dynamodb table의 item을 S3에 저장
사전 준비
- DynamoDB 테이블 이름: Surveys
S3 버킷 이름: aws-dynamodb-surveys-item
Lambda 함수 생성 및 설정
-
IAM 역할 생성
-
IAM 콘솔을 엽니다.
-
역할 생성을 클릭합니다.
-
Lambda를 선택합니다.
-
권한 연결 단계에서 다음과 같은 정책을 포함하는 사용자 지정 정책을 생성합니다
AmazonDynamoDBReadOnlyAccess, AmazonS3FullAccess
-
-
Lambda 함수 생성
-
Lambda 콘솔을 엽니다.
-
함수 생성을 클릭합니다.
-
함수 이름( Surveys-items )을 입력하고 Python을 런타임으로 선택합니다.
-
실행 역할로 앞서 생성한 IAM 역할을 선택합니다.
-
import boto3
import csv
import json
from datetime import datetime
from io import StringIO
dynamodb = boto3.resource('dynamodb')
s3 = boto3.client('s3')
# DynamoDB 테이블 이름
table_name = 'Surveys'
# S3 버킷 이름
s3_bucket_name = 'aws-dynamodb-surveys-item'
def lambda_handler(event, context):
table = dynamodb.Table(table_name)
response = table.scan()
items = response['Items']
# 현재 날짜와 시간을 기준으로 경로 설정
now = datetime.now()
year = now.strftime('%Y')
month = now.strftime('%m')
day = now.strftime('%d')
hour = now.strftime('%H')
minute = now.strftime('%M')
s3_key_csv = f"AWSItems/533267020503/DynamodbItems/ap-northeast-2/Surveys/{year}/{month}/{day}/{hour}/{minute}/data.csv"
# CSV 파일로 저장
csv_buffer = StringIO()
csv_writer = csv.writer(csv_buffer)
# CSV 헤더 작성
if items:
headers = items[0].keys()
csv_writer.writerow(headers)
# CSV 데이터 작성
for item in items:
csv_writer.writerow(item.values())
s3.put_object(
Bucket=s3_bucket_name,
Key=s3_key_csv,
Body=csv_buffer.getvalue()
)
return {
'statusCode': 200,
'body': json.dumps('DynamoDB items have been saved to S3 in CSV format')
}
-
Lambda 함수 테스트
-
Lambda 함수의 테스트 버튼을 클릭합니다.
-
이벤트 템플릿을 선택하거나 빈 이벤트를 사용합니다.
-
테스트를 클릭하여 함수가 제대로 작동하는지 확인합니다
-
- Lambda 함수 트리거 추가 (선택사항)
Lambda 함수를 일정 간격으로 실행하려면 CloudWatch Events를 사용하여 주기적으로 Lambda 함수를 트리거할 수 있습니다. 이 과정은 다음과 같습니다:- CloudWatch 콘솔을 엽니다.
- 이벤트 > 규칙 > 규칙 생성을 클릭합니다.
( 이벤트 이름: dynamodb_Surveys_items ) - 이벤트 소스로 일정을 선택합니다.
- 고급 옵션을 사용하여 CRON 표현식으로 트리거 빈도를 설정합니다.
( 표현식: cron(0,30 * * * ? *), 설명: 매 시간의 0분과 30분마다 실행) - 대상 추가로 Lambda 함수를 선택하고, 앞서 생성한 Lambda 함수를 선택합니다.
( Surveys-items ) - 규칙에 이름을 지정하고 생성합니다.
- 이 과정을 통해 DynamoDB 테이블의 항목들을 주기적으로 S3에 저장할 수 있습니다.
AWS Athena를 통해 S3에 저장된 DynamoDB 데이터를 쿼리
-
AWS Glue를 사용하여 데이터 카탈로그 생성
-
Athena에서 데이터베이스 및 테이블 설정
-
Athena 콘솔에서 쿼리 실행
- AWS Glue를 사용하여 데이터 카탈로그 생성
-
먼저 AWS Glue를 사용하여 데이터 카탈로그를 생성해야 합니다. AWS Glue 크롤러를 사용하여 S3 버킷에 있는 JSON 데이터를 스캔하고 스키마를 생성할 수 있습니다.
-
AWS Glue 크롤러 생성
-
AWS Glue 콘솔을 엽니다.
-
왼쪽 탐색 창에서 크롤러를 선택합니다.
-
크롤러 추가를 클릭합니다.
-
크롤러 이름을 입력하고 다음을 클릭합니다.
( 크롤러 이름: dynamodb-surveys-crawler )
-
데이터 스토어에서 S3를 선택합니다.
-
S3 경로를 입력합니다. 예: s3://aws-dynamodb-Surveys-item/AWSItems/533267020503/DynamodbItems/ap-northeast-2/Surveys/
-
크롤러가 액세스할 수 있는 IAM 역할을 선택하거나 새로 만듭니다.
( Glue 크롤러가 S3 버킷에 액세스할 수 있도록 권한이 있는 역할을 선택,
AWSGlueServiceRole: Glue 작업을 수행하기 위한 기본 권한을 포함합니다.
AmazonS3ReadOnlyAccess: S3 버킷에 대한 읽기 전용 액세스를 제공합니다. ) -
크롤링 빈도를 설정합니다. (예: 매일)
-
크롤러가 결과를 저장할 데이터베이스를 선택하거나 새 데이터베이스를 생성합니다.
( 예를 들어, dynamodb_surveys_db라는 데이터베이스를 생성할 수 있습니다.
테이블 접두사를 입력합니다. 예를 들어, surveys_와 같이 입력할 수 있습니다. ) -
완료를 클릭하여 크롤러를 생성하고 실행합니다.
-
- Athena에서 데이터베이스 및 테이블 설정
-
Glue 크롤러가 실행된 후 생성된 스키마를 기반으로 Athena에서 쿼리를 실행할 수 있습니다.
-
Athena에서 데이터베이스 및 테이블 확인
-
Athena 콘솔을 엽니다.
-
Query Editor로 이동합니다.
-
데이터베이스 목록에서 Glue 크롤러가 생성한 데이터베이스를 선택합니다.
-
테이블 목록에서 크롤러가 생성한 테이블을 확인합니다.
-
- Athena 콘솔에서 쿼리 실행
- 이제 Athena에서 데이터를 쿼리할 수 있습니다. 예를 들어, 다음과 같은 쿼리를 실행하여 DynamoDB 데이터를 조회할 수 있습니다.
Athena 쿼리 예시
SELECT *
FROM your_database.your_table
LIMIT 10;- DynamoDB 테이블 구조를 기반으로 쿼리 작성
- DynamoDB 테이블의 구조에 따라 특정 필드를 쿼리할 수 있습니다. 예를 들어, 데이터가 다음과 같은 구조로 저장된 경우:
- 해당 구조를 기반으로 쿼리를 작성할 수 있습니다.
{
"PrimaryKey": "12345",
"Attribute1": "Value1",
"Attribute2": "Value2",
"Attribute3": {
"NestedAttribute": "NestedValue"
}
}SELECT
PrimaryKey,
Attribute1,
Attribute2,
Attribute3.NestedAttribute
FROM
your_database.your_table
LIMIT 10;-
전체 과정 요약
-
S3에 저장된 데이터 확인: Lambda 함수가 DynamoDB 데이터를 JSON 형식으로 S3에 저장합니다.
-
Glue 크롤러 설정 및 실행: Glue 크롤러를 사용하여 S3 버킷을 스캔하고 데이터베이스 및 테이블을 생성합니다.
-
Athena에서 데이터 확인 및 쿼리: Athena 콘솔에서 Glue 크롤러가 생성한 데이터베이스와 테이블을 확인하고 쿼리를 실행하여 데이터를 분석합니다.
-
이 과정을 통해 S3에 저장된 DynamoDB 데이터를 Athena에서 효율적으로 쿼리하고 분석할 수 있습니다.
Athena에서 쿼리를 실행하기 전에 쿼리 결과의 위치 및 암호화를 설정하는 것은 필수적인 단계입니다. 쿼리 결과를 저장할 S3 버킷을 지정하고, 필요에 따라 암호화를 설정해야 합니다. 다음은 그 과정을 단계별로 설명한 것입니다.
- S3 버킷 준비
-
먼저 Athena 쿼리 결과를 저장할 S3 버킷을 준비해야 합니다. 이미 버킷이 있는 경우 해당 버킷을 사용할 수 있으며, 새로운 버킷을 생성할 수도 있습니다.
-
S3 버킷 생성
-
AWS Management Console에 로그인합니다.
-
S3 서비스로 이동합니다.
-
Create bucket 버튼을 클릭합니다.
-
버킷 이름과 리전을 입력합니다.
-
Create bucket 버튼을 클릭하여 버킷을 생성합니다.
-
- Athena 콘솔 설정
-
Athena 콘솔에서 쿼리 결과를 저장할 S3 버킷과 암호화 설정을 구성합니다.
-
Athena 쿼리 결과 위치 설정
-
AWS Management Console에서 Athena 서비스로 이동합니다.
-
왼쪽 메뉴에서 Settings를 클릭합니다.
-
Query result location 섹션에서 Manage 버튼을 클릭합니다.
-
쿼리 결과를 저장할 S3 버킷 경로를 입력합니다. 예: s3://your-athena-query-results-bucket/
-
(선택 사항) Encryption Configuration에서 결과 파일의 암호화를 설정할 수 있습니다.
-
No encryption: 암호화를 사용하지 않음.
-
SSE-S3: S3 관리형 키로 서버 측 암호화.
-
SSE-KMS: AWS KMS 관리형 키로 서버 측 암호화. 이 옵션을 선택하면 KMS 키를 지정해야 합니다.
-
-
설정을 완료한 후 Save 버튼을 클릭합니다.
-
- Athena 쿼리 실행
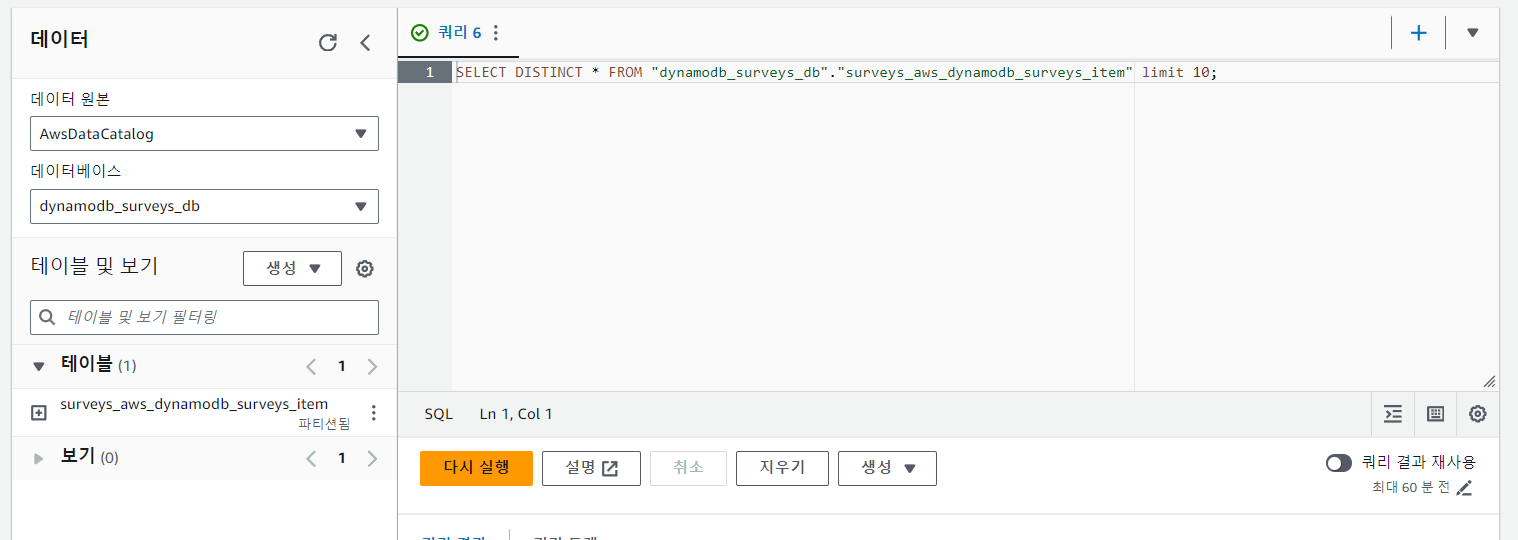
설정을 완료한 후, Athena Query Editor로 돌아가서 쿼리를 실행할 수 있습니다.
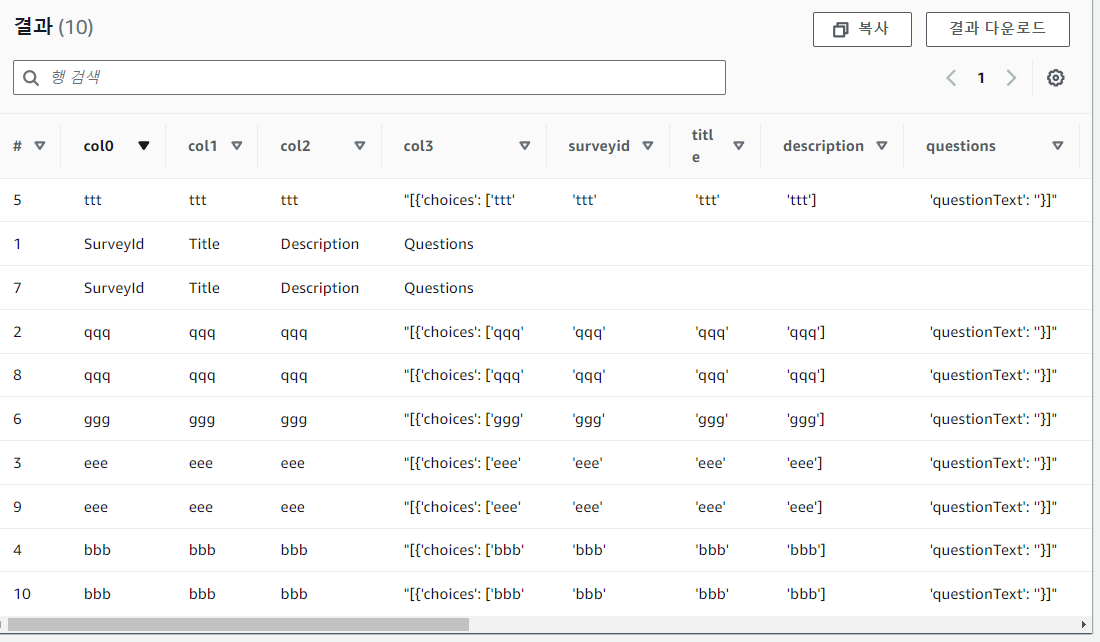
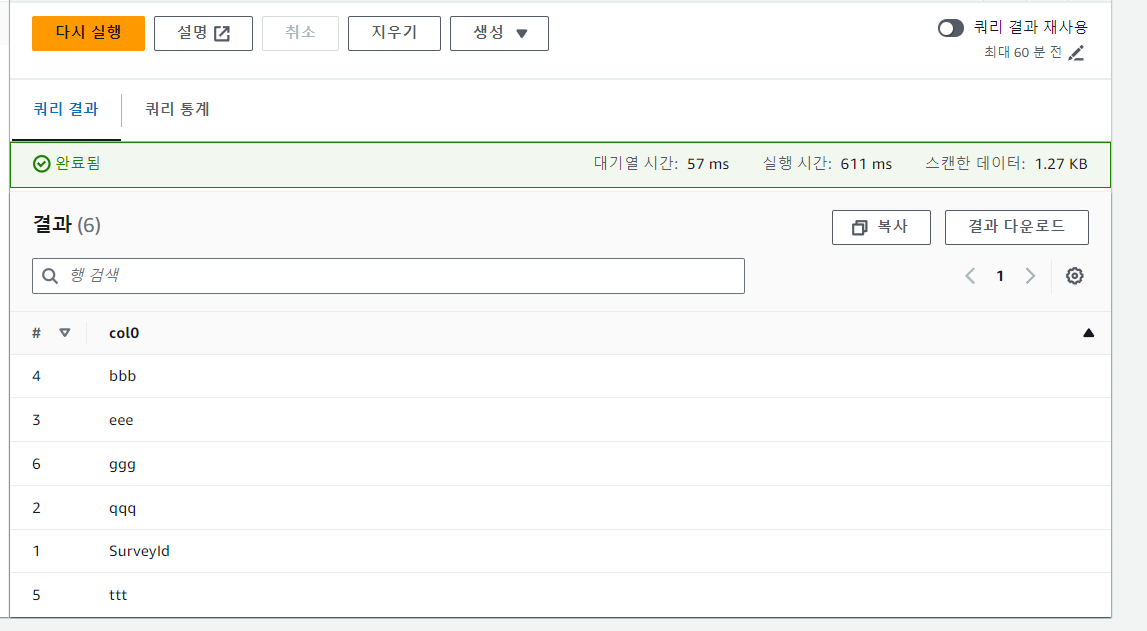
SELECT DISTINCT * FROM "dynamodb_surveys_db"."surveys_aws_dynamodb_surveys_item" limit 10;위와 같은 쿼리를 작성하여 저장된 데이터 확인
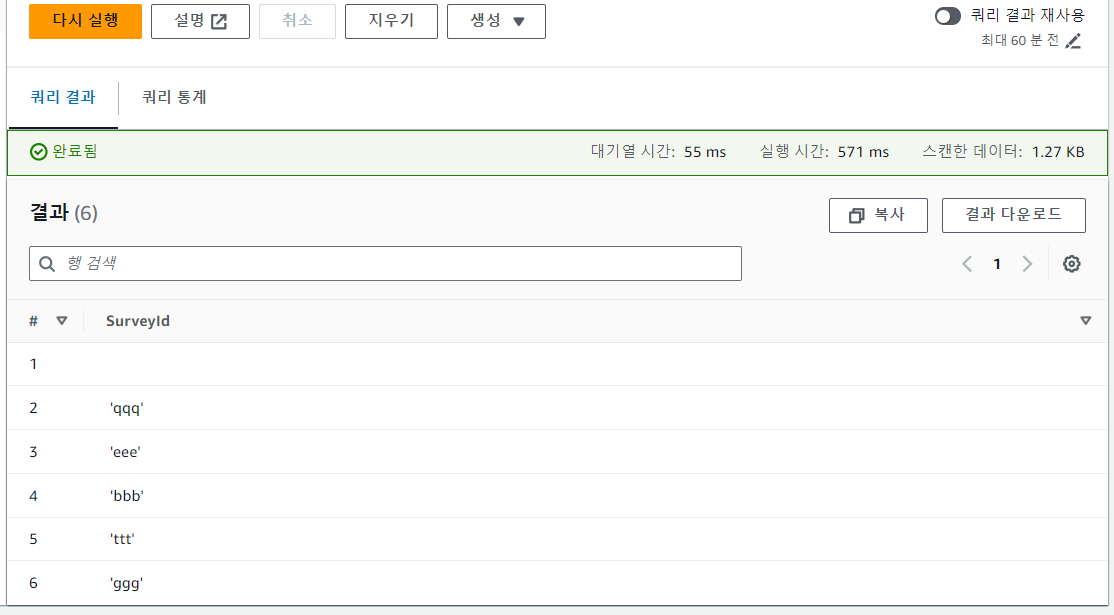
SELECT DISTINCT SurveyId FROM "dynamodb_surveys_db"."surveys_aws_dynamodb_surveys_item" limit 10;위와 같은 쿼리를 작성하여 중복된 데이터를 구별 가능
S3 waf 로그를 Athena를 통해 쿼리
Athena를 통해 AWS WAF 로그를 분석하려면 다음과 같은 단계를 따라야 합니다:
-
S3 버킷에 대한 데이터 스키마 정의:
AWS WAF 로그의 구조를 Athena에서 읽을 수 있도록 정의합니다. -
Glue 데이터 카탈로그에서 테이블 생성:
Athena는 AWS Glue 데이터 카탈로그에 있는 테이블을 통해 데이터를 인식합니다. Glue를 사용하여 테이블을 생성합니다. -
Athena에서 쿼리 작성 및 실행:
테이블을 생성한 후 Athena 콘솔에서 쿼리를 작성하여 데이터를 분석합니다.
단계별 가이드:
- S3 버킷 데이터 스키마 정의
- AWS WAF 로그는 JSON 형식으로 저장됩니다. 로그 형식을 이해하려면 AWS WAF 로그 파일의 샘플을 참고하십시오. 일반적으로 다음과 같은 필드가 포함됩니다:
{
"timestamp": "2024-07-06T05:55:00Z",
"formatVersion": "1.0",
"webaclId": "arn:aws:wafv2:ap-northeast-2:123456789012:regional/webacl/ExampleWebACL/1234abcd-12ab-34cd-56ef-1234567890ab",
"terminatingRuleId": "Default_Action",
"terminatingRuleType": "REGULAR",
"action": "ALLOW",
"httpSourceName": "CF",
"httpSourceId": "example-distribution-id",
"ruleGroupList": [],
"rateBasedRuleList": [],
"nonTerminatingMatchingRules": [],
"httpRequest": {
"clientIp": "192.0.2.1",
"country": "US",
"headers": [
{
"name": "Host",
"value": "www.example.com"
},
{
"name": "User-Agent",
"value": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
],
"uri": "/",
"args": "",
"httpVersion": "HTTP/1.1",
"httpMethod": "GET",
"requestId": "example-request-id"
}
}- Glue 데이터 카탈로그에서 테이블 생성
-
AWS Glue 콘솔에서 테이블을 생성합니다.
-
AWS Glue 콘솔 열기.
-
데이터 카탈로그에서 크롤러를 선택하고 테이블 추가를 클릭.
( 크롤러 이름: aws-waf-logs-nginx-crawler ) -
데이터베이스 선택 또는 새 데이터베이스 생성.
( 데이터베이스 생성, 이름: aws-waf-logs-nginx-db ) -
테이블 생성 방법에서 테이블 접두사를 입력, 예시: nginx_
-
S3 경로에 s3://aws-waf-logs-nginx/AWSLogs/533267020503/WAFLogs/ap-northeast-2/NGINX-WebACL/ 입력.
-
크롤러를 사용하여 테이블 생성 (크롤러가 자동으로 S3 버킷에서 데이터를 읽고 스키마를 정의합니다).
-
- Athena에서 쿼리 작성 및 실행
-
AWS Glue에서 테이블을 생성한 후 Athena 콘솔로 이동하여 쿼리를 실행할 수 있습니다.
-
Athena 콘솔 열기.
-
Query Editor로 이동.
-
Database에서 AWS Glue에서 생성한 데이터베이스 선택.
-
테이블을 선택한 후, 다음과 같은 쿼리를 작성하여 데이터를 분석:
-
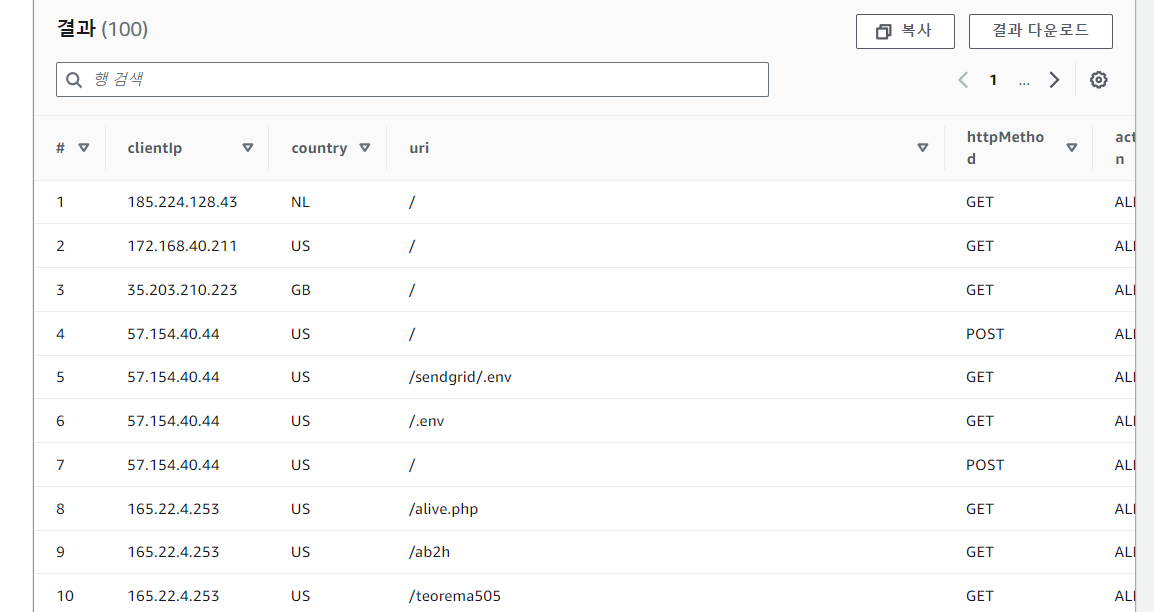
SELECT
httpRequest.clientIp,
httpRequest.country,
httpRequest.uri,
httpRequest.httpMethod,
action,
timestamp
FROM
nginx_aws_waf_logs_nginx
LIMIT 100;- 이 쿼리는 2024년 7월 6일에 발생한 로그를 시간순으로 정렬하여 상위 100개 항목을 반환합니다.
결론
위의 단계들을 따르면 Athena에서 AWS WAF 로그를 쉽게 분석할 수 있습니다. 필요한 경우, Athena 콘솔에서 다른 쿼리를 작성하여 더 복잡한 분석을 수행할 수도 있습니다.
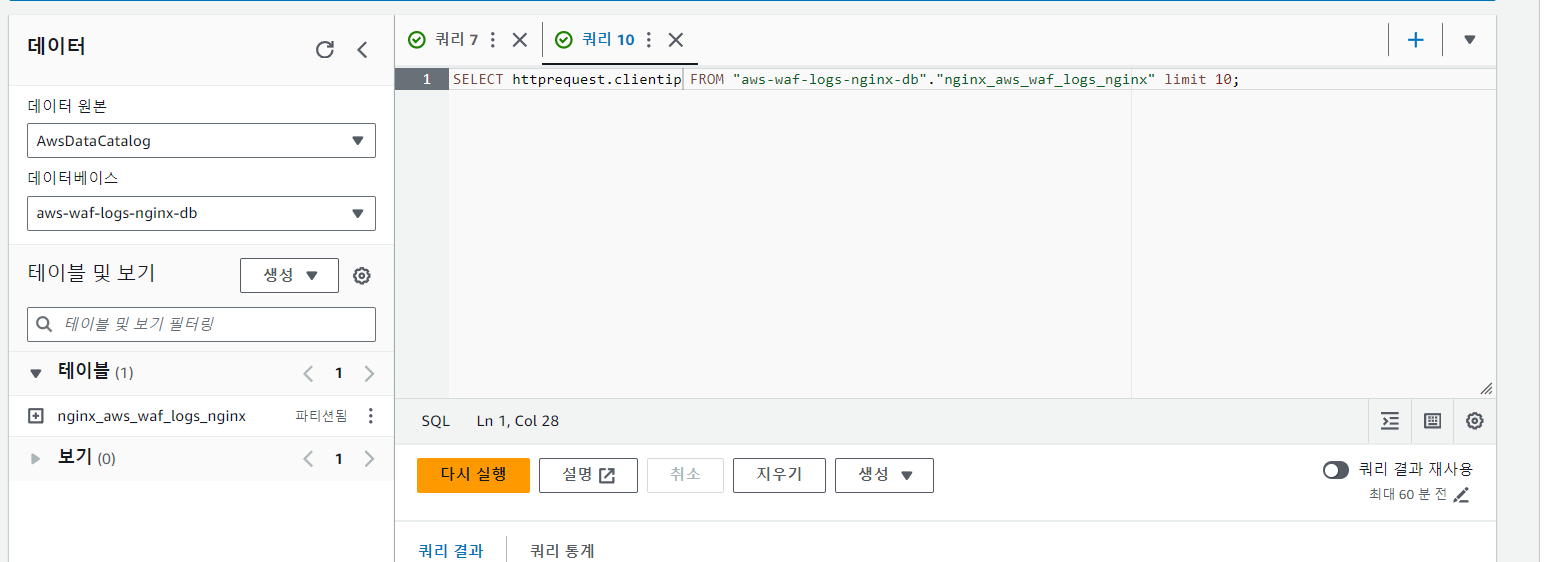
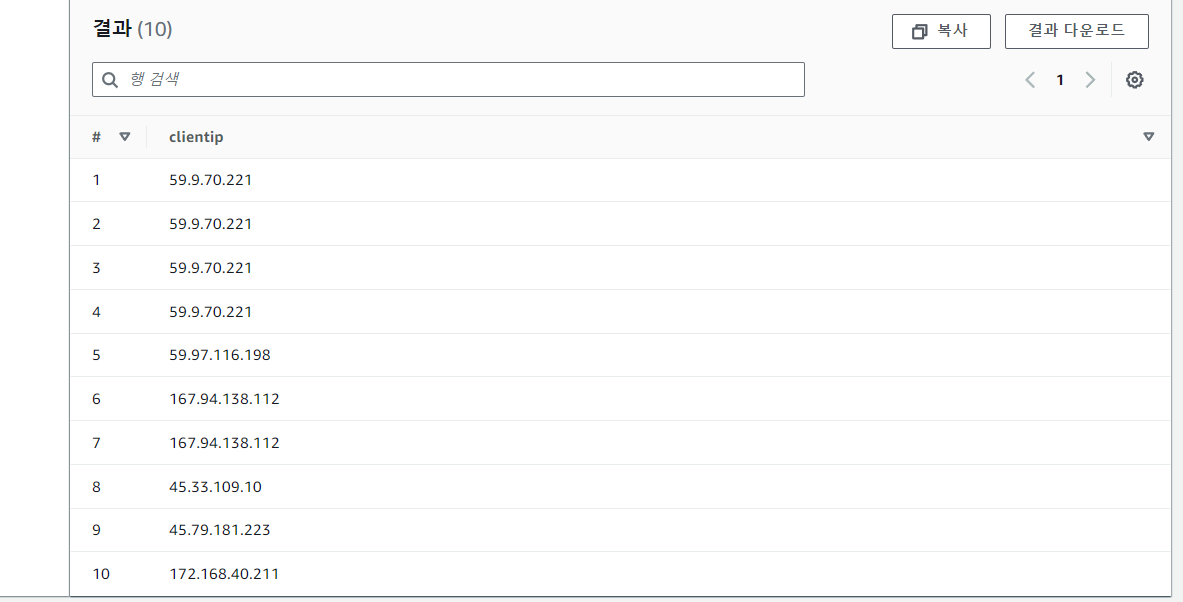
SELECT httprequest.clientip FROM "aws-waf-logs-nginx-db"."nginx_aws_waf_logs_nginx" limit 10;위의 쿼리 작성을 통해 clientip 확인
Athena 쿼리가 오류 'HIVE_PARTITION_SCHEMA_MISMATCH'와 함께 실패할 때
-
해결 방법
-
파티션 스키마를 업데이트하도록 AWS Glue 크롤러 구성
-
AWS Glue 콘솔을 엽니다.
-
탐색 창에서 크롤러(Crawlers)를 선택합니다.
-
구성하려는 크롤러를 선택합니다.
-
작업(Action)을 선택한 다음 크롤러 편집(Edit crawler)을 선택합니다.
-
크롤러의 출력 선택(Choose the crawler's output) 페이지로 이동할 때까지 다음(Next)을 선택합니다.
-
구성 옵션(Configuration options)을 확장합니다.
-
테이블에서 메타데이터가 있는 새 파티션과 기존 파티션을 모두 업데이트(Update all - new and existing partitions with metadata from the table)를 선택합니다.
-
다음(Next)을 선택한 다음 완료(Finish)를 선택하여 크롤러 구성을 저장합니다.
-
크롤러(Crawlers) 페이지에서 편집한 크롤러를 선택합니다.
-
크롤러 실행(Run crawler)을 선택합니다. 크롤러를 실행하면 파티션이 테이블 스키마를 상속합니다.
-
