
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 8번째 미니 프로젝트에서는 공조기기 전력 사용 상태 분석을 진행했습니다!
공장에는 다양한 설비들이 있는데, 설비들의 관리가 제품 상태에 큰 영향을 끼치기 때문에 설비들의 건강상태를 예측하는 일은 매우 중요한 일이라고 합니다. 그래서 이번에는 설비들에 달려있는 센서가 가지고 있는 데이터 분석을 통해 SOH (state of health)에 대해 예측할 수 있는 모델링을 진행해보았습니다.
그 중에서도 이번 글에서 자세하게 다뤄보고 싶은 포인트는 다중공선성에 대한 내용입니다. 제가 책에서 배웠을때는 VIF가 3이상인 변수는 삭제하는 것이 좋다라고 배웠습니다. 하지만 이번 미니 프로젝트의 데이터는 VIF가 3을 넘는 변수가 대부분이었는데요, 그러면 많은 변수를 삭제하고 몇개의 변수만 가지고 모델링을 해야할까요?
이번 미니 프로젝트에서 해당 부분을 어떻게 진행했는지 소개해드리고자합니다!
02. 미니 프로젝트 진행과정
VIF 진행과정을 소개하기에 앞서 전체 진행과정에 대해 먼저 소개해드리겠습니다.
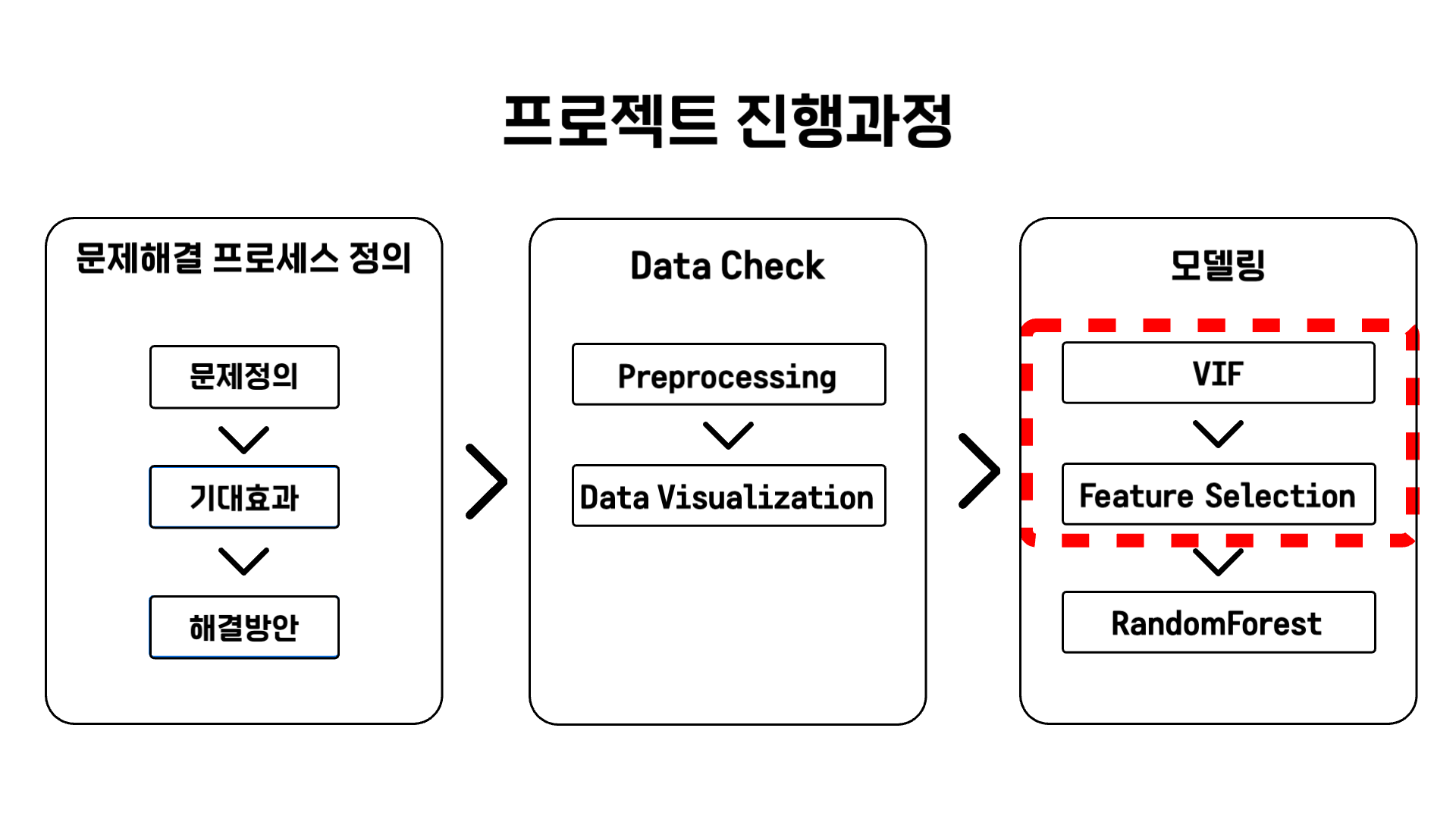
먼저 문제해결 프로세스 정의 단계에서 1) 문제정의 2) 기대효과 3) 해결방안을 정리했습니다.
-
이 미니 프로젝트에서 풀고자 하는 문제 (현실)는 생산설비의 이상상태를 미리 예측하고자 하는 것입니다.
설비에 문제가 생길 경우 설비를 멈추고 조치를 취해야 하나, 이때는 생산이 중단되어 두가지 손실이 발생하게 됩니다. 첫번째로는 당연하게도 수리비용이 발생하고 더 큰 문제로는 정지시간동안 생산을 못하게되어 손실이 발생하게 됩니다.
때문에 회사에서는 각 설비의 건강상태를 예측하여 사전에 수리를 하고자 합니다. -
이 문제를 해결함으로서 기대되는 효과는 첫번째로 생산 안정성을 확보할 수 있게 됩니다. 사전에 수리를 하고자 계획을 하고 설비를 멈추는 것과 문제가 발생했을 때 계획을 하지 않고 설비를 멈추는 것은 안정성 면에서 큰 차이가 있을 것이기 때문입니다.
두번째로는 다운타임 (생산을 못하게 되는 시간)의 감소를 통해 전체 비용 절감의 효과를 기대할 수 있게 될 것입니다. -
해결방안으로는 1) 수집된 데이터를 분석할 수 있는 형태로 변형 후 2) 모델링 및 성능평가를 통해 설비의 정상/주의/경고 상태를 예측하는 것입니다.
이번 미니 프로젝트에서는 데이터가 Json 형태로 되어있었습니다. 이는 데이터 저장에 있어 더 많은 flexibility를 확보할 수 있는 NoSQL에 데이터가 저장되어 있던 데이터를 가져왔기 때문입니다.
다음으로 Data Check 단계에서는 1) 데이터 전처리 과정과 2) 데이터 시각화 과정을 거쳤습니다.

-
전처리 단계에서 Json 형태의 데이터를 분석에 사용할 수 있도록 Pandas의 데이터 프레임으로 변경했습니다. 이후 따로 떨어져있던 데이터 파일에서 label을 합쳐주었습니다.
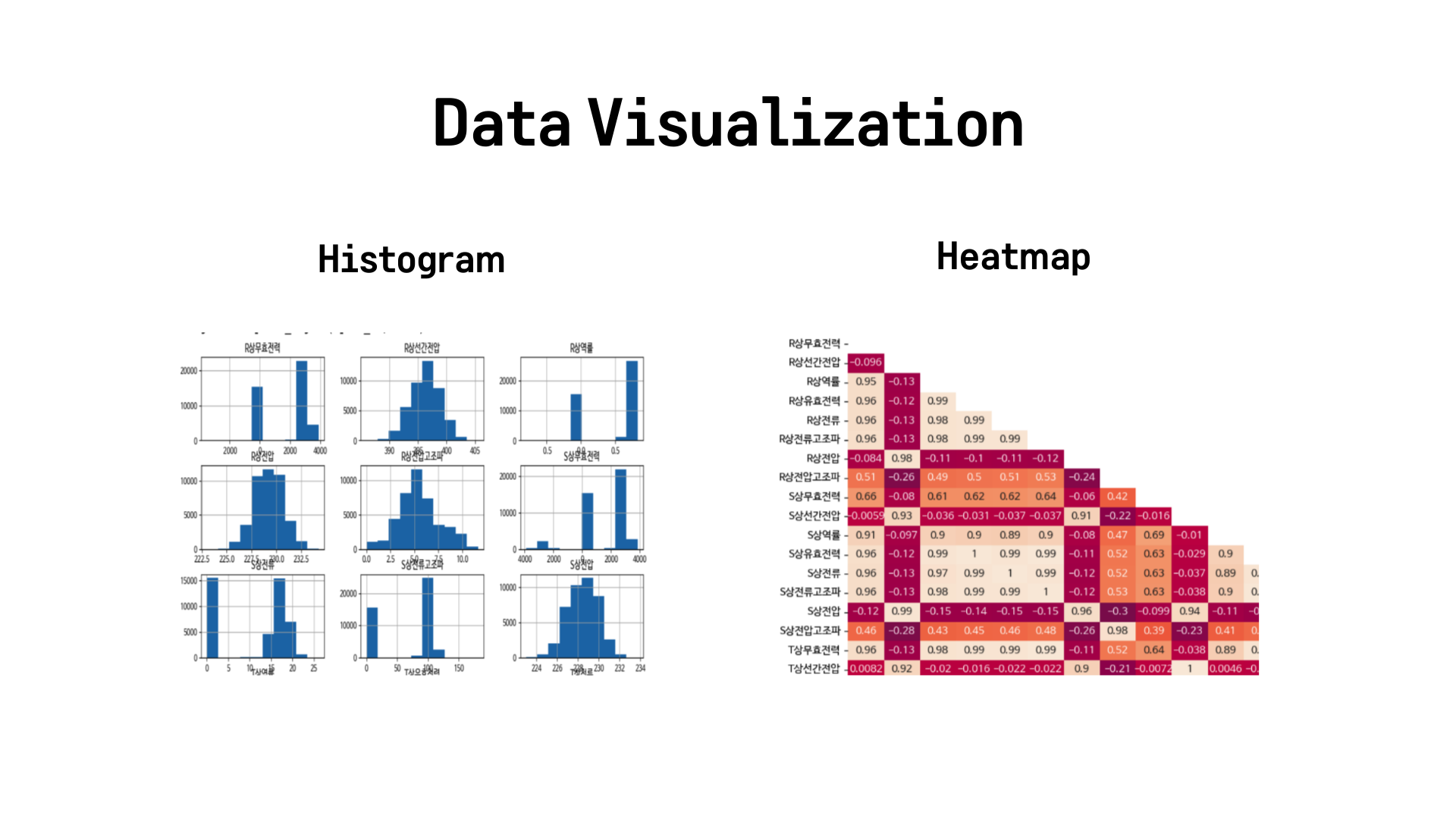
-
데이터 시각화 단계에서 히스토그램과 히트맵을 그리며 feature들의 분포와 feature와 label의 상관관계, featuer들간의 상관관계를 파악할 수 있었습니다.
그런데 시각화 단계에서 발견할 수 있었던 점은 feature들간에 다중공선선이 존재한다는 것을 알 수 있었습니다. 데이터분포가 비슷한 feature들이 있었고, heatmap을 봤을 때 상관관계가 0.9를 넘어가는 변수들이 많았습니다.
그렇다면 이 변수들은 어떻게 해야할까요? 다음 단계인 Modeling 단계에서 이 부분을 어떻게 진행했는지 소해드리겠습니다.
03. VIF & Modeling
다중공선성의 유무를 확인하기 위해 앞서 Histogram,Heatmap과 더불어 VIF점수를 구했습니다.

35개 feature들의 VIF 점수를 구한 결과 4개를 제외한 나머지 featuer들의 점수가 모두 10점을 넘어갔습니다. 보통 VIF 점수가 5가 넘어간 feature들은 삭제하는 등으로 feature selection 과정을 거치게 되는데, 이렇게 되면 대부분의 featuer를 삭제하게 되어 모델링을 하기 어려울 상황에 처했습니다. (VIF가 높으면 각각 feature들의 설명력이 약해집니다!)
공장 도메인 지식에 의하면 설비에 들어가는 3성 모터의 경우 R, S, T 3종류의 전력 (전류)가 발생하는데, 한 모터에서 전력이 나오기 때문에 상관관계가 서로 높을 수 밖에 없다고 합니다.
그렇다면 어떻게 해야할까요? VIF에 관해 배운내용에 의하면 많은 feature들을 쓸 수 없겠지만 결국 모델링을 해야하기 때문에 우선 모든 feature들을 넣어 모델에 집어넣었습니다. (여기서는 RandomForestClassifier를 사용했습니다.)

1차로 모델링을 한 결과, test 셋에대하여 0.9859가 나왔습니다. 다중공선성 문제로 인해 변수들 각각의 설명력이 약해져 더 낮은 점수가 나올것이라 예상했지만, 변수들간에 시너지가 생겨 모델의 성능이 높게 나온것 같습니다. 이를 통해 다수의 feature들간에 다중공선성이 존재해도 모델의 성능이 급격히 떨어지지 않을 수 있다는 것을 알 수 있었습니다.
이후에는 feature importance 점수를 구하여 35개 feature들 중 상위 20개의 feature들만 뽑아서 모델링을 진행해보았습니다. 그 결과 모델의 성능은 크게 변하지 않았습니다. (0.9850)
마지막으로 상위 15개의 feature들로 모델링을 한 결과는 20개 feature들로 모델링을 한 결과보다 더 높은 0.9857을 기록했습니다. 물론 feature를 35개 사용했을 때보다는 성능이 조금 떨어졌지만, 20개를 사용했을때보다 성능이 높은 것으로 보니 20개를 사용했을 때는 노이즈가 어느정도 섞여있었다는 것을 짐작해볼 수 있었습니다.
04. 정리하며
이번 미니 프로젝트에서 배운내용을 정리하면, 다중공선성이 높은 변수들이 많다면 변수들을 제거하는 것으로 시작하는 것이 아니라, 먼저 모델링을 통해 결과를 확인한 후 feature importance에 기반하여 변수들을 selection하는 것을 생각해볼 수 있다는 것이었습니다.
또한 변수들의 숫자를 feature importance에 기반하여 줄이면서 모델의 성능을 유지할 수 있디먄, 변수를 적게 사용하기 때문에 배포를 했을 때 메모리 사용량을 줄일 수 있어 데이터 엔지니어링 관점에서 최적화에 기여할 수 있다는 것도 배울 수 있었습니다.
때문에 앞으로 다른 프로젝트 등을 진행할 때 최대한 많은 변수를 넣어서 모델의 성능을 높이는 것보다 최대한 변수들의 다이어트(?)를 통해 시스템 최적화에도 기여할 수 있는 분석가가 될 수 있도록 해야겠다는 것을 느꼈습니다.
많이 부족하지만 읽어주셔서 감사합니다. 피드백은 언제나 환영입니다:)
