AWS Athena를 통해 S3에 저장된 DynamoDB 데이터를 쿼리 ( terraform )
람다 함수 ( surveys_aws_dynamodb_surveys_item )
import boto3
import csv
import json
from datetime import datetime
from io import StringIO
dynamodb = boto3.resource('dynamodb')
s3 = boto3.client('s3')
# DynamoDB 테이블 이름
table_name = 'Surveys'
# S3 버킷 이름
s3_bucket_name = 'aws-dynamodb-surveys-item'
def lambda_handler(event, context):
table = dynamodb.Table(table_name)
response = table.scan()
items = response['Items']
# 현재 날짜와 시간을 기준으로 경로 설정
now = datetime.now()
year = now.strftime('%Y')
month = now.strftime('%m')
day = now.strftime('%d')
hour = now.strftime('%H')
minute = now.strftime('%M')
s3_key_csv = f"AWSItems/533267020503/DynamodbItems/ap-northeast-2/Surveys/{year}/{month}/{day}/{hour}/{minute}/data.csv"
# CSV 파일로 저장
csv_buffer = StringIO()
csv_writer = csv.writer(csv_buffer)
# CSV 헤더 작성
if items:
# 기본 헤더 작성
headers = list(items[0].keys())
headers.remove('Questions') # Questions 필드는 나중에 추가
max_questions_length = max(len(item.get('Questions', [])) for item in items)
max_choices_length = max(len(q['choices']) for item in items for q in item.get('Questions', []))
question_headers = [f"QuestionText_{i+1}" for i in range(max_questions_length)]
choice_headers = [f"Choices_{i+1}-{j+1}" for i in range(max_questions_length) for j in range(max_choices_length)]
# 새로운 헤더 순서에 맞게 조정
header_row = headers + sum([[f"QuestionText_{i+1}"] + [f"Choices_{i+1}-{j+1}" for j in range(max_choices_length)] for i in range(max_questions_length)], [])
csv_writer.writerow(header_row)
# CSV 데이터 작성
for item in items:
row = [item.get(header, '') for header in headers]
questions = item.get('Questions', [])
for i in range(max_questions_length):
if i < len(questions):
question = questions[i]
row.append(question.get('questionText', ''))
row.extend(question['choices'] + [''] * (max_choices_length - len(question['choices'])))
else:
row.append('')
row.extend([''] * max_choices_length)
csv_writer.writerow(row)
s3.put_object(
Bucket=s3_bucket_name,
Key=s3_key_csv,
Body=csv_buffer.getvalue()
)
return {
'statusCode': 200,
'body': json.dumps('DynamoDB items have been saved to S3 in CSV format')
}
람다 함수 ( surveys_aws_dynamodb_surveyresponses_item )
import boto3
import csv
import json
from datetime import datetime
from io import StringIO
dynamodb = boto3.resource('dynamodb')
s3 = boto3.client('s3')
# DynamoDB 테이블 이름
table_name = 'SurveyResponses'
# S3 버킷 이름
s3_bucket_name = 'aws-dynamodb-surveyresponses-item'
def lambda_handler(event, context):
table = dynamodb.Table(table_name)
response = table.scan()
items = response['Items']
# 현재 날짜와 시간을 기준으로 경로 설정
now = datetime.now()
year = now.strftime('%Y')
month = now.strftime('%m')
day = now.strftime('%d')
hour = now.strftime('%H')
minute = now.strftime('%M')
s3_key_csv = f"AWSItems/533267020503/DynamodbItems/ap-northeast-2/Surveys/{year}/{month}/{day}/{hour}/{minute}/data.csv"
# CSV 파일로 저장
csv_buffer = StringIO()
csv_writer = csv.writer(csv_buffer)
# CSV 헤더 작성
headers = ["SurveyId", "Timestamp", "ResponseId"]
max_questions = 0
for item in items:
responses = item.get("Responses", [])
max_questions = max(max_questions, len(responses))
for i in range(1, max_questions + 1):
headers.append(f"Question{i}")
headers.append(f"Answer{i}")
csv_writer.writerow(headers)
# CSV 데이터 작성
for item in items:
row = [item["SurveyId"], item["Timestamp"], item["ResponseId"]]
responses = item.get("Responses", [])
for response in responses:
row.append(response['question'])
row.append(response['answer'])
# 만약 질문/답변 수가 최대 질문 수보다 적다면 빈 필드 추가
while len(row) < len(headers):
row.append("")
csv_writer.writerow(row)
s3.put_object(
Bucket=s3_bucket_name,
Key=s3_key_csv,
Body=csv_buffer.getvalue()
)
return {
'statusCode': 200,
'body': json.dumps('DynamoDB items have been saved to S3 in CSV format')
}
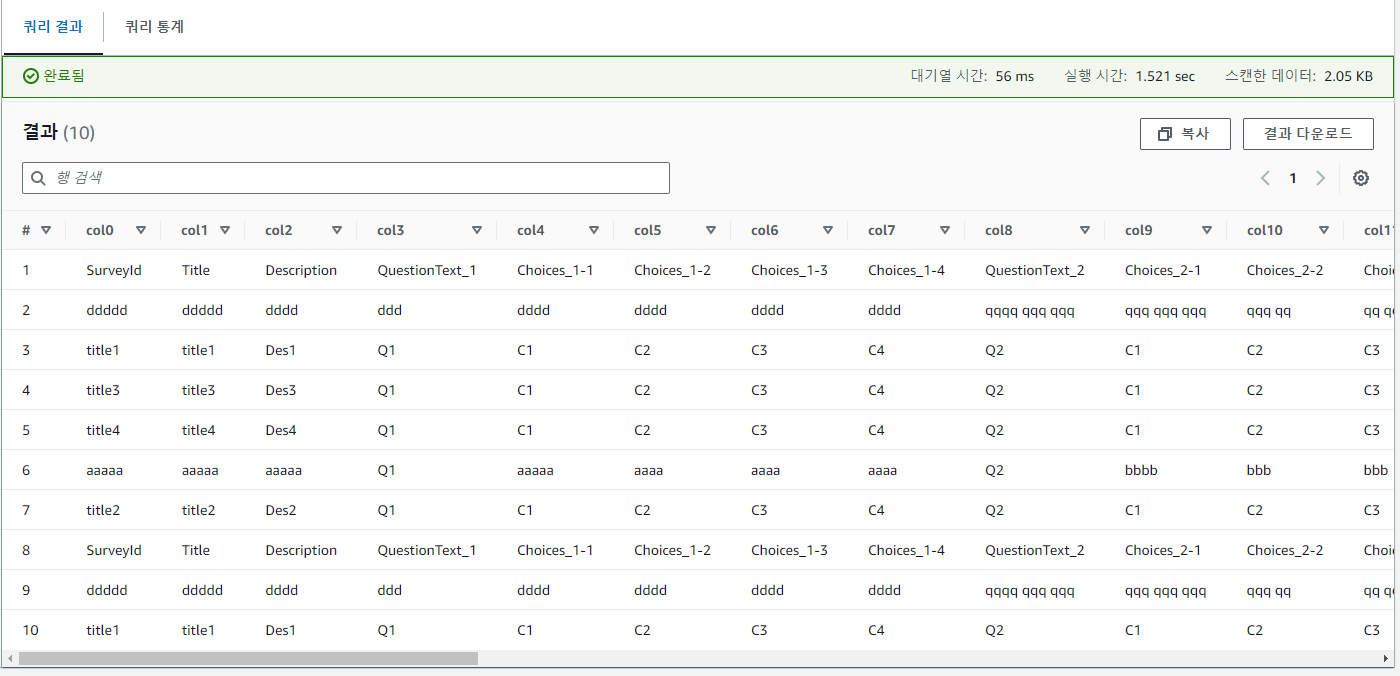
surveys_aws_dynamodb_surveys_item 쿼리 결과
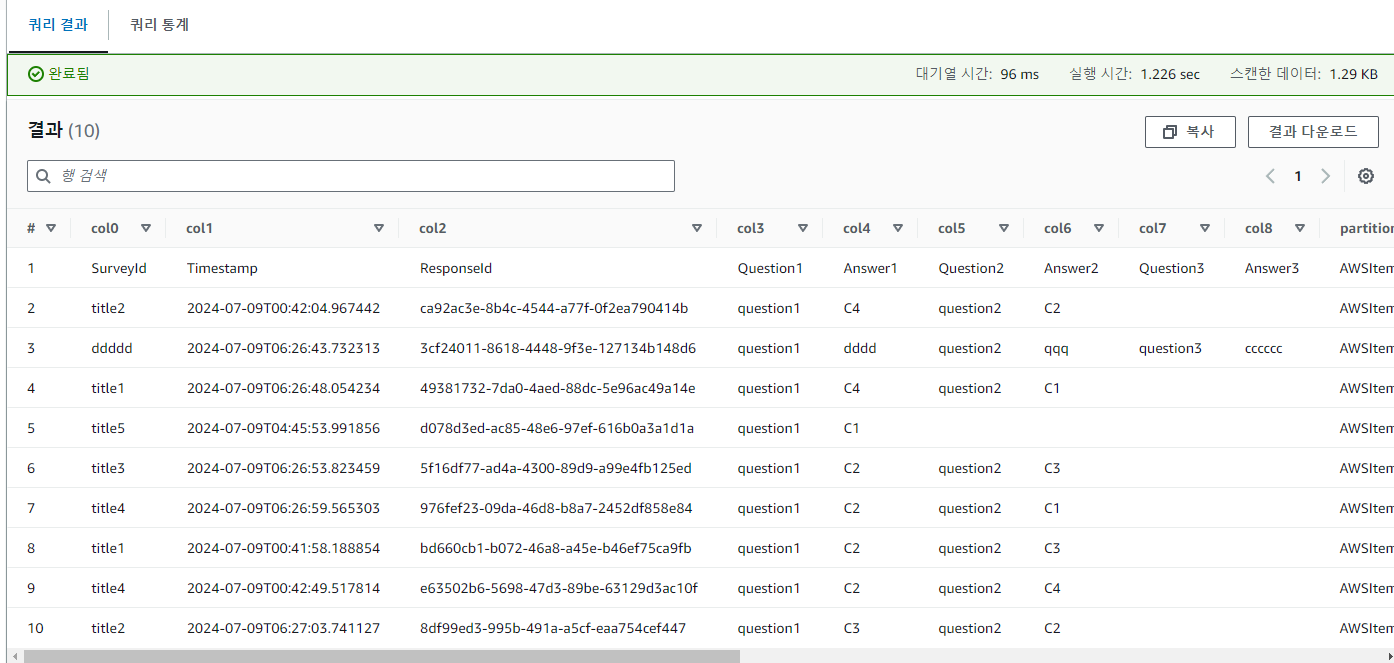
surveys_aws_dynamodb_surveyresponses_item 쿼리 결과
dynamodb table의 item을 S3에 저장 및 AWS Athena를 통해 S3에 저장된 DynamoDB 데이터를 쿼리
설정 ( 16회차 참고 )
-
db 생성
-
크롤러 생성
-
이름 지정
-
역할 지정
-
table prefix 지정
-
스케줄 지정
-
Update all - new and existing partitions with metadata from the table 활성화
-
glue 모듈 main.tf
resource "aws_glue_catalog_database" "dynamodb_surveys_db" {
name = "dynamodb_surveys_db"
}
resource "aws_glue_catalog_database" "dynamodb_surveyresponses_db" {
name = "dynamodb_surveyresponses_db"
}
resource "aws_glue_catalog_database" "nginx_db" {
name = "aws-waf-logs-nginx-db"
}
resource "aws_glue_catalog_database" "tomcat_db" {
name = "aws-waf-logs-tomcat-db"
}
resource "aws_glue_crawler" "dynamodb_surveys_crawler" {
name = "dynamodb-surveys-crawler"
role = var.glue_role_arn
database_name = aws_glue_catalog_database.dynamodb_surveys_db.name
table_prefix = "item_"
s3_target {
path = "s3://aws-dynamodb-surveys-item"
}
schedule = "cron(0 0 * * ? *)" # 매일 자정에 실행
schema_change_policy {
delete_behavior = "DEPRECATE_IN_DATABASE"
update_behavior = "UPDATE_IN_DATABASE"
}
configuration = jsonencode({
Version = 1.0,
CrawlerOutput = {
Partitions = {
AddOrUpdateBehavior = "InheritFromTable"
}
}
})
}
resource "aws_glue_crawler" "dynamodb_surveyresponses_crawler" {
name = "dynamodb-surveyresponses-crawler"
role = var.glue_role_arn
database_name = aws_glue_catalog_database.dynamodb_surveyresponses_db.name
table_prefix = "item_"
s3_target {
path = "s3://aws-dynamodb-surveyresponses-item"
}
schedule = "cron(0 0 * * ? *)" # 매일 자정에 실행
schema_change_policy {
delete_behavior = "DEPRECATE_IN_DATABASE"
update_behavior = "UPDATE_IN_DATABASE"
}
configuration = jsonencode({
Version = 1.0,
CrawlerOutput = {
Partitions = {
AddOrUpdateBehavior = "InheritFromTable"
}
}
})
}
resource "aws_glue_crawler" "nginx_crawler" {
name = "aws-waf-logs-nginx-crawler"
role = var.glue_role_arn
database_name = aws_glue_catalog_database.nginx_db.name
table_prefix = "nginx_"
s3_target {
path = "s3://aws-waf-logs-nginx"
}
schedule = "cron(0 0 * * ? *)" # 매일 자정에 실행
schema_change_policy {
delete_behavior = "DEPRECATE_IN_DATABASE"
update_behavior = "UPDATE_IN_DATABASE"
}
configuration = jsonencode({
Version = 1.0,
CrawlerOutput = {
Partitions = {
AddOrUpdateBehavior = "InheritFromTable"
}
}
})
}
resource "aws_glue_crawler" "tomcat_crawler" {
name = "aws-waf-logs-tomcat-crawler"
role = var.glue_role_arn
database_name = aws_glue_catalog_database.tomcat_db.name
table_prefix = "tomcat_"
s3_target {
path = "s3://aws-waf-logs-tomcat"
}
schedule = "cron(0 0 * * ? *)" # 매일 자정에 실행
schema_change_policy {
delete_behavior = "DEPRECATE_IN_DATABASE"
update_behavior = "UPDATE_IN_DATABASE"
}
configuration = jsonencode({
Version = 1.0,
CrawlerOutput = {
Partitions = {
AddOrUpdateBehavior = "InheritFromTable"
}
}
})
}variables.tf
variable "region" {
description = "The region where resources will be created"
type = string
}
variable "glue_role_arn" {
description = "The ARN of the IAM role to be used by Glue Crawlers"
type = string
}