
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 개요
이번 미니 프로젝트에서는 E-commerce 사용자들의 데이터를 사용하여 사용자들의 구매 패턴을 군집화하는 실습을 진행했습니다. 이전 미니 프로젝트들에서는 하지 않았던 군집화였던만큼 이론적으로만 어느정도 잡혀있던 클러스터링을 실제로 활용할 수 있는 좋은 기회였습니다.
저처럼 마케팅에 관심이 있는 사람이라면 군집화의 효용성은 이미 저보다 더 잘 알고 있으신 분들도 많을 것 같습니다. 그로스 해킹 등의 관점에서 코호트별로 유저 및 구매 데이터를 분석하는 것은 A/B test 등의 실험 등에서도 유용하게 사용될 수 있기에 관심을 가지고 분석 실습을 진행했습니다.
전체적인 분석 과정은 지도 (supervised) 학습을 할 때와 크게 다르지 않았습니다.
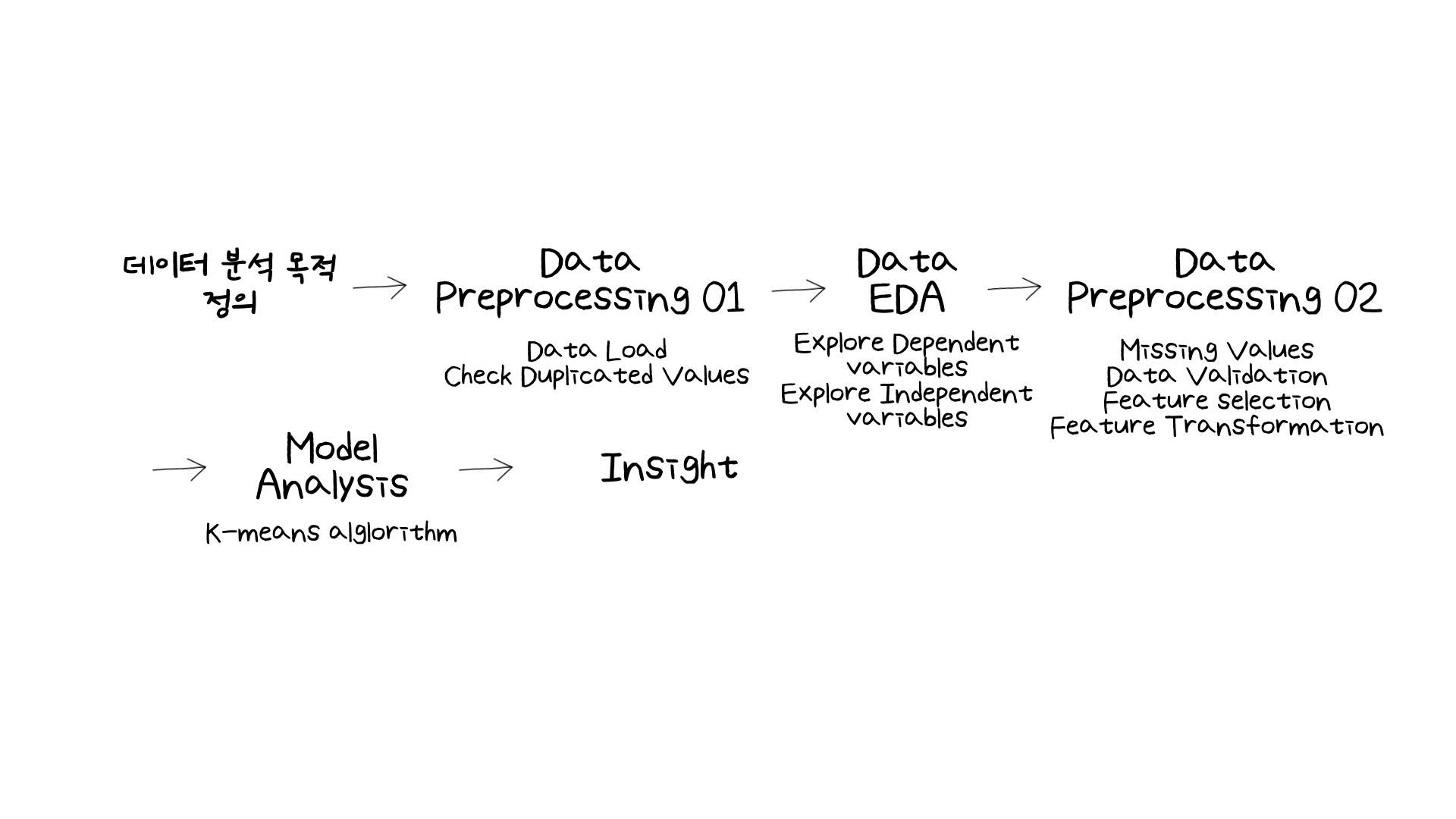
똑같이 분석 목적을 정의하고, 데이터를 정제하고 EDA하는 과정은 똑같이 진행했습니다. 다만 다른 부분이라면 모델링 부분에서 비지도학습의 클러스터링 알고리즘, 그 중에서도 K-means 알고리즘을 쓴 것이었습니다.
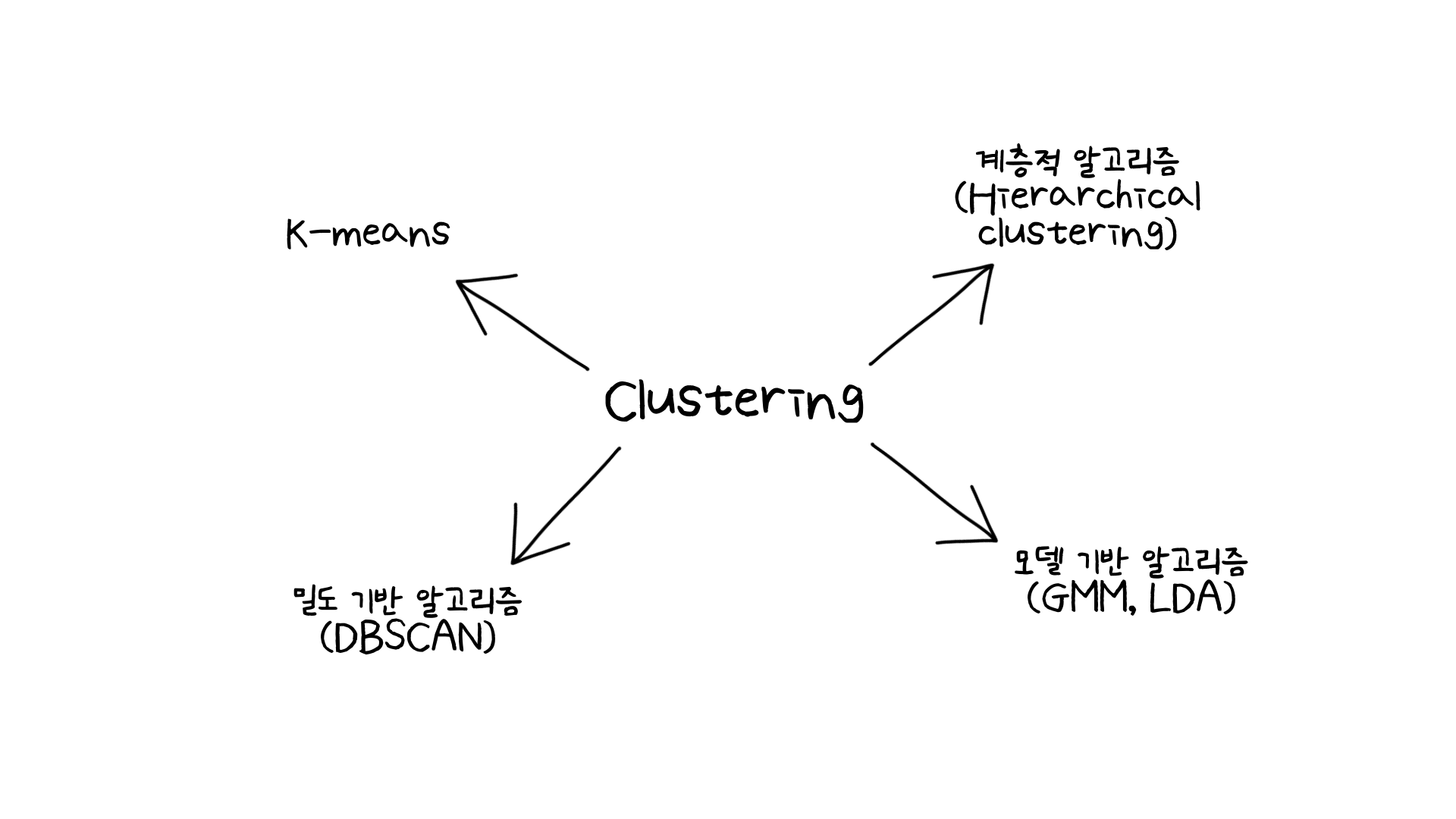
여러가지 클러스터링 알고리즘이 있지만 그 중에서 빠르고 간단한 구현으로도 좋은 성능을 보여주는 K-means 알고리즘을 선정하여 사용했습니다. 다른 알고리즘을 사용할 수 있었지만, 데이터의 크기가 매우 컸기 때문에 (약 515MB), 모델링을 하다가 실습시간이 너무 길어질 것 같아 K-means 알고리즘을 선택했습니다. 하지만 사용하는 데이터에 더 맞는 알고리즘이 있을 수 있기 때문에 이후 시간이 더 있다면 다른 알고리즘도 사용해볼 예정입니다!
그렇다면 먼저 데이터는 어떻게 구성되어있는지, 분석은 어떻게 진행했는지 다루어보겠습니다!
02. What Have I Learned?
첫번째로 데이터 컬럼은 어떻게 구성되어있는지 보겠습니다. 이전 미니 프로젝트 마지막에서도 다루었던것처럼 주어진 데이터를 바로 분석하다보니 데이터가 어떻게 구성되어있는지 놓치고 가능 경우가 많았습니다. 하지만 현업에서는 직접 Data Mart를 구성하거나 수집을 직접해야하기 때문에 어떤 데이터를 사용해서 분석했는지 기억하는 것은 향후에 제가 취업을 했을 때 도움을 줄 것으로 예상이 됩니다.
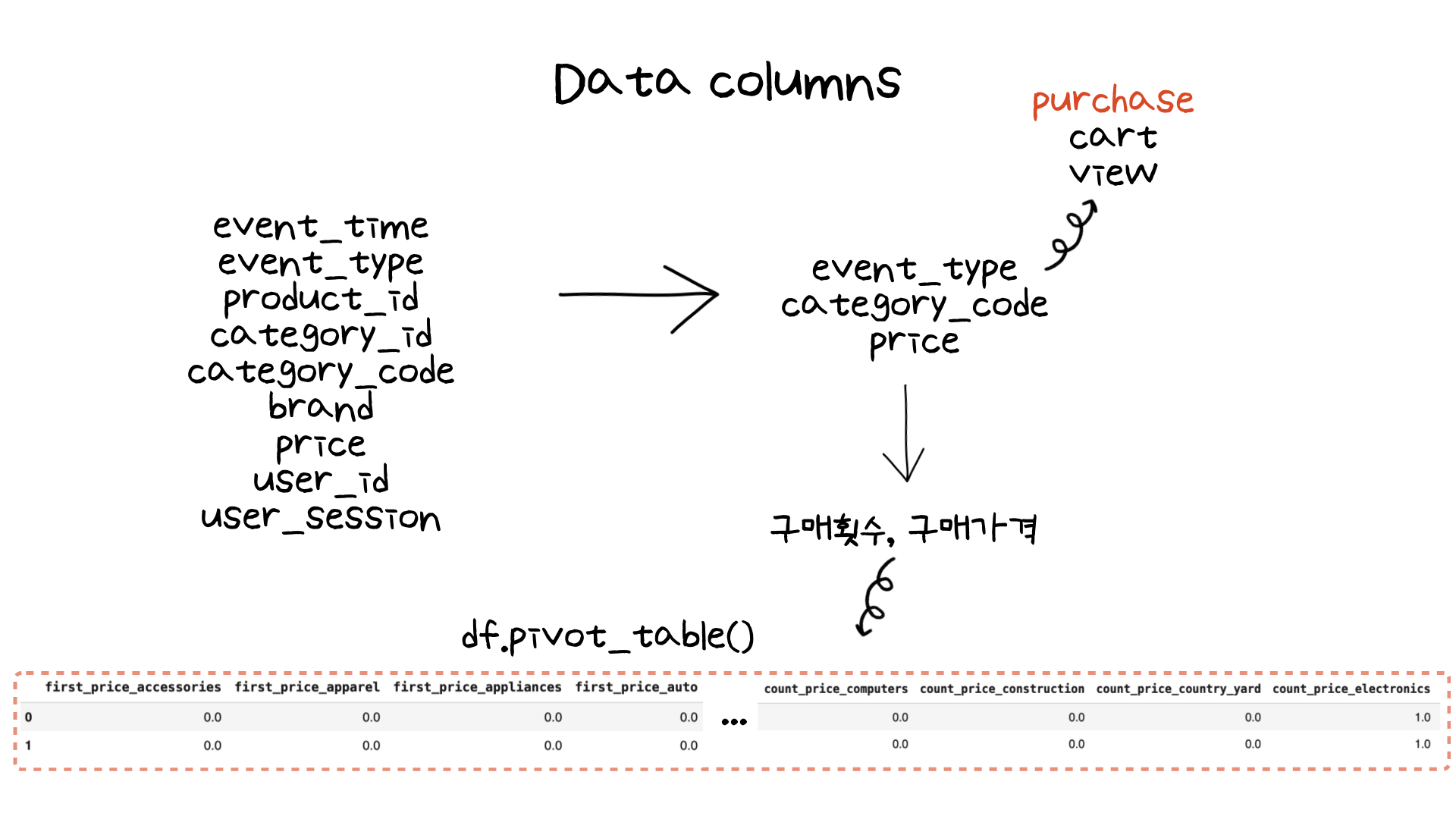
주어진 데이터는 9개의 컬럼으로 이루어져 있었습니다. 그 중에서 고객이 구매한 상품 클러스터링을 위해 event_type (사용자 행동), category_code (상품 카테고리 코드), price (상품 가격)을 최종 컬럼으로 사용했습니다. 고객의 경우 구매를 한 고객으로 필터링을 하기 위해 event_type 중 purchase (구매)를 한 고객 데이터를 선정했습니다. 그 결과 데이터는 약 68000 row 데이터 (약 3 MB)로 추려졌습니다.
하지만 데이터를 있는 그대로 사용하지 않고 pandas의 pivot_table을 사용하여 카테고리별 구매횟수와 구매가격 별로 합계해주었습니다. 여기서 카테고리는 대, 중, 소처럼 3가지 카테고리로 되어있었는데 데이터가 sparse 해질 수 있는 우려가 있어 대분류를 기준으로 합계를 해주었습니다.
이와 같은 과정은 제가 모델링에 집중을 한다면 놓칠 수 있는 부분이었습니다. 사실 다시 복습을 하면서 클러스터링을 하기 전 데이터를 pivot table로 만들고 스케일링 (여기서는 Normalization)을 해주는 과정은 잘 인지하지 못하고 있는 부분이었습니다. 만약 이 부분을 잘 복습하지 않고 지나갔다면 저는 아마 그냥 raw 데이터를 가지고 클러스터링을 하지 않았을까 싶습니다.
이전에 번개장터 사이트의 상품 데이터를 가지고 모델링을 해보려고 했었습니다. 하지만 분석 프로세스를 잘 정의하지도 못했지만, 수집한 데이터를 가지고 어떻게 분석을 해야할지 잘 몰랐었습니다. 단순히 count나 mean 등만 찍어보고 분석을 마무리했었습니다. 하지만 이번에 클러스터링 분석 과정을 실습했으니 다시 한번 데이터를 수집하여 분석을 추후에 하려고 합니다!
이렇게 모델링 전 데이터를 가공한 후, K-means 알고리즘을 사용하여 모델링을 했습니다.
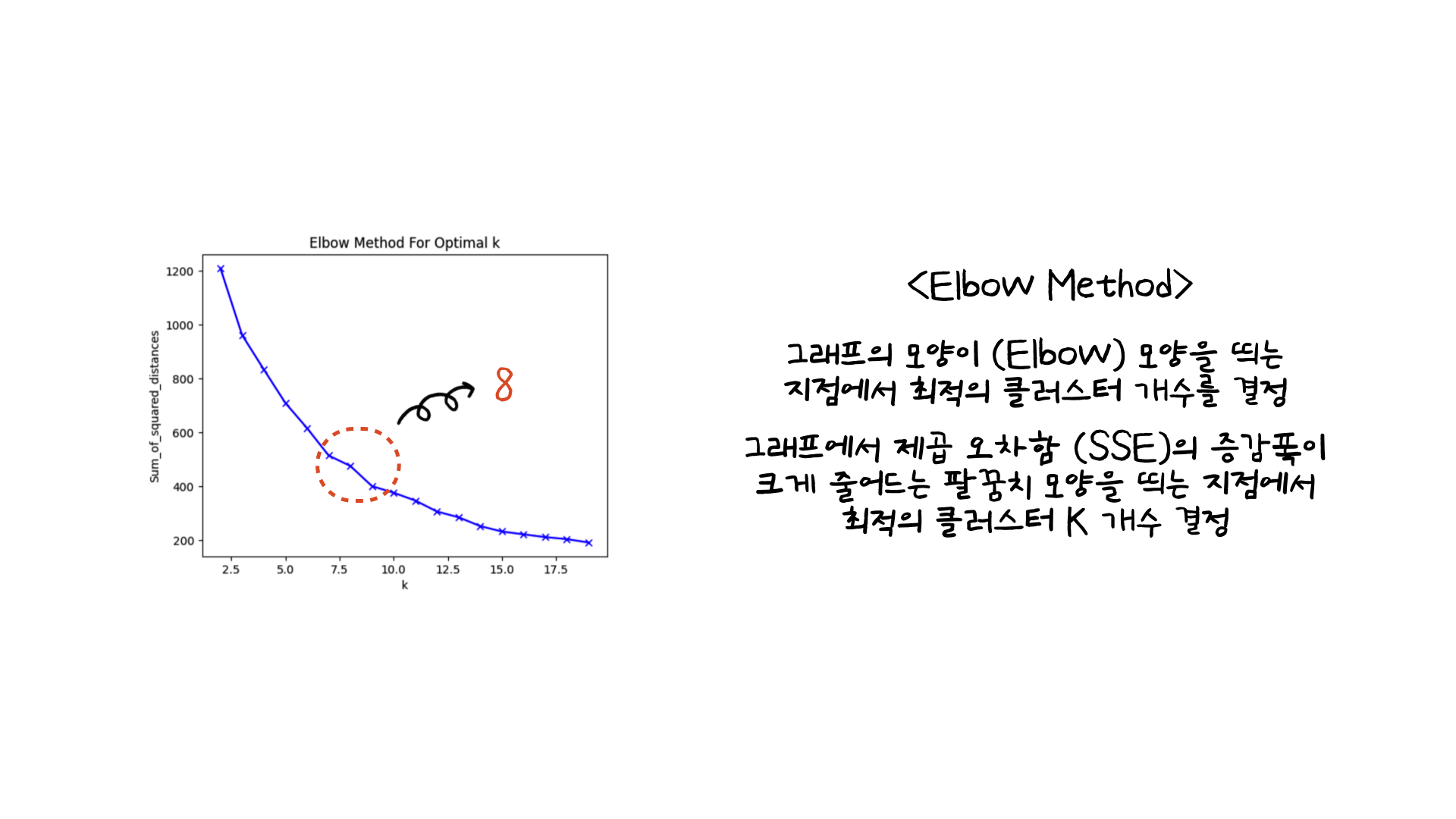
클러스터링 K의 개수를 바꿔가며 클러스텅한 결과 제곱 오차합 (SSE) 그래프는 위의 왼쪽 이미지와 같습니다. 이때, 최적의 클러스터 K의 개수를 선정할 때는 Elbow method를 사용했습니다. 위의 설명과 같이 제곱 오차합의 증감폭이 줄어드는 구간에서 클러스터 개수를 결정하는 방법입니다. 그렇게 결정된 K는 8이었습니다.
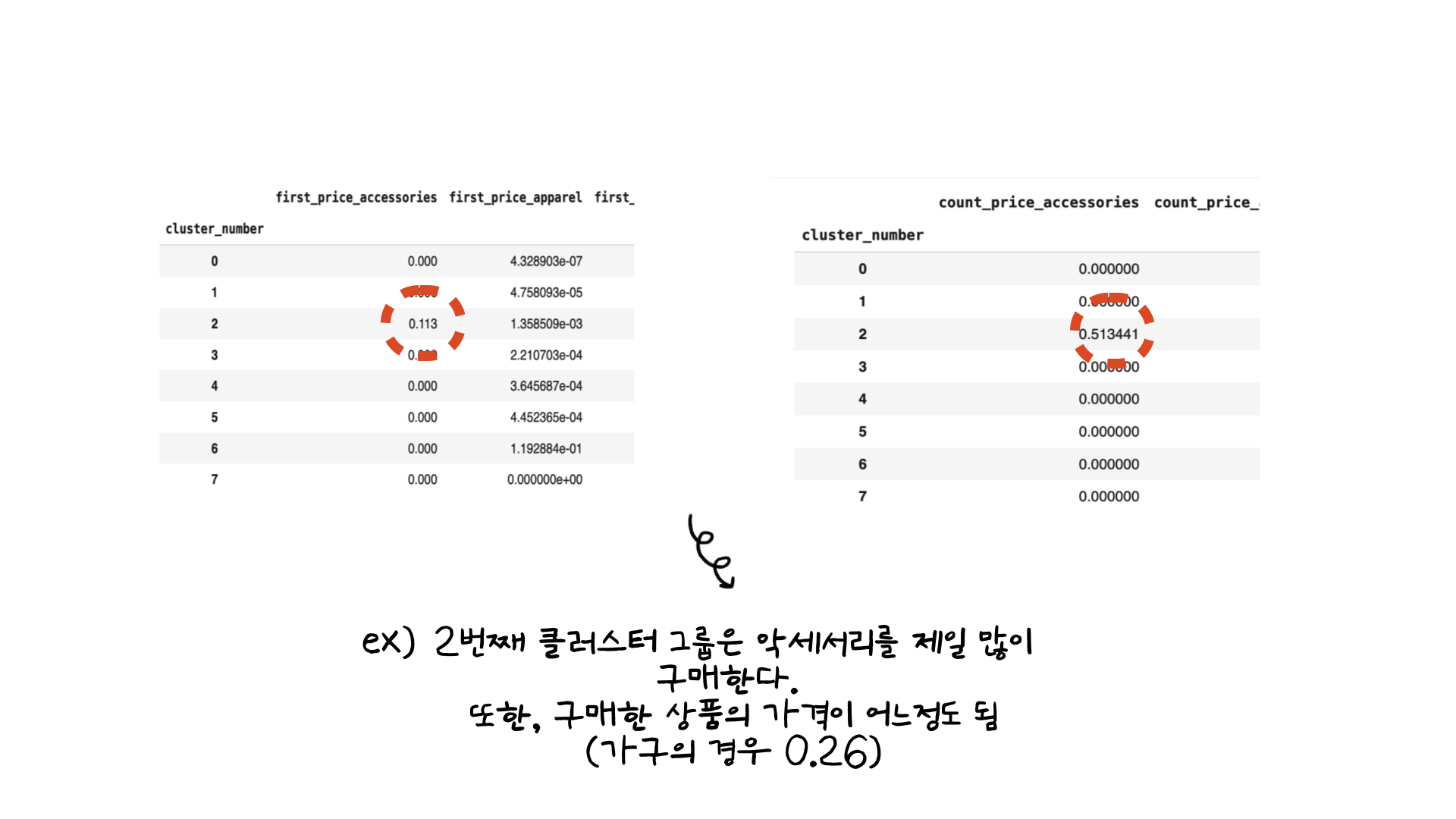
이후 클러스터별 값을 groupby를 통해 평균을 구한 예시는 위의 이미지와 같습니다. 정규화를 했기 때문에 클러스터별로 비교가 가능했었습니다. 그래서 한 예시로 클러스터링 결과를 해석하자면, 2번째 클러스터는 악세서리에서 가장 많은 구매가 이루어진 것을 확인할 수 있었습니다. 또한 구매를 한 가격대 또한 어느정도 되는 것을 확인할 수 있었습니다 (악세서리의 평균 판매 가격이 높았기 때문이지 않을까 싶습니다).
03. 마무리하며
이번 실습을 통해 클러스터링 과정에 관해 더 자세히 알 수 있는 시간이었습니다. 특히 데이터를 가공하는 과정은 따로 템플릿을 만들어 깃헙에 저장해놓았을 정도로 까먹지 않고 싶은 부분이었습니다.
또한 저는 그로스 해킹에 대해서도 관심이 많았습니다. 퍼널 분석 혹은 AARRR 프레임워크에서 코호트별 다양한 관점으로 데이터를 분석하는 것이 중요하다는 것을 책에서 읽었었습니다 (book review 그로스 해킹 글에서 확인할 수 있습니다). 분명 구글 애널리틱스, 옵티마이즐링 등의 툴을 통해서 사용자 행동 로그별 데이터 분석을 수행할 수도 있지만, raw 데이터를 추출해 분석이 필요한 경우도 있을 것입니다. 그럴때 해당 과정에서 심화하여 분석을 진행한다면 분석툴에서 얻지 못하는 또 다른 인사이트를 얻을 수 있지 않을까 싶습니다.
부족한 글 읽어주셔서 감사합니다:)
