*AutoScaling
⇒ 지정해둔 조건에 따라 파드개수를 자동으로 늘렸다 줄였다 하는 기능
⇒ 지정된 자원을 API가 먼저 확인 / 조건에 맞으면 HPA가 오토스케일링 함.
- HPA 가 Deployment를 모니터링 ( HPA는 컨트롤러 매니저 )
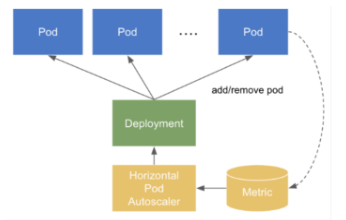
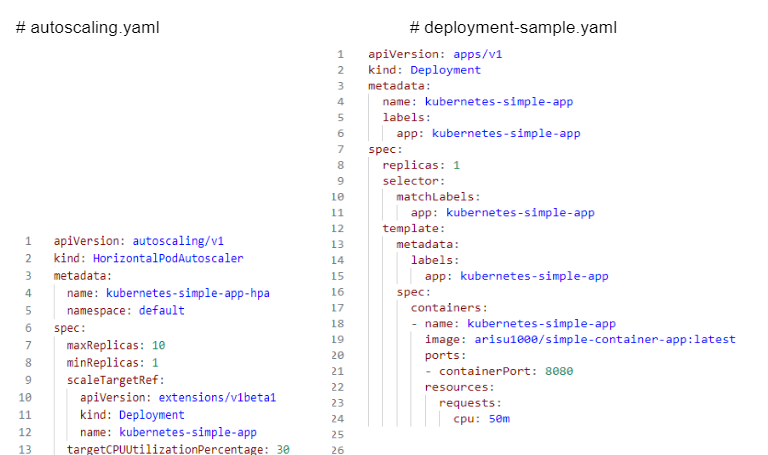
-kind : HorizontalPodAutoscaler (매니저 역할)
-maxReplicas : 최대 생성 개수
-minReplicas: 최소(기본) 개수
-spec 아래 kind 가 대상 즉 Deployment로 동작하는 파드들이 대상이됨.
-targetCPUUtilizationPercentage: 30% ⇒ CPU사용량이 30% 이상 일때 파드 생성
⇒ CPU사용량 계산법 : 파드에 있는 CPU개수 사용률 합계 / 30 (결과값이 소숫점은 올림으로)
⇒ 템플릿( autoscaling.yaml )이 아닌 명령을 통해서 HPA지정
- ex) kubectl autoscale deployment [타겟이름지정: kubenernetes-simple-app] --cpu-percent=30 --min=1 --max=10
⇒ 위 두개의 파일 생성 후 동작 / 확인
⇒ unknown ⇒ 0% 으로 표시되기도함
예제파일 및 실행 과정 있는곳.
https://github.com/kubernetes-sigs/metrics-server/issues/1282
https://kubernetes.io/ko/docs/tasks/run-application/horizontal-pod-autoscale-walkthrough/
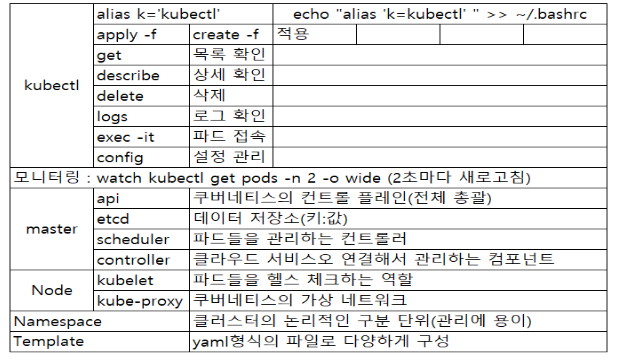
*기본적인 kubeclt 명령어 : 아래 기술문서에 정리되어 있음.
https://kubernetes.io/ko/docs/reference/kubectl/
구조
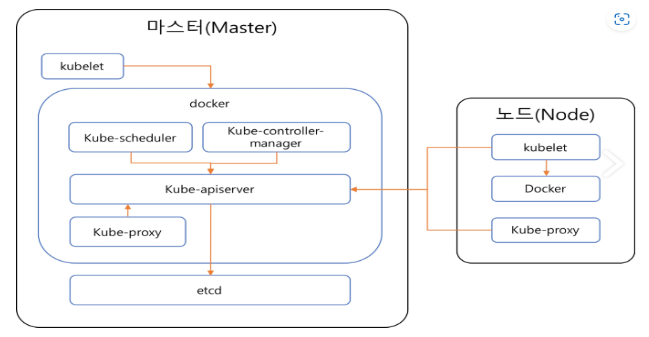
*파드 :
⇒ 컨테이너의 묶음 ( 목적이 같은 컨테이너를 묶어서 관리, 똑같은 IP 사용 , 포트는 다름 )
*컨트롤러
- 레플리카 셋 : 지정한 숫자만큼의 파드가 항상 실행되도록 하는것.
- 디플로이먼트(Deployment) : 처음 생성할때 사용 / 좀더 세밀하게 설정 하고, 관리 가능.
- 데몬셋 : 전체노드에 중에서 특정한 파드 사용할때 사용하는 컨트롤러(노드당 1개는 보장)
- 스테이트 풀셋 : 특정한 상태에 있는 파드관리
- 잡 / 크론잡 : 일회성 실행 , 지속적인 실행을 통해서 파드를 컨트롤 하는 기능.
*서비스
⇒파드에 접속하기 위해서 필요한 기능, 외부에서도 접속 할 수 있도록 해줌.
- ClusterIP : 클러스터 안(내부 전용)에서만 사용 가능
- NodePort : 클러스터 IP 생성 후 포트를 지정해서 외부에서도 접속 할 수 있도록 해주는 기능
- 로드밸런서 : 외부에서 접속 가능하도록 해주는 기능.(별도의 LB기능이 있는 장비를 이용해서 )
- ExternalName : 클러스터 안에서 외부로 접근 하도록 해주는 기능.
- kube-proxy : IP나 포트를 통해 접근 할때 연결 시켜주는 역할
*인그레스
⇒ 외부에서 내부로 접근시 요청을 하는데 어떻게 처리할지 정해 놓은 규칙에 대한 모음.
- SSL 인증서 , 도메인 , URL
*레이블( Label ) , --show-labels
키:
- 값으로 구성되어있는 메타데이터로 설정
- 관리할때 파드들을 구분하는 역할
어노테이션 :
- 레이블처럼 키:값으로 구성되 있어서 사용가능.
무중단 배포:
- 롤링업데이트 : 일정한 개수씩 교체 또는 업데이트 하는것.
- 블루/그린 : 한꺼번에 작업을 하는 기능.
- 카나리 : 기존 버전은 유지한채로 신규 버전으로 교체를 함.
*컨피그 맵
⇒ 환경설정에 대한 것을 일부 또는 전체에 대해서 불러와서 적용 시켜주는것.
⇒ 컨피그맵에 있는 내용중 일부 또는 전체를 불러와서 사용 가능함.
⇒ 컨피그맵을 이용하여 볼륨에 마운트할 수 도 있음.
- 템플릿 mountPath 에 마운트할 볼륨과 디렉터리 경로를 넣어 주면됨.
*시크릿
⇒ 비밀번호, 토큰, SSH키 등 정보를 저장하는 용도
- 내장 시크릿 : API접근시 사용하는 용도
- 외장 시크릿 : API접근 이외의 용도로 사용
*스케줄링 ( 파드 스케줄링 )
⇒ 파드가 어떤 노드에서 실행될지는 키:값으로 설정 해서 결정 할 수 있음.
- 어피니티 : 파드들을 묶어서 같은 노드에 실행 되도록 하는 기능
- 안티 어피니티 : 어피니티와 반대로 파드들을 노드에 골고루 나누어서 실행 되도록 하는것.
- 커든 : 스케줄러가 적용되지 않도록 하는 기능. 차단 및 해지 가능.
*볼륨 - 저장소, 즉 데이터 저장소
종류
- emptydir : 파드가 실행되는 호스트(노드)의 디스크를 임시로 볼륨으로 연결해서 사용
- hostpath : 파드가 실행된 호스트(노드)의 파일이나 디렉터리를 실행된 파드에 마운트 시켜서 사용
- NFS 볼륨 : NFS서버를 생성 후 여러개의 파드를 하나의 서버에 마운트 하는 기능
*오트 스케줄링
⇒ 지정해둔 조건에 따라 파드개수를 자동으로 늘렸다 줄였다 하는 기능
⇒ HPA에 의해 Deploy가 관리되며, CPU사용값을 설정해두면 그 값에 도달시 파드가 실행되거나 다시 축소되는 기능
