*파드 스케줄링
- 사용자가 원하는 구조대로 파드들을 클러스터 안에 배치
- 특정 파드 들을 하나의 노드에 모두 모아두기(예 라벨이나 IP대역 )
- 골고루 분산도 가능.
- 관리적인 측면에서도 어떤 노드들을 해당 노드로 이동시킬수 있음.
- key:value 으로 이루어진 기준을 가지고 결정
*마스터 노드의 정보 확인
- kubectl get nodes --show-labels

*node1 노드에 레이블(ssd)추가
- #kubectl label nodes node1.example.com disktype=ssd

*node셀럭터를 이용하여 스케줄링
- #cat nodeselector.yaml
- [root@master scheduling]# kubectl apply -f nodeselector.yaml
- pod/kubernetes-nodeselector-pod created


node selector 설정
- Pod 리소스를 정의하는 yaml 파일 작성
( "disktype: ssd" 라벨을 가진 노드에 배치 )
- kubectl create -f nodeselector.yaml
- ssd 라벨을 가진 node1에 스케줄링하여 파드 생성
*어피니티 / 안티어피니티
- 어피니티 : 파드들을 묶어서 같은 노드에서 실행 되도록 하는것.
- 안티어피니티 : 파드들을 노드에 나누어서 실행 되도록 하는것.
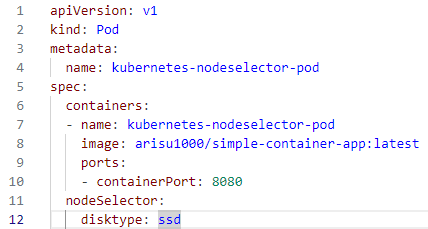
node-affinity.yaml
- requiredDuringSchedulingIgnoredDuringExecution:
⇒ 꼭 필요한 조건들이면서 만족해야 실행 - preferredDuringSchedulingIgnoredDuringExecution:
⇒ 꼭 필요한 조건은 아니면서 만족하지 않아야 실행되는것.
• In :
- values [ ] 필드에 설정한 값 중 레이블에 있는 값과 일치하는 것이 하나라도 있는지 확인
• Notln :
- In과 반대로 values [ ] 필드에 있는값 모두와 맞지 않는지 확인
• Exists :
- values [ ] 필드가 필요없음
- key 필드에 설정한 값이 레이블에 있는지만 확인
- 노드의 레이블에 disktype이라는 커가 있는지만 확인합나다
• DoesNotExist :
- Exists와 반대로 노드의 레이블에 key 펼드 값이 없는지만 확인
• Gt :
- 뜻(Grate than)
- values[ ] 필드에 설정된 값보다 큰 숫자형 데이터인지를 확인합니다
- values [ ] 필드는 배열 타입이지만 이때는 값이 하나만 있어야 함
• Lt:
- 뜻은(Lower than)
- values[ ] 필드에 설정된 값보다 작은 숫자형 데이터인지를확인
- values [ ] 필드는 배열 타입이지만 이때는 값이 하나만 있어야 함
node1 라벨 설정
- kubectl label nodes node1.example.com core=8
- kubectl get nodes node1.example.com --show-labels로 라벨 확인
Pod 리소스 설정
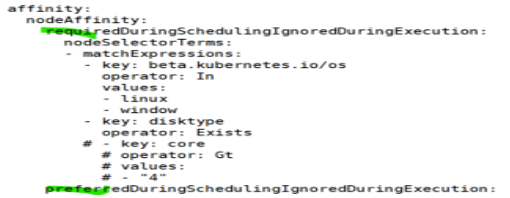
- Pod 리소스를 정의하는 yaml 파일 작성
( 노드 어피니티(Node Affinity)를 설정,
"requiredDuringSchedulingIgnoredDuringExecution" 부분에서는
스케줄링 시 노드 선택에 대한 필수 조건을 정의
"preferredDuringSchedulingIgnoredDuringExecution" 부분에서는
선호하는 조건 정의 )
( 특정 운영 체제 (linux 또는 window)를 가진 노드와 "disktype" 라벨이
존재하는 노드를 필수적으로 선택,
"worker-node01"이라는 호스트네임을 가진 노드를 선호적으로 선택 )
- kubectl create -f node-affinity.yaml
- node1을 선호아여 선택하므로 node1에 컨테이너 생성 확인
⇒ 여기까지는 노드들을 대상으로 스케줄링을 했다면 이제는 파드가 대상이 되어서 스케줄링을 하는 방법
즉 서로 다른 노드에 웹서버가 각각동작 하고 있다면 이러한 웹서버끼리는 통신이 원할 하게 될 수 있도록
스케줄링 하기
*pod들을 대상으로 스케줄링
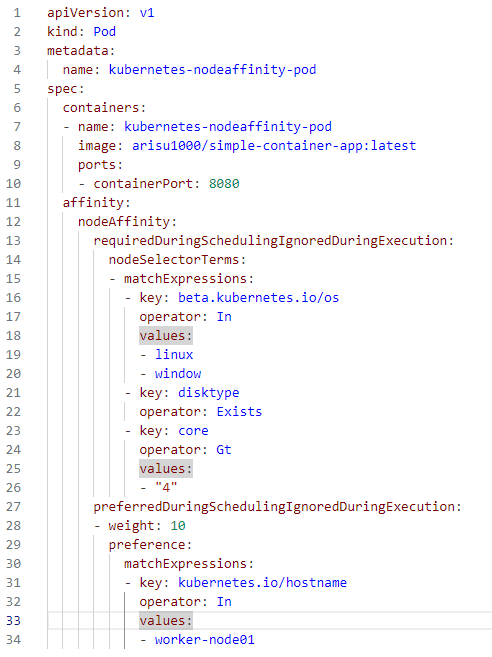
#cat pod-antiaffinity.yaml
- key: app , values: store 부분을 참고 하여 실행되도록 하는것
*파드의 어피니티 / 안티 어피니티
⇒ 여기까지는 노드들을 대상으로 스케줄링을 했다면 이제는 파드가 대상이 되어서 스케줄링을 하는 방법
즉 서로 다른 노드에 웹서버가 각각동작 하고 있다면 이러한 웹서버끼리는 통신이 원할 하게 될 수 있도록
스케줄링 하기

-key: app , values: store 부분을 참고 하여 실행되도록 하는것.
어피니티, 안티 어피니티 설정 ( IN과 NotIn을 통해 실행 가능 )
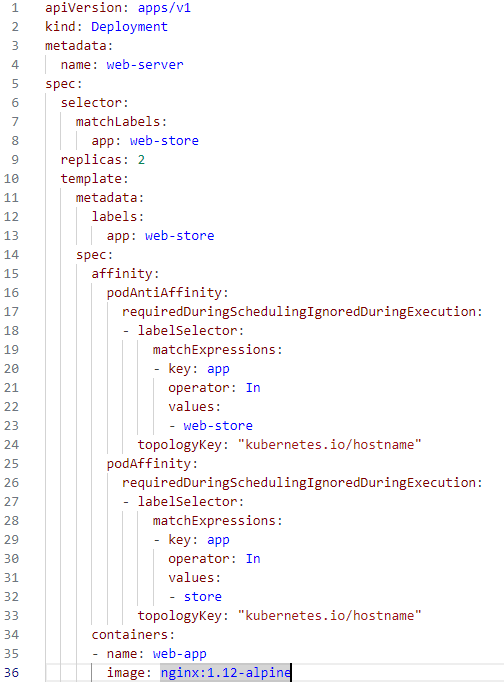
- Deployment 리소스를 정의하는 yaml 파일 작성
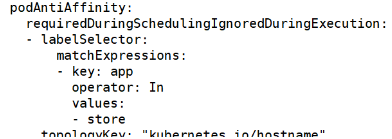
( Deployment에는 "podAntiAffinity"와 "podAffinity"가 모두 설정
( "podAntiAffinity"는 동일한 topologyKey("kubernetes.io/hostname")를 가진
"web-store" 라벨을 가진 Pod들 사이에 안티 어피니티가 적용되도록 설정,
"podAffinity"는 동일한 topologyKey("kubernetes.io/hostname")를 가진
"store" 라벨을 가진 Pod들 사이에 어피니티가 적용 )
- kubectl create -f pod-affinity.yaml
안티 어피니티 설정
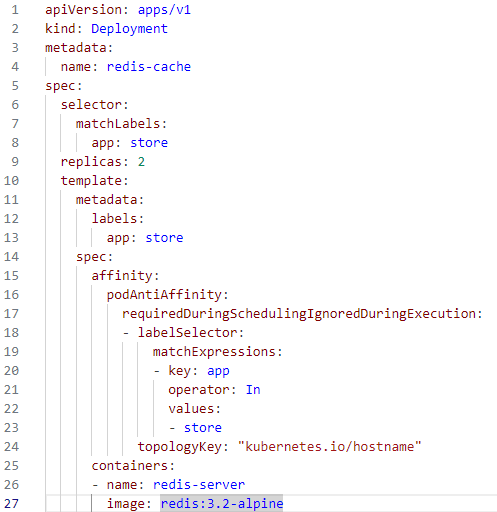
- Deployment 리소스를 정의하는 yaml 파일 작성
( Deployment에는 "podAntiAffinity"가 설정,
스케줄링 시 동일한 topologyKey("kubernetes.io/hostname")를 가진
"store" 라벨을 가진 Pod들 사이에 안티 어피니티가 적용되도록 설정 )
-pod-antiaffinity 실행 시키면 -key: app , values: store 부분을 참고 하여 일치는 파드끼리 한곳으로 모아서 실행 시켜줌 예) 노드-1 : web-store , 노드2: store 파드 3개가 동작
-다시 antiaffinity에서 하나는 web-store로 수정하고 실행 하면 이때는 노드1에는 web-store 두개, 노드 2에는 store가 두개 동작을 하는 방법
*스케줄러 차단 / 해지
⇒ 특정한 노드에는 스케줄러가 적용되지 않도록 설정 = 커든
– 노드2에 스케줄러가 적용되지 않도록
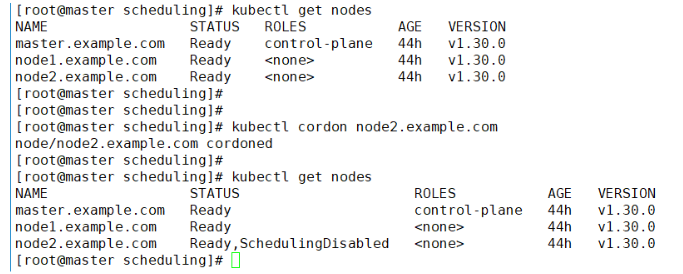
#kubectl cordon node2.example.com ⇒node2 에 대해 스케줄링 차단
node/node2.example.com uncordoned
#kubectl apply -f pod-antiaffinity.yaml
⇒ 실행시키면 node1에만 running node2는 pending 상태가됨.
#kubectl uncordon node2.example.com ⇒ 차단해지 하면 바로 running 으로 동작됨.
*볼륨 (volume ) - 저장소 , 데이터 저장
- 컨테이너 삭제시 데이터가 모두 삭제됨. 재시작을 해도 모두 삭제됨.
- AWS, AzureDisk, AzureFile, iscsi , local, nfs, emptydir , hosts…
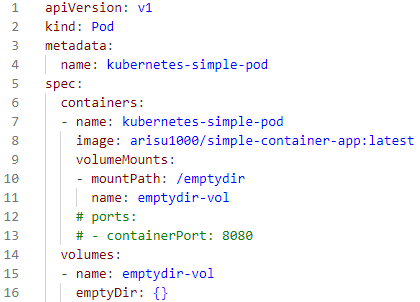
-emptydir : 파드가 실행되는 호스트의 디스크를 임시로 볼륨으로 연결해서 사용
- #cat volume-emptydir.yaml
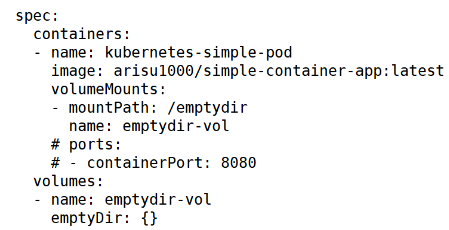
빈 볼륨 설정
- 볼륨을 정의하는 yaml 파일 작성
( emptyDir: 빈 디렉토리 볼륨을 나타내며,
파드 내의 컨테이너 간에 데이터를 공유하는 데 사용 )
( 이 볼륨은 파드 내에서 사용되며, 파드가 삭제되면 데이터도 함께 삭제 )
-hostpath : 파드가 실행된 호스트의 파일이나 디렉터리를 실행된 파드에 마운트 시켜서 사용
- #cat volume-hostpath.yaml
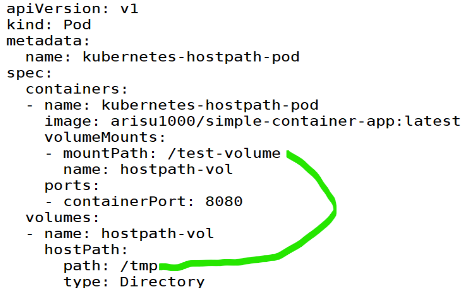
/tmp는 무조건 있어야함.
경로를 사용하는 볼륨 설정
- 볼륨을 정의하는 yaml 파일 작성
( hostPath( node ): 호스트의 파일 시스템 경로를 사용하는 볼륨을 정의 )
( path: 호스트의 디렉토리 경로를 지정합니다. 이 경우에는 /tmp 디렉토리를 지정 )
( type: 볼륨의 유형을 지정합니다. 이 경우에는 Directory로 지정 )
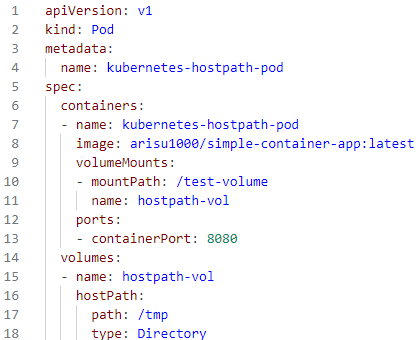
⇒ kubernetes-hostpath-pod 접속 / test-volume 로 이동 해서 파일생성 test.txt 하나 생성
- #kubectl exec -it kubernetes-hostpath-pod -- sh
#cd /test-volume, touch test.txt
⇒ kubernetes-hostpath-pod 파드 삭제 하고 파드가 생성된 호스트 노드에 test.txt 파일 여부 확인
volume 마운트 확인
- kubectl exec -it kubernetes-hostpath-pod -- sh ( 컨테이너 진입 후 )
- cd /test-volume/
- echo 'test' > test.txt
- node1로 진입해서 ls /tmp | grep test 확인
- pods를 삭제해도 volume 보존
*NFS 볼륨 : 가장쉽고, 가장 간단하고, 가장 저렴.
-NFS서버를 만들어 놓고 서버를 에다 파드를 마운트 하는 방식
-여러개의 파드를 하나의 서버에 마운트도 가능함.( 서버의 하드웨어가 성능이 뒷받침이 되어야함 )
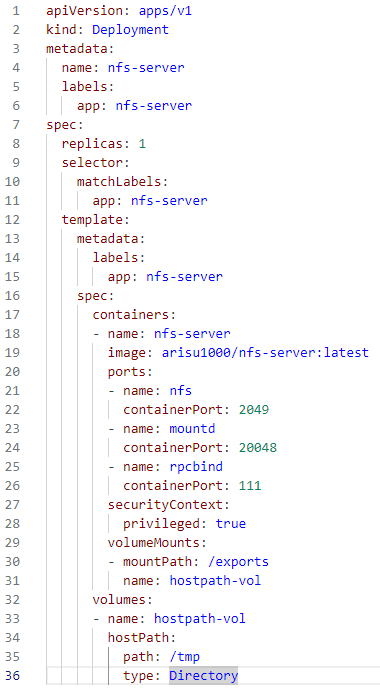
#cat volume-nfsserver.yaml
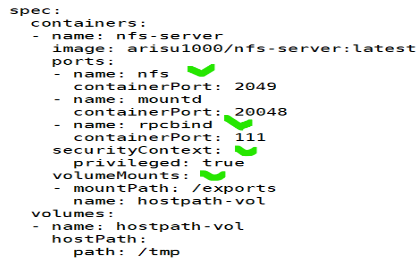
- 포트 지정 / 서비스 관리 부분 / 보안관련 / 마운트 위치 4곳으로 구분
템플릿 동작 시키고, 실행 확인
- #kubectl apply -f volume-nfsserver.yaml
deployment.apps/nfs-server created
NFS 서버 설정
- NFS 서버를 배포하기 위한 쿠버네티스 Deployment를 정의
( hostPath: 호스트의 파일 시스템 경로를 사용하는 볼륨을 정의 )
( path: 호스트의 디렉토리 경로를 지정, 이 경우에는 /tmp 디렉토리를 지정
type: 볼륨의 유형을 지정, 이 경우에는 Directory로 지정 )
- kubectl create -f volume-nfsserver.yaml
- NFS 서버 파드는 호스트 머신의 /tmp 디렉토리를 /exports로 마운트하여 사용
이를 통해 다른 파드가 NFS를 통해 /exports 경로에 접근하여 데이터를 공유
⇒서버와 마운트 시킬 파드 ( 클라이언트 파드 )
- #cat volume-nfsapp.yaml 열어서 nfs서버의 IP 수정
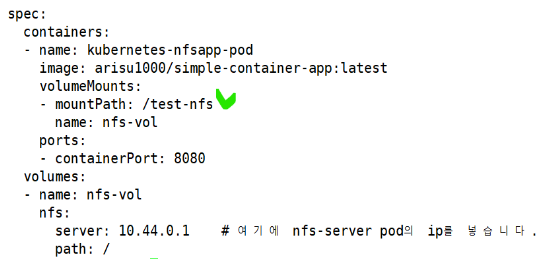
NFS 볼륨 설정
- NFS 볼륨을 사용하는 쿠버네티스 배포(Deployment)를 정의하는 yaml 파일 작성
( nfs: NFS(Network File System) 볼륨을 정의 )
( server: NFS 서버의 IP 주소를 지정하고,
여기에는 실제 NFS 서버의 IP 주소가 들어가야 한다 )
( path: NFS 서버에서 마운트할 디렉토리 경로를 지정하고,
이 경우에는 루트 디렉토리(/)를 지정하고 있다 )
- kubectl create -f volume-nfsapp.yaml
- 파드 내의 컨테이너는 외부 NFS 서버의 데이터를 /test-nfs 경로에 마운트하여 사용
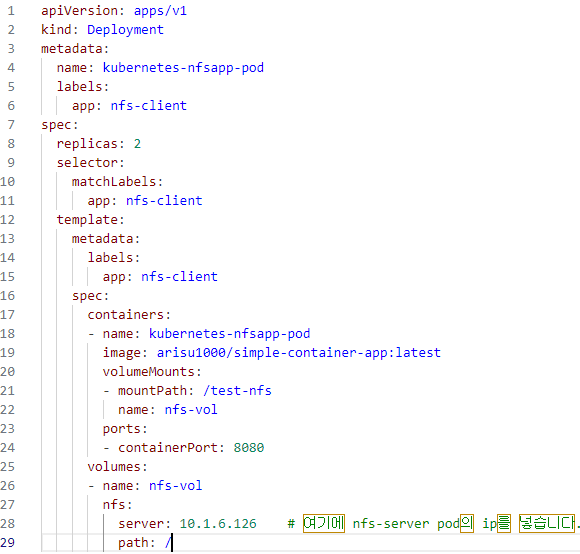
⇒ 실행하고 실행된 파드2곳 모두 접속해서 Test용 파일 각각 생성 ( test-1.txt, index.html )
-

-
#kubectl exec -it kubernetes-nfsapp-pod-9b7d878db-wqf6q -- sh
- ~ # cd /test-nfs
- /test-nfs # vi index.html
컨테이너 접속하여 파일 생성하고 마운트 확인 ( node2 )
- kubectl exec -it kubernetes-nfsapp-pod-5b65fdd4c-5s8zn -- sh
- cd /test-nfs
- touch node2.txt
컨테이너 접속하여 파일 생성하고 마운트 확인 ( node1 )
- kubectl exec -it kubernetes-nfsapp-pod-5b65fdd4c-92c7f -- sh
- cd /test-nfs
- vi index.html ( 내용 입력 )
⇒서버로 동작하고 있노드에서 확인 해보면 node1에서 생성한 파일과 노드2에서 생성한 파일 모두 보여짐.
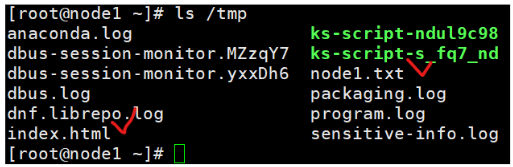
node1 에서 마운트 확인 ( nfs 서버 )
- ls /tmp | grep index
- ls /tmp | grep node
*퍼시스턴스 볼륨 : 용량을 지정하기
#cat pvc-hostpath.yaml ⇒ 읽고,쓰기 및 용량 지정 (기본용량은 1G )
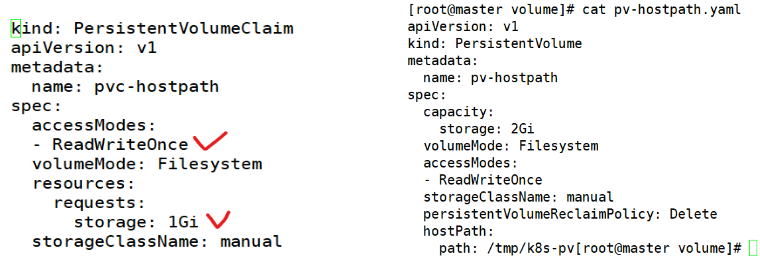
#kubectl apply -f pvc-hostpath.yaml
- [root@master volume]# kubectl delete persistentvolumeclaim pvc-hostpath
- persistentvolumeclaim "pvc-hostpath" deleted
⇒ pv에 있는 용량이(2G) 기준이 되어서. pvc에 용량을 pv용량보다 높게 설정하면 생성이 안됨.
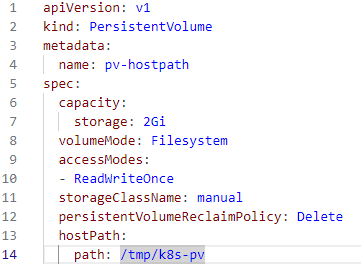
PersistentVolume 설정
- PersistentVolume을 정의하는 yaml 파일 작성
( spec: PersistentVolume의 스펙을 정의 )
- kubectl apply -f pv-hostpath.yaml
- kubectl get pv로 확인
- "pv-hostpath"라는 이름의 2기가바이트 용량을 가지는 파일 시스템 모드의
PersistentVolume이 정의되며, 호스트의 /tmp/k8s-pv 경로를 사용하도록 설정
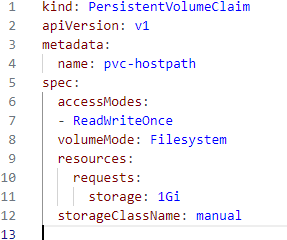
PersistentVolumeClaim 설정
- PersistentVolumeClaim을 정의하는 yaml파일 작성
( spec: PersistentVolumeClaim의 스펙을 정의 )
( volumeMode: 볼륨의 모드를 지정, 이 경우에는 파일 시스템으로 지정
resources: PVC가 요청하는 자원을 정의, 이 경우에는 1기가바이트의 스토리지를 요청
storageClassName: PersistentVolumeClaim의 스토리지 클래스를 지정,
이 경우에는 "manual"로 지정 )
- kubectl create -f pvc-hostpath.yaml
- kubectl get pvc 로 확인
- 1기가바이트 용량의 파일 시스템 모드의 스토리지를 요청
*파드에서 PVC를 볼륨으로 사용
- #kubectl apply -f pv-hostpath.yaml ⇒ 용량 2G
#kubectl apply -f pvc-hostpath.yaml ⇒ 1G로 수정 후
#kubectl apply -f deployment-pvc.yaml- ⇒ 노드에 파드가 생성되면
#kubectl port-forward pods/kubernetes-simple-app-59b576c86d-hbxx4 8080:8080 - 해당노드에 SSH로 접속 해서 /tmp디렉토리 확인 해보면 app.log 파일 확인
- #cat /tmp/app.log
접속 기록 확인
- ⇒ 노드에 파드가 생성되면
PersistentVolumeClaim을 통해 deploy
- Deployment를 정의하는 yaml 파일 작성
( "/tmp" 경로에 "myvolume"이라는 이름의 볼륨을 마운트 )
( volumes: "myvolume"이라는 이름의 볼륨을 정의 )
( "pvc-hostpath"라는 이름의 PersistentVolumeClaim과 연결 )
- kubectl apply -f deployment-pvc.yaml
- "pvc-hostpath"라는 이름의 PersistentVolumeClaim을 통해 스토리지를 사용
- 마운트된 노드의 /tmp 디렉터리 확인

