오늘 리뷰할 논문은 BEGAN 논문이다. 논문 하나에 상당히 다양한 성과가 담겨서 인상적이었다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- BEGAN 논문 리뷰 - BEGAN Boundary Equilibrium Generative Adversarial Networks (arXiv2017)
- 초짜 대학원생의 입장에서 이해하는 BEGAN: Boundary Equilibrium Generative Adversarial Networks (1)
Summary
기존 GANs의 문제는 train이 어렵다는 것, hyper-parameter selection이 매우 중요하다는 것, generated samples의 image diversity를 조절하는 게 어렵다는 것 등이 있다. 또 generator와 discriminator의 convergence를 balancing하는 것도 어려운데, discriminator가 훈련 초기에 너무 쉽게 이기기 때문이다. GANs는 하나의 image만 학습하는 failure mode인 modal collapse 문제에 쉽게 시달린다.
논문의 기여는 다음과 같다.

논문은 EBGAN처럼 auto-encoder를 discriminator로 사용한다. 일반적인 GANs은 data distribution을 직접 match하려고 하지만 이 논문은 Wasserstein distance에서 기인한 loss를 사용해 auto-encoder loss distributions를 match하고자 한다. 이는 일반적인 GAN objective에 discriminator과 generator을 balance하기 위한 equilibrium term을 추가해 이루어진다. 이 방식은 training 과정이 더 쉽고 architecture이 간단하다는 장점이 있다.
samples의 distribution을 matching하는 대신 errors의 distribution을 matching하고자 논문은 먼저 auto-encoder loss를 소개하고 real과 generated samples의 auto-encoder loss distributions 사이 Wasserstein distance의 lower bound를 계산한다.
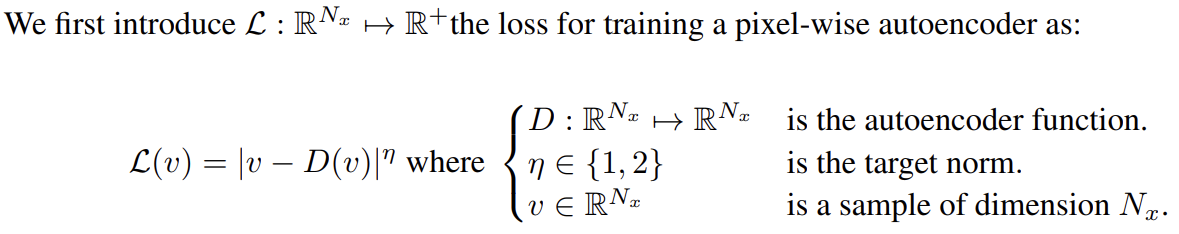
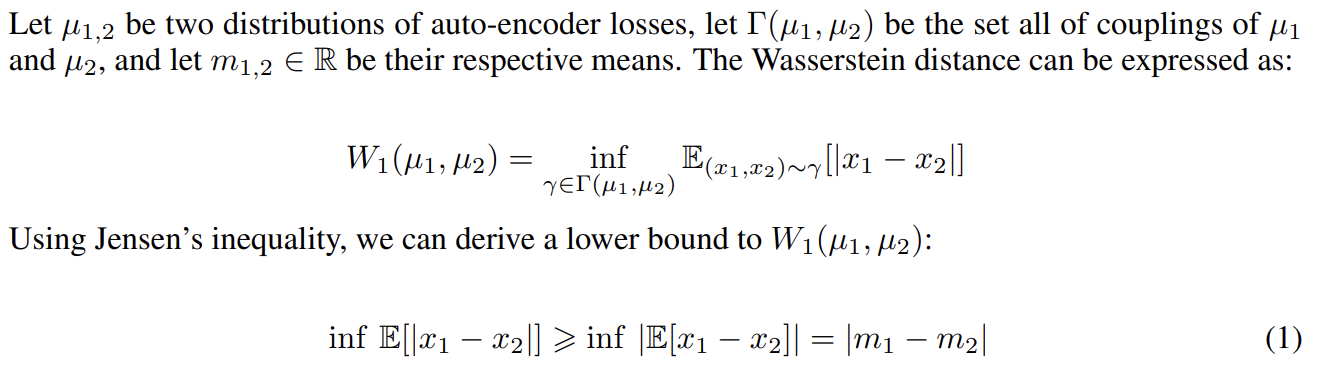
(수식을 타이핑하기 귀찮으므로 캡처 사진으로 대체한다)
이제 식 (1)을 최대화하는 discriminator을 디자인한다. 은 real samples x에 대한 loss L(x)의 distribution, 는 loss L(G(z))의 distribution이다.
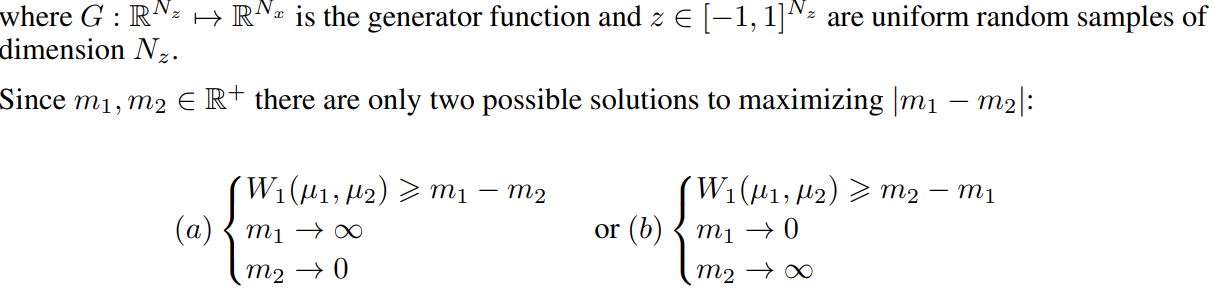
논문은 식 (1)을 최대화하는 두 가지 방법 중에서 (b)를 고르는데, m1을 최소화하는 것이 자연스럽게 real image를 auto-encoding하는 것으로 인도하기 때문이다. 다음과 같이 를 최소화하는 식으로 D, G의 parameter 를 update하고 는 z에서 온 samples이다.
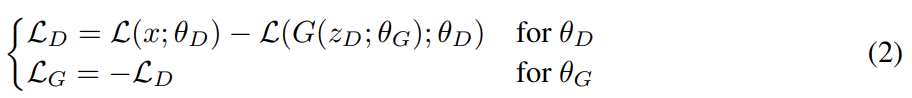
이 objective은 WGAN과 비슷하지만 두 가지 중요한 차이점이 있다. 첫째는 samples 간 distribution을 match하는 게 아니라 losses 간 distribution을 match한다는 것이다. 둘째는 Kantorovich and Rubinstein duality theorem를 사용하지 않기 때문에 discriminator가 명시적으로 K-Lipschitz를 만족하게 요구하지 않는다는 점이다.
D가 쉽게 이기는 경우를 막고 G와 D를 잘 balance하기 위해 논문은 equilibrium 개념을 소개한다. 논문은 식 (3)을 만족할 때 equilibrium 상태에 있다고 간주한다. 편의상 으로 표기를 간단히 했다.

D가 구분할 수 없을 정도로 G가 real과 비슷한 sample을 생성한다면 그들의 errors의 distribution도 동일할 것이고 error의 기댓값도 동일할 것이다. 논문은 diversity ratio라고 이름붙인 새로운 hyper-parameter 를 정의해서 equilibrium을 relax한다.

이제 discriminator은 두 가지 목표가 있다. real images를 auto-encode하는 것과 real/generated images를 구분하는 것이다. term이 두 목표를 balance하게 해준다. 낮은 값은 낮은 image diversity를 야기하는데, discriminator가 real images를 auto-encoding하는 것에 더 집중하기 때문이다. 논문은 image과 sharp하고 detail한 정도가 자연적인 한계(boundary)가 있다고 언급한다.
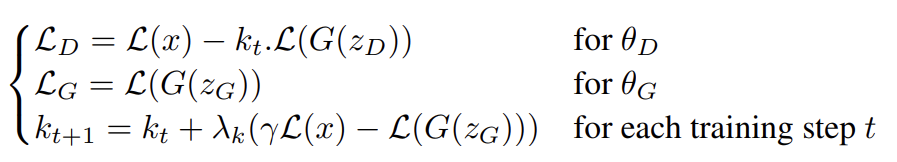
BEGAN의 objective은 위와 같다. equilibrium 을 유지하기 위해 Proportional Control Theory를 사용한다. 이는 gradient descent 도중 을 얼마나 강조할 것인지 조절하는 변수 를 사용하여 구현된다. 으로 초기화하며 는 k의 proportional gain, 즉 k의 learning rate이고 실험에선 0.001을 사용했다. 본질적으로 이는 식 (4)를 유지하기 위해 각 step마다 가 조정되는 closed-loop feedback control 형태로 생각할 수 있다.
초기 training stages에선 G가 encoder가 reconstruct하기 쉬운 data를 생성하는 경향이 있는데 generated data가 0에 가깝고 real data distribution이 아직 정확히 학습되지 않았기 때문이다. 이는 초기에 를 야기하고 이후 전체 training process에서 equilibrium constraint에 의해 유지된다.
stable train을 위해 D와 G를 번갈아 학습하거나(alternating training) D를 pretraining하는 기존 GAN과 달리 BEGAN은 그런 걸 요구하지 않는다.
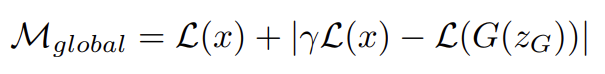
또 GAN의 본래 식이 zero-sum game으로 정의되었기 때문에 convergence를 결정하는 것이 어려운 과제다. (G와 D 중) 하나의 loss가 오르면 다른 loss는 감소하기 때문이다.
논문은 equilibrium 개념을 사용해 convergence의 global measure을 유도한다. proportion control algorithm 에 대한 instantaneous process error의 가장 작은 절대값을 가진, closest reconstruction L(x)을 찾는 것으로 converge process를 간주하여 위와 같이 두 항을 더하여 measure을 정의한다. 이 measure은 network가 final state에 도달했는지 collapse했는지 판단하기 위해 사용될 수 있다.
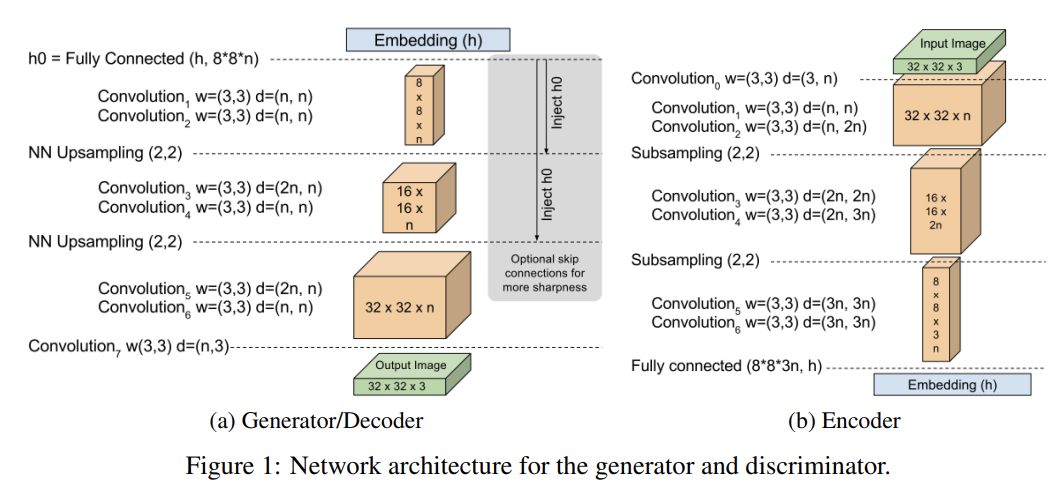
Discriminator D ()는 auto-encoder 형태의 convolutional deep neural network이다. 3 × 3 convolutions과 exponential linear units(ELUs)를 사용했고 각 층이 (보통 2번씩) 반복된다. 더 많은 반복이 더 좋은 visual result를 만듬을 관찰했다. 각 down-sampling마다 conv filters가 선형적으로 증가했다. down-sampling은 stride 2로 sub-sampling하는 식으로 구현됐고 up-sampling은 nearest neighbor로 수행됐다. encoder와 decoder의 경계 사이에는 tensor of processed data가 fully connected layers를 통해 mapping되고 non-linearities(활성화함수)를 사용하지 않는다. mapping은 embedding state 에서 h로 가며 는 auto-encoder hidden state의 dimension이다.
Generator G ()도 (단순히 simplicity를 위해) discriminator의 decoder와 동일한 (그러나 weight은 다른) architecutre을 사용한다. input state는 uniformly sample된 다.
이 간단한 architecture은 high quality results와 robustness를 준다. 추가로 optional하게 vanishing residuals를 사용하여 network를 초기화하거나 gradient propagation을 도울 skip connection을 도입하면 gradient propagation를 돕고 sharper images를 생성할 수도 있었다.

(Fig 2a의 EBGAN 결과는 다른 dataset에 train되었기 때문에 곧대로 비교하면 안 된다)
CelebA dataset의 360K celebrity face images로 BEGAN을 학습시켰다. Fig 2는 128 x 128 해상도의 결과이며, Stacked GANs을 제외하면 최초의 해부학적으로 일관적인 high-resolution 결과물이다. 다양한 poses, expressions, genders, skin colors, light exposure, facial hair을 관찰할 수 있었지만 glasses는 보지 못했고 older people이 적었고, men보다 women이 더 많았다.
Fig 3은 의 효과를 비교했다. 작은 값일 때는 얼굴들이 매우 획일적이다. 값이 증가하면 다양성이 증가하지만 artifacts도 증가한다. 이는 diversity와 quality가 독립적이라던 기존의 연구와 상반된다.

generator의 modal coverage을 추정하기 위해 real images에 상응하는 generator의 embedding을 찾는다. 이는 Adam을 통해 을 최소화하는 값을 찾는 식으로 이루어진다. real images로 mapping하는 게 모델의 목표는 아니지만 이는 모델의 일반화 능력을 테스트하는 방법을 제공한다. 두 real images 사이 embeddings을 interpolating하는 식으로 모델이 단순히 memorize한 게 아니라 image contents를 generalize했음을 판별할 수 있다.
Fig 4는 (training data가 아닌) 128 x 128 images 사이 interpolation 결과다. Sample diversity는 확실하고 generated images는 실제와 가깝다. interpolation도 좋은 continuity를 보인다. 담배처럼 일부 features는 표현되지 않기도 한다. rotation은 smoothe한데 옆얼굴(profile)이나 정면 얼굴(camera facing ones)은 잘 포착하지 못한다. 이는 dataset에 흔하지 않기 때문으로 추정된다. Fig 4d의 좌우반전 사진의 interpolation 결과는 identity와 rotation의 분리를 입증한다. 하나의 옆얼굴 사진으로부터 사실적인 정면 얼굴 사진을 얻을 수 있었다.
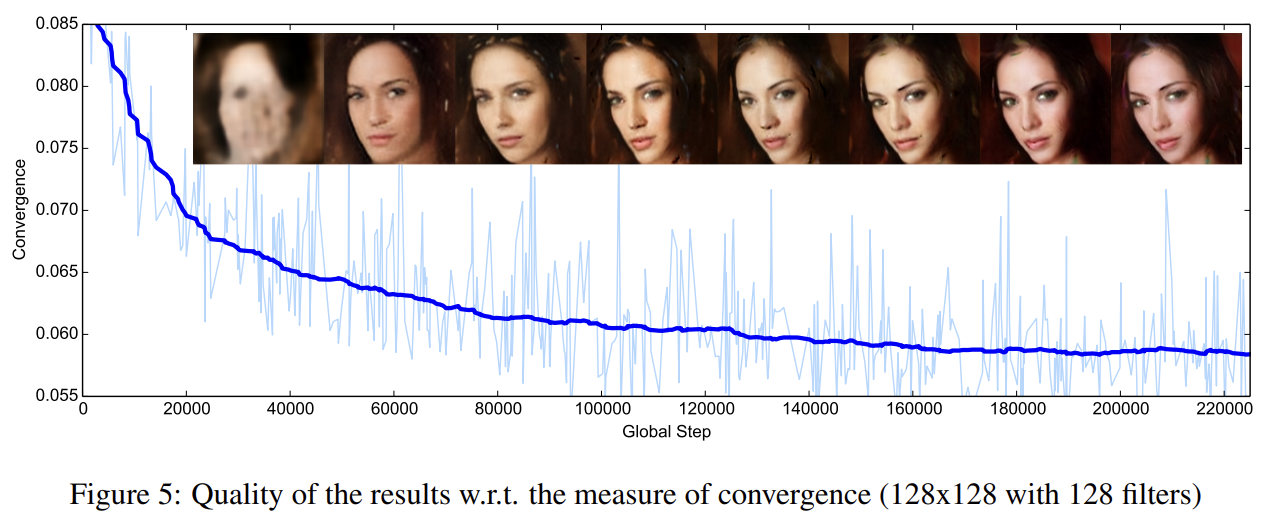
convergence measure의 경우 image fidelity와 잘 상관관계가 있음을 Fig 5에서 확인할 수 있다. EBGANs처럼 모델이 빠르게 수렴함을 볼 수 있는데, fast convergence property가 pixel-wise losses에서 오는 것처럼 보인다고 한다.
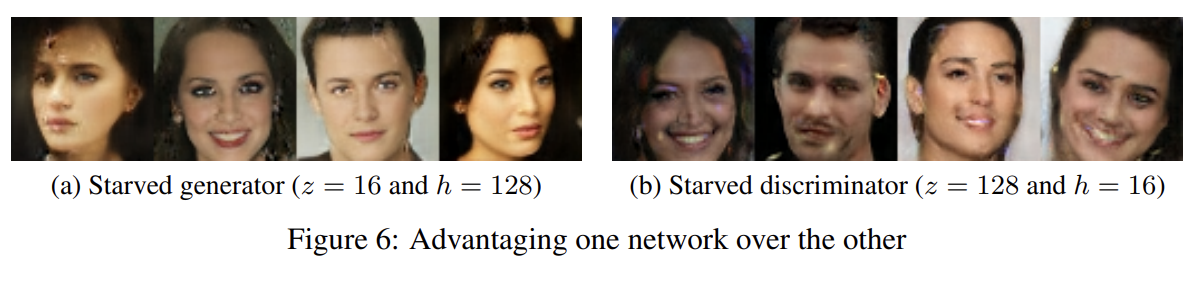
equilibrium balancing technique의 robustness를 테스트하기 위해 D와 G를 각각 advantaging시키는 실험을 했다. equilibrium을 유지함으로써 model은 stable했고 의미있는 결과를 냈다. h의 낮은 dimensionality로 인해 discriminator capacity가 감소해 예상대로 image quality가 나빠졌다. 그런데 놀랍게도 z의 낮은 dimensionality는 상대적으로 image diversity와 quality에 적은 효과를 끼쳤다.
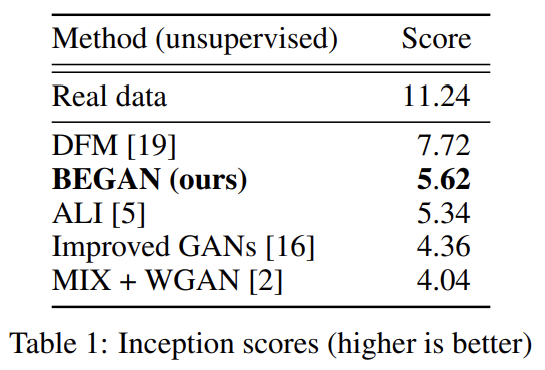
CIFAR-10 데이터셋에 inception score을 계산해서 정량평가도 했다.
Strengths
- 실험이 다양했다. 정성평가뿐 아니라 정량평가도 포함하고 있었다.
- equilibrium을 이용해 학습 불안전성을 해소했다.
- 모델의 결과물 quality와 상관 관계가 있는 convergence measure을 제안했다.
- generator에서 embedding을 이용한 interpolation 결과가 성공적이었다.
- 고해상도 결과를 뽑을 수 있었다.
