오늘 리뷰할 논문은 PixelRNN & PixelCNN의 후속 연구인 Gated PixelCNN & Conditional PixelCNN 논문이다.
Summary
논문은 PixelCNN architecture에 기반한 새로운 image density model을 가지고 conditional image generation을 탐구한다. 모델은 descriptive labels, tags나 다른 네트워크가 생성한 latent embeddings 등 어떤 vector에도 condition될 수 있다. ImageNet 데이터베이스의 class label에 condition되었을 때, 모델은 다양하고 현실적인 사진을 생성할 수 있다. unseen face의 single image가 주어졌을 때 CNN이 생성한 embedding에 condition되어 동일 인물의 다양한 표정, poses, lighting condition으로 초상화를 그릴 수 있다. 또한 논문은 image autoencoder에서 conditional PixelCNN이 강력한 decoder가 될 수 있음을 보인다. 또한 제안된 모델의 gated convolutional layers은 PixelCNN의 log-likelihood를 향상시켜 ImageNet에서 PixelRNN의 SOTA를 크게 감소한 연산량으로 맞먹는다.
image modeling의 많은 실용적인 application이 model이 prior information에 condition되기를 요구한다. denoising, deblurring, inpainting, super-resolution, colorization 등의 image processing tasks도 noisy/incomplete data에 condition되어 이미지를 생성해야 한다.
논문은 PixelRNN architecture의 convolutional variant를 발전시켜 conditional image modelling의 잠재력을 탐구한다. 이 네트워크는 훌륭한 sample을 만들뿐 아니라 (GAN 같은 대체제와 달리) 명시적인 probability densities을 반환해서 compression, probabilistic planning, exploration 등의 domain에 적용하기 쉽다. architecture의 기본 아이디어는 image를 pixel by pixel로 model하기 위해 autoregressive connections를 사용하는 것이다. joint image distribution은 conditionals의 곱으로 분해된다. 이전 논문에서 PixelRNN과 PixelCNN을 제안했는데 PixelRNN이 더 정확하지만 CNN이 병렬화가 더 쉽기 때문에 PixelCNN의 학습이 더 빠르다. 논문은 PixelCNN의 gated 버전인 Gated PixelCNN을 소개해 두 모델의 장점을 합치고자 한다. Gated PixelCNN은 학습 시간은 절반보다 적게 요구하면서 CIFAR과 ImageNet 모두에서 PixelRNN의 log-likelihood를 맞먹는다.
또 Gated PixelCNN의 conditional 버전인 Conditional PixelCNN도 소개한다. 이는 latent vector embedding가 주어졌을 때 natural images의 복잡한 conditional distributions을 model할 수 있다. 논문은 single Conditional PixelCNN model이 class의 one-hot encoding에 condition되었을 때 다양한 class의 이미지를 생성할 수 있음을 보인다. 비슷하게 high level information을 포착하는 embeddings을 사용해 비슷한 features의 다양한 사진들을 생성할 수 있다. 이는 embeddings 내에 encode된 불변성에 대한 통찰을 제공한다.
- Gated PixelCNN
PixelCNNs/PixelRNNs은 image x 위의(over) pixels의 joint distribution을 다음과 같이 conditional distributions의 곱으로 model한다.
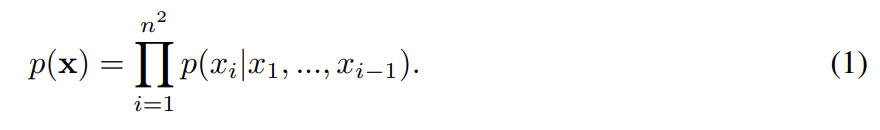
pixel dependencies의 순서는 raster scan order (row by row, pixel by pixel within every row)이다. 따라서 모든 픽셀은 왼쪽과 위쪽의 픽셀에만 의존한다. PixelCNN에서 모든 conditional distribution은 CNN으로 model된다. CNN이 위와 왼쪽 픽셀만 볼 수 있게 convolution의 filters가 mask된다. 각 픽셀마다 R, G, B channel이 model되는데 B는 R, G에 condition되고 G는 R에 condition된다. 이는 네트워크의 모든 layer에서 feature map을 셋으로 split하고 mask tensors의 centre values를 adjust하는 식으로 구현된다. 그 다음 softmax로 각 channel에 가능한 256개 값이 model된다.
PixelCNN은 N x N x 3 image를 input으로 받아 N x N x 3 x 256 predictions을 output한다. convolution의 사용은 training 도중 모든 pixel에 대한 예측이 병렬적이게 만들어준다. sampling 중에는 예측이 sequential하다. pixel이 예측될 때마다 다음 pixel을 예측하기 위한 input으로 네트워크에 되먹인다. 모든 pixel이 highly non-linear하고 multimodal한 방식으로 이전 pixel에 의존하게 해서 sequentiality는 고품질 이미지를 생성하는 데 중요하다.
- Gated Convolutional Layers
convolutional stacks 대신 spatial LSTM layers을 쓰는 PixelRNN은 PixelCNN보다 generative model로서의 성능이 더 좋았다. 그 이유는 LSTM 내의 recurrent conections이 네트워크 내의 모든 layer가 이전 pixel의 이웃 전부에 접근할 수 있게 허용하기 때문이다. 반면 PixelCNN이 접근 가능한 이웃은 convolutional stack 깊이에 linearly 증가한다. 이 단접은 충분히 많은 layer을 사용함으로써 완화할 수 있다. PixelRNN의 다른 장점은 PixelRNN이 (LSTM gates의 형태로) multiplicative units을 보유한다는 것이고 이는 더 복잡한 상호작용을 model할 수 있게 돕는다. 이를 개선하기 위해 논문은 PixelCNN 내의 masked convolutions 사이 rectified linear units을 다음과 같은 gated activation unit으로 대체했다.
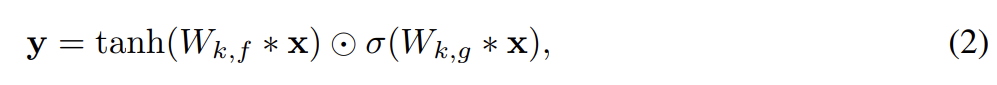
σ은 sigmoid non-linearity, k는 layer number, 동그러미점은 element-wise product, ∗은 convolution 연산자다. 이 모델을 Gated PixelCNN이라고 부른다.
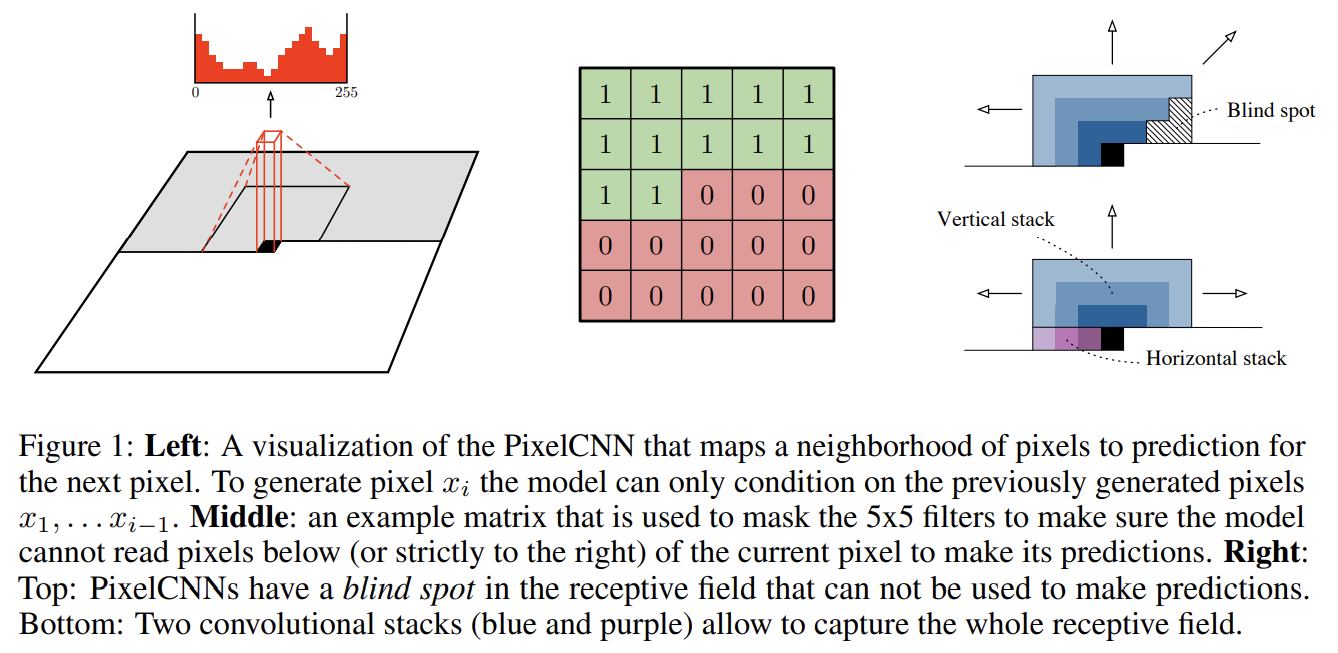
- Blind spot in the receptive field
Fig 1 우측은 3 × 3 masked filter의 effective receptive field의 점진적 성장을 보여준다. input image의 상당한 부분이 masked convolutional architecture에 의해 무시된다. 이 사각지대는 (3 × 3 filter를 쓸 때) potential receptive field의 1/4까지도 차지할 수 있다. 이는 pixel의 오른쪽 내용물은 고려되지 않는다는 소리다.
논문은 두 convolutional network stacks을 조합해 사각지대를 제거한다. Fig 1에서 볼 수 있듯 현재 row에 condition하는 horizontal stack과 위의 모든 row에 condition하는 vertical stack이다. vertical stack은 masking이 없으며 receptive field가 사각지대 없이 직사각형 모양으로 자란다. 각 layer 이후 두 stack의 output을 조합한다. horizontal stack 내의 모든 layer은 이전 layer의 output과 vertical stack의 output을 input으로 받는다. 만약 horizontal stack의 output을 vertical stack으로 연결했다면 오른쪽/아래 픽셀의 정보도 사용할 수 있어서 conditional distribution을 망가뜨렸을 것이다.
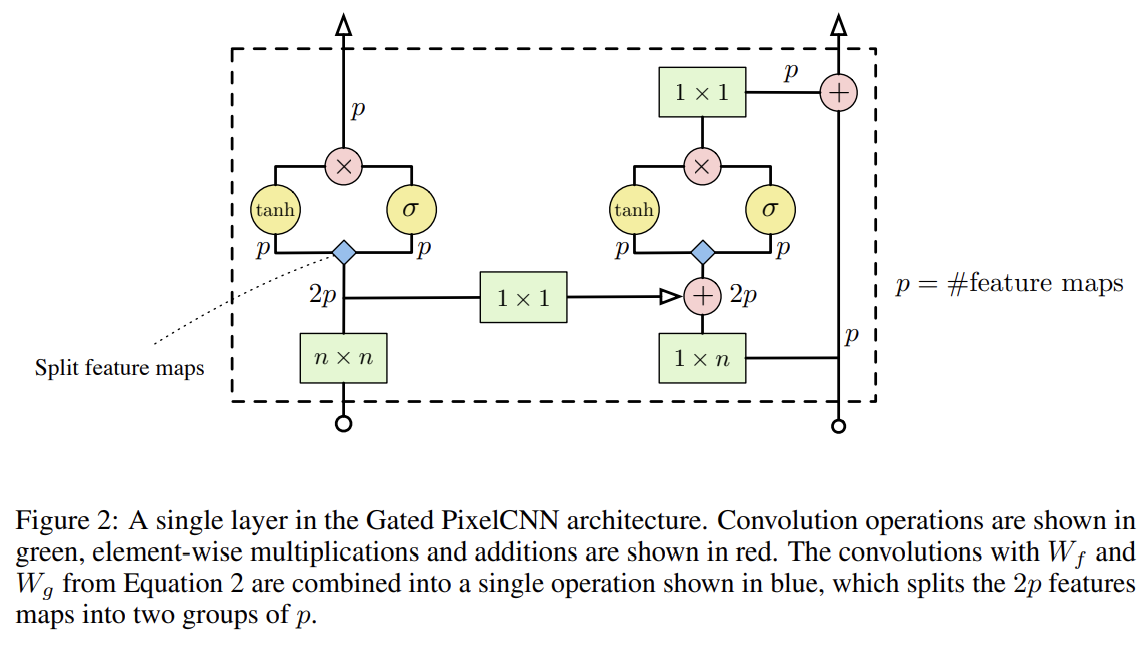
Fig 2는 Gated PixelCNN의 single layer block을 보여준다. 를 single (masked) convolution으로 조합해 병렬화를 향상시킨다. horizontal stack에서는 residual connection도 사용한다. residual connection을 vertical stack에도 적용해봤지만 성능 향상이 없어서 제외했다. Fig 2의 (n × 1)과 (n × n) masked convolutions은 convolutions과 뒤따르는 pixel shift, padding, cropping으로 구현할 수 있음을 유의하라.
- Conditional PixelCNN
latent vector h로 표현된 high-level image description이 주어졌을 때 이 description에 맞는 conditional distribution p(x|h)를 model하고자 한다. conditional PixelCNN은 다음과 같은 distribution을 model한다.
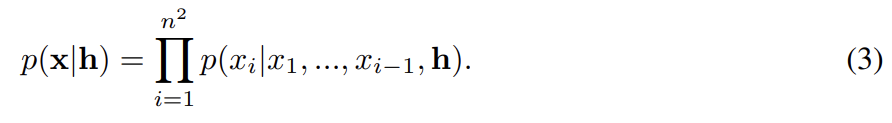
식 (2)의 nonlinearity 이전에 h에 의존하는 항을 activation에 더해 conditional distribution을 model한다.
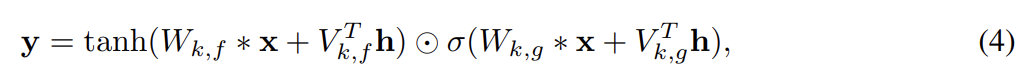
k는 layer number다. h가 class를 명시하는 one-hot encoding이면 이는 모든 layer에 class dependent bias를 추가하는 것과 동일하다. conditioning이 image 내 pixel의 위치에 의존하지 않는다는 것에 유의하라. h가 image에 무엇이 있어야 하느냐는 정보만 담고 있지, 어디에 있느냐는 정보를 담지 않기 때문에 적절하다.
또한 conditioning function이 location dependent한 variant도 개발했다. 이는 h에 embed된 image 내의 특정 구조물의 위치 정보를 가지고 있는 application에 유용하다. deconvolutional neural network m()를 가지고 h를 (image와 동일한 width, height을 가졌지만 features map 수는 다를 수도 있는) spatial representation s = m (h)로 mapping하여 다음과 같이 location dependent bias을 얻을 수 있다. 은 unmasked 1 × 1 convolution이다.
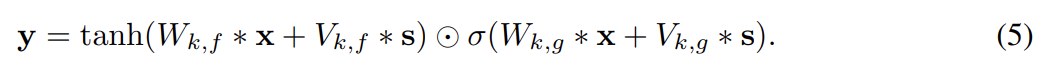
- PixelCNN Auto-Encoders
conditional PixelCNNs이 다양한 mutlimodal image distribution p(x|h)을 model할 수 있기 때문에 이들을 auto-encoder 같은 기존의 neural networks의 image decoder로 적용할 수 있다.
traditional convolutional auto-encoder architecture [16]로 시작해 deconvolutional decoder를 conditional PixelCNN로 대체하고 end-to-end로 network 전체를 학습한다. PixelCNN이 강력한 unconditional generative model이기 때문에 reconstruction 향상이 기대된다. encoder가 데이터에서 추출하는 representations도 low level pixel statistics의 많은 부분이 PixelCNN에 의해 다뤄지기 때문에 encoder은 이들을 low-dimensional representation h에서 생략하고 high-level abstract information에 집중하게 될 것이다.
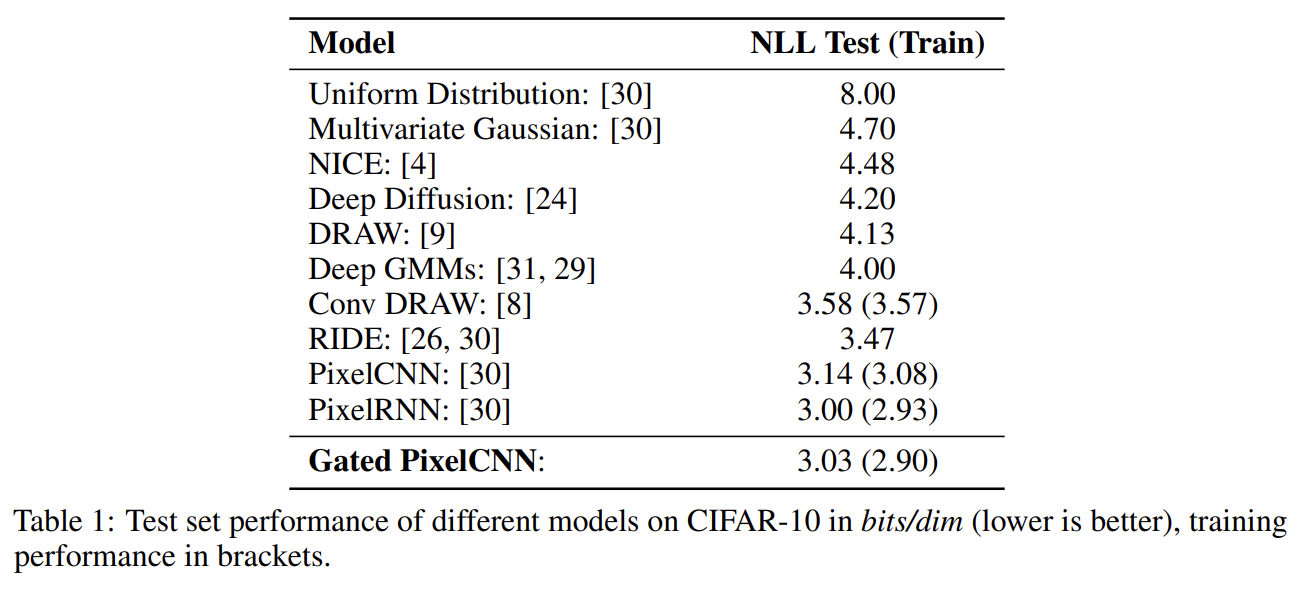
CIFAR-10 데이터셋에 Gated PixelCNN을 실험한 결과다. Gated PixelCNN의 성능은 PixelCNN보다 뛰어나며 PixelRNN에 근접한다.
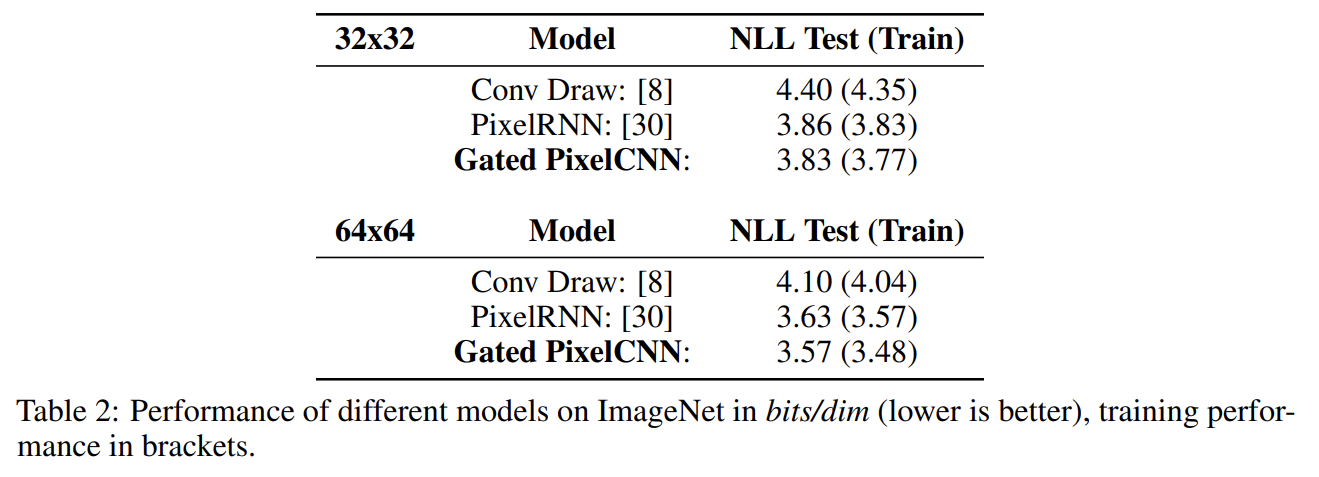
ImageNet 데이터셋에서 Gated PixelCNN은 PixelRNN보다 성능이 뛰어나다. 논문은 이를 underfitting 때문으로 추정하며 larger models의 성능이 더 좋고 simpler PixelCNN model이 더 잘 scale한다.

다음으로 Gated PixelCNN과 ImageNet으로 class-conditional modelling을 실험한다. i번째 class의 one-hot encoding 가 주어졌을 때 를 model한다. conditioning이 log-likelihood results를 향상시킬 것이라고 예상할 수도 있지만 결과에 큰 차이는 없었다. 반면 생성된 sample의 visual quality에 큰 향상이 있었다.

다음으로 큰 초상화 데이터베이스로 학습시킨 CNN의 꼭대기 층에서 latent representation을 가져와 portrait embedding에 conditioning하는 실험을 했다.

이미지 쌍의 embeddings 사이 linear interpolations에 condition하는 실험도 했다.

PixelCNN auto-encoder을 32x32 ImageNet patches에 훈련시켜 convolutional auto-encoder와 비교했다. bottleneck representation h에 encode된 정보가 질적으로 다르리라는 앞선 추측을 지지한다. 예를 들어 맨 밑의 row를 보면 input을 똑같이 재구성하는 게 아니라 다르지만 비슷하게 생긴 장면을 생섬함을 볼 수 있다.
Strengths
- gating을 통해 정확도와 수렴 속도가 향상됐고 PixelCNN이기 때문에 PixelRNN보다 연산량도 적다.
- 두 종류 stack을 조합해 context의 사각 지대를 없앴다.
- conditional PixelCNN은 auto-encoder 내에서 decoder로 성공적으로 사용 가능했다.
