
해당 포스트는 패스트 캠퍼스에 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝 SIGNATURE를 공부한 뒤 복습을 위해 각색하여 작성하였습니다.
01. 시작하며
이번 7번째 미니 프로젝트에서는 신용카드 이상거래 탐지에 대해 다루었습니다.
이전에 해당 내용을 비지도 학습으로 분류를 하는 방법으로 배운 적이 있었는데, 이번 데이터는 레이블링이 되어있어 지도학습으로 진행했습니다.

첫번째로 문제해결 프로세스를 정의했습니다. 해결하고자 하는 문제가 무엇인지, 그에 대한 기대효과는 무엇인지, 그리고 어떻게 해결을 할 수 있는지에 대하여 정리했습니다.
다음으로 데이터 및 데이터 분포를 보며 undersampling 작업을 진행했습니다. 이후 히스토그램 및 히트맵을 그리며 레이블 간 feature들의 데이터 분포 및 상관관계를 확인했습니다.
세번째로는 모델링을 진행하며 해당 미니 프로젝트에서 사용하는 데이터에 부합하는 모델은 어떤 것이 있을지 확인하는 작업을 거쳤습니다.
마지막으로는 데이터 불균형이 존재하여 모델링의 성능이 좋아질까 하여 oversampling을 진행했습니다.
02. 문제해결 프로세스 정의

이번 미니 프로젝트에서 해결하고자 하는 현실 (문제)은 신용카드 이상거래입니다. 많은 금융기관에서 시간, 장소 등의 특정 조건과 개인의 거래 특성에 기반하여 트리거를 만들어 경보 시스템을 만들어 운영하고 있습니다.
이와같은 방법을 통해서도 이상거래를 탐지할 수 있는 방법이 있지만, 다양한 Feature를 활용하여 복합적인 상황에서의 이상거래를 탐지하기 위한 모델을 만들고자 합니다.
그래서 이번 미니 프로젝트 후에는 이상거래 탐지모델 개발을 통한 새로운 탐지 기능 적용과 이상거래를 통해 발생하는 고객의 피해 금액을 감소시키는 효과를 기대할 수 있습니다.
이에 대한 해결방안으로는 먼저 Data를 확인하며 데이터를 모델링에 사용할 수 있는 상태로 변형하는 것입니다. 다음으로는 여러 모델을 사용하며 사용하는 데이터 분포에 가장 적합한 모델을 찾습니다. 이후 데이터의 imbalanced 한 특성을 고려한 oversampling을 하여 모델의 성능을 높일 수 있을지 확인합니다.
마지막으로는 성능을 확인하며 최종 모델을 선택하는 과정을 거칩니다.
그럼 다음으로 데이터를 확인하는 과정을 소개하고자 합니다.
03. Data Check

해당 문제는 Positive인 이상거래와 Negative인 정상거래를 구분하는 문제로 Binary Classification을 통해 진행했습니다.
하지만 클래스의 불균형이 크다는 것을 알 수 있습니다. 때문에 불균형 문제를 해소하기 위해 대표적인 방법 중 하나인 undersampling을 진행했습니다. 이때 Positive와 Negative의 undersampling을 비율을 동일하게 5%로 하여 각 레이블 간의 데이터 분포를 동일하게 가져갔습니다 (99.82% vs. 0.176%)/
다음으로 Feature들의 Positive와 Negative 간 분포를 Distplot을 통해 그렸습니다.
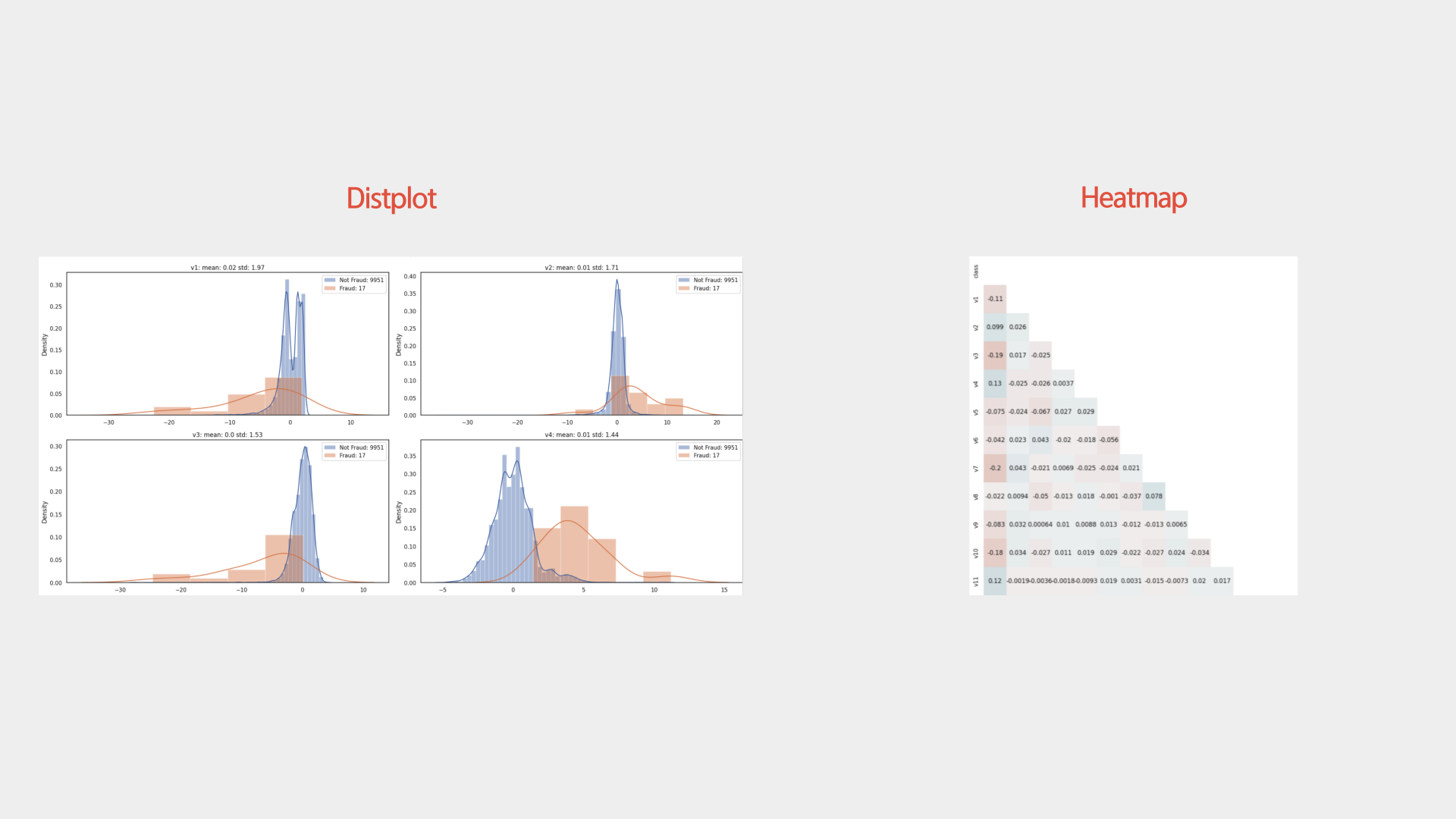
해당 히스토그램을 보며 각 Feature들 중 레이블을 분류하는 결정 경계를 그리는 데 유용한 Feature가 어떤 것일지 짐작할 수 있었습니다. 예를 들어, 위의 두 분포를 그리는 2개의 Feature보다는 아래의 2개의 Feature가 레이블 간 분포가 더 잘 떨어져있어 분류에 더 유용한 Feature가 될 것이라는 것을 짐작할 수 있습니다.
다음으로는 Feature들과 레이블간, 또한 Feature들간의 상관관계를 파악하기 위해 Heatmap을 그렸습니다. 확인해보니 눈에 띄게 다중 공선성을 가지는 Feature들은 찾지 못했습니다.
다음으로는 Undersampled된 데이터로 모델링을 진행한 과정을 소개해드리겠습니다.
04. Modeling
여러 모델들을 비교하기 전에 (베이스) 모델을 만드는 과정은 다음과 같습니다.
이전 미니 프로젝트에서도 소개해드렸다시피, 먼저 GridSearchCV를 통해 하이퍼 파라미터를 설정했습니다.
이후 5-fold Cross Validation을 통해 score를 평균, 편차, 2.5% quantile, 97.5% 별로 나타내었습니다.
다음으로는 성능을 나타내기 위해 Confusion Matrix와 Classification Report로 각각 미탐, 오탐이 어떻게 되는지와 Precision, Recall, F1-score를 확인했습니다.
위 모델링 과정을 거쳐 나온 결과는 다음과 같습니다.
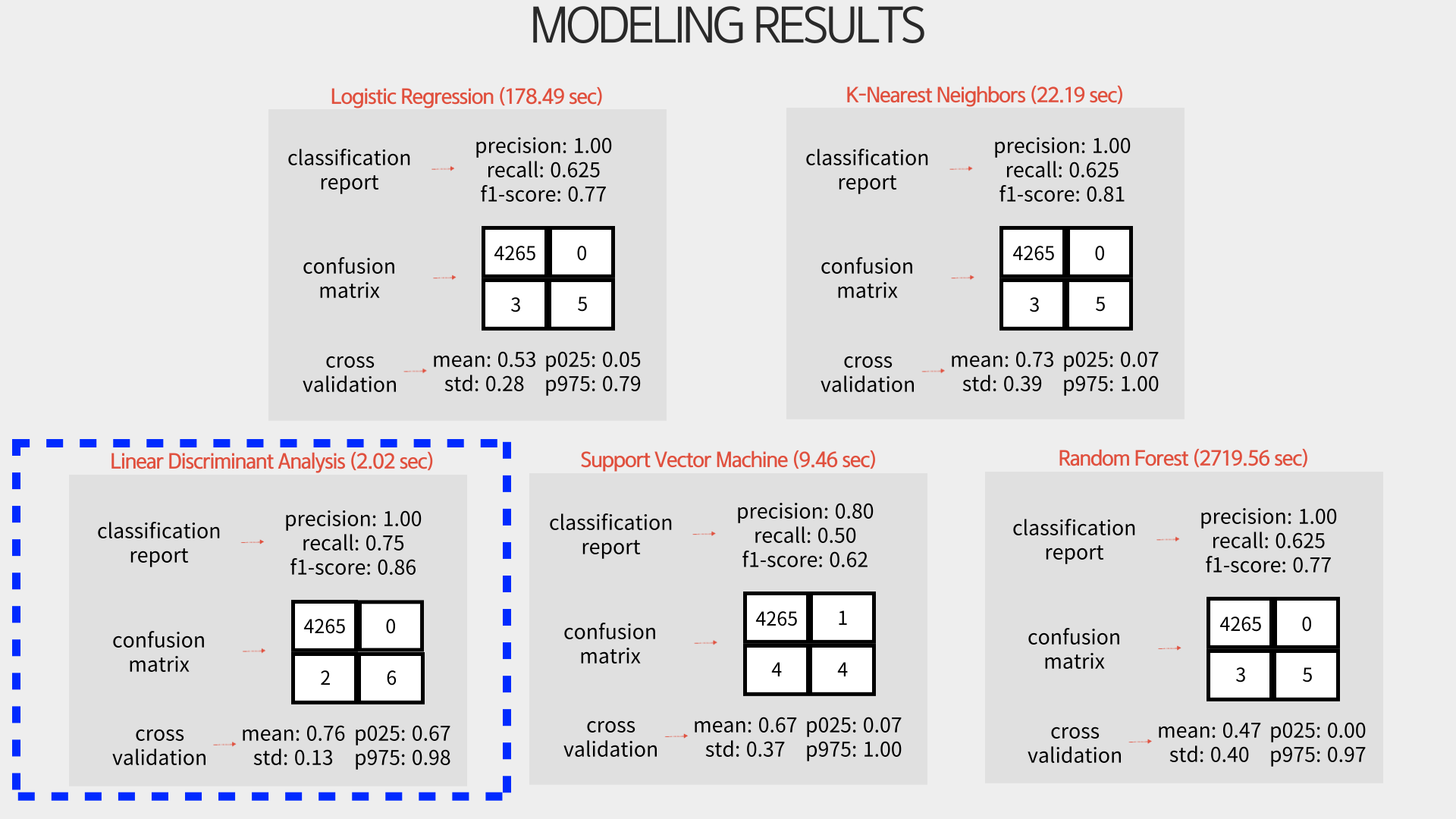
5개의 모델을 통해 모델링을 진행했을 때 Linear Discriminant Analysis (선형판별분석)이 가장 좋은 결과를 나타내었습니다. Recall 점수도 0.75로 가장 높은 성능을 나타내었으며 (이상탐지에서 중요한 지표) f1-score도 0.86으로 높은 성능을 보여주었습니다.
또한 5-fold cross validation의 결과를 보면 평균이 0.76으로 가장 높고, 편차 또한 0.13으로 가장 낮은 것을 확인할 수 있었습니다. 해당 결과를 통해 LDA가 해당 데이터에 가장 적합한 모델임을 알 수 있었습니다.
시간 또한 2.02초로 다른 모델들보다 압도적인 성능을 보여주는 것을 알 수 있습니다.
하지만 해당 데이터는 imbalance 하므로 이 데이터의 Positive와 Negative의 1:1 비율로 맞추면 성능이 올라갈까?라는 의문이 들 수 있습니다. 그래서 다음 단계에서 oversampling을 진행해보았습니다.
05. Oversampling
LDA를 통해 oversampling한 결과는 다음과 같습니다.
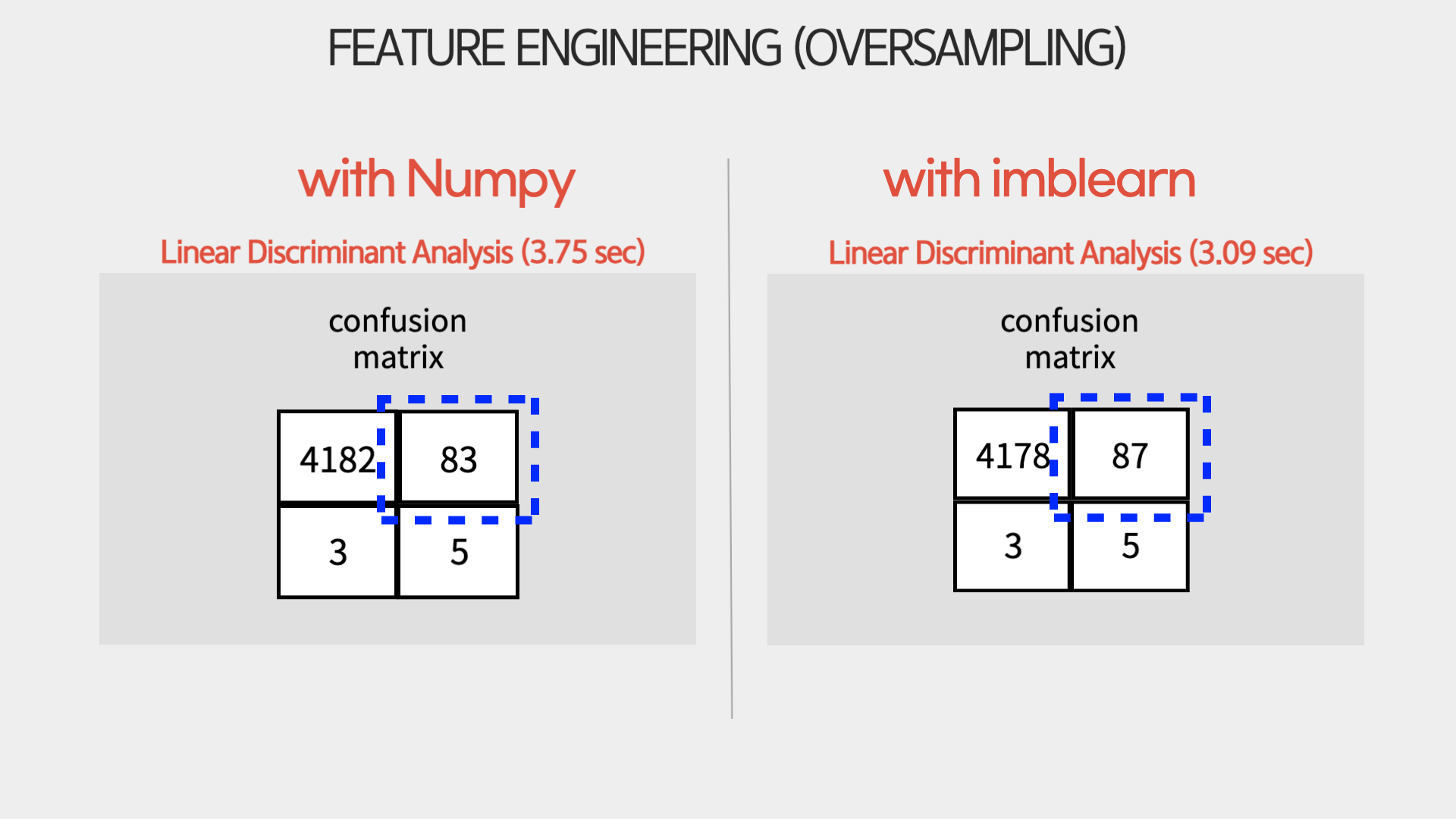
두 결과 동일하게 oversampling을 하기 전보다 오탐(False Positive) 숫자가 높아진 것을 알 수 있습니다. 또한 미탐 (False Negative) 또한 2에서 3으로 하나 더 늘어난 것을 확인할 수 있었습니다.
이를 통해 데이터 비율을 맞추고자 oversampling을 한다고 해도 성능이 좋아지는 건 아니라는 것을 배울 수 있었습니다.
06. 마무리하며
이번 미니 프로젝트에서는 클래스의 비율이 imbalance한 이상거래 탐지에 대한 내용을 다루었습니다.
클래스의 imbalance를 해결하고자 할 때는 먼저 undersampling 방법을 고려하여 진행하는 것은 괜찮아보였지만, oversampling을 통해 비율을 맞추는 것은 성능을 높이는데 꼭 기여하는 것은 아니라는 것을 알 수 있었습니다.
이전에 클래스가 imbalance한 경우 오버샘플링을 고려하세요!라는 것을 어디선가(?) 본적이 있어 시도해봐야지 라는 생각을 가지고 있었습니다. 그런데 이번 미니 프로젝트 수행을 통해 항상 도움이 되는 것이 아니고 심지어 최근에는 잘 사용하지 않는다는 것 또한 배울 수 있었습니다.
다음에 비슷한 문제 혹은 데이터 분포를 마주했을 때 다시 적용해보며 오버샘플링 & 언더샘플링을 적용하여 문제를 해결해봐야겠다는 것을 느꼈습니다!
부족하지만 여기까지 읽어주신 분들께 감사드립니다:) 피드백 환영합니다!

좋은 글이네요. 공유해주셔서 감사합니다.