오늘 리뷰할 논문은 (대부분) VAE를 기반으로 한 multimodal generative models의 survey 논문이다.
그런데 VAE 논문을 아직 안 읽어서 이거도 일단 대충 읽었다.
포스트는 리뷰보다는 메모용이다.
Heterogeneity : modalities가 서로 다른 feature space와 distribution을 가진다는 것
surveys on multimodal (or multi-view) machine learning [3, 5, 17, 45, 87, 108, 117, 122]
[5]를 따라 multimodal generative models을 coordinated와 joint models로 구분한다.
-
coordinated models
focus on the definition of closeness between inference distributions in the objective and divide them into two criteria: the distance between inference distributions and cross-modal generation loss. -
joint models
classify studies according to three main challenges: the handling of missing modalities, modality-specific latent variables, and weakly-supervised learning.
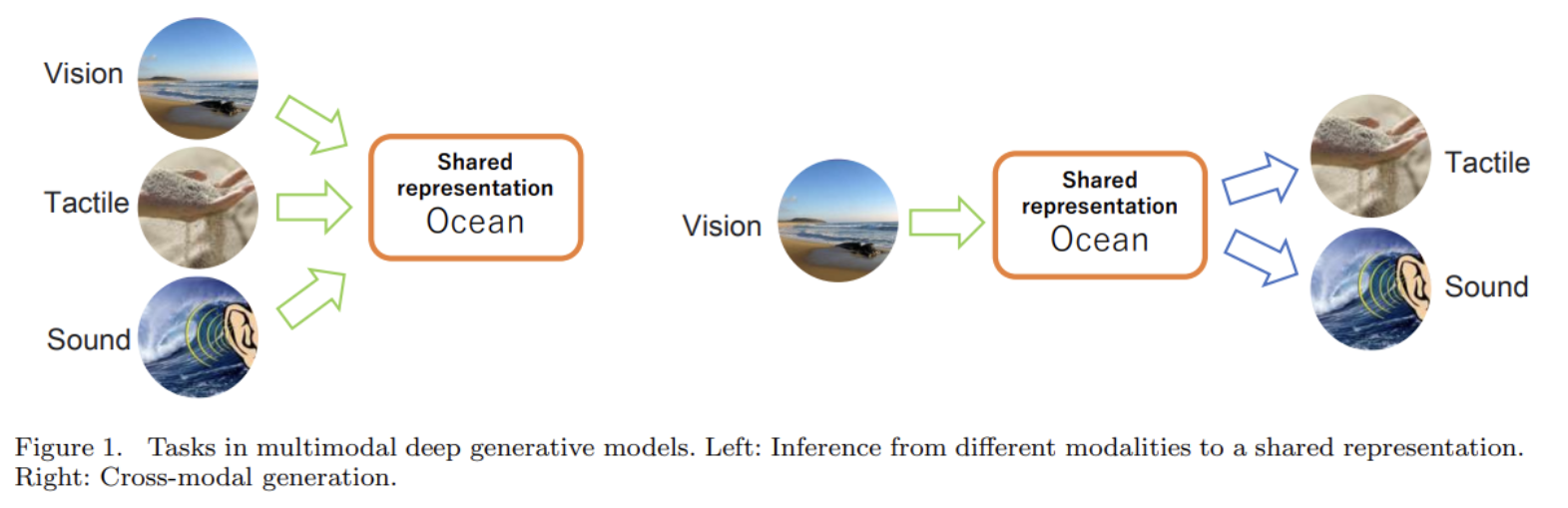
논문은 multimodal generative model이 다음 두 목적이 있다고 가정한다.
- multimodal representation learning : Embed all modalities X in a good common space called the shared representation.
- cross-modal generation : Generate modalities from arbitrary modalities Xk via the shared representation z
Therefore, the key issues for multimodal generative models are twofold: how to design and train the above generative models, and how to perform inference to a latent variable.
deep generative model 이전에도 multimodal을 다루는 generative model-based methods가 존재했으나 could not directly infer from or generate complex data such as images.
Deep generative models은 variational autoencoders (VAEs) [43], generative adversarial networks (GANs) [19], autoregressive models [64, 102], flow-based models [42, 72] 등이 있다.
다른 모델에 비한 VAE의 장점
- VAEs represent both generation and inference as paths of DNNs; therefore, their training and execution are fast and they can handle high-dimensional and complex inputs
- VAEs are good models for representation learning. As mentioned earlier, good representation requires the inclusion of general-purpose priors in the model. It is known that VAEs can easily incorporate such priors by adding constraints to the inference distribution and by explicitly assuming a graphical model structure [101].
- since VAEs are probabilistic models, they can explicitly represent differences in the distribution of data, unlike normal deep autoencoders. In other words, VAEs can explicitly deal with the heterogeneity of multimodal data.
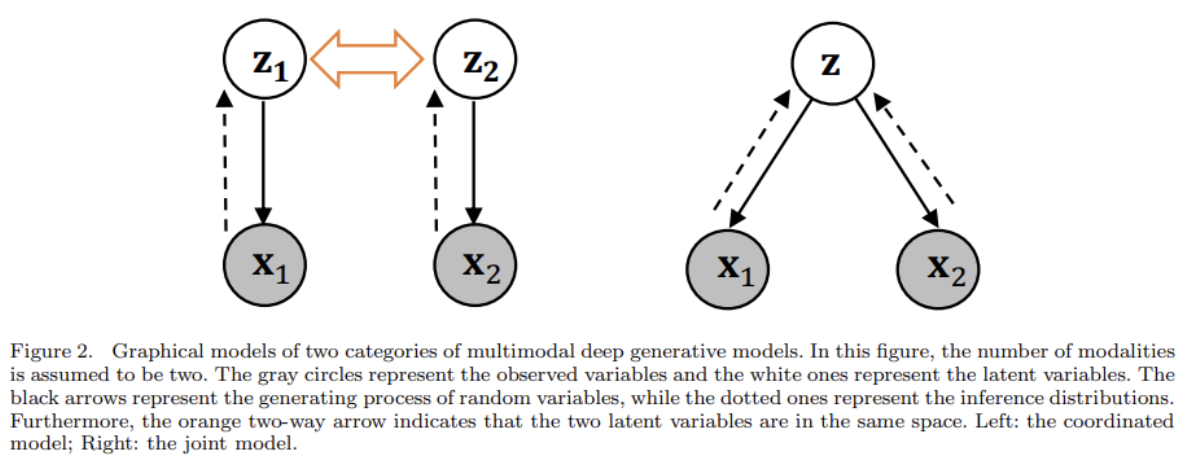
앞서 말했듯 multimodal deep generative models를 어떻게 그들이 inference to shared representation를 model하느냐에 따라 둘로 구분한다. single modality에서 inference를 modeling하면 coordinated model, all modalities에서 inference를 modeling하면 joint model이다.
두 카테고리 모두 multimodal generative model의 두 목적인 multimodal representation learning와 cross-modal generation을 만족하려한다. 첫목적은 VAE의 representation learning로 성취되기에 두 번째 목적에 집중하는데, coordinated model과 joint model은 여기서 조금 다르다.
The coordinated model aims for the inference results from each modality to be the same, whereas the joint model aims for the inference results from any set of modalities to be the same.

The goal of the coordinated model is to bring the inference distributions conditioned on the different modalities closer together.
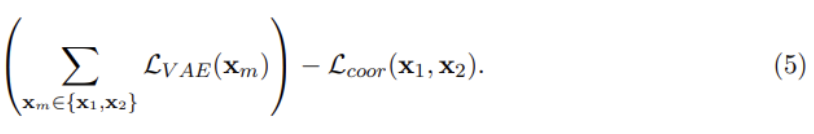
Lcoor을 정의하는 방법은 여러 종륜데 그 중 2가지로 distance between inference distributions와 cross-modal generation loss가 있다.
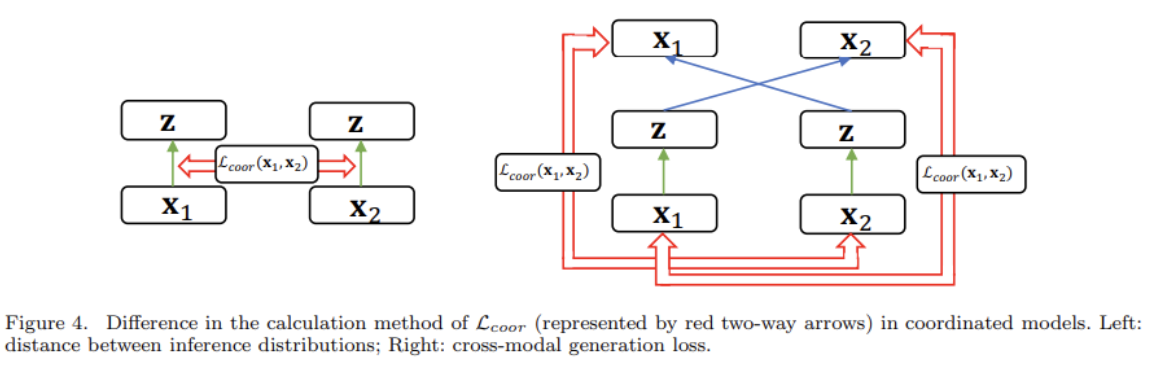
The coordinated model can embed each modality into the same shared representation using the encoder for each modality. However, this model cannot perform inference from all modalities. The joint model, on the other hand, directly models the inference qΦ(z|X) to the shared latent space given all modalities X.
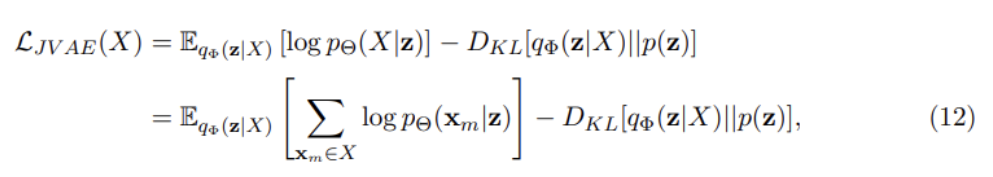
JVAE has three major challenges: handling of missing modalities, modality-specific latent variables, and weakly-supervised learning.
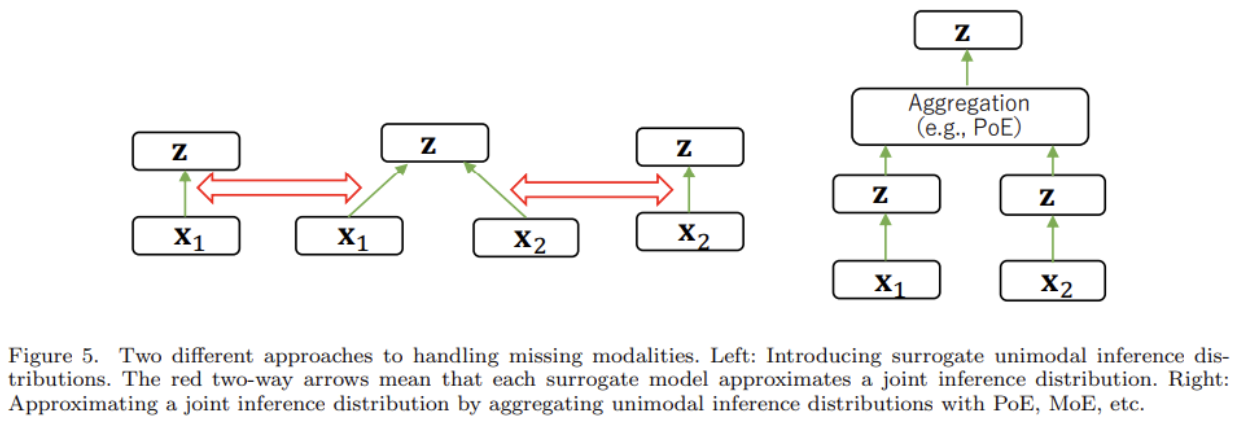
missing modality 문제는 2가지 방식으로, 1. introduce a surrogate unimodal inference distribution하는 방식과 2. approximate the joint inference distribution by aggregating the unimodal inference distributions하는 방식으로 다룬다.
- Future works에서 흥미로웠던 부분
Moreover, the greater the number and variety of modalities, the more difficult training the entire model end-to-end will be. Therefore, it is important to learn modules that deal with different modalities separately and integrate their inference. Coordinated models often use these two-step approaches; however, as mentioned earlier, they cannot perform inference on shared representations from arbitrary sets of modalities. Recently, Symbol Emergence in Robotics tool KIT (SERKET) [60] and Neuro-SERKET [93] have been proposed as a frameworks for integration in probabilistic models that deal with multimodal information. SERKET provides a protocol that divides inference from different modalities into the inference of modules of individual modalities and their communication, i.e., message-passing. Neuro-SERKET, an extension of the SERKET framework for including neural networks, can integrate modules of different modalities that perform different inference procedures, such as Gibbs sampling and variational inference.
Another possible approach is to refer to the idea of global workspace (GW) theory in cognitive science [4], in which interactions between different modules are realized by a shared space that can be modified by any module and broadcast to all modules. Goyal et al. [20] proposed an attention-based GW architecture for communicating positions and modules in Transformer [103] and slot-based modular architectures [21]. Such idea might also be applied to the integration of modules of different modalities.
