1 오목이란
: 오목은 19x19 크기의 바둑판 위에 돌을 놓아 가로, 세로, 대각선으로 연속된 다섯 개의 돌을 먼저 만드는 사람이 이기는 게임이다.
2 omok-ai 프로젝트
2.1 목표
: 알파고(AlphaGo)와 알파고 제로(AlphaGo Zero)의 방법론을 모방하여 오목 인공지능(AI)을 구현한다.
2.2 Train 단계
2.2.1 방법론
학습을 위해 3가지 방법론을 활용했다.
1 정책망(Policy Network)
알파고(AlphaGo)에서 사용된 방법론으로, 현재 오목판의 상태(state)를 입력받아 각 위치에 대한 기댓값을 계산한다. 기댓값이 크다는 것은 자신 또는 상대가 착수하기 좋은 위치를 의미한다.
2 자가 대국(self-play)을 통한 학습
알파고 제로(AlphaGo Zero)에서 사용된 방법론으로, 자가 대국을 통해서 생성한 플레이 데이터만을 사용하여 정책망을 학습한다. 인간의 플레이 데이터를 전혀 사용하지 않았음에도, 알파고 제로는 알파고보다 뛰어난 성능을 보여주었다.
3 MCTS(Monte Carlo Tree Search : 몬테카를로 트리 탐색) 알고리즘
알파고와 알파고 제로에서 사용된 방법론으로, 다양한 경우의 수를 탐색하여 최종적으로 착수 위치를 결정한다.
2.2.2 코드 해석
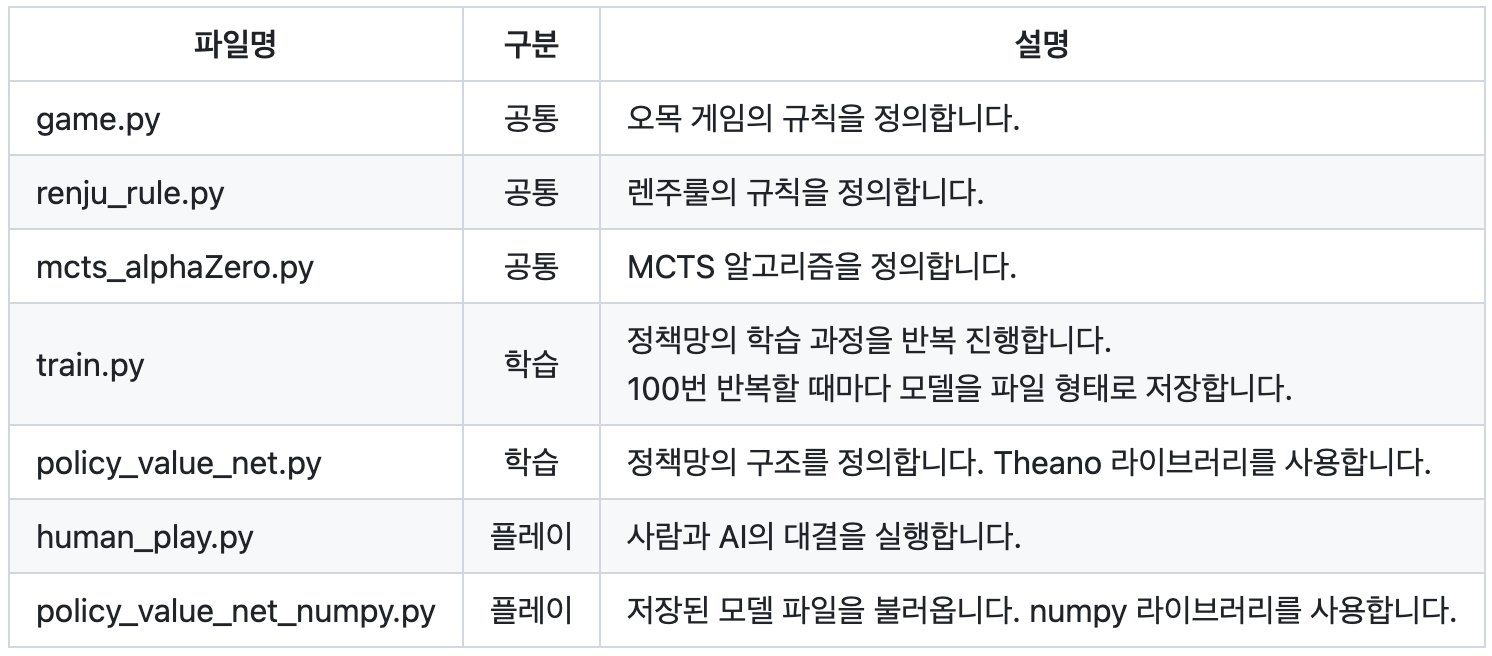 git에 들어있는 각 파일들의 역할은 다음과 같다.
git에 들어있는 각 파일들의 역할은 다음과 같다.
1 game.py
이 파일은 Board와 Game 2가지 클래스로 구성되어있다.
- Board 클래스: 보드 상태 관리, 금수 위치 계산, 승자 확인 등의 기능을 포함.
def __init__(self, **kwargs):
self.width = int(kwargs.get('width', 15))
self.height = int(kwargs.get('height', 15))
self.n_in_row = int(kwargs.get('n_in_row', 5))
self.players = [1, 2] # player1 and player2--> 게임 보드 상태에 대한 기본적인 설정
: 가로 15칸, 세로 15칸, 5개의 돌이 연속일 때 승리, 2명의 플레이어.
def init_board(self, start_player=0) :
self.order = start_player # order = 0 → 사람 선공(흑돌) / 1 → AI 선공(흑돌)
self.current_player = self.players[start_player] # current_player = 1 → 사람 / 2 → AI
self.last_move, self.last_loc = -1, -1
self.states, self.states_loc = {}, [[0] * self.width for _ in range(self.height)]
self.forbidden_locations, self.forbidden_moves = [], []--> 게임 초기화
: 선공 정하기(0은 사람, 1은 AI), 현재 상태와 금수 초기화.
def move_to_location(self, move):
""" 3*3 보드를 예로 들면 : move 5 는 좌표 (1,2)를 의미한다.""" # ex) 0 1 2
h = move // self.width # 3 4 5
w = move % self.width # 6 7 8
return [h, w]
def location_to_move(self, location):
if len(location) != 2 : return -1
h, w = location[0], location[1]
move = h * self.width + w
if move not in range(self.width * self.height) : return -1
return move--> 위치 정보의 차원 간 변환
: 바둑판에서 플레이어의 위치를 move는 1차원으로, locataion은 2차원으로 표현.
def current_state(self):
"""현재 플레이어의 관점에서 보드 상태(state)를 return한다.
state shape: 4 * [width*height] """
square_state = np.zeros((4, self.width, self.height))
if self.states:
moves, players = np.array(list(zip(*self.states.items())))
move_curr = moves[players == self.current_player]
move_oppo = moves[players != self.current_player]
square_state[0][move_curr // self.width, move_curr % self.height] = 1.0 #내가 둔 돌의 위치를 1로 표현
square_state[1][move_oppo // self.width, move_oppo % self.height] = 1.0 #적이 둔 돌의 위치를 1로 표현
square_state[2][self.last_move // self.width, self.last_move % self.height] = 1.0 #마지막 돌의 위치
if len(self.states) % 2 == 0 : square_state[3][:, :] = 1.0 # indicate the colour to play
return square_state[:, ::-1, :]--> 현재 보드 상태를 4개의 채널로 표현
square_state[0]: 현재 플레이어의 돌 위치,
square_state[1]: 상대 플레이어의 돌 위치,
square_state[2]: 마지막으로 놓인 돌의 위치,
square_state[3]: 현재 플레이어의 차례를 표시
def do_move(self, move):
self.states[move] = self.current_player
loc = self.move_to_location(move)
self.states_loc[loc[0]][loc[1]] = 1 if self.is_you_black() else 2
self.current_player = (self.players[0] if self.current_player == self.players[1] else self.players[1])
self.last_move, self.last_loc = move, loc--> 플레이어의 움직임 적용
: 주어진 위치에 돌을 두고, 보드 상태를 업데이트. 그리고 현재 플레이어를 변경.
def has_a_winner(self):
width = self.width
height = self.height
states = self.states
n = self.n_in_row
# moved : 이미 돌이 놓인 자리들
moved = list(self.states.keys())
if len(moved) < self.n_in_row * 2-1 : return False, -1
for m in moved:
h = m // width
w = m % width
player = states[m]
if (w in range(width - n + 1) and
len(set(states.get(i, -1) for i in range(m, m + n))) == 1):
return True, player
if (h in range(height - n + 1) and
len(set(states.get(i, -1) for i in range(m, m + n * width, width))) == 1):
return True, player
if (w in range(width - n + 1) and h in range(height - n + 1) and
len(set(states.get(i, -1) for i in range(m, m + n * (width + 1), width + 1))) == 1):
return True, player
if (w in range(n - 1, width) and h in range(height - n + 1) and
len(set(states.get(i, -1) for i in range(m, m + n * (width - 1), width - 1))) == 1):
return True, player
return False, -1
def game_end(self):
win, winner = self.has_a_winner()
if win : return True, winner
elif len(self.states) == self.width*self.height : return True, -1
return False, -1
--> 승리 조건과 종료 조건 확인
: 현재 상태를 2차원 배열로 표현한 뒤 수직, 수평, 대각선 방향으로 연속된 5개의 돌이 있는지 확인. 승자가 있는지, 더이상 돌을 놓을 있는지, 없는지 판단하고 게임 종료를 선언.
def set_forbidden(self) :
# forbidden_locations : 흑돌 기준에서 금수의 위치
rule = Renju_Rule(self.states_loc, self.width)
if self.order == 0 : self.forbidden_locations = rule.get_forbidden_points(stone=1)
else : self.forbidden_locations = rule.get_forbidden_points(stone=2)
self.forbidden_moves = [self.location_to_move(loc) for loc in self.forbidden_locations]--> 금수 위치 반환
: 플레이어가 흑돌인지 백돌인지 확인한 뒤, 금수의 위치를 출력.
- Game 클래스: 게임 진행, 그래픽 출력, 플레이어 간 상호작용 관리.
def graphic(self, board, player1, player2):
width = board.width
height = board.height
clear_output(wait=True)
os.system('cls')
print()
if board.order == 0 :
print("흑돌(●) : 플레이어")
print("백돌(○) : AI")
else :
print("흑돌(●) : AI")
print("백돌(○) : 플레이어")
print("--------------------------------\n")
if board.current_player == 1 : print("당신의 차례입니다.\n")
else : print("AI가 수를 두는 중...\n")
row_number = ['⒪','⑴','⑵','⑶','⑷','⑸','⑹','⑺','⑻','⑼','⑽','⑾','⑿','⒀','⒁']
print(' ', end='')
for i in range(height) : print(row_number[i], end='')
print()
for i in range(height):
print(row_number[i], end='')
for j in range(width):
loc = i * width + j
p = board.states.get(loc, -1)
if p == player1 : print('●' if board.order == 0 else '○', end='')
elif p == player2 : print('○' if board.order == 0 else '●', end='')
elif board.is_you_black() and (i,j) in board.forbidden_locations : print('Ⅹ', end='')
else : print(' ', end='')
print()
if board.last_loc != -1 :
print(f"마지막 돌의 위치 : ({board.last_loc[0]},{board.last_loc[1]})\n")--> 보드의 현재 상태 시각화
def start_play(self, player1, player2, start_player=0, is_shown=1):
self.board.init_board(start_player)
p1, p2 = self.board.players
player1.set_player_ind(p1)
player2.set_player_ind(p2)
players = {p1: player1, p2: player2}
while True:
# 흑돌일 때, 금수 위치 확인하기
if self.board.is_you_black() : self.board.set_forbidden()
if is_shown : self.graphic(self.board, player1.player, player2.player)
current_player = self.board.get_current_player()
player_in_turn = players[current_player]
if current_player == 1 : # 사람일 때
move = player_in_turn.get_action(self.board)
else : # AI일 때
move = player_in_turn.get_action(self.board)
self.board.do_move(move)
end, winner = self.board.game_end()
if end:
if is_shown:
self.graphic(self.board, player1.player, player2.player)
if winner != -1 : print("Game end. Winner is", players[winner])
else : print("Game end. Tie")
return winner--> 게임 시작
: 기본 설정을 초기화. 종료 조건에 도달할 때까지 1 플레이어가 흑인지 백인지 확인, 2 금수의 위치를 계산, 3 플레리어의 수 입력 과정을 계속 반복.
def start_self_play(self, player, is_shown=0, temp=1e-3):
""" 스스로 자가 대국하여 학습 데이터(state, mcts_probs, z) 생성 """
self.board.init_board()
p1, p2 = self.board.players
states, mcts_probs, current_players = [], [], []
while True:
# 흑돌일 때, 금수 위치 확인하기
if self.board.is_you_black() : self.board.set_forbidden()
if is_shown : self.graphic(self.board, p1, p2)
move, move_probs = player.get_action(self.board, temp=temp, return_prob=1)
# store the data
states.append(self.board.current_state())
mcts_probs.append(move_probs)
current_players.append(self.board.current_player)
# perform a move
self.board.do_move(move)
end, winner = self.board.game_end()
if end:
# winner from the perspective of the current player of each state
winners_z = np.zeros(len(current_players))
if winner != -1:
winners_z[np.array(current_players) == winner] = 1.0
winners_z[np.array(current_players) != winner] = -1.0
# reset MCTS root node
player.reset_player()
if is_shown:
self.graphic(self.board, p1, p2)
if winner != -1 : print("Game end. Winner is player:", winner)
else : print("Game end. Tie")
return winner, zip(states, mcts_probs, winners_z)--> self play 시작
: states, mcts_probs를 활용해 AI 혼자 대국을 진행하며 학습 데이터 만듦.
2 mcts_alphaZero.py
: MCTS(몬테카를로 트리 탐색)이란, Monte Carlo + Tree search의 약자로 어떤 상태에서 게임이 종료될 때까지 모든 경우의 수를 전부 탐색하지 않고, Monte Carlo 기반 시뮬레이션을 통해 랜덤한 수를 두어가며 게임을 끝까지 진행하기를 반복하는 강화학습법이다.
코드는 TreeNode, MCTS, MCTSPlayer 3가지 클래스로 구성된다.
- TreeNode 클래스
def __init__(self, parent, prior_p):
self._parent = parent
self._children = {} # a map from action to TreeNode
self._n_visits = 0
self._Q = 0
self._u = 0
self._P = prior_p--> 트리 초기화
def expand(self, action_priors, forbidden_moves, is_you_black):
"""Expand tree by creating new children.
action_priors: a list of tuples of actions and their prior probability according to the policy function.
"""
for action, prob in action_priors:
# 흑돌일 때 금수 위치는 트리 탐색을 하지 않도록
if is_you_black and action in forbidden_moves : continue
if action not in self._children : self._children[action] = TreeNode(self, prob)--> 금수 위치를 제외하고 자식 노드 확장
def select(self, c_puct):
"""Select action among children that gives maximum action value Q plus bonus u(P).
Return: A tuple of (action, next_node)
"""
return max(self._children.items(), key=lambda act_node: act_node[1].get_value(c_puct))--> 자식 노드 중 Q와 u값이 가장 큰 노드 선택
def update(self, leaf_value):
"""Update node values from leaf evaluation.
leaf_value: the value of subtree evaluation from the current player's perspective.
"""
# Count visit.
self._n_visits += 1
# Update Q, a running average of values for all visits.
self._Q += 1.0*(leaf_value - self._Q) / self._n_visits
def update_recursive(self, leaf_value):
"""Like a call to update(), but applied recursively for all ancestors."""
# If it is not root, this node's parent should be updated first.
if self._parent:
self._parent.update_recursive(-leaf_value)
self.update(leaf_value)--> 리프 노드 값을 기반으로 노드 업데이트
- MCTS 클래스
def __init__(self, policy_value_fn, c_puct=5, n_playout=10000):
"""
policy_value_fn: a function that takes in a board state and outputs
a list of (action, probability) tuples and also a score in [-1, 1]
(i.e. the expected value of the end game score from the current
player's perspective) for the current player.
c_puct: a number in (0, inf) that controls how quickly exploration
converges to the maximum-value policy. A higher value means
relying on the prior more.
"""
self._root = TreeNode(None, 1.0)
self._policy = policy_value_fn
self._c_puct = c_puct
self._n_playout = n_playout--> MCTS 객체 초기화. policy_value_fn은 정책 함수, c_puct는 수렴 속도 제어, n_playout은 플레이아웃 수를 나타냄.
def _playout(self, state):
"""Run a single playout from the root to the leaf, getting a value at
the leaf and propagating it back through its parents.
State is modified in-place, so a copy must be provided.
"""
node = self._root
while(1):
if node.is_leaf() : break
# Greedily select next move.
action, node = node.select(self._c_puct)
state.do_move(action)
# Evaluate the leaf using a network which outputs a list of
# (action, probability) tuples p and also a score v in [-1, 1]
# for the current player.
action_probs, leaf_value = self._policy(state)
end, winner = state.game_end()
if not end : node.expand(action_probs, state.forbidden_moves, state.is_you_black())
else:
# for end state,return the "true" leaf_value
if winner == -1: # tie
leaf_value = 0.0
else:
leaf_value = (1.0 if winner == state.get_current_player() else -1.0)
node.update_recursive(-leaf_value)--> 단일 플레이아웃 실행. 리프의 값을 부모 노드에게 전달.
def get_move_probs(self, state, temp=1e-3):
for n in range(self._n_playout):
state_copy = copy.deepcopy(state)
self._playout(state_copy)
act_visits = [(act, node._n_visits) for act, node in self._root._children.items()]
# print([(state.move_to_location(m),v) for m,v in act_visits])
# acts = 위치번호 / visits = 방문횟수
acts, visits = zip(*act_visits)
act_probs = softmax(1.0/temp * np.log(np.array(visits) + 1e-10))
return acts, act_probs--> 플레이아웃 중 가능한 수와 확률 반환
- MCTSPlayer 클래스
def get_action(self, board, temp=1e-3, return_prob=0):
move_probs = np.zeros(board.width*board.height)
if board.width*board.height - len(board.states) > 0:
# acts와 probs에 의해 착수 위치가 정해진다.
acts, probs = self.mcts.get_move_probs(board, temp)
move_probs[list(acts)] = probs
if self._is_selfplay:
# (자가 학습을 할 때는) Dirichlet 노이즈를 추가하여 탐색
move = np.random.choice(acts, p=0.75*probs + 0.25*np.random.dirichlet(0.3*np.ones(len(probs))))
self.mcts.update_with_move(move)
else:
move = np.random.choice(acts, p=probs) # 확률론적인 방법
self.mcts.update_with_move(-1)
if return_prob : return move, move_probs
else : return move
else:
print("WARNING: the board is full")--> 다음 수 선택.
: 보드 상태를 기반으로 다음 수를 선택. 자가 학습일 경우, Dirichlet 노이즈를 추가하여 탐색함.
2.3 Play 단계
!pip install -r https://raw.githubusercontent.com/Lasagne/Lasagne/master/requirements.txt
!pip install --upgrade https://github.com/Theano/Theano/archive/master.zip
!pip install --upgrade https://github.com/Lasagne/Lasagne/archive/master.zip
!git clone https://github.com/gibiee/omok_AI.git다음과 같은 방식으로 git에 있는 코드를 가져와
%run omok_AI/human_play.py위의 코드를 실행하면 AI와 오목 게임을 진행할 수 있다.

