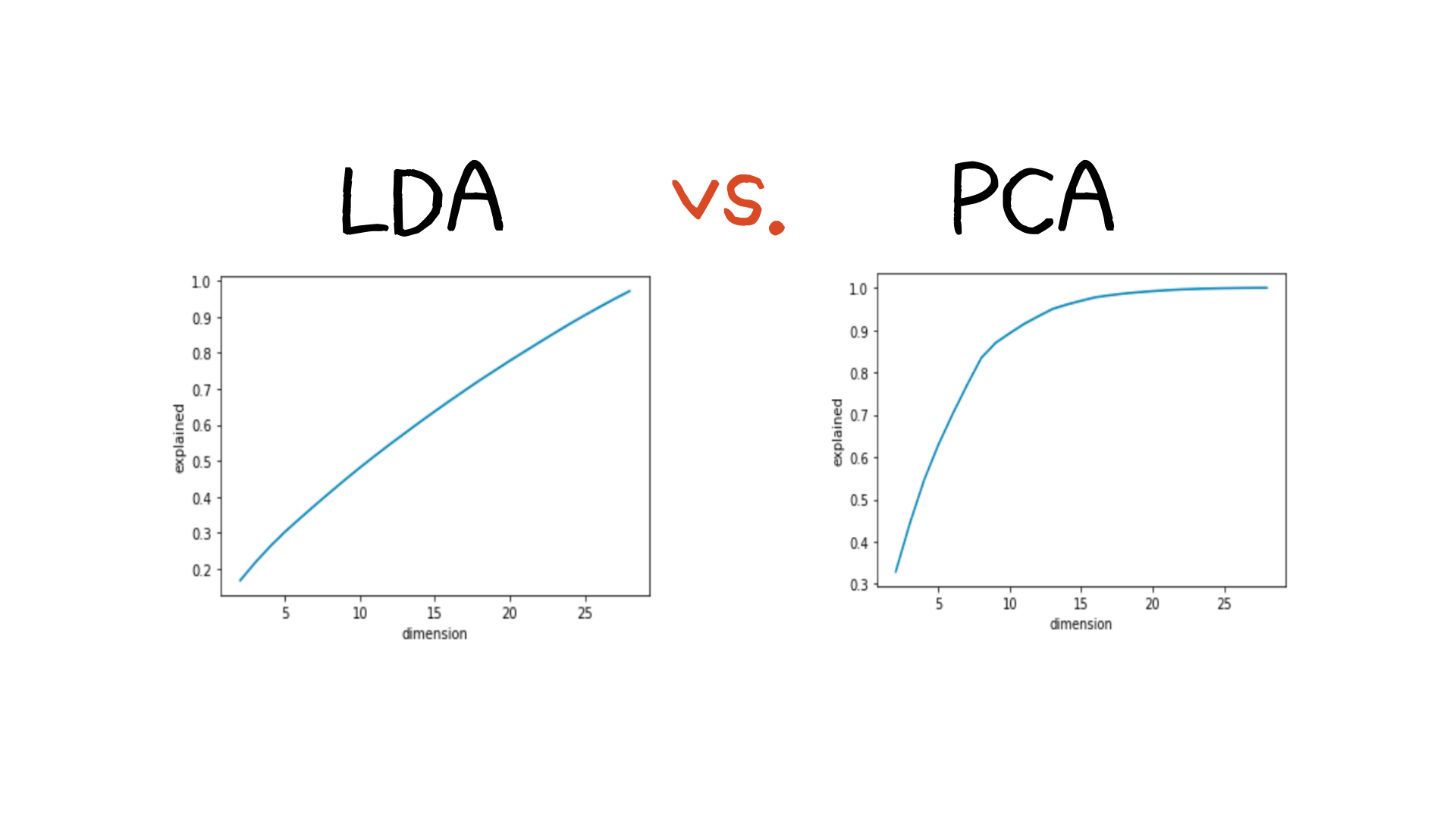
하지만 이번 미니 프로젝트에서는 차원 축소가 효과적으로 작용하지 않아 차원 축소를 진행하지 않은 변수로 모델링을 진행했습니다. 실습에서 차원을 2에서 줄인 것부터 시작하여 29까지 줄여봤으나, 모델의 설명력이 빠르게 증가하지 않고 천천히 증가하는 것을 발견했습니다. 이는 원래의 변수의 갯수와 큰 차이가 나지 않았기 때문에 차원축소를 진행하지 않은 변수들로 모델링을 진행했습니다.
03. 마무리하며
이번 글에서는 차원축소의 대표적인 방법인 PCA와 LDA에 대해 알아보았습니다. 비록 이번 미니 프로젝트에서는 두 가지 차원축소 방법이 큰 효과를 보이지 않았지만, 다음 미니 프로젝트나 또 다른 실습에서는 두가지 방법을 다시 시도해봐야겠습니다.
그리고 오늘 미니 프로젝트를 하며 깨달은 부분이 있었습니다. 매번 분석할 수 있는 데이터가 주어주다 보니 가끔 왜 이 데이터의 변수를 수집했을까? 이 데이터가 왜 필요할까? 등의 생각을 하지 않게 되었습니다. 하지만 실제 현업에서는 만약 제가 데이터 분석가로 일하게 되었을 때 필요한 데이터를 수집하거나 Data Mart를 구성해야 하게 될 것입니다. 그런데 제가 데이터 수집 및 구성에 미흡하다면 분석 속도가 느려지고 모델링을 하더라도 성능이 크게 좋아질 것 같지 않을 것이라는 생각이 들었습니다. 그래서 다음 미니 프로젝트에서는 데이터가 어떻게 구성되어있는지 저의 생각도 함께 velog에 적어보려고 합니다. 물론 제 생각이 틀릴 수 있겠지만 이런 사고과정도 실습을 하며 함께 연습을 해보고자 합니다.
부족한 글 읽어주셔서 감사합니다:)
