논문리뷰
1.목표

일단 년도별 추천 paper 찾아보고 학회 best paper award 받은 걸로도 찾아보자ex) CVPR, ICCV, ECCV, NeurIPS, ICML, AAAI, ICLRComputer Vision: 10 Papers to Start2
2.Distinctive Image Features from Scale-Invariant Keypoints

(2023.01.02)SIFT에 관해서는 주한별 교수님의 AI 강의시간에 배운 바가 있기 때문에 비교적 논문을 읽기 수월할 것으로 기대됐다.SIFT는 사진에서 invariant feature를 extract하는 방법인데, 이로써 서로 다른 크기와 각도에서 찍은 사진들에
3.Histograms of Oriented Gradients for Human Detection

HoG 논문이다. 이 역시 SIFT처럼 학교 강의에서 다룬 바가 있고, SIFT보다 페이지 수도 확연히 적어서 읽기 수월했다.(그렇다고 완벽히 이해했단 건 아니지만) 아래 포스트를 먼저 읽으면 이해에 도움이 될 것 같다. [정리]Histograms of Orien
4.Photo Tourism: Exploring Photo Collections in 3D

이 논문은 2D 사진 묶음에서 입체적인 3D 모형을 reconstruct하고, 그 사진들을 관리하기/둘러보기 쉽게 하는 방법을 소개한다. 논문은 저자들이 설계한 end to end system을 어떻게 만들었는지 설명하는데, section 5, 6, 7은 그 프로그램의
5.ImageNet Classification with Deep Convolutional Neural Networks
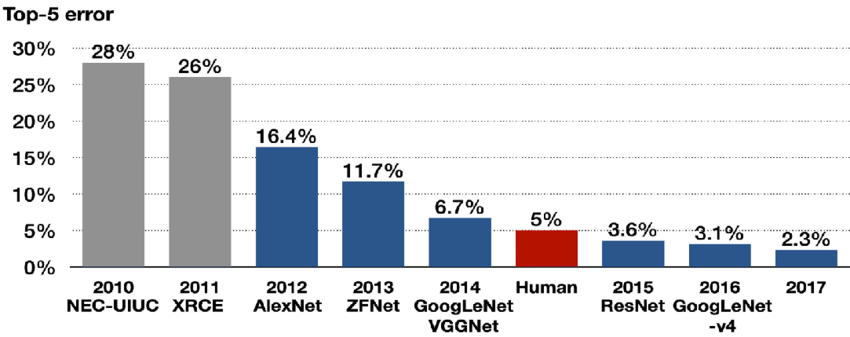
오늘 리뷰할 논문은 그 유명한 AlexNet 논문이다. ImageNet 데이터셋을 분류하는 대회에서 2012년 전년도에 비해 10%p나 오류율을 줄였고 이후로 image classification에 머신러닝이 우후죽순 사용하게 되었다. 유명한 모델이다보니 논문을 읽을
6.Visualizing and Understanding Convolutional Networks
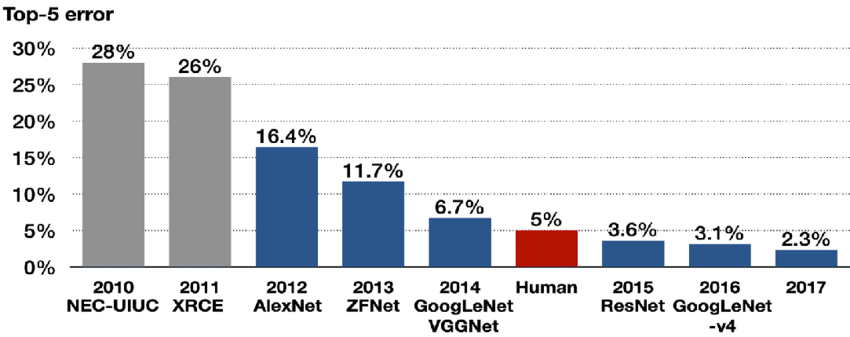
이번에 리뷰할 논문은 ZFNet 논문이다. 의도한 건 아닌데 어쩌다 보니 AlexNet 논문을 리뷰한 다음 순서로 이 논문을 리뷰하게 되었다. 이 논문이 ILSVRC-2013에서 우승하긴 했지만 ZFNet은 AlexNet을 약간 손 본 것에 지나지 않기 때문에 모델 자
7.Going deeper with convolutions
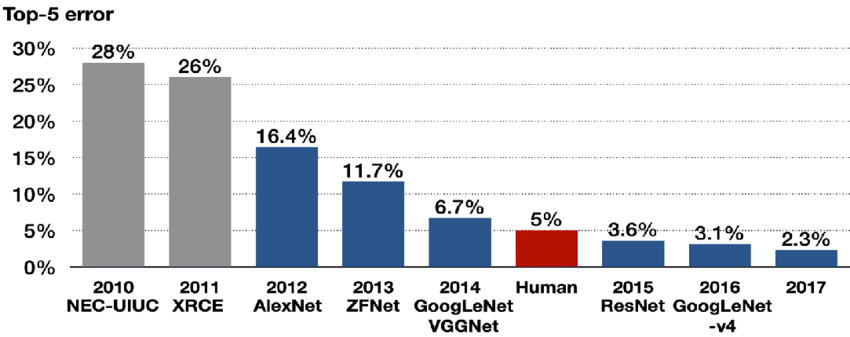
이번에 리뷰할 논문은 ILSVRC14에서 우승한 GoogLeNet 논문이다. network depth와 width는 증가했는데 동시에 computing resource 활용도 효율적으로 향상시켰다고 한다. 최적화에는 Hebbian principle, multi-scal
8.Very Deep Convolutional Networks for Large-Scale Image Recognition
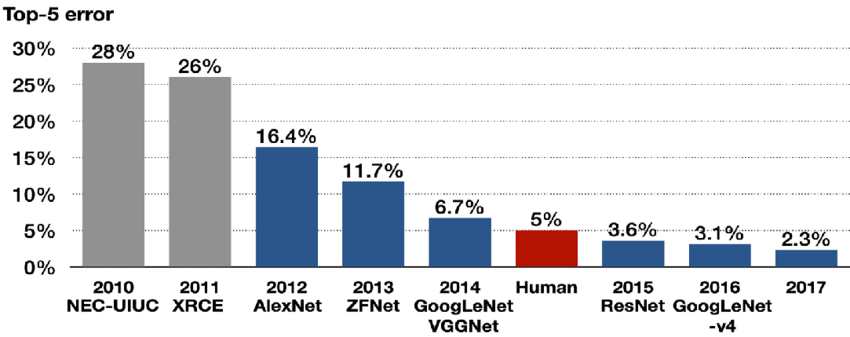
오늘 리뷰할 논문은 ILSVRC 2014에서 GoogLeNet에 밀려 우승하지는 못했지만 비교적 간단한 구조로 상당히 뛰어난 성과를 내 이후 수많은 모델의 backbone이 된 VGGNet의 논문이다. 이 논문의 주 목표는 작은 convolution 필터(3x3)를 사
9.Deep Residual Learning for Image Recognition
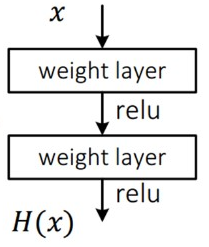
이번에 리뷰할 논문은 ILSVRC15에서 우승한 ResNet 논문이다. ResNet은 무려 152 layer으로 VGGNet보다 약 8배 더 깊은데, 이게 가능한 것은 ResNet이 residual block이라는 구조를 사용했기 때문이다. 이런 residual n
10.Rich feature hierarchies for accurate object detection and semantic segmentation
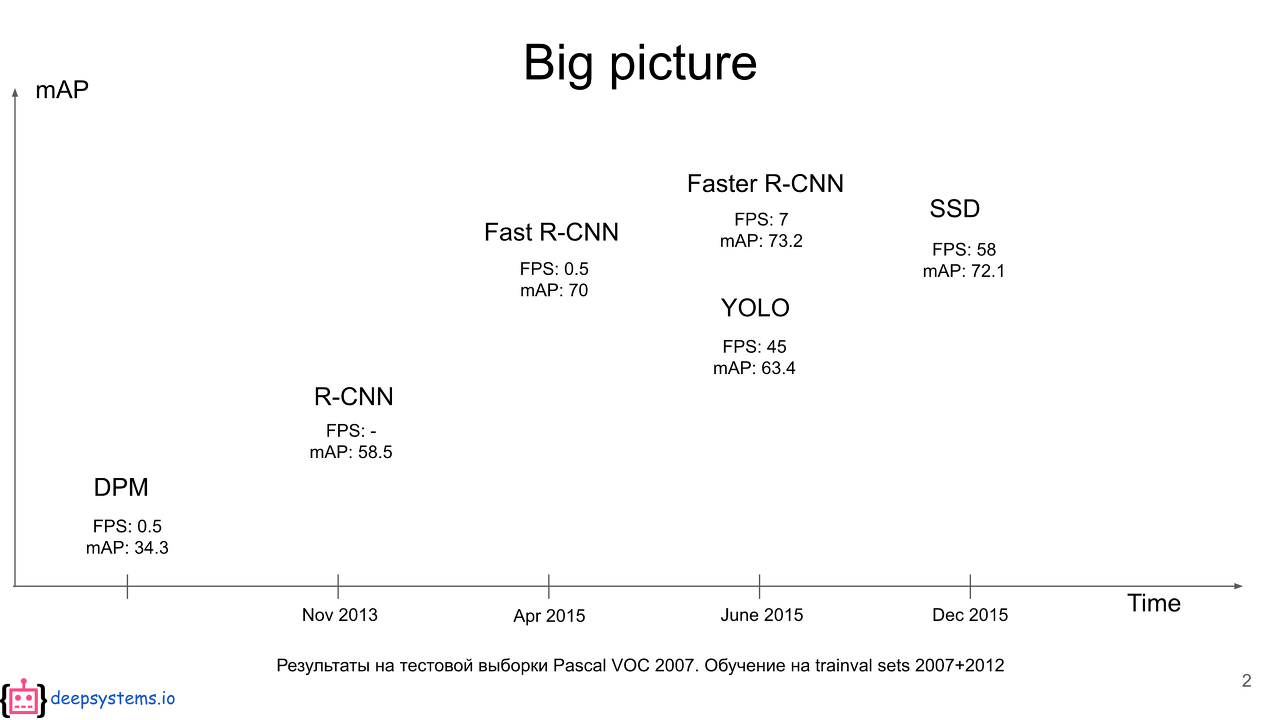
오늘의 논문은 object detection에 사용되는 R-CNN 논문이다. object detection은 물체의 위치(localization)와 종류(classification)를 모두 찾아내는 것이다. object detection은 localization과 cl
11.Disentangling Visual and Written Concepts in CLIP

이번 논문은 Disentangling Visual and Written Concepts in CLIP이라는 논문이다. 사실 대학 인공지능 강의 조별과제로 리뷰해서 제출한 것인데, 이참에 여기에도 올리겠다. 영강이었던지라 리뷰도 영어다. 번역은 귀찮아서(...) 안했다.
12.You Only Look Once: Unified, Real-Time Object Detection
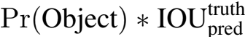
이번에 리뷰할 논문은 YOLO 논문이다. 기존의 2-stage object detection과 달리 YOLO는 1-stage object detection으로, 물체의 위치와 종류를 동시에 찾는다.object detection에서 기존의 논문들은 classifier을
13.Generative Adversarial Nets
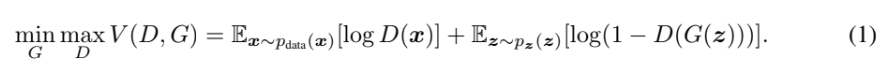
오늘의 리뷰는 그 유명한 GAN 논문이다.아래 포스트들을 먼저 읽으면 도움이 될 것이다.GAN(GAN)Generative Adversarial Nets 논문 리뷰논문의 목표는 adversarial process를 통해 generative model을 추정하는 것이며,
14.Network In Network
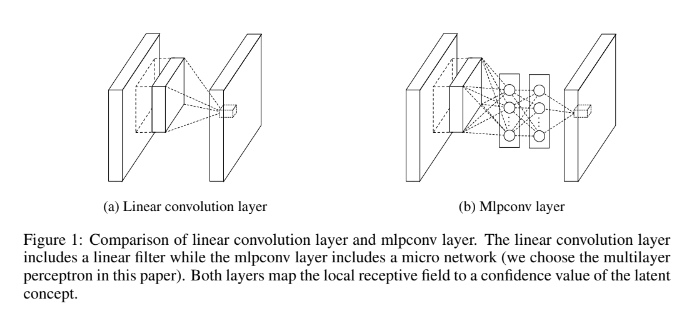
오늘 리뷰할 논문은 NiN 논문이다. 앞서 읽은 여러 논문에서 Lin et al.이란 이름으로 자주 등장하길래 도대체 무슨 논문인가 궁금해져서 읽게 되었다.논문의 목표는 Network In Network(NIN)라고 이름붙인 deep network structure를
15.Selective Search for Object Recognition

오늘 리뷰할 논문은 R-CNN에서 region proposal을 하는 원천 기술인 selective search 알고리즘에 대한 논문이다. R-CNN 논문을 읽고 궁금해져서 리뷰하게 되었다.이 논문의 목표는 object recognition에 이용할 수 있는 objec
16.Squeeze-and-Excitation Networks
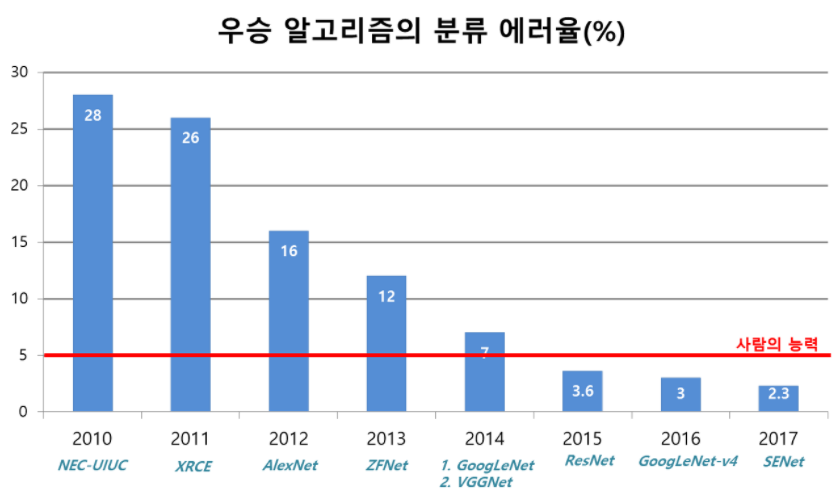
오늘 리뷰할 논문은 ILSVRC 2017에서 우승한 SENet 논문이다. 논문은 “Squeeze-and-Excitation” (SE) block를 소개함으로써 channel relationship에 집중한다. SE block은 channel간 상호의존성을 명시적으로 m
17.U-Net: Convolutional Networks for Biomedical Image Segmentation
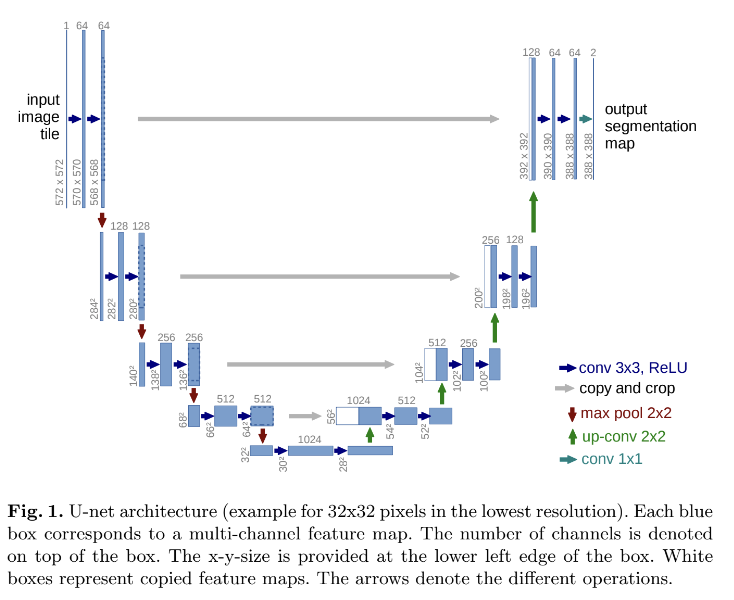
오늘 리뷰할 논문은 ISBI cell tracking challenge 2015에서 우승한 U-Net 논문이다. U-Net이 stable diffusion에 쓰인다고 해서 호기심이 생겨 읽게 되었다. 이 논문에서는 data augmentation의 사용에 강하게 의존하
18.A Neural Algorithm of Artistic Style

오늘 리뷰할 논문은 고흐 사진으로 유명한 style transfer 논문이다.논문은 CNN(VGGNet)을 이용해 사진/그림을 style과 content라는 요소로 구분해 이 두 가지를 재조합하여 새로운 artistic image를 생성하는 것을 목표로 한다.CNN에서
19.Efficient Estimation of Word Representations in Vector Space
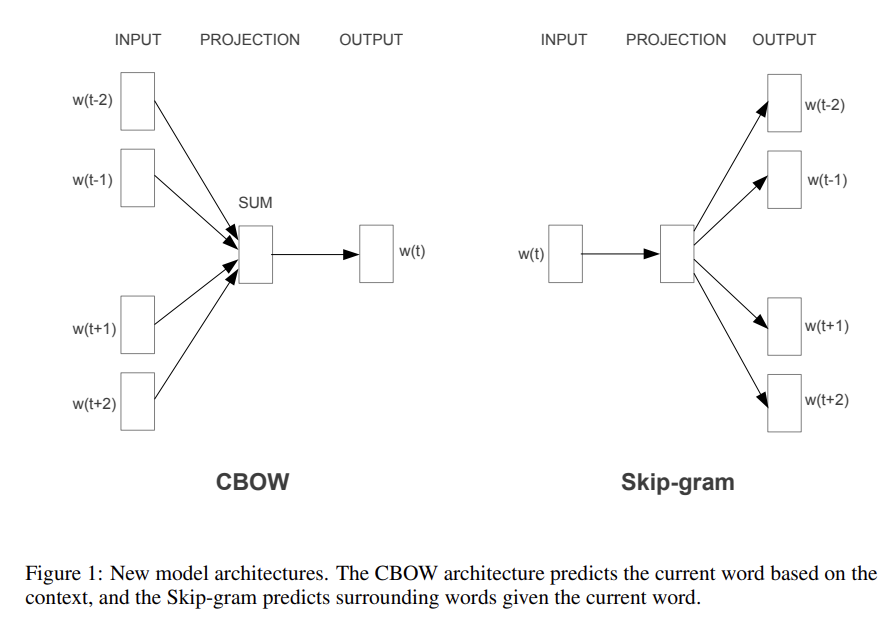
오늘 리뷰할 논문은 word2vec 논문이다. 논문의 목표는 10억 개 이상의 단어를 가진 큰 데이터셋으로부터 high-quality word vectors를 배우는 것이다.아래 포스트를 먼저 읽으면 도움이 될 것이다.\[NLP 논문 리뷰] Efficient Estim
20.Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
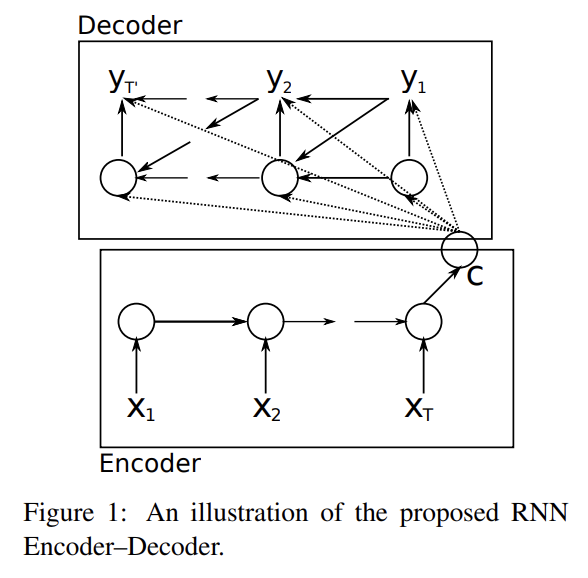
오늘 리뷰할 논문은 최초의 seq2seq이자 LSTM의 변형인 Gated Recurrent Units (GRU)를 제안한 논문이다.논문에선 2개의 RNN을 연결해 RNN Encoder–Decoder라고 이름붙인 모델을 만든다. encoder은 (길이가 자유로운) sym
21.Sequence to Sequence Learning with Neural Networks
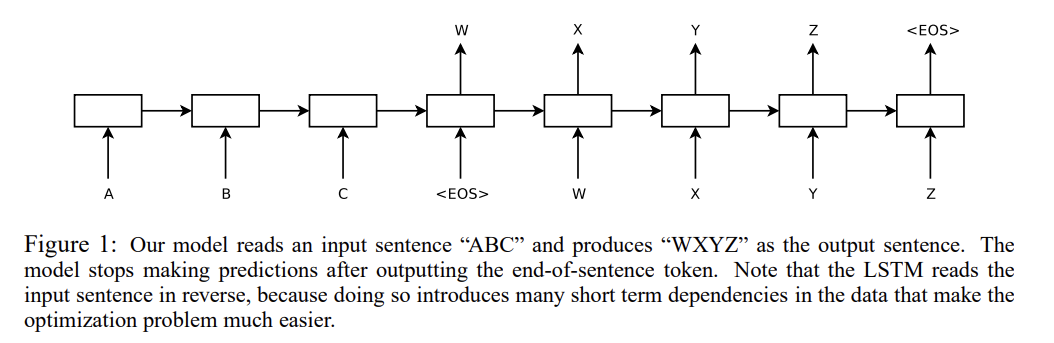
이번에 리뷰할 논문은 seq2seq 논문이다. 최초로 seq2seq를 제안한 논문은 아닌데(최초의 논문은 직전 리뷰에서 다뤘다) 성능/결과물이 뛰어나서 유명한 논문이라고 한다.논문은 LSTM 2개를 encoder, decoder 역할로 연결해서 sequence 정보를
22.Attention Is All You Need
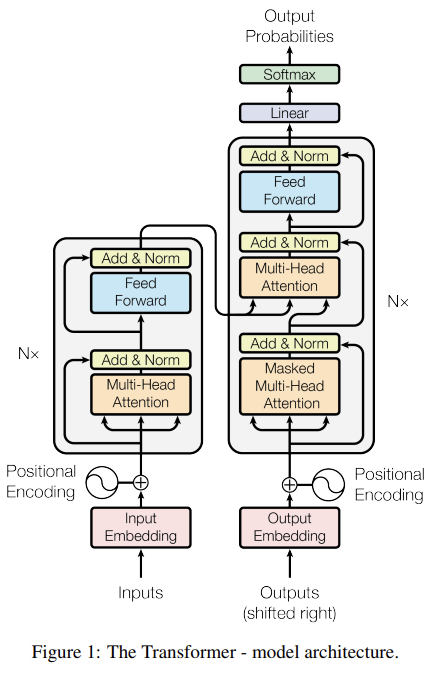
오늘 리뷰할 논문은 transformer를 도입한 유명한 논문이다(attention 자체는 이전에도 많이 쓰이고 있었다).아래 포스트를 먼저 읽으면 도움이 될 것이다.16-01 트랜스포머(Transformer)\[논문리뷰] Attention is All you need
23.Image-to-Image Translation with Conditional Adversarial Networks

오늘 리뷰할 논문은 위의 Fig 1으로 유명한 pix2pix 논문이다.논문은 image-to-image translation 문제에 대한 범용적인 해결책으로 conditional adversarial networks를 제시한다. 전통적으론 각각의 문제에 대해 다른, 특
24.A Discriminatively Trained, Multiscale, Deformable Part Model

오늘 리뷰할 논문은 HOG를 이용한 초기 object detection 알고리즘인 deformable part model (DPM)이다.논문을 읽었는데 이해는 거의 못해서 리뷰 퀄이 많이 낮다.아래 포스트를 먼저 읽으면 도움이 될 것이다.4\. DPM (Deformab
25.OverFeat: Integrated Recognition, Localization and Detection using Convolutional Networks

오늘 리뷰할 논문은 R-CNN과 동시대에 나온 object detection 모델이며 ILSVRC 2013 localization task의 우승자인 OverFeat이다. R-CNN 논문에서 OverFeat와 성능을 비교한 부분이 있어 호기심이 생겨 읽게 되었다.아래
26.Fast R-CNN
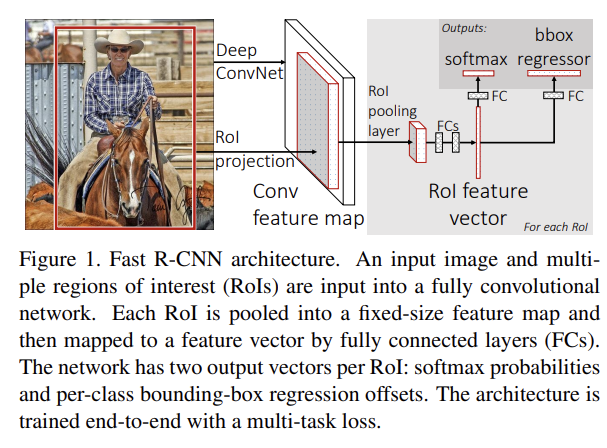
오늘 리뷰할 논문은 R-CNN의 발전형인 R-CNN이다. R-CNN의 단점이었던 속도를 개선하고 정확도도 향상시켰다.논문은 classify object proposals와 refine spatial locations를 동시에 학습하는 single-stage traini
27.Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks

오늘 리뷰할 논문은 Fast R-CNN의 발전형인 Faster R-CNN이다.Fast R-CNN은 여전히 region proposal computation을 속도의 bottleneck으로 가진다. 논문은 detection network와 full-image convol
28.SSD: Single Shot MultiBox Detector

오늘 리뷰할 논문은 OverFeat, MultiBox, SPPNet, YOLO처럼 1-stage object detection을 하는 SSD 논문이다.아래 포스트를 먼저 읽으면 도움이 될 것이다.SSD 논문(SSD: Single Shot MultiBox Detector
29.Feature Pyramid Networks for Object Detection

오늘 리뷰할 논문은 Feature Pyramid Network (FPN) 논문이다. Mask R-CNN에 FPN이 쓰인다고 하여 먼저 읽게 되었다.아래 포스트를 먼저 읽으면 도움이 될 것이다.FPN 논문(Feature Pyramid Networks for Object
30.Mask R-CNN
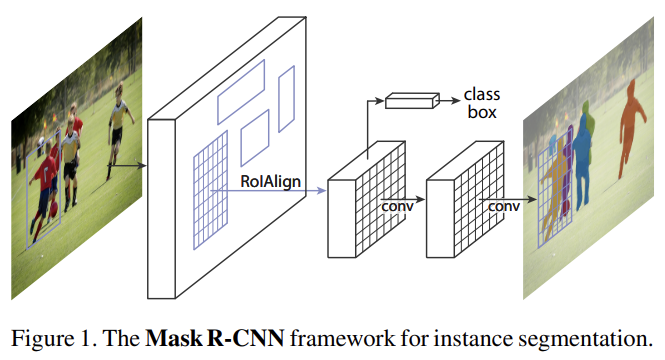
오늘 리뷰할 논문은 object detection과 object instance segmentation에 사용되는 Mask R-CNN이다.아래 포스트를 먼저 보면 도움이 될 것이다.Mask R-CNN 논문(Mask R-CNN) 리뷰MASK RCNN 논문 리뷰\[논문 리
31.High-resolution image reconstruction with latent diffusion models from human brain activity

논문은 functional Magnetic Resonance Imaging (fMRI)와 latent diffusion model (LDM), 특히 Stable Diffusion을 이용해 brain activity에서 visual image를 reconstruct하고자
32.UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
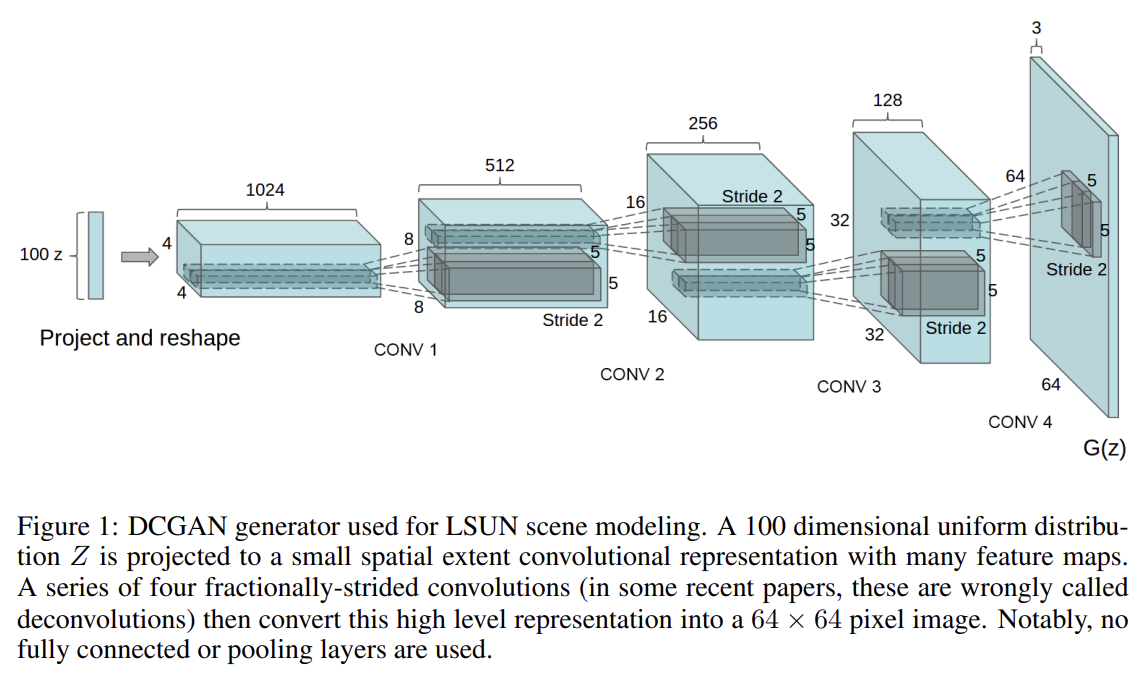
오늘 리뷰할 논문은 Deep Convolutional GANs, DCGAN 논문이다.논문은 DCGANs를 제안해 CNN의 unsupervised learning이 효과적임을 보이고자 한다.최근(당시) 유행하는 방식은 large unlabeled datasets에서 재사
33.InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets

오늘 리뷰할 논문은 InfoGAN 논문이다.InfoGAN은 비지도학습으로 disentangled representations을 학습하고 latent variables와 observation(=생성한 이미지) 사이의 mutual information을 최대화한다. 논문은
34.Wasserstein GAN
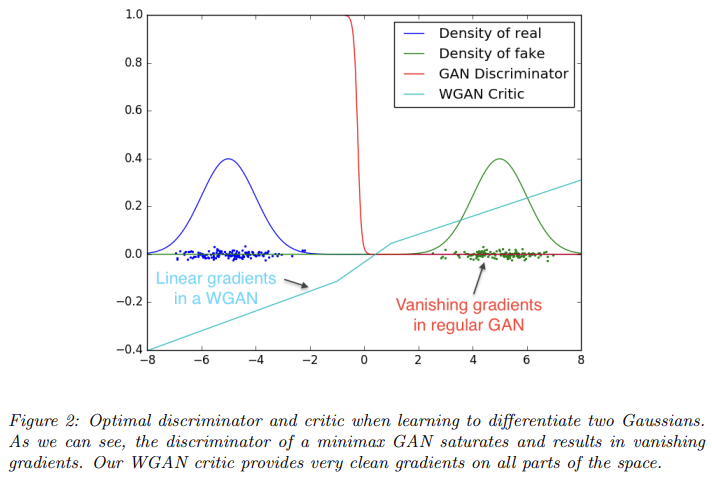
오늘 리뷰할 논문은 Wasserstein GAN, WGAN 논문이다. 기존 GAN은 두 확률 분포 비교를 위해 KL Divergence를 사용했는데 WGAN은 Wassestein Distance(EM distance)를 도입했다.unsupervised learning은
35.Improved Training of Wasserstein GANs
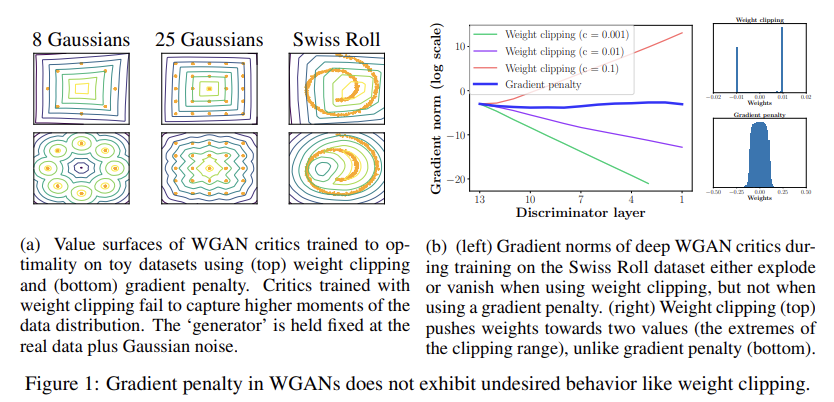
오늘 리뷰할 논문은 WGAN을 보완한 WGAN-GP 논문이다.GANs는 강력한 generative model이지만 training instability에 시달린다. WGAN은 stable training에 성취를 이루었지만 여전히 poor samples만을 생성하거나
36.Least Squares Generative Adversarial Networks
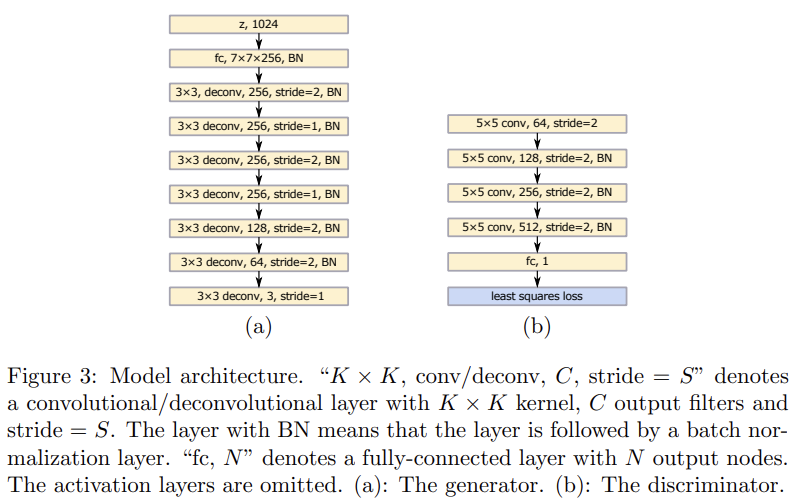
오늘 리뷰할 논문은 LSGAN 논문이다.기존의 일반적인 GANs는 discriminator에 sigmoid cross entropy loss function를 사용한다. 하지만 이 loss function은 generator을 (real data에서 여전히 멀지만 de
37.ENERGY-BASED GENERATIVE ADVERSARIAL NETWORKS
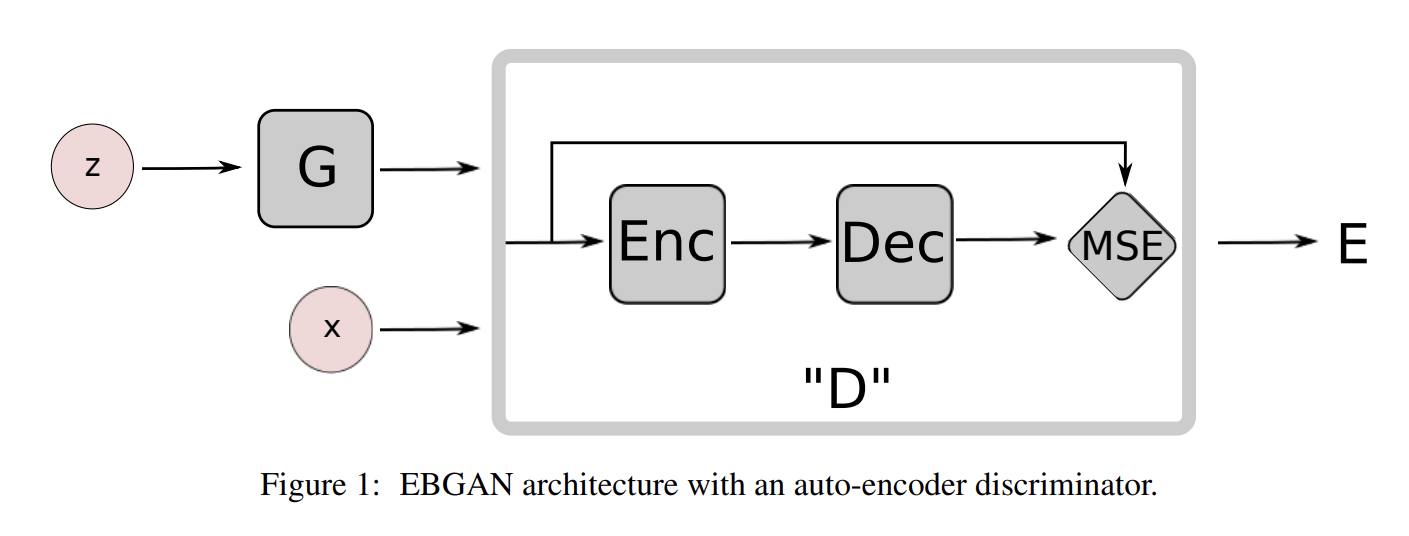
오늘 리뷰할 논문은 EBGAN 논문이다.증명의 수학은 이해하지 못했다.energy-based model이란 것은 input space의 각 점을 single scalar 값인 "energy"로 map하는 함수를 만든다는 것이다. learning phase에서는 desi
38.BEGAN: Boundary Equilibrium Generative Adversarial Networks
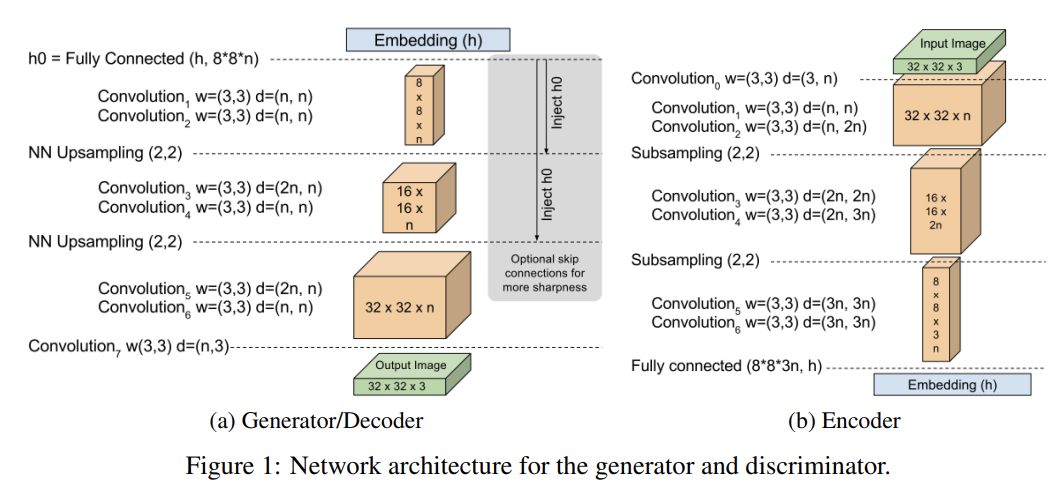
오늘 리뷰할 논문은 BEGAN 논문이다.기존 GANs의 문제는 train이 어렵다는 것, hyper-parameter selection이 매우 중요하다는 것, generated samples의 image diversity를 조절하는 게 어렵다는 것 등이 있다. 또 ge
39.Conditional Generative Adversarial Nets
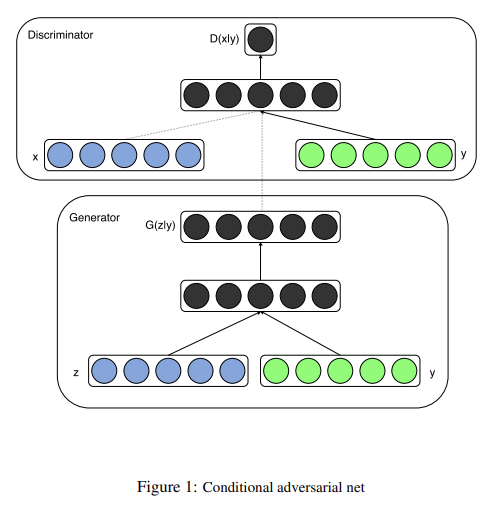
오늘 리뷰할 논문은 conditional GANs, CGAN 논문이다.아래 포스트를 먼저 읽으면 도움이 될 것이다.\[논문 리뷰 및 실습]Conditional GAN\[논문 리뷰] Conditional Generative Adversarial Nets\[논문리뷰]Con
40.Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks

오늘 리뷰할 논문은 CycleGAN이다.논문은 image-to-image translation을 목표로, paired training data가 없는 상황에서 source domain X에서 target domain Y로 mapping하는 G : $$X \\to Y$$
41.Semantic Image Synthesis with Spatially-Adaptive Normalization

오늘 리뷰할 논문은 SPADE(Spatially-Adaptive Denormalization), GauGAN 논문이다.논문은 특정 input data에 conditioning하여 photorealisstic image를 생성하는 Conditional image synt
42.StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation

오늘 리뷰할 논문은 StarGAN이다. 참고로 한국에서 나온 논문이다.image-to-image translation task는 특정 domain의 image를 다른 domain의 image로 변환하는 과제다. 논문은 'attribute'를 hair color, gen
43.Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network

오늘 리뷰할 논문은 SRGAN 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문] SRGAN 리뷰 : Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network\[논
44.MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
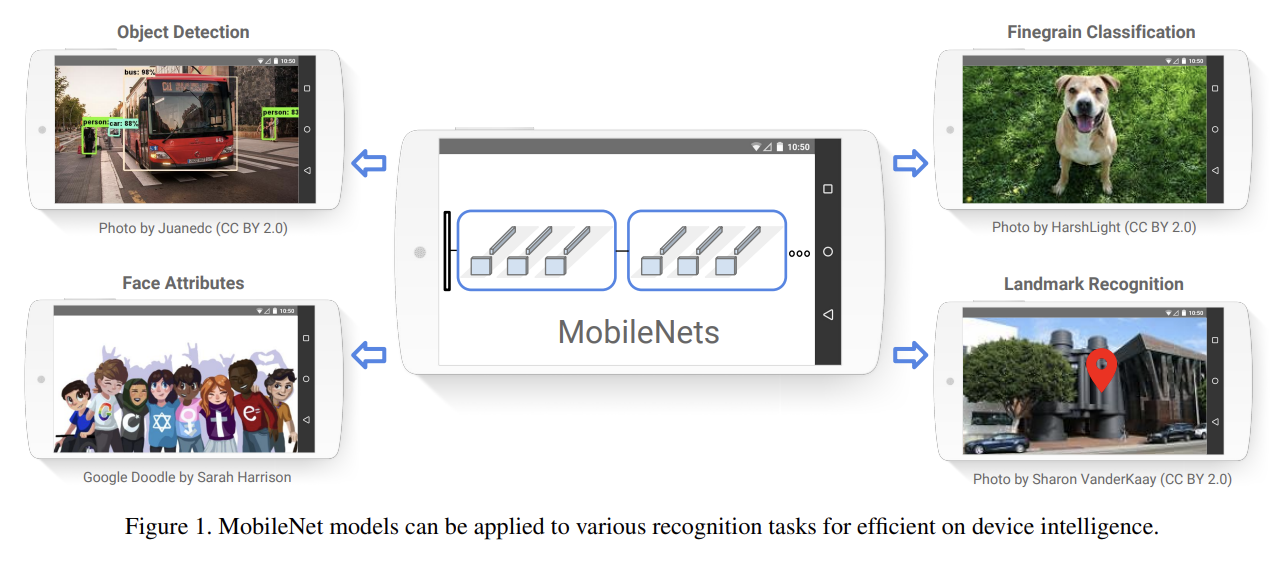
오늘 리뷰할 논문은 MobileNet이다.논문은 mobile, embedded vision applications을 위해 효율적인 small, low latency network architecutre을 소개한다. 그리고 application의 resource rest
45.MobileNetV2: Inverted Residuals and Linear Bottlenecks

오늘 리뷰할 논문은 MobileNetV2다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문 읽기] MobileNetV2(2018) 리뷰, MobileNetV2: Inverted Residuals and Linear BottlenecksMobileNetV2 논문 설명
46.Searching for MobileNetV3
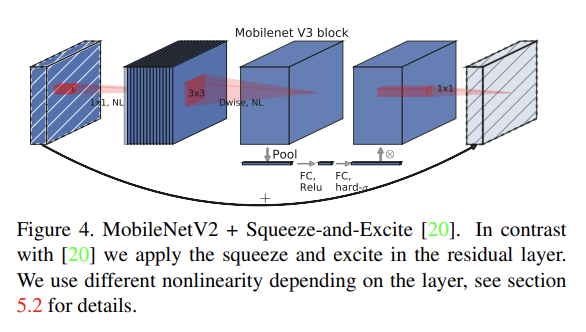
오늘 리뷰할 논문은 MobileNetV3이다.논문은 complementary search techniques의 조합과 새로운 architecture로 MobileNetV3를 제시한다. MobileNetV3는 NetAdapt algorithm로 보완되는 hardwarea
47.SPECTRAL NORMALIZATION FOR GENERATIVE ADVERSARIAL NETWORKS
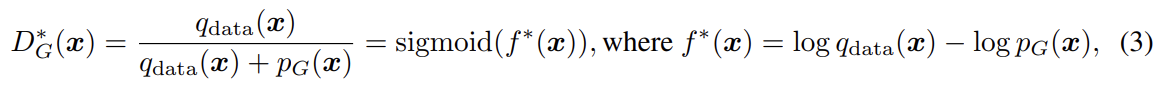
오늘 리뷰할 논문은 SNGAN 논문이다. 아래 포스트를 먼저 읽으면 도움이 될 것이다. https://aigong.tistory.com/371 Summary GAN의 고질적인 문제는 discriminator의 performance control이다. high d
48.Self-Attention Generative Adversarial Networks
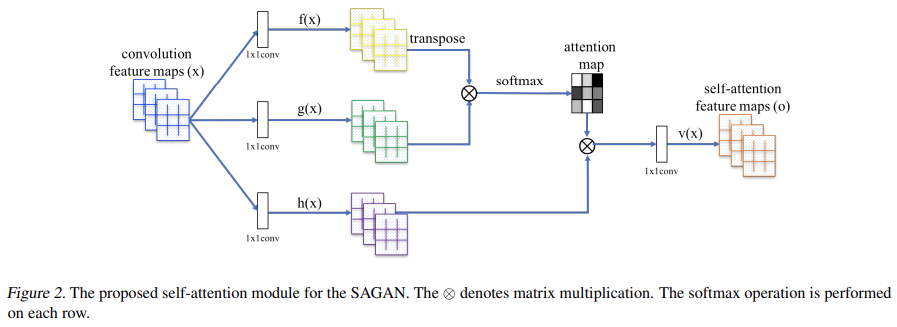
오늘 리뷰할 논문은 attention을 GAN에 적용한 SAGAN 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문 리뷰] Self-Attention Generative Adversarial Networks\[paper-review] Self-Attentio
49.LARGE SCALE GAN TRAINING FOR HIGH FIDELITY NATURAL IMAGE SYNTHESIS
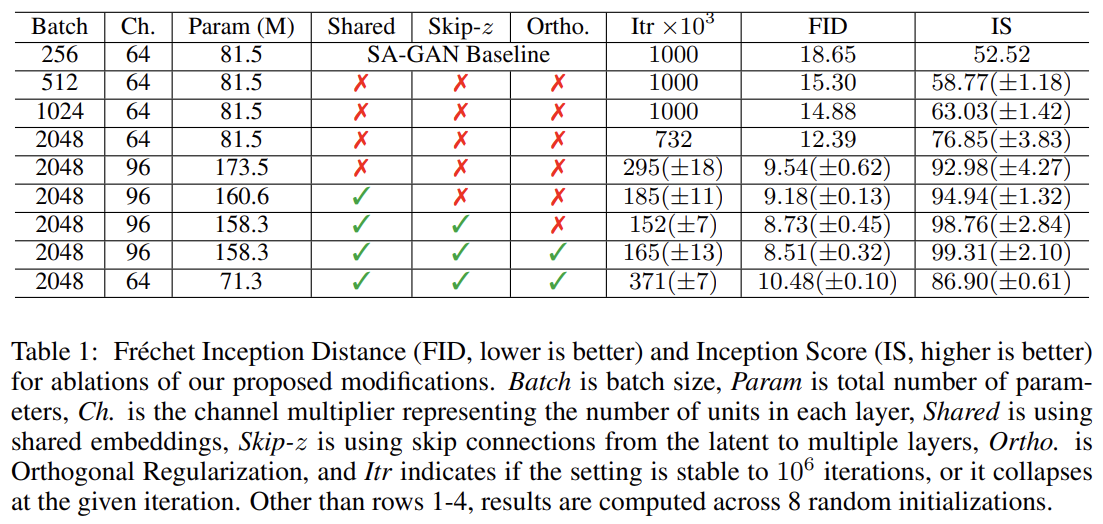
오늘 리뷰할 논문은 BigGAN 논문이다. GAN의 크기, batch size도 키우고 데이터셋인 ImageNet도 커서 BigGAN이라고 이름붙인 것 같다.GAN은 다양하고 퀄리티 좋은 이미지를 생성하게 발전했지만 여전히 ImageNet 같은 크고 복잡한 데이터셋은
50.PROGRESSIVE GROWING OF GANS FOR IMPROVED QUALITY, STABILITY, AND VARIATION
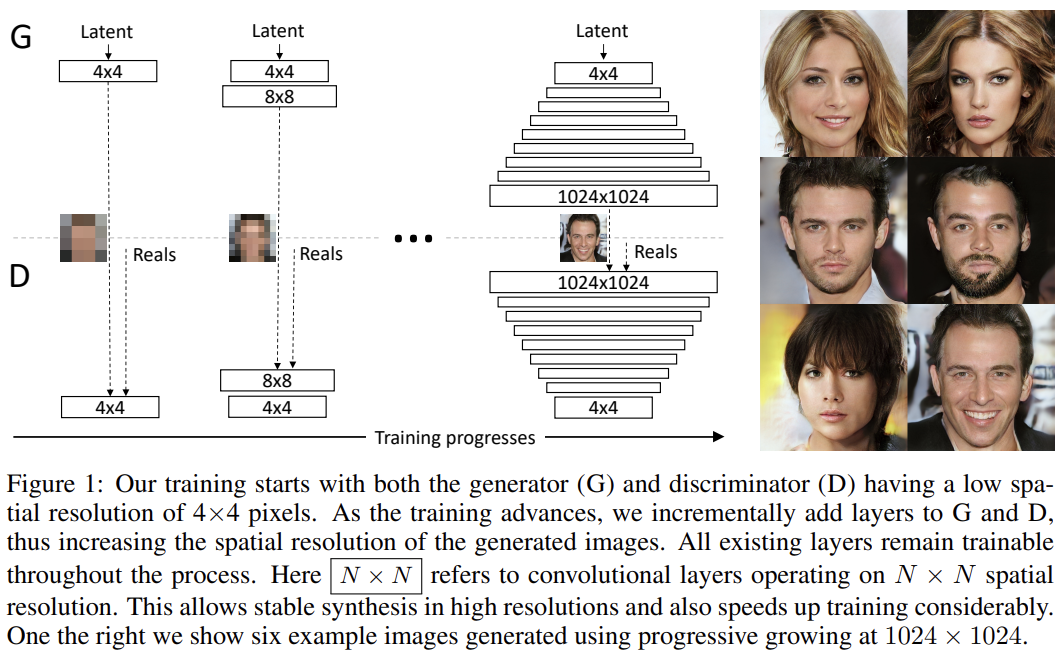
오늘 리뷰할 논문은 PGGAN 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.PGGAN 개인정리(논문 리뷰 Progressive Growing of GANs for Improved Quality, Stability, an\[DL - 논문 리뷰] Progressiv
51.A Style-Based Generator Architecture for Generative Adversarial Networks
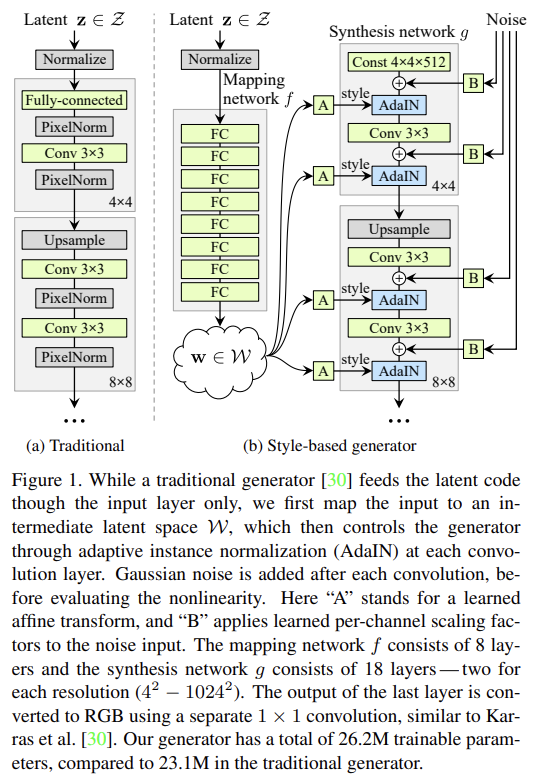
오늘 리뷰할 논문은 유명한 StyleGAN 논문이다. PGGAN을 바탕으로 Style transfer를 적용해서 style을 scale 별로 조절할 수 있다고 한다.논문은 generated image의 high-level attributes (사람 얼굴을 학습했을 때
52.Analyzing and Improving the Image Quality of StyleGAN

오늘 리뷰할 논문은 StyleGAN2다.논문은 StyleGAN의 architecture와 training method를 바꿔 characteristic artifacts를 다룬다. 특히 generator normalization를 다시 디자인하고, progressive
53.StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks

오늘 리뷰할 논문은 StackGAN이다.논문은 text description에서 high-quality, 256×256 photo-realistic image를 생성하기 위해 Stacked Generative Adversarial Networks (StackGAN)을
54.A Survey of Vision-Language Pre-Trained Models

오늘 리뷰할 논문은 Vision-Language PreTrained Models (VL-PTMs)에 대한 survey 논문이다. survey 논문이라 리뷰라기보다는 개인적으로 흥미로운 내용을 간단히 메모하는 수준으로 포스트를 적을 것 같다.BERT, CLIP, FLAV
55.A survey on Self Supervised learning approaches for improving Multimodal representation learning
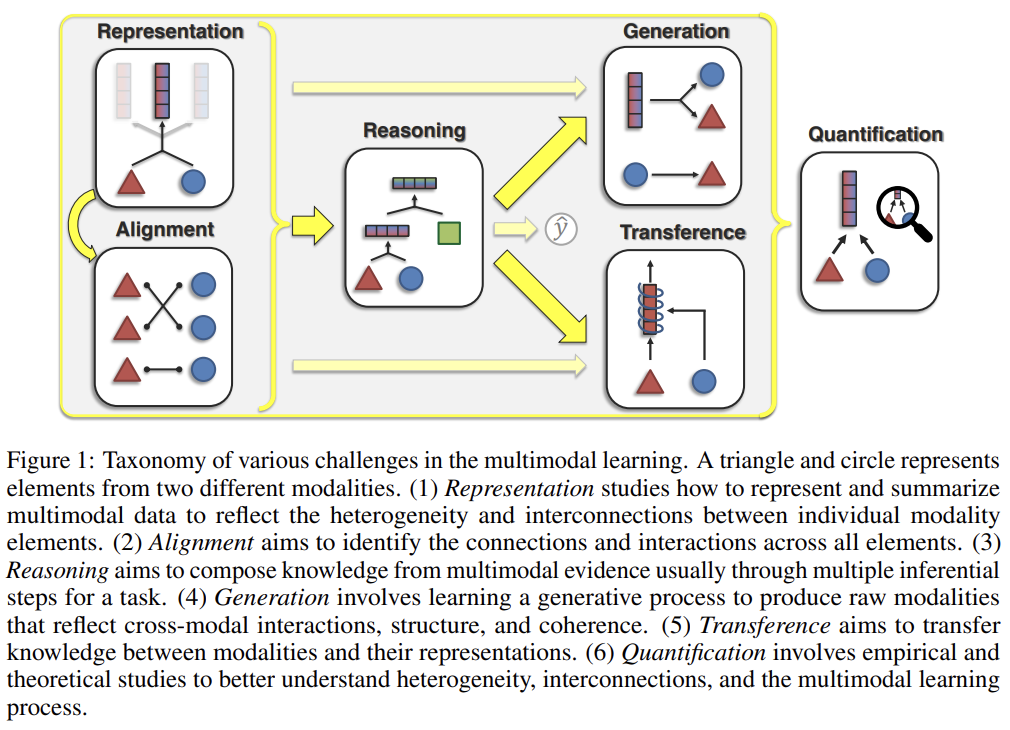
오늘 리뷰할 논문은 multimodal survey 논문이다. multimodal approach에서 유명한 4가지 방식을 소개하는 듯하다.Self supervised unimodal label prediction and Multi-task for better repr
56.A survey of multimodal deep generative models
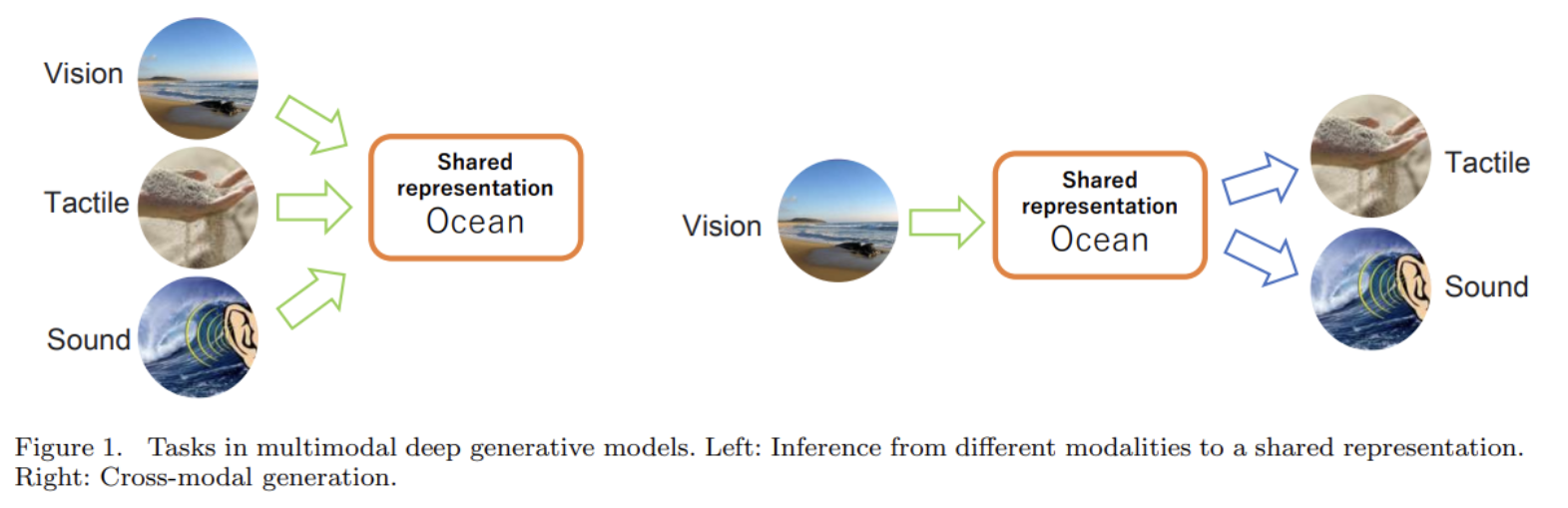
오늘 리뷰할 논문은 (대부분) VAE를 기반으로 한 multimodal generative models의 survey 논문이다.그런데 VAE 논문을 아직 안 읽어서 이거도 일단 대충 읽었다.Heterogeneity : modalities가 서로 다른 feature sp
57.Multimodal Learning with Transformers: A Survey
오늘 리뷰할 논문은 transformer 관련 Multimodal Learning (MML) survey다.찾아볼 논문ViT5VideoBERT 7CLIP논문의 구성은 다음과 같다.(1) a background of multimodal learning, Transform
58.Multimodal Machine Learning: A Survey and Taxonomy

오늘 리뷰할 논문은 multimodal 2017년 survey다.In this paper we identify and explore five core technical challenges (and related sub-challenges) surrounding mult
59.Self-Supervised Multimodal Learning: A Survey
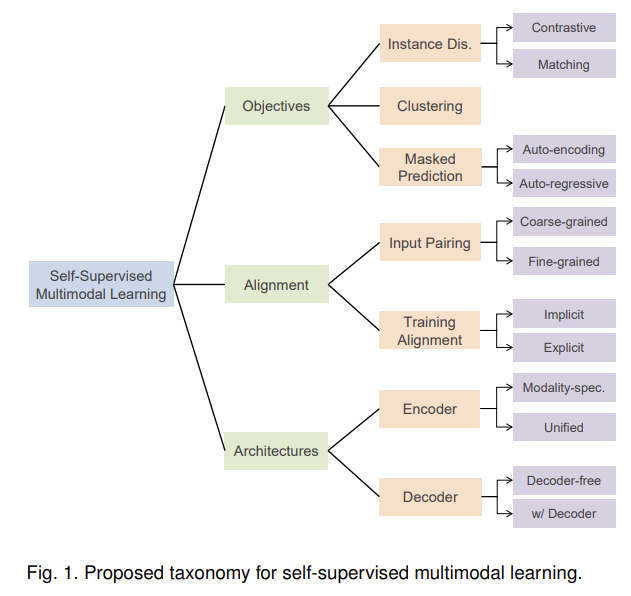
오늘 리뷰할 논문은 self-supervised multimodal learning (SSML)에 관한 survey 논문이다.찾아볼 것ViLBERTFLAVAActBERTOscarUNITERVisualBERTLXMERTVL-BERTMDETRActBERTBLIPIn thi
60.EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
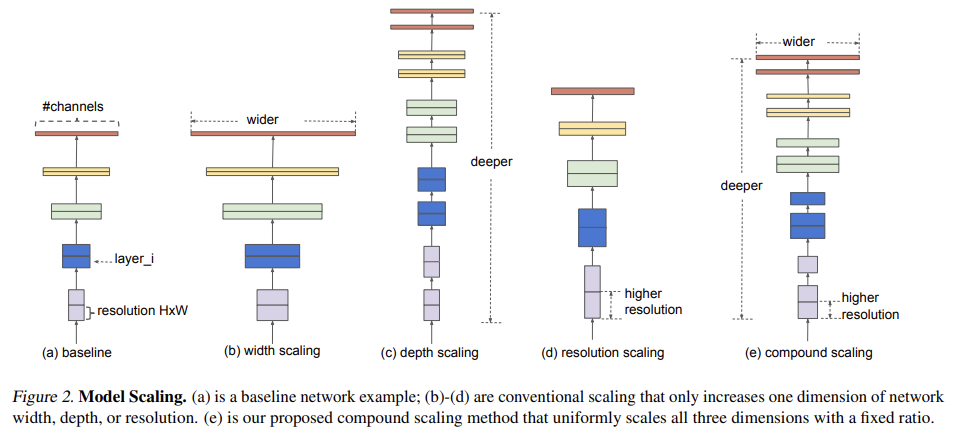
오늘 리뷰할 논문은 EfficientNet 논문이다. 논문의 목표는 주어진 resource constraint에서 model accuracy를 최대화하는 최적화를 찾는 것이다.기존의 ConvNet은 한정된 resource budget에서 개발된 후 더 많은 resour
61.EfficientDet: Scalable and Efficient Object Detection
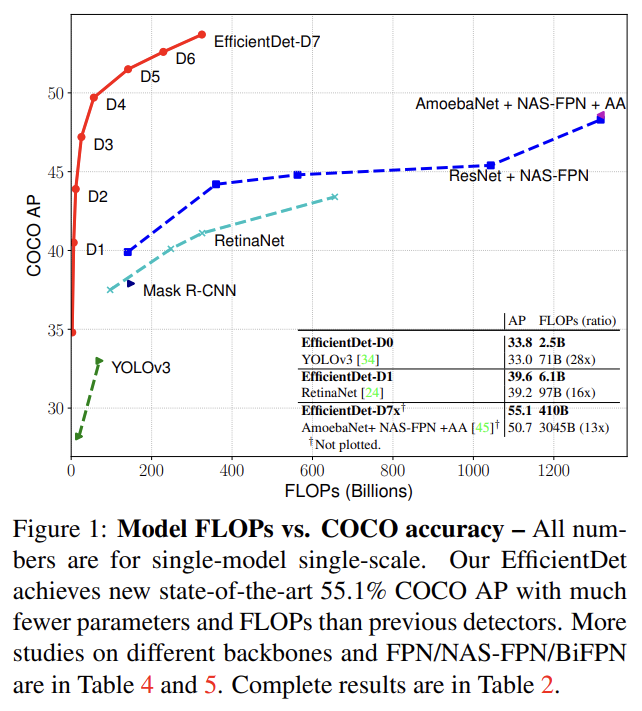
오늘 리뷰할 논문은 EfficientNet의 발전형이며 object detection에 사용되는 EfficientDet 논문이다.논문의 목표는 넓은 스펙트럼의 resource constraint에서 higher accuracy와 better efficiency를 가진
62.Auto-Encoding Variational Bayes
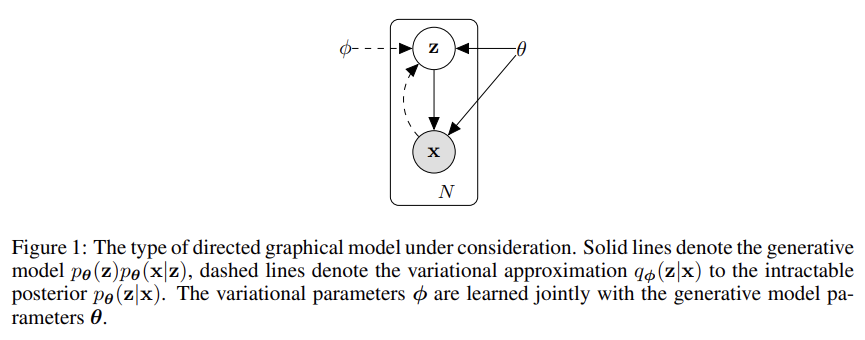
오늘 리뷰할 논문은 유명한 VAE 논문이다.continuous latent variables and/or parameters가 intractable posterior distributions를 가지는 directed probabilistic models로 어떻게 eff
63.GloVe: Global Vectors for Word Representation

오늘 리뷰할 논문은 word2vec처럼 단어 임베딩을 만드는 데 사용되는 GloVe 논문이다.word vector를 배우는 두 주요 모델은 1) latent semantic analysis (LSA) 같은 global matrix factorization methods
64.Improving Language Understanding by Generative Pre-Training
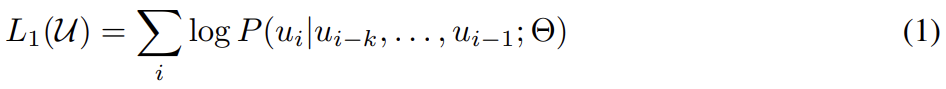
오늘 리뷰할 논문은 GPT-1 논문이다.NLP에는 다양한 task가 있고 large unlabeled text corpora는 많지만 specific task를 위한 labeled data는 적다. 논문은 language model을 diverse unlabeld te
65.Language Models are Unsupervised Multitask Learners
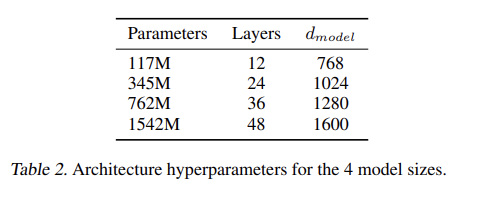
오늘 리뷰할 논문은 GPT-2 논문이다. Summary
66.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
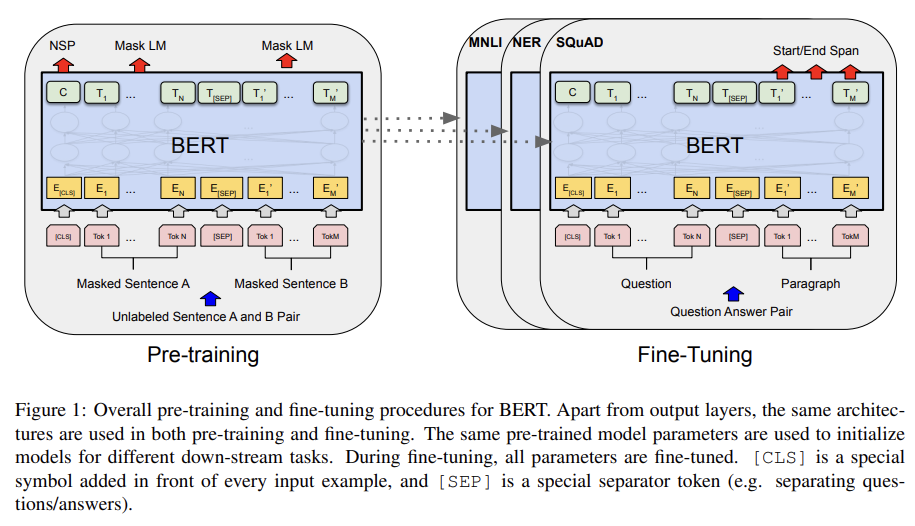
오늘 리뷰할 논문은 Bidirectional Encoder Representations fromTransformers, BERT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[최대한 자세하게 설명한 논문리뷰] BERT: Pre-training of Deep B
67.Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context

오늘 리뷰할 논문은 Transformer의 발전형인 Transformer-XL 논문이다.Transformer는 longer-term dependency를 학습할 수 있지만, fixed-length context로 제한된다. 그래서 논문은 temporal coherenc
68.BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
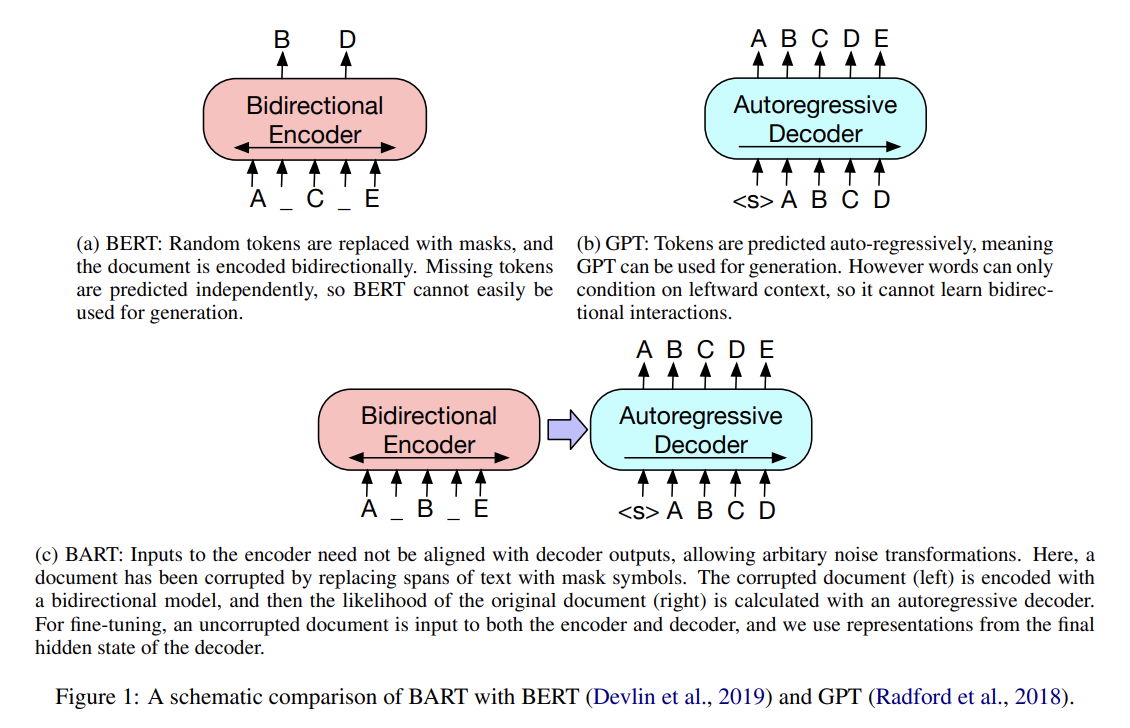
오늘 리뷰할 논문은 BART 논문이다. Summary
69.RoBERTa: A Robustly Optimized BERT Pretraining Approach
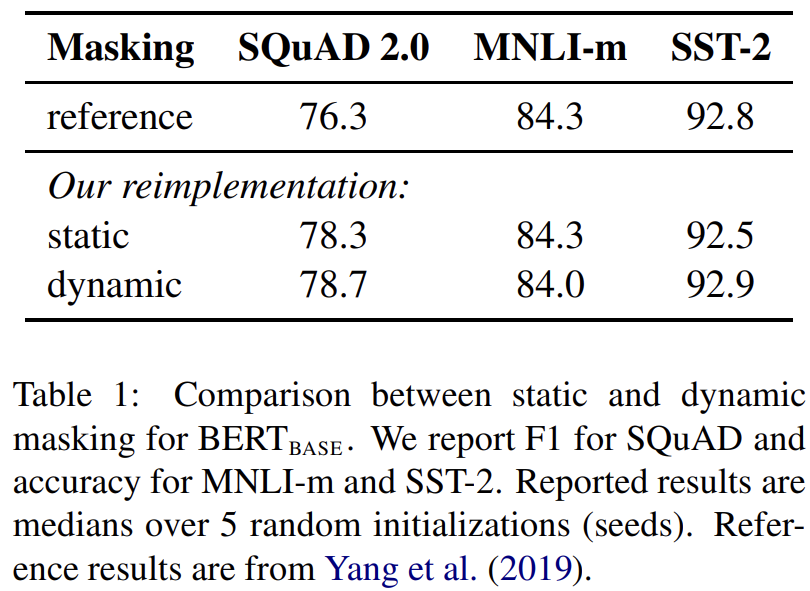
오늘 리뷰할 논문은 RoBERTa 논문이다.Language model pretraining의 여러 approaches 간 비교는 힘든데, training이 expensive하고 주로 다른 크기/종류의 dataset에 학습되며 hyperparameter 선택이 최종 성능
70.STRUCTBERT: INCORPORATING LANGUAGE STRUCTURES INTO PRE-TRAINING FOR DEEP LANGUAGE UNDERSTANDING
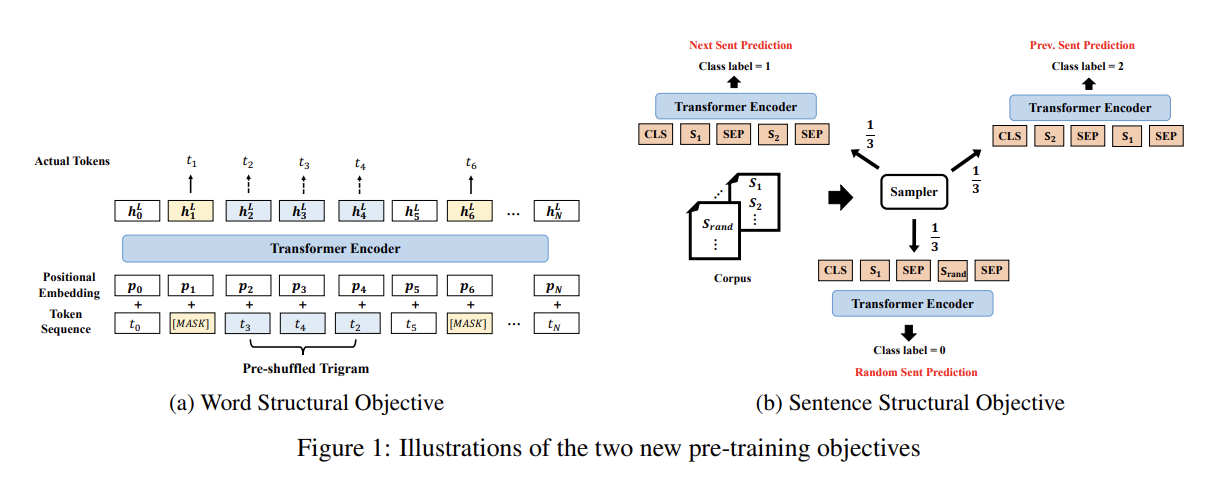
오늘 리뷰할 논문은 StructBERT 논문이다. StructBERT는 BERT가 문장과 단어의 순서를 이해하도록 확장한 모델이다.논문은 Elman 8의 linearization exploration work에서 영감을 받아 language structures를 pre
71.XLNet: Generalized Autoregressive Pretraining for Language Understanding
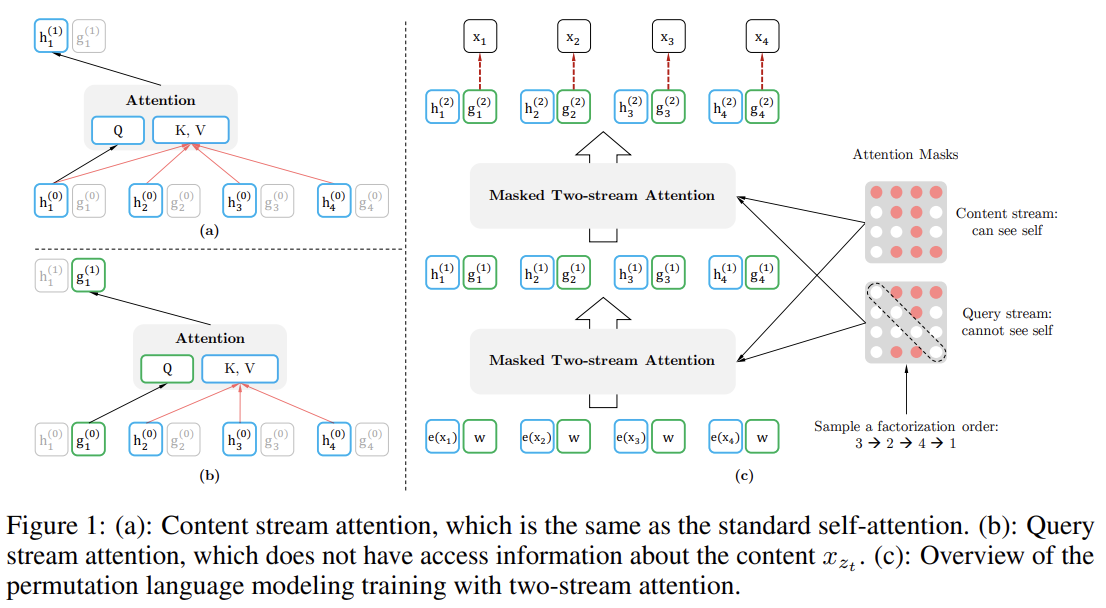
오늘 리뷰할 논문은 XLNet 논문이다.BERT처럼 bidirectional context를 modeling하는 denoising autoencoding based pretraining은 autoregressive language modeling 방식보다 더 잘 작동하
72.ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS
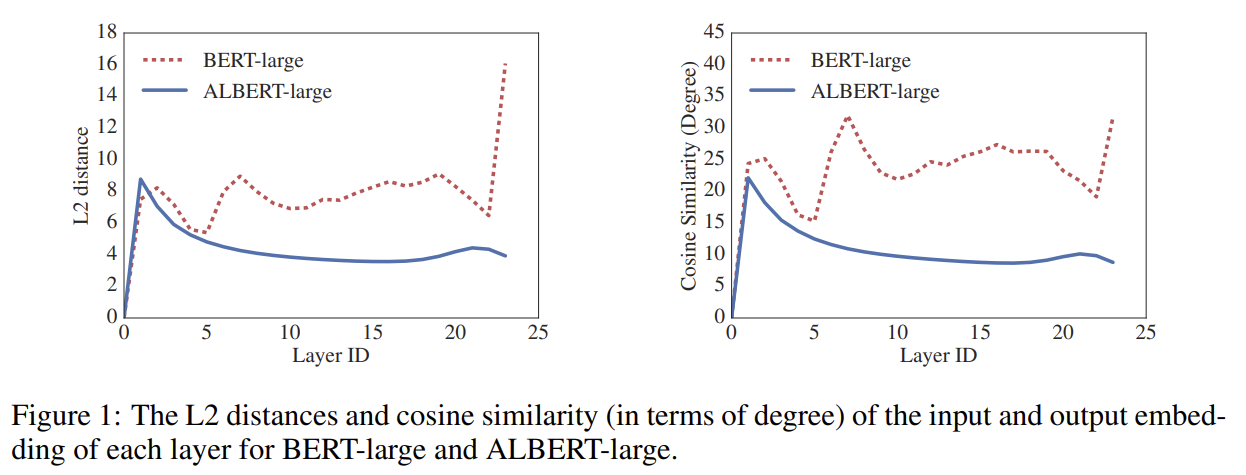
오늘 리뷰할 논문은 ALBERT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.nlp ALBERT 논문 정리(논문 리뷰) - A Lite BERT for Self-supervised Learning of Language Representations\[논문리뷰] A
73.ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
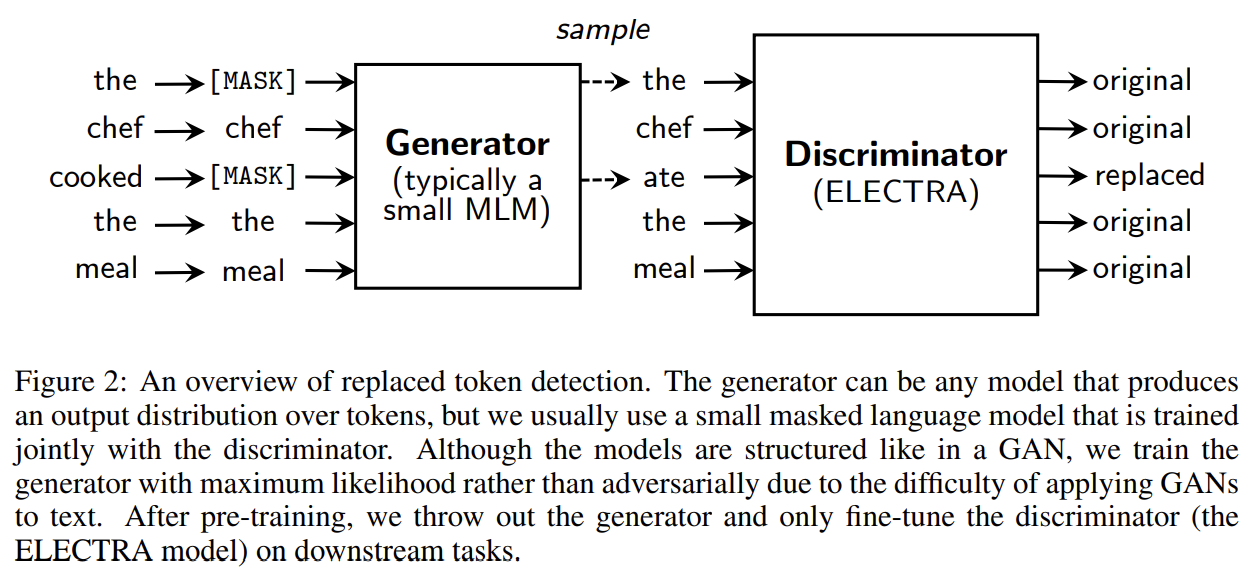
오늘 리뷰할 논문은 Efficiently Learning an Encoder that Classifies Token Replacements Accurately, ELECTRA 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문리뷰] ELECTRA: Pre-tr
74.DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION
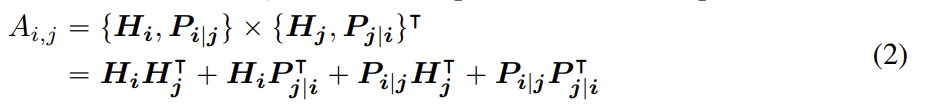
오늘 리뷰할 논문은 마이크로소프트에서 낸 DeBERTa 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.DeBERTa 논문 리뷰DeBERTa(Decoding-enhanced BERT with disentangled attention) 논문 리뷰논문은 두 새로운 기술
75.Reducing the Dimensionality of Data with Neural Networks
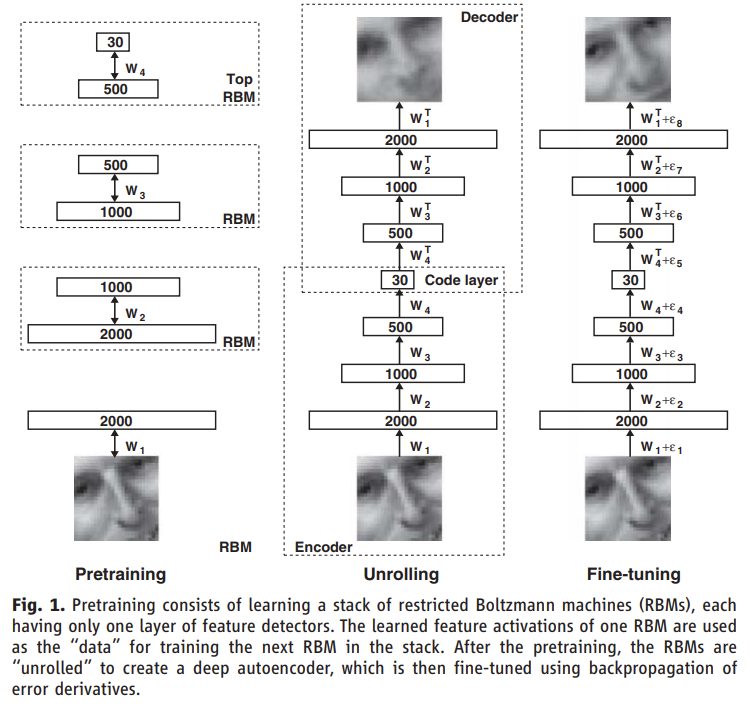
오늘 리뷰할 논문은 Autoencoder 논문이다. RBM과 DBN의 선행 연구라고 해서 읽어보게 되었다.아래 포스트를 먼저 보면 도움이 될 것이다.Restricted Boltzmann MachineReview — Autoencoder: Reducing the Dime
76.Neural Turing Machines
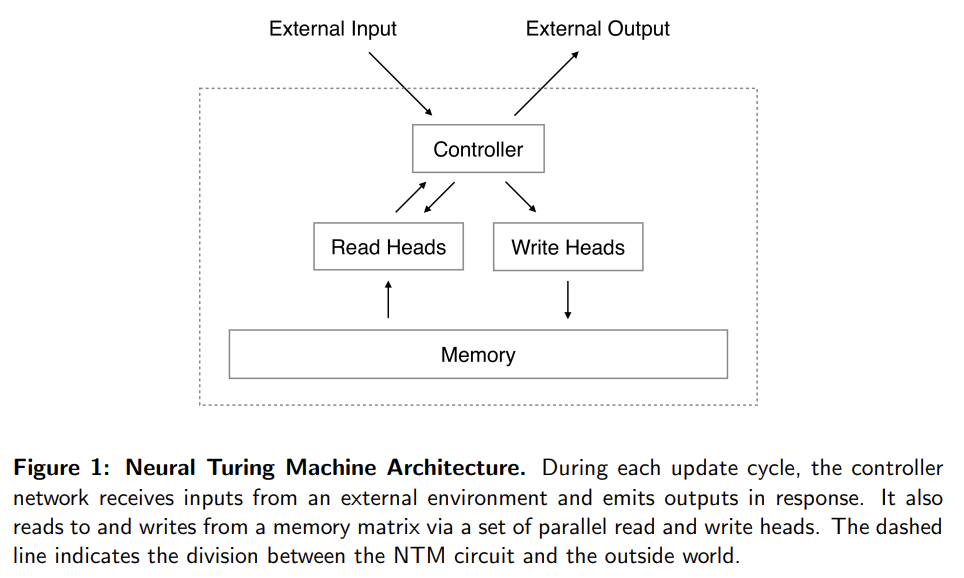
오늘 리뷰할 논문은 구글 딥마인드의 NTM 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.Neural Turing Machines 리뷰Neural Turing MachinesNTM(Neural-Turing-Machine) 코드 리뷰neural network에 ex
77.Hybrid computing using a neural network with dynamic external memory
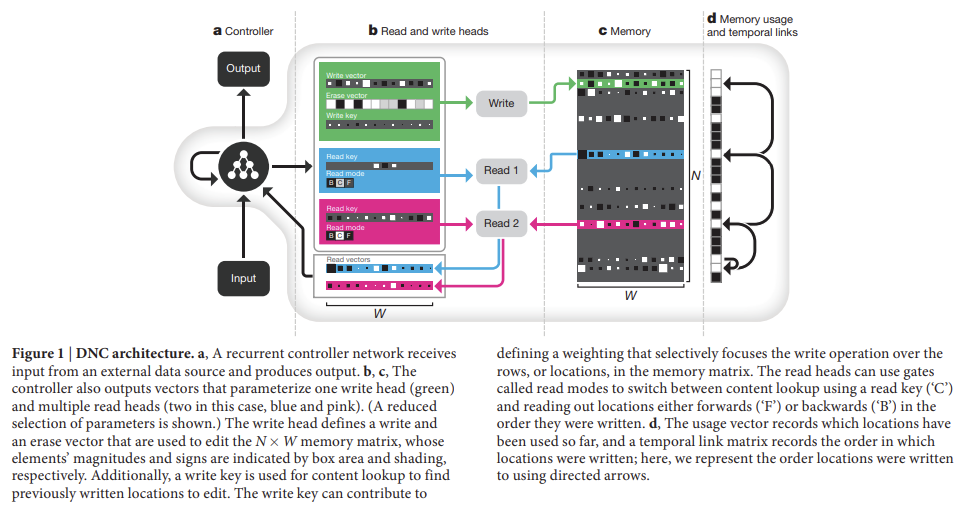
오늘 리뷰할 논문은 differentiable neural computer, DNC 논문이다.인공신경망은 외부 메모리가 없기 때문에 variables/data structures를 표현하거나 긴 시간동안 데이터를 저장할 능력이 부족하다. 논문은 컴퓨터의 random-a
78.Pixel Recurrent Neural Networks
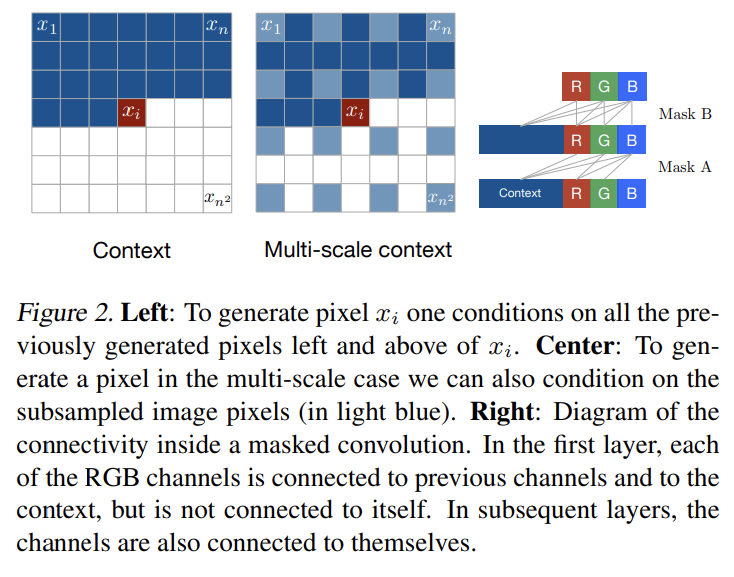
오늘 리뷰할 논문은 PixelCNN & PixelRNN 논문이다. 여러 논문에 몇 번 언급되서 궁금해서 잧아보게 되었다.아래 포스트를 먼저 보면 도움이 될 것이다.Pixel Recurrent Neural Network\[PR12-Video] 24. Pixel Recur
79.Conditional Image Generation with PixelCNN Decoders
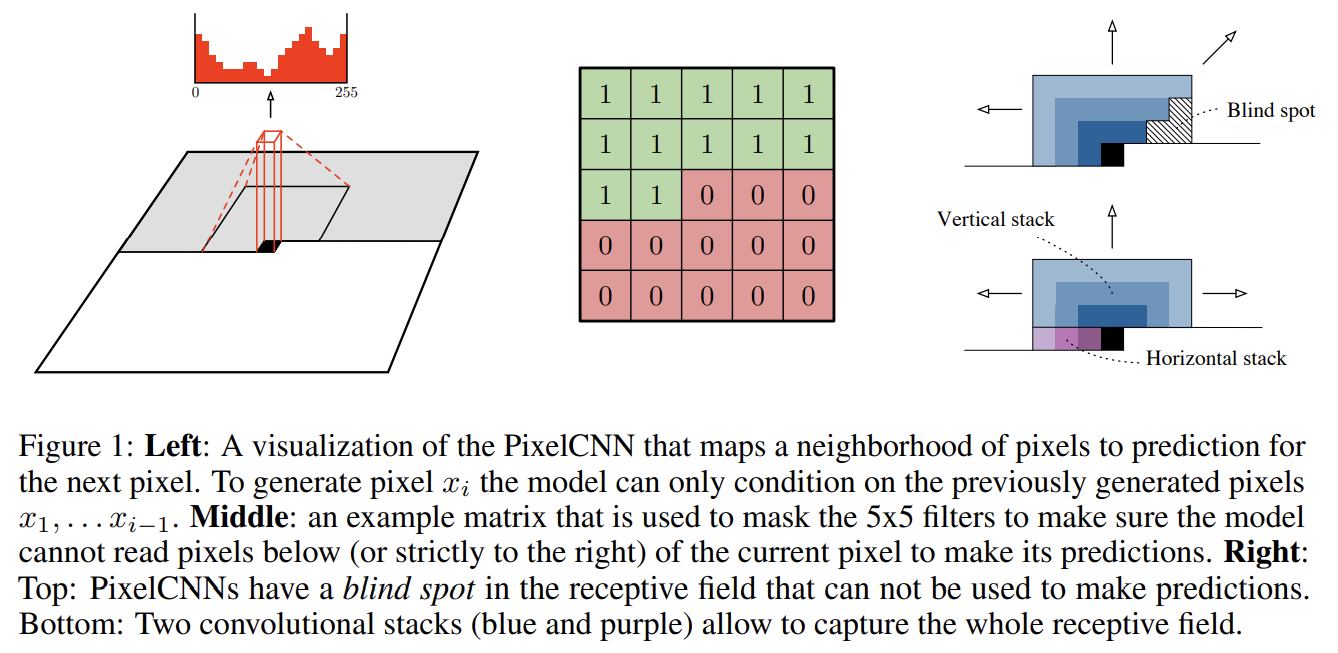
오늘 리뷰할 논문은 PixelRNN & PixelCNN의 후속 연구인 Gated PixelCNN & Conditional PixelCNN 논문이다.논문은 PixelCNN architecture에 기반한 새로운 image density model을 가지고 conditio
80.PIXELCNN++: IMPROVING THE PIXELCNN WITH DISCRETIZED LOGISTIC MIXTURE LIKELIHOOD AND OTHER MODIFICATIONS
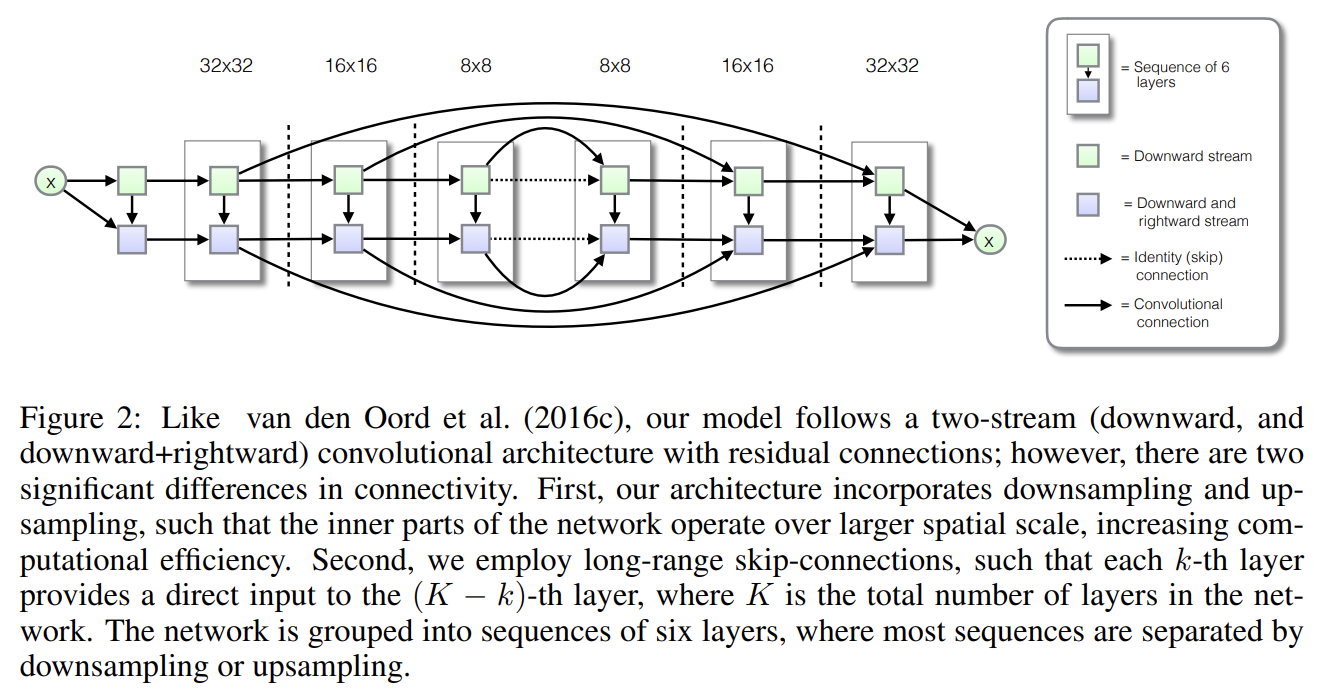
오늘의 논문 리뷰는 PixelCNN의 발전형인 PixelCNN++ 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문리뷰] Autogressive Generative Model \_ Pixel CNN++ & GLOW (Out Of Distribution(OO
81.VideoBERT: A Joint Model for Video and Language Representation Learning
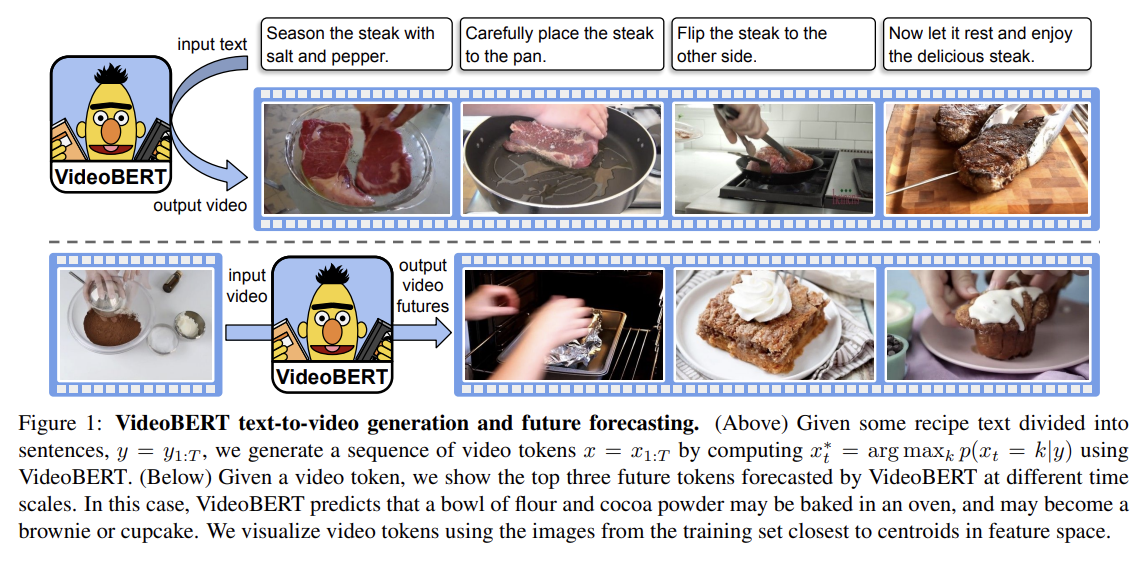
오늘 리뷰할 논문은 VideoBERT다.아래 포스트를 먼저 보면 도움이 될 것이다.VideoBERT - A Joint Model for Video and Language Representation Learning, CBT(Learning Video Representat
82.AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
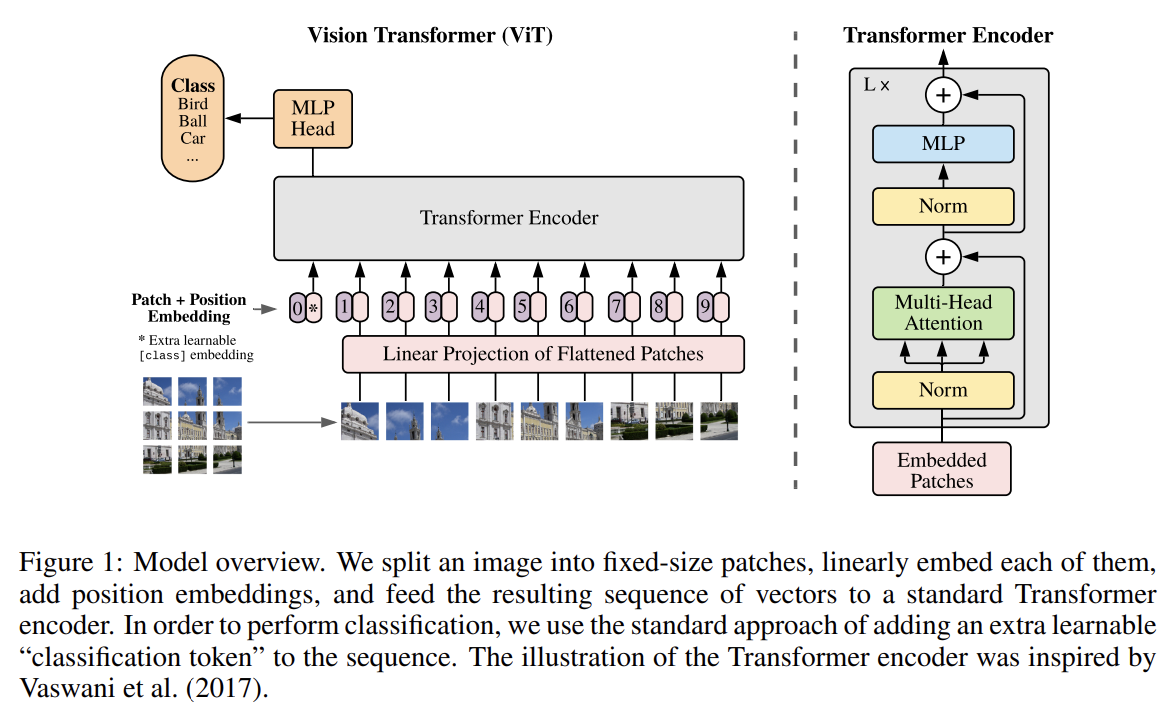
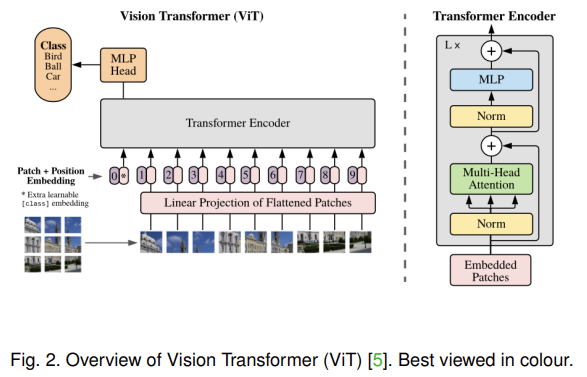
오늘 리뷰할 논문은 ViT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문리뷰]AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE : Vi-T(Vision Transforme
83.ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
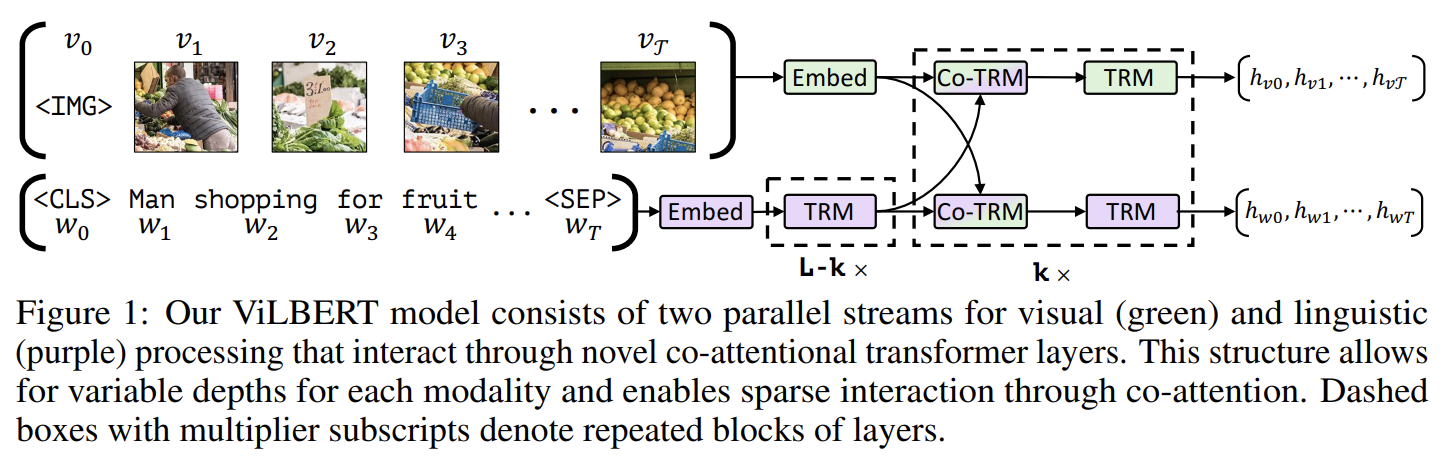
오늘 리뷰할 논문은 Vision-and-Language BERT, ViLBERT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[\[Multimodal \* ViLBERT & LXMERT논문은 image content와 natrual language의 task
84.FLAVA: A Foundational Language And Vision Alignment Model
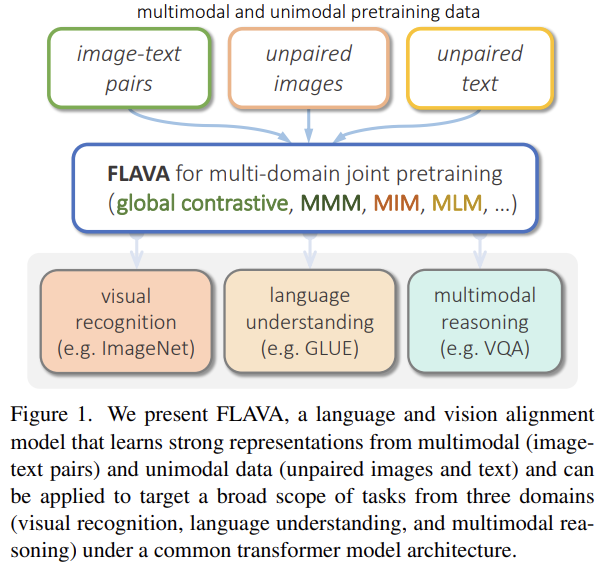
오늘 리뷰할 논문은 Facebook AI Research (FAIR)의 FLAVA 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.Facebook AI’s FLAVA Foundational Model Tackles Vision, Language, and Vision
85.ActBERT: Learning Global-Local Video-Text Representations
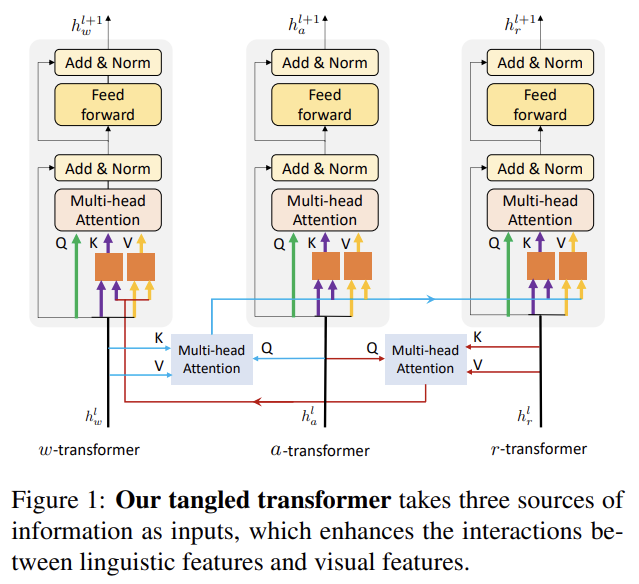
오늘 리뷰할 논문은 ActBERT 논문이다.문법적으로 이상한 문장이 좀 보이는데 아무래도 오타 같다.논문은 unlabeled data에서 joint video-text representations를 self-supervised learning으로 학습하는 ActBERT
86.Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
오늘 리뷰할 논문은 마이크로소프트의 Oscar 논문이다. 아래 포스트를 먼저 보면 도움이 될 것이다. Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks 논문 리뷰 [초 간단 논문리뷰| OSC
87.VISUALBERT: A SIMPLE AND PERFORMANT BASELINE FOR VISION AND LANGUAGE
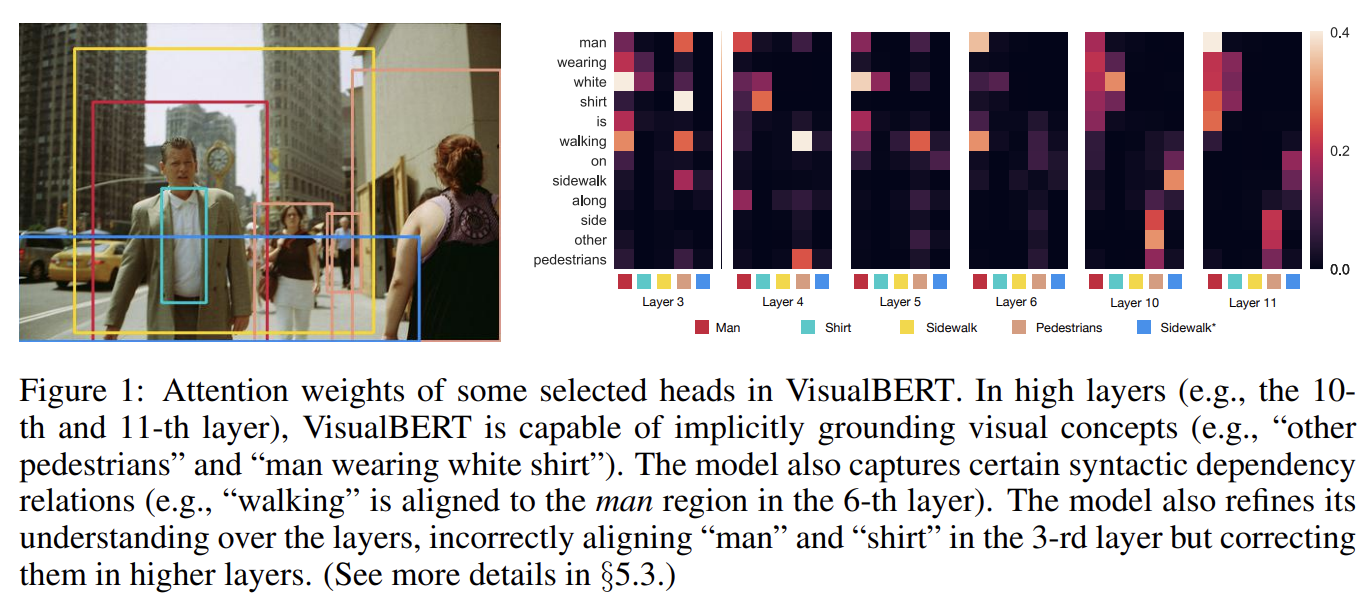
오늘 리뷰할 논문은 VisualBERT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.Review — VisualBERT: A Simple and Performant Baseline for Vision and LanguageVisualBERT는 self-atten
88.UNITER: UNiversal Image-TExt Representation Learning
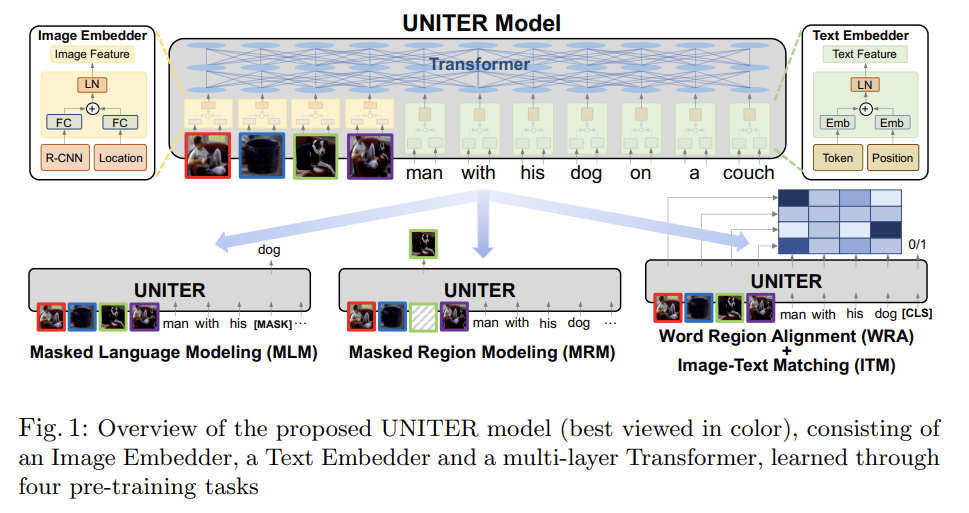
오늘 리뷰할 논문은 마이크로소프트의 UNITER다.사실 이틀 전에 이미 리뷰를 썼는데 억까 당해서 날아가버려서 다시 쓴다 ㅅㅂ각 benchmark의 기존 SOTA 모델은 architecture이 다양하고 learned representations이 몹시 task-spe
89.LXMERT: Learning Cross-Modality Encoder Representations from Transformers
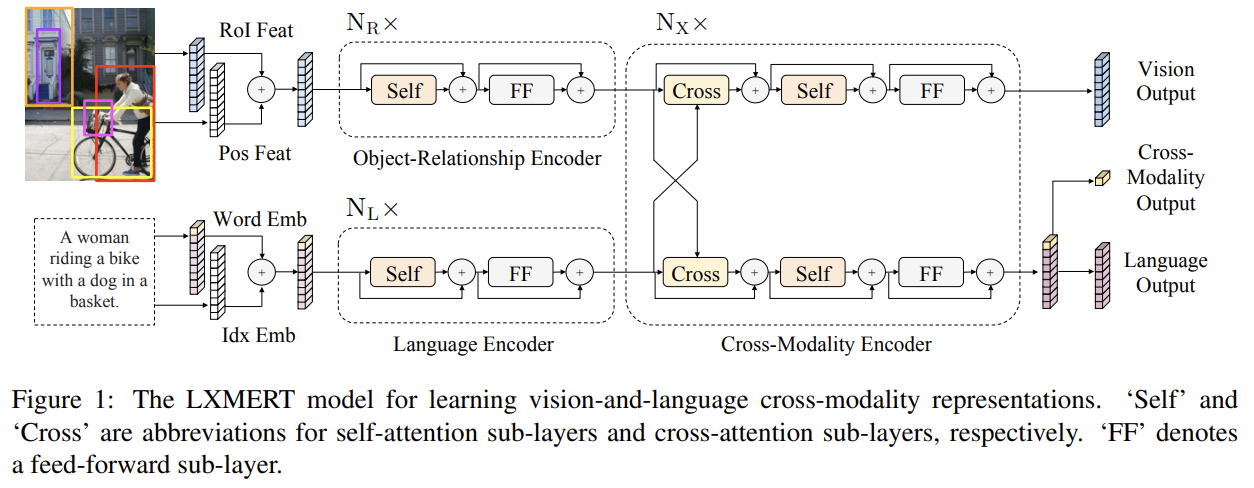
오늘 리뷰할 논문은 LXMERT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.LXMERT ReviewViLBERT & LXMERTLXMERT: Learning Cross-Modality Encoder Representations from Transformersv
90.VL-BERT: PRE-TRAINING OF GENERIC VISUALLINGUISTIC REPRESENTATIONS
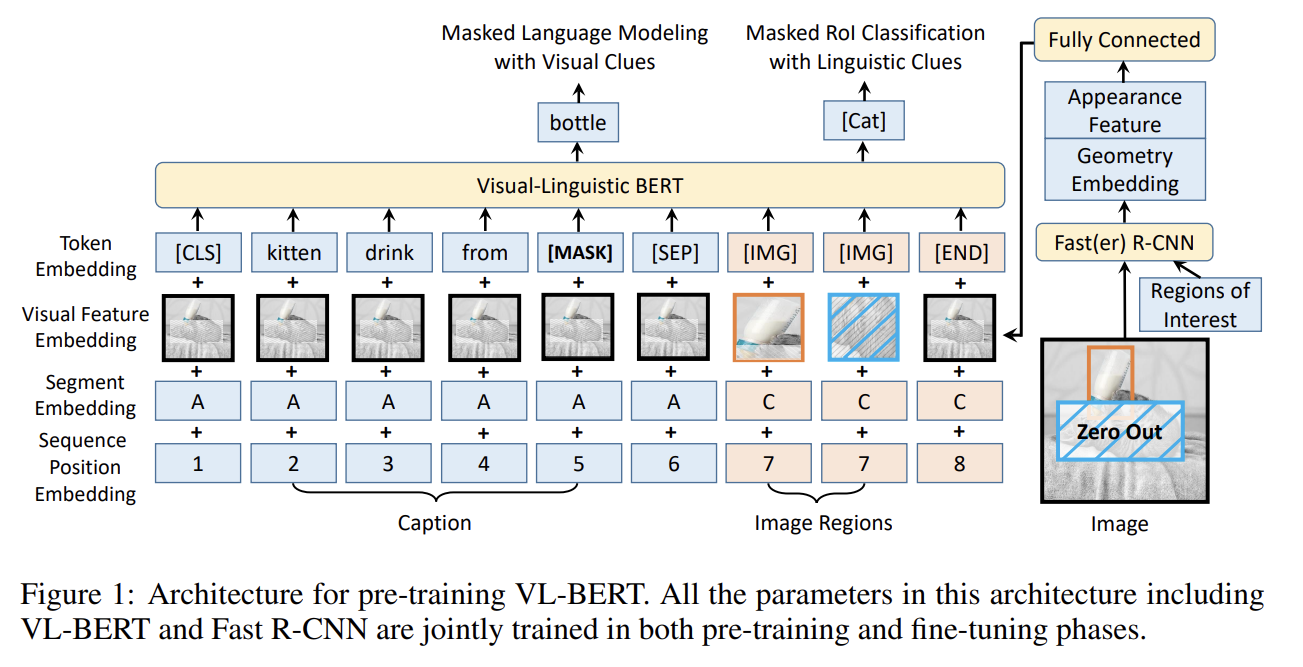
오늘 리뷰할 논문은 마이크로소프트의 VL-BERT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.VL-BERT:Visual-Linguistic BERT \[Kor]VL-BERT, ViL-BERT 논문 설명(VL-BERT - Pre-training of Generi
91.MDETR - Modulated Detection for End-to-End Multi-Modal Understanding

오늘 리뷰할 논문은 Facebook의 MDETR 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문리뷰] MDETR - Modulated Detection for End-to-End Multi-Modal UnderstandingMulti-modal reason
92.End-to-End Object Detection with Transformers
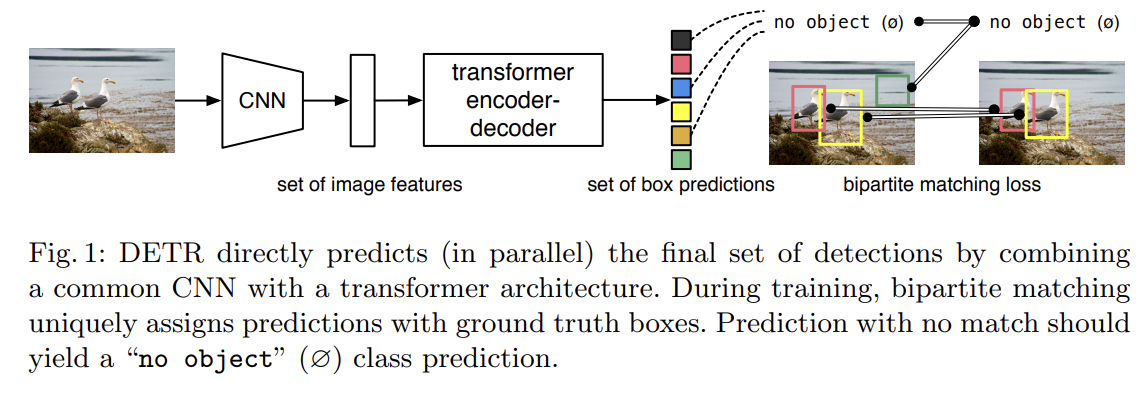
오늘 리뷰할 논문은 Facebook의 DETR 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.DETR 논문(End-to-End Object Detection with Transformers) 리뷰object detection을 direct set predictio
93.BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
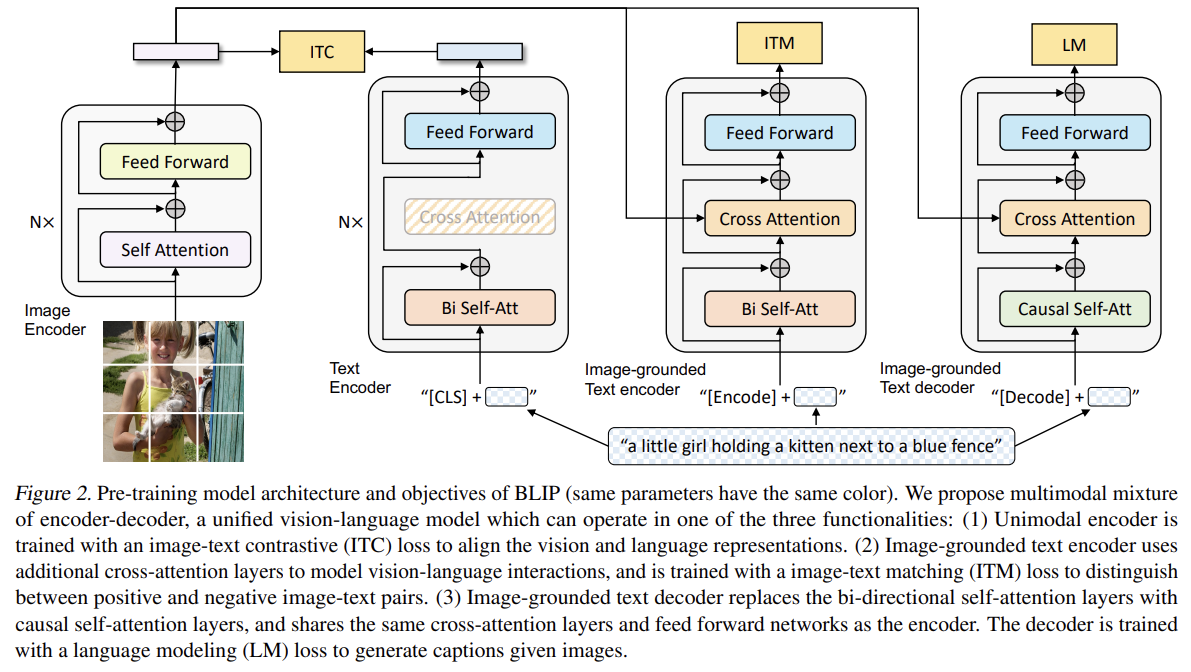
오늘 리뷰할 논문은 BLIP 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.📹빠르게 보는 BLIP 논문 리뷰📹Bootstrapping Language-Image Pre-training(BLIP, BLIP2) 논문 리뷰\[Paper Review] BLIP: Bo
94.Deep contextualized word representations
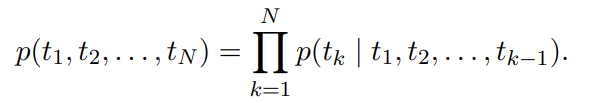
오늘 리뷰할 논문은 ELMo 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문 리뷰] Deep contextualized word representations\[논문리뷰] ELMo(Deep contextualized word representations)의
95.Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering

오늘 리뷰할 논문은 BUTD 논문이다.fine-grained analysis와 심지어 multiple steps of reasoning을 통해 깊은 이미지 이해를 가능하게 하고자 image captioning과 visual question answering (VQA)
96.Cross-lingual Language Model Pretraining
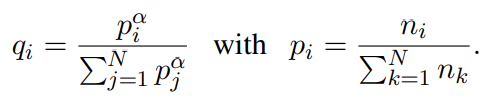
오늘 리뷰할 논문은 XLM 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.XML, Cross-lingual Language Model Pretraining 리뷰Cross-lingual Language Model Pre-training최근 연구들은 English n
97.YOLO9000: Better, Faster, Stronger
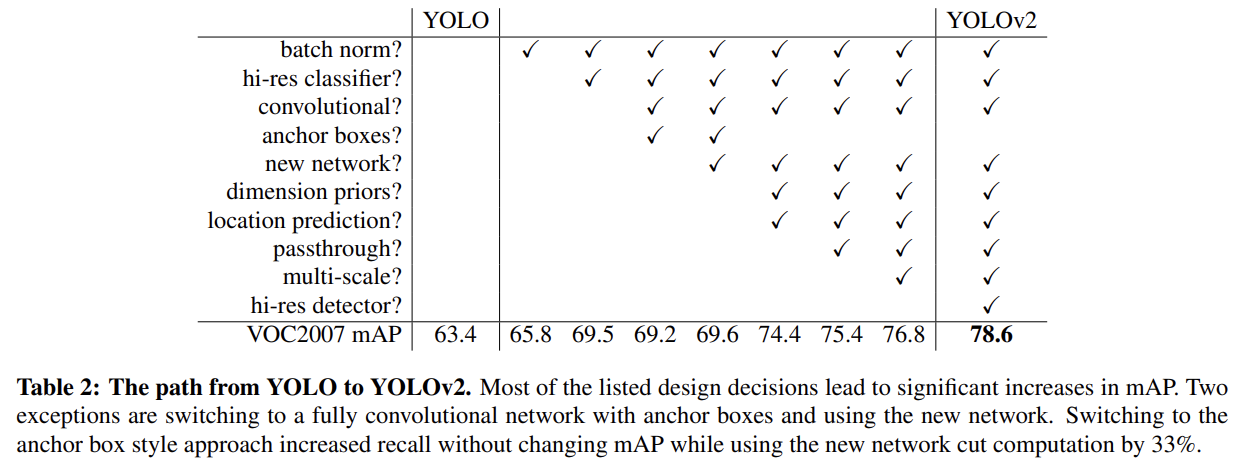
오늘 리뷰할 논문은 YOLOv2 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[YOLOv2 리뷰] YOLO9000: Better, Faster, Stronger (CVPR 17)YOLO v2 논문(YOLO9000:Better, Faster, Stronger)
98.YOLOv3: An Incremental Improvement
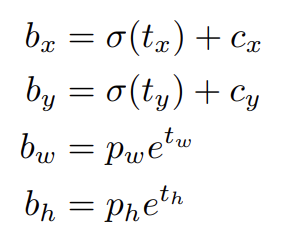
오늘 리뷰할 논문은 YOLOv3 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.YOLO v3 논문(YOLOv3: An Incremental Improvement) 리뷰YOLOv3 : An Incremental Improvement 리뷰논문은 YOLO를 발전시켰다.
99.YOLOv4: Optimal Speed and Accuracy of Object Detection
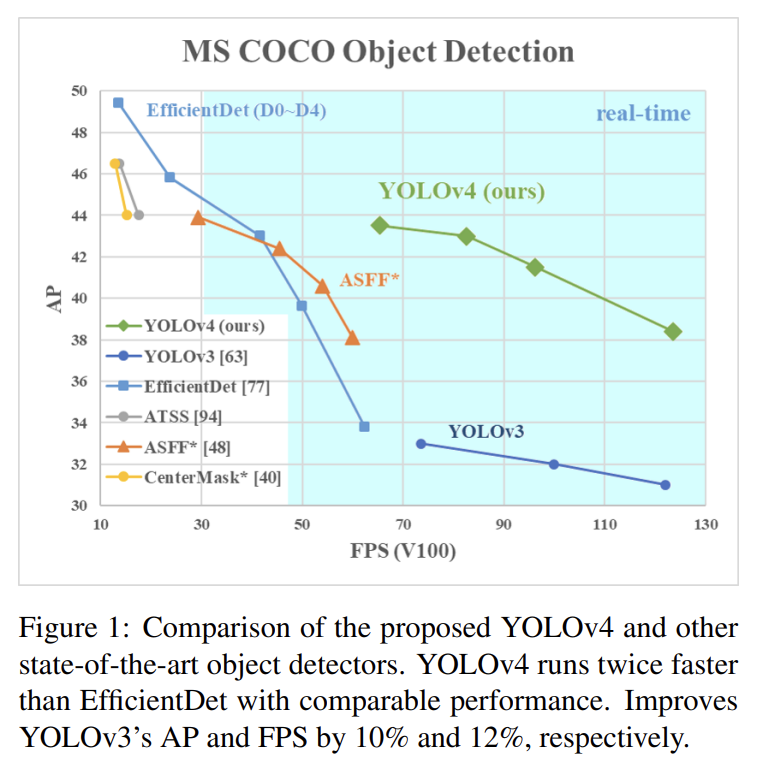
오늘 리뷰할 논문은 YOLOv4 논문이다.다음 포스트를 먼저 보면 도움이 될 것이다.YOLO v4 논문(YOLOv4: Optimal Speed and Accuracy of Object Detection) 리뷰YOLOv4:Optimal Speed and Accuracy
100.Universal Language Model Fine-tuning for Text Classification
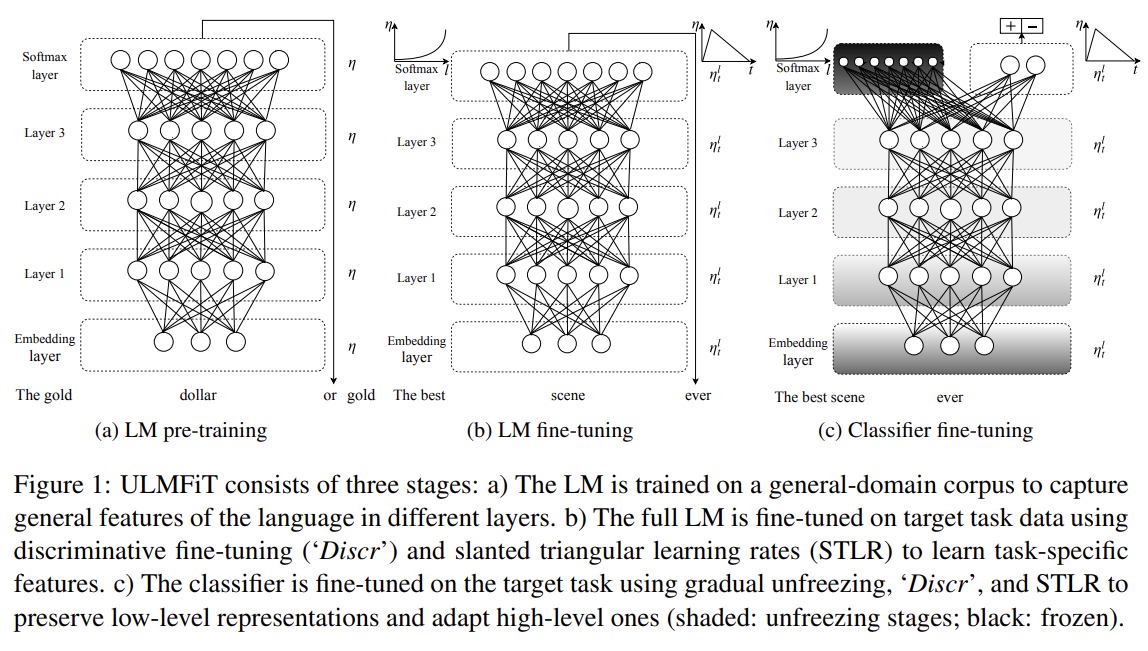
오늘 리뷰할 논문은 ULMFiT 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문리뷰] Universal Language Model Fine-tuning for Text Classification (2018)논문 요약: Universal Language Mo
101.Focal Loss for Dense Object Detection
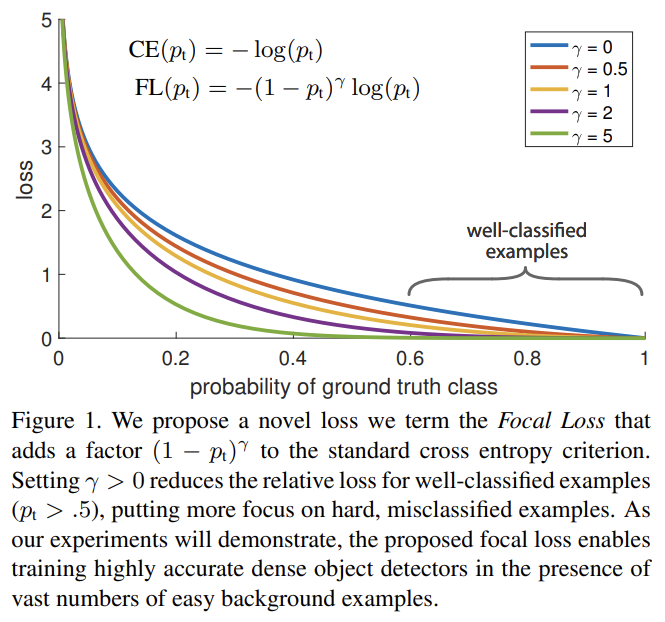
오늘 리뷰할 논문은 Facebook의 RetinaNet 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.Focal Loss for Dense Object Detection 리뷰\[논문리뷰] RetinaNet: Focal Loss for Dense Object Det
102.Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
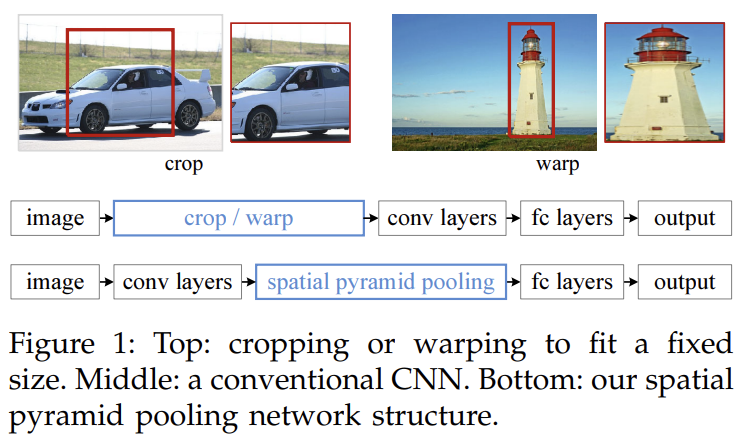
오늘 리뷰할 논문은 SPPNet 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문 리뷰] SPPNet(2014) 설명 (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
103.Fully Convolutional Networks for Semantic Segmentation
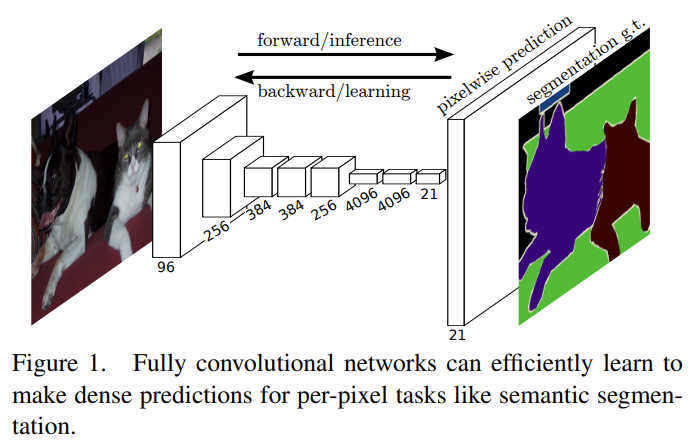
오늘 리뷰할 논문은 FCN 논문이다.근데 논문이 옛날 논문이기도 하고 좀 중구난방인 느낌이라 다른 사람들이 정리한 포스트를 보는 게 더 도움이 됐다. 이번 논문 리뷰는 대충 썼다.아래 포스트를 먼저 보면 도움이 될 것이다.\[논문 리뷰] FCN: Fully Convol
104.SEMANTIC IMAGE SEGMENTATION WITH DEEP CONVOLUTIONAL NETS AND FULLY CONNECTED CRFS
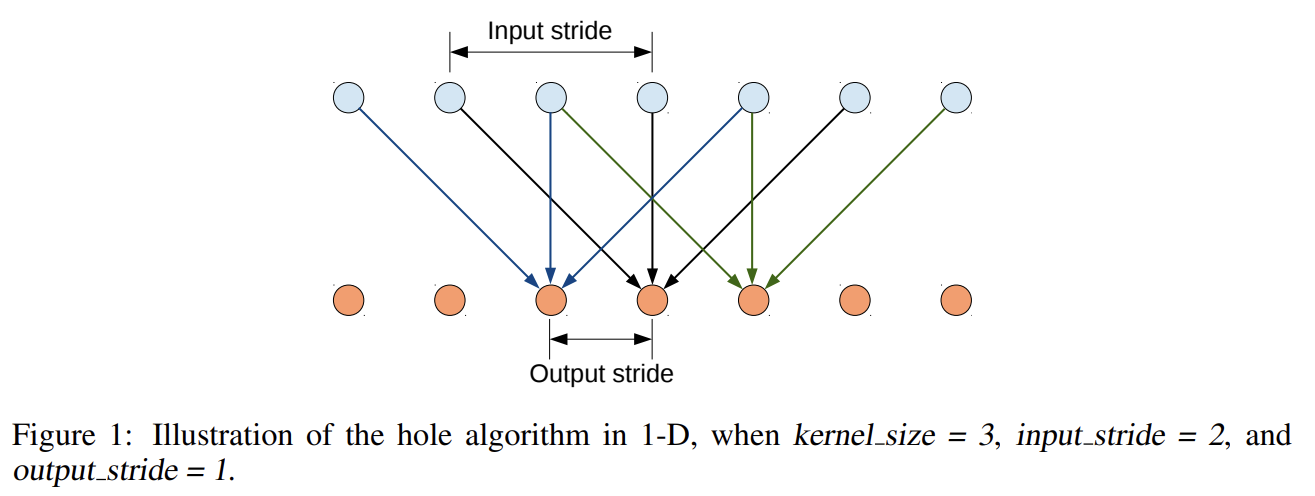
오늘 리뷰할 논문은 DeepLabV1 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.(Deeplab v1) Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully
105.Distilling the Knowledge in a Neural Network

오늘 리뷰할 논문은 최초의 knowledge distillation 논문이다.아래 포스트를 먼저 보면 도움이 될 것이다.Distilling the Knowledge in a Neural Network 논문 리뷰\[논문 리뷰] Distilling the Knowledge
106.VLP: A Survey on Vision-Language Pre-training
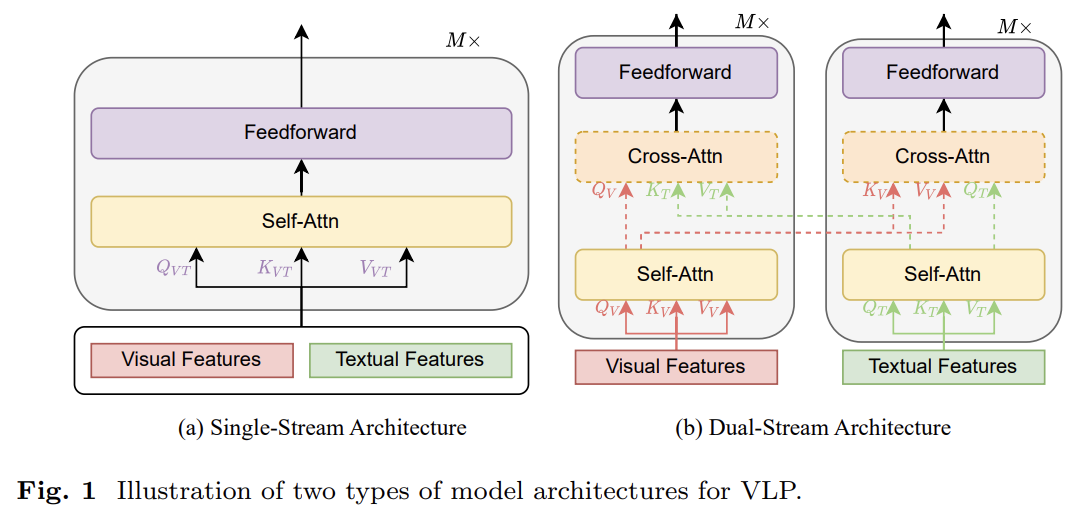
오늘 리뷰할 논문은 VLP survey 논문이다.포스트는 논문 요약/정리보다는 내 마음대로 메모하는 식이다.논문은 5가지 측면 feature extraction, model architecture, pre-training objectives, pre-training d
107.읽은 리뷰
논문 리뷰 읽은 것 정리용 [논문 리뷰] Finetuned Language Models Are Zero-Shot Learners (인용 3326) [논문 리뷰] InstructGPT: Training language models to follow instruction
108.LM2: Large Memory Models
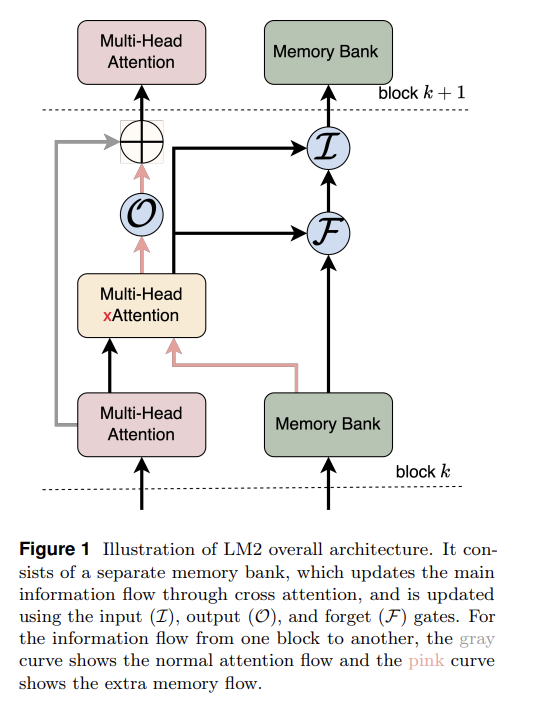
메모용모양 재미있고 좋은데 memory bank가 순전히 input에만 반응하니 불완전하지 않나?외부 감각만 기억하는게 아니라 내 '생각', 즉 내적 청각에도 cross attention해서 기억해야하지 않나?그럼 '생각' 후 forget/input gate를 한번 더
109.Chain of Draft: Thinking Faster by Writing Less

이전에 흥미롭게 읽은 Training large language models to reason in a continuous latent space 논문이 언급된다.Hao et al. (2024) proposes Coconut to trainLLMs to perform
110.A-MEM: Agentic Memory for LLM Agents 비판
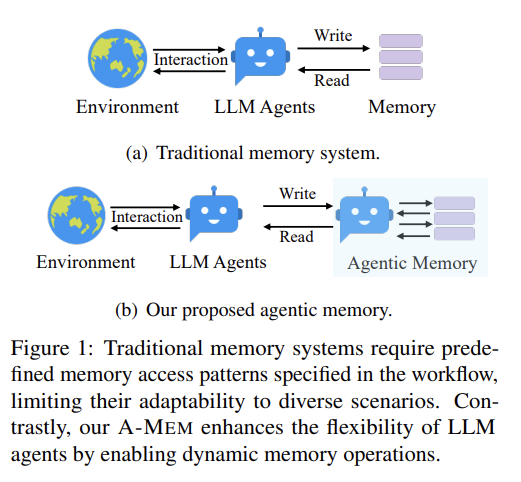
논문 아이디어에 여러모로 지적할 점이 많은데... 메모 겸 정리해보겠다.agent를 2개 뒀길래 해마인줄 알았더니 아니었다.note 만드는 것부터 naive하다. timestamp, keywords, tags 등등이 명시적으로 저장된다. 그리고 결국 RAG의 docum
111.Augmenting Language Models with Long-Term Memory
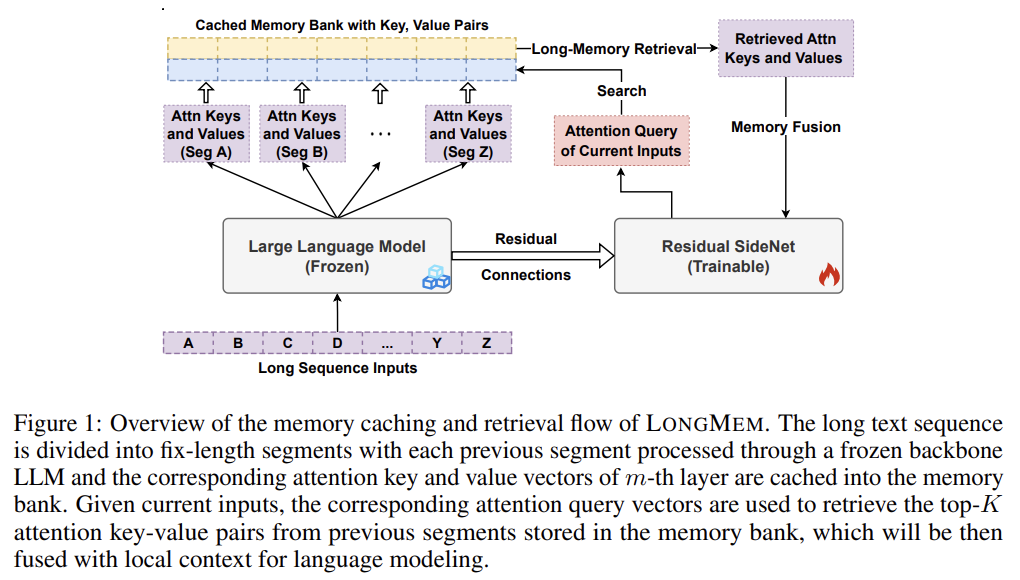
LongMem 모델.frozen backbone LLM, SideNet, and Cache Memory Bank 3개 구조로 이루어짐.frozen LLM 처리하면서 최근 M개 input의 각 LLM layer에서 K, V 값을 bank에 저장. retrieval and
112.Language Models Represent Beliefs of Self and Others 메모

아이디어, 내 감상 메모용위와 같은 BigToM dataset을 사용한다. Mistral-7B-Instruct라는 SOTA instruction fine-tuned autoregressive language model을 학습.각 head, layer마다 선형 probe
113.MemInsight: Autonomous Memory Augmentation for LLM Agents 메모
Related Work 기존 메모리 저장 방식 summaries and abstract high-level information from raw observations to capture key points and reduce information redundanc
114.Conditional [MASK] Discrete Diffusion Language Model
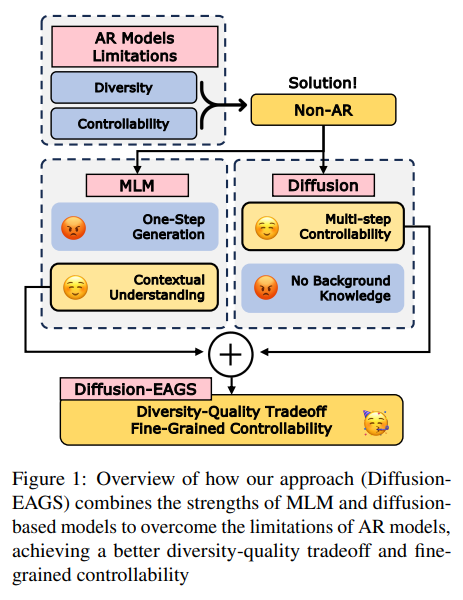
Overviewconditional masked language models를 diffusion language model로 통합한 Diffusion-EAGS 제안.entropy-adaptive Gibbs sampling, entropy based noise sched
115.Generating Diverse Hypotheses for Inductive Reasoning
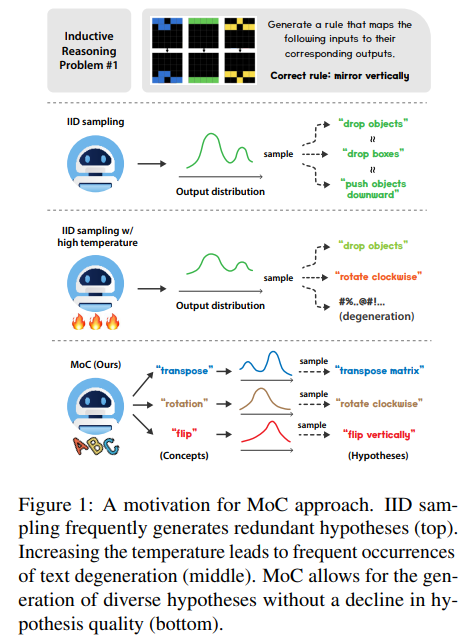
적은 수의 observations에서 일반적인 rule을 추론하는 inductive reasoning에서 여러 hypothesis를 sampling해 가장 좋은 것을 선택하는 방식이 있다. 그러나 IID sampling으로 인해 hypothesis가 redundant하
116.Learning vs Retrieval: The Role of In-Context Examples in Regression with Large Language Models

LLM의 in-context learning (ICL) 원리에 대한 연구 결과가 항상 일관적이지는 않다. 논문은 ICL mechanisms을 평가할 framework를 제안하며 ICL이 retrieving internal knowledge와 learning from i
117.Large Concept Models: Language Modeling in a Sentence Representation Space
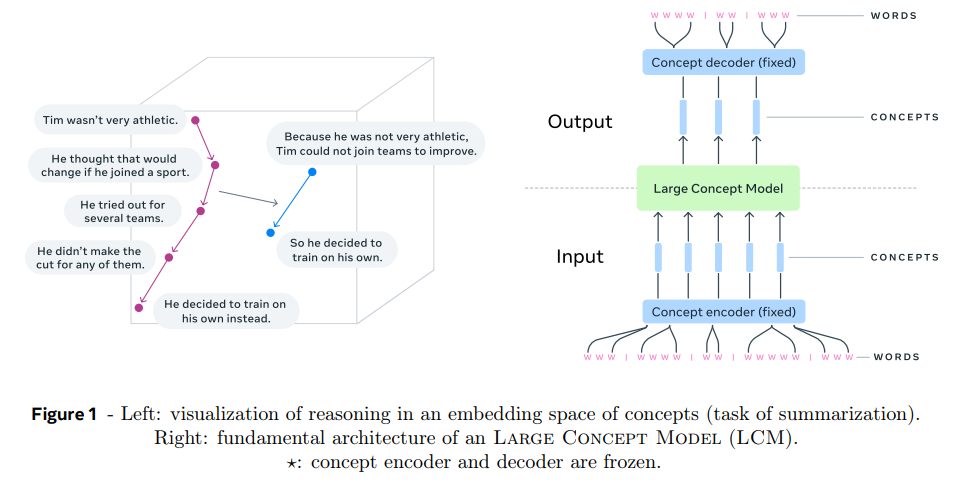
이번 논문은 meta의 Large Concept Models (LCM) 논문이다. LLM을 대체할지도 모르는 모델이라는 소리까지 들어서 회의적인 시각으로 읽기 시작했는데 어느 정도 그럴듯하다고 느꼈다.LLM은 token level에서 처리하지만 이는 다양한 수준의 추상
118.SONAR: Sentence-Level Multimodal and Language-Agnostic Representations
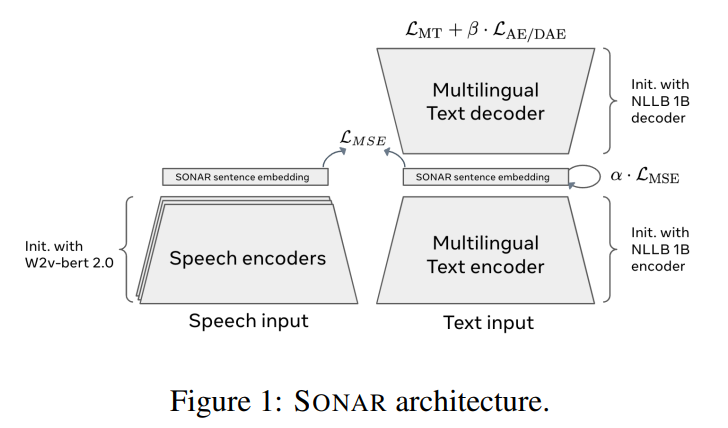
이번 논문은 meta의 SONAR 논문으로, 직전에 리뷰한 LCM의 이전 연구이다. LCM 기능에 SONAR이 핵심적인 듯해서 더 자세히 알아보려고 읽게 되었다.SONAR는 multilingual, multimodal fixed-size sentence embeddin
119.Large Language Diffusion Models
읽다가 너무 별로라서 중단한 논문이다.Auto Regressive 방법 대신 Transformer에 Masked Language Modeling을 사용해 Diffusion 하려는 시도.8B 모델을 만들어서 LLaMA3 8B와 경쟁적인 성능.그런데 방법이 너무 간단하고,
120.Human-like Few-Shot Learning via Bayesian Reasoning over Natural Language
2023/6, NeurIPS 논문이다.https://docs.google.com/presentation/d/e/2PACX-1vSIk5Qa9-\_ED50pd6NNtwlA-NDlaBpWh_PKLEbrow2GDtDlxrvSeXEEfH8LG-6kRfwPXmRRhmXF
121.Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking
2024/3, COLM 논문이다.https://docs.google.com/presentation/d/e/2PACX-1vQm83FevJ2HI5I9SnJ2cs1025kf4UcD1C6eRBzk6wpMrbrh2nSlW6zzC0zAEoJvDT--O8nQxqoI5GdP
122.Training Large Language Models to Reason in a Continuous Latent Space
2024/12, Meta의 Coconut 논문이다. 기대보다는 실망스럽다. 성능은 task에 유리하게 과장된 측면이 있다.https://docs.google.com/presentation/d/e/2PACX-1vSMdtkLWJ0NwCvc9eq1oJAXOUg-4U
123.From Tokens to Thoughts: How LLMs and Humans Trade Compression for Meaning
2025/5 논문이다. 그 유명한 Yann LeCun 교수님이 공저자로 있는 논문인데 굉장히 구리다.https://docs.google.com/presentation/d/e/2PACX-1vSYDNNJwprgdf8wRa9Wl8VId9Xl-bodhrgjC9KMbz
124.OMNI-EPIC: Open-endedness via Models of human Notions of Interestingness with Environments Programmed in Code
2024년 5월, ICLR 2025 논문이다.https://docs.google.com/presentation/d/e/2PACX-1vQ8TpK-uUgqAgY9Zt1BJ5hC4uCLsYrLixAYA7yQ8_4uszAj6rSOA3iiMu3EsalATbOi8MAN1
125.Reasoning by Superposition: A Theoretical Perspective on Chain of Continuous Thought
2025/5 논문이다. 이전에 읽은 Meta의 Coconut 논문을 연구한 논문이다. 이 논문이 Coconut 논문보다 나은 것 같다. superposition 관점이 재밌다.https://docs.google.com/presentation/d/e/2PACX-