오늘 리뷰할 논문은 transformer를 도입한 유명한 논문이다(attention 자체는 이전에도 많이 쓰이고 있었다).
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- 16-01 트랜스포머(Transformer)
- [논문리뷰] Attention is All you need
- [논문 리뷰] Transformer 논문 리뷰 (Attention Is All You Need)
- Attention Is All You Need, NIPS 2017 - Transformer 논문 리뷰
논문은 NLP에서 자주 사용되는 RNN, LSTM 등의 recurrent model들이 순차적으로 input을 처리하기 때문에 training examples의 parallelization이 불가능하다고 지적한다. 한편 attention은 input과 output sequences의 distance에 상관없이 dependency를 modeling하여 강력한 성능을 보인다.
기존의 논문들은 attention을 recurrent network와 결합하여 사용했지만, 이 논문은 recurrence 없이 (그리고 convolution도 없이) 오직 attention으로만 이루어진 Transformer이라는 model architecture을 제안해 input과 output 간의 global dependencies를 이끌어내고자 한다. Transformer은 더 많은 parallelization를 허용하며 translation quality도 SOTA 성능을 보인다.
self-attention(=intra-attention)은 sequence의 representation을 계산하기 위해 single sequence에서 different positions를 연관시키는 attention mechanism이다. Transformer은 (sequencealigned RNNs이나 convolution 없이) 전적으로 self-attention에만 의존하는 최초의 transduction model이다.
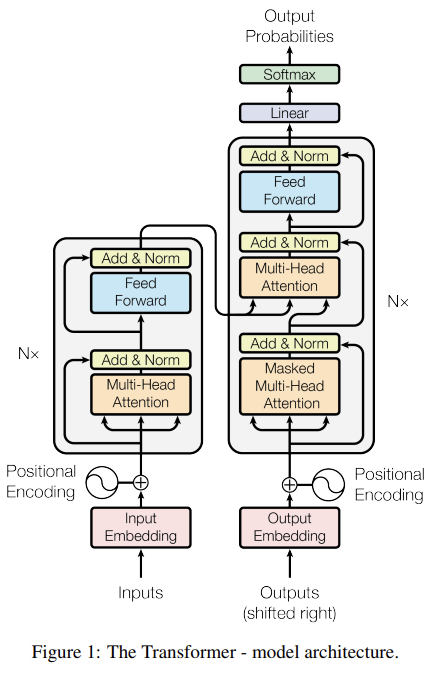
Fig 1에서 볼 수 있듯이 Transformer은 encoder(왼쪽)과 decoder(오른쪽)로 구성된다. encoder와 decoder은 stacked self-attention과 point-wise, fully connected layers로 이루어진다.
encoder은 N(=6)개의 동일한 layer의 stack으로 이루어진다. 각 층은 2개의 sub-layer, 즉 multi-head self-attention mechanism과 simple, position-wise fully connected feed-forward network을 가진다. 각 sub-layer 주위로 residual connection이 있고 layer normalization가 뒤따른다.
decoder도 N(=6)개의 동일한 layer의 stack으로 구성되며 3개의 sub-layer을 가진다. encoder과 같은 2개 sub-layer에 추가로 encoder stack의 output에 대해 multi-head attention을 수행하는 층이 있다. encoder처럼 각 sub-layer마다 residual connection과 layer normalization이 존재한다. 또 decoder의 self-attention sub-layer(첫번째 sub-layer)은 encoder과 조금 다른데 position들이 subsequent positions에 attending하는 것을 막기 위해 masking을 한다. 즉, (output embeddings가 offset by one position이라는 것과 함께) masking은 i번째 position에서의 prediction이 i보다 작은 positions에서의 known output에만 의존하게 한다.
attention function은 query와 set of key-value pairs를 output으로 mapping하는 것이다(query, keys, values, output은 모두 vector). output은 values의 weighted sum으로 계산되며 각 value의 weight은 상응하는 key를 가진 query에 대한 compatibility function으로 계산된다.
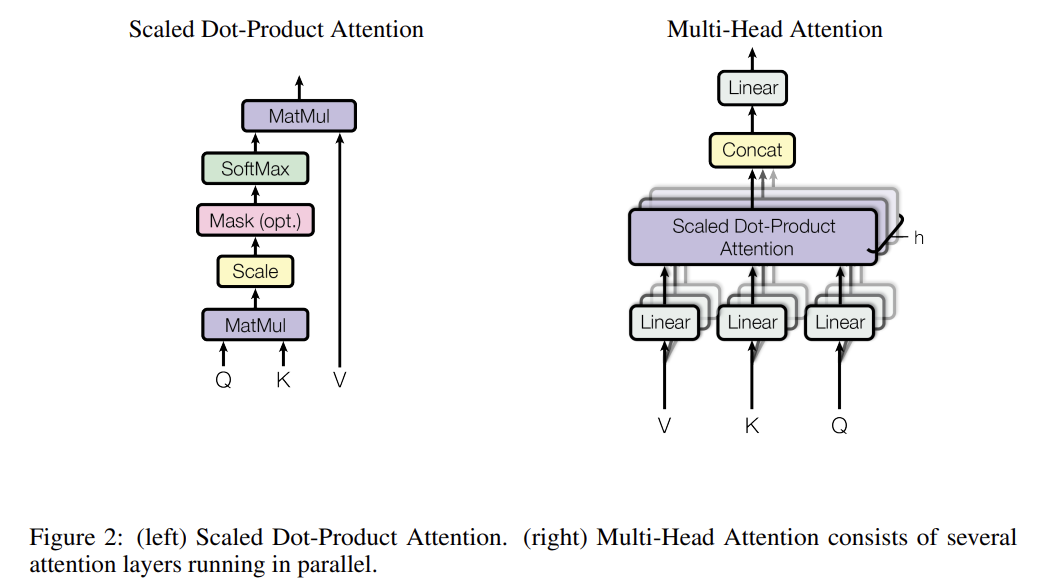
우선 scaled dot-product attention은 차원의 queries, keys와 차원의 values를 input으로 가진다. 그리고 각 value당 weight을 얻기 위해 query와 모든 key의 dot products을 구하고 각각을 으로 나눈 후 softmax function을 적용한다. 실제로는 queries를 matrix Q로, keys를 K로 values를 V로 묶어서 다음과 같이 동시에 계산한다.
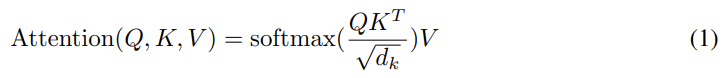
그런데 차원의 keys, values, queries를 하나의 attention function에 적용하는 것보다 이들을 h개의 서로 다른, learned linear projections에 linearly project하는 편이, 즉 multi-head attention이 더 성능이 좋다. (h개의) keys, values, queries의 projected versions을 parallel하게 attention function에 넣고 차원의 output을 concatenate하여 다시 project하여 최종 결과값을 산출한다.
multi-head attention은 모델이 서로 다른 position의 다른 representation subspaces에서 온 정보를 결합하여(jointly) attend할 수 있도록 한다.

이 논문에선 h=8, 이다. 각 head의 (input vector의) dimension을 reduce했기 때문에(즉 ) multi-head attention의 total computational cost은 full dimensionality를 가진 single-head attention과 비슷했다.
multi-head attention은 다음과 같이 3가지 방법으로 사용된다.

또 Fig 1에서 볼 수 있듯이 encoder와 decoder은 position-wise, fully connected feed-forward networks도 가진다. 중간에 ReLU가 낀 두 번의 linear transformation으로 계산하며 각 position에 separately하고 identically하게 적용된다. parameter도 N(=6)개의 layer마다 따로 학습된다.
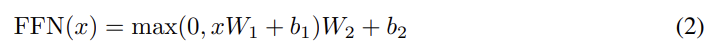
기존의 sequence transduction models처럼 input tokens와 output tokens을 차원의 vector로 전환하기 위해 learned embeddings을 사용했다. 또 decoder output을 predicted next-token probabilities으로 전환하기 위해 일반적인 learned linear transformation과 softmax function을 사용한다. 이 논문의 모델에선 2개의 embedding layers과 pre-softmax linear transformation이 같은 weight matrix을 공유한다. embedding layers에선 weights에 을 곱해준다.
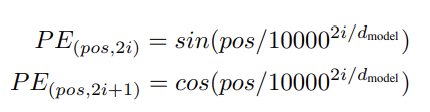
이 모델은 recurrence와 convolution이 없기 때문에 sequence의 순서를 유용하게 쓰기 위해선 sequence 내의 tokens의 relative/absolute position을 정보로 넣어줘야 한다. 그래서 encoder/decoder stack 밑바닥의 input embeddings에 차원의 "positional encodings"을 더해준다. positional encoding은 여러 선택지가 있는데 논문에선 위와 같이 사인, 코사인 함수를 사용했다.
(여기 잘 이해 못함)
pos는 position이고 i는 dimension(의 index인듯)이다. 즉 positional encoding의 각 dimension이 사인곡선에 대응된다. 이 함수를 채택한 이유는 어떤 고정된 offset k에 대해 가 의 linear function으로 표현될 수 있기에 모델이 쉽게 relative positions를 attend할 수 있다고 추측했기 때문이다.
논문은 self-attention을 사용하는 이유로 3가지를 댄다.
- layer 당 총 computational complexity
- (요구되는 sequential operation의 최소 개수로 측정되는) parallelized될 수 있는 연산량
- long-range dependencies 간 path length
학습은 WMT 2014 English-German dataset과 WMT 2014 English-French dataset을 사용했다. detail과 결과는 생략하겠다.
Strengths
- 기존의 encoder-decoder 구조를 차용하면서도 오직 attention만을 사용해 reccurence를 사용한 것보다 연산 부담이 적으면서 SOTA 성능을 달성했다.
내용과 architecture이 확실히 어려워서 이해도가 평소보다 낮은 것 같다. 다른 포스트도 읽어보고 논문도 다시 읽어보고 실습도 해보는 식으로 더 알아봐야 할 것 같다.
