오늘 리뷰할 논문은 XLM 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
최근 연구들은 English natural language understanding을 위한 generative pretraining의 효율을 증명했다. 논문은 이를 multiple languages로 확장해 cross-lingual pretraining의 효과를 보인다. cross-lingual language models (XLMs)을 학습하기 위해 2가지 방법을 사용한다. 1. monolingual data에만 의존하는 unsupervised 방법과 2. 새로운 cross-lingual language model objective을 가지고 parallel data를 leverage하는 supervised 방법이다. cross-lingual classification, unsupervised machine translation, supervised machine translation에 SOTA를 달성한다.
3가지 language modeling objective를 소개하며 2가지는 monolingual data (unsupervised)만 필요하고 하나는 parallel sentences (supervised)가 필요하다. N languages를 고려하며 명시하지 않은 이상 N monolingual corpora 을 가진다고 가정한다. 내 문장 수를 로 표기한다.
- Shared sub-word vocabulary
모든 실험에서 Byte Pair Encoding (BPE)로 생성된 동일한 shared vocabulary를 가지고 모든 languages를 처리한다. Lample et al. (2018a)가 보였듯 이는 동일한 alphabet나 (digit이나 고유명사 같은) anchor tokens을 공유하는 languages에 걸친(across) embedding spaces의 alignment를 크게 향상시킨다. monolingual corpora에서 랜덤하게 sample한 문장들의 concatenation에 BPE splits을 학습한다. probabilities 을 가진 multinomial distribution에 따라 문장들이 sample된다.
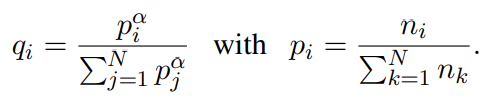
α = 0.5로 고려한다. 이 distribution을 가지고 sampling하는 것은 low-resource languages와 연관된 tokens의 수를 증가시키고 high-resource languages를 향한 bias를 완화한다. 특히 이는 low-resource languages의 단어가 character level에서 split되는 것을 방지한다.
- Causal Language Modeling (CLM)
CLM은 sentence 내에 previous words가 주어졌을 때 word의 probability를 model하도록 학습된 Transformer language model로 구성된다. Transformer는 batch 내 first words에게 context를 제공하기 위해 previous hidden states가 current batch로 전해진다. 그러나 이 기법은 cross-lingual setting에 확장되지 않으므로 간단함을 위해 각 batch 내 first words를 context 없이 둔다.
- Masked Language Modeling (MLM)
BERT 논문을 따라 text streams에서 랜덤하게 15%의 BPE tokens을 sample한 후 80% 확률로 [MASK] token로 대체하고 10% 확률로 random token으로 대체하고 10% 확률로 변하지 않은 채로 둔다. BERT의 MLM과의 차이점은 pairs of sentences 대신 임의의 개수의 문장(256 tokens에서 잘린)을 지닌 text streams의 사용을 포함한다. rare tokens와 frequent tokens 사이 불균형을 조절하기 위해 Mikolov et al. (2013b)와 비슷한 방법을 사용해 frequent outputs를 subsample한다. text stream 내 tokens은 multinomial distribution에 따라 sample되고, 그들의 weights는 그들의 invert frequencies의 제곱근에 비례한다.
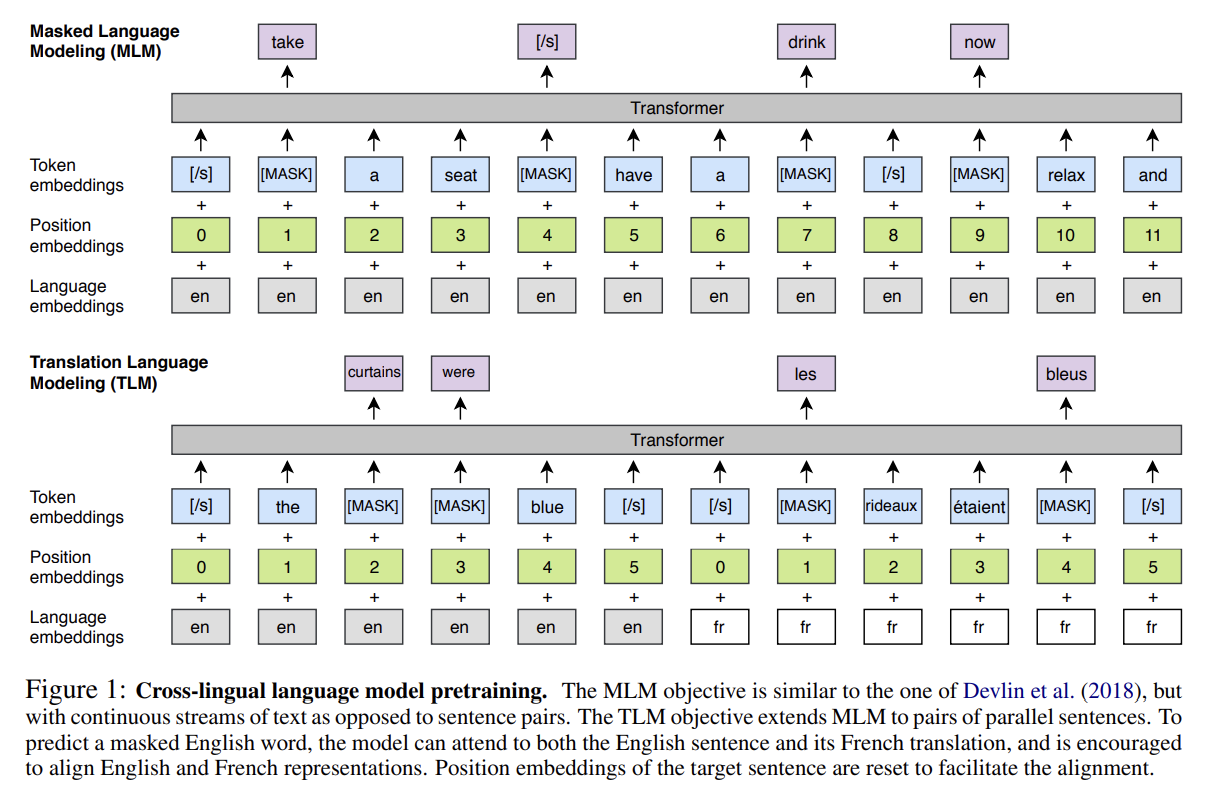
- Translation Language Modeling (TLM)
CLM과 MLM 둘 다 unsupervised이며 monolingual data만 요구한다. 그러나 이 objectives는 parallel data를 leverage할 수 없다. 그래서 cross-lingual pretraining을 향상시키기 위해 새로운 TLM을 도입한다. TLM은 MLM의 확장이며, monolingual text streams를 고려하는 대신 Fig 1처럼 parallel sentences를 concatenate한다. source와 target sentences 양쪽 내의 단어들을 랜덤하게 mask한다. English sentence 내 masked word를 예측하기 위해 모델은 주변 English words나 French translation에 attend하여 English와 French representations을 align하도록 모델을 장려할 수 있다. 특히 masked English word를 추론하기에 English context가 불충분하면 모델은 French context를 leverage할 수 있다. alignment를 촉진하기 위해 target sentences의 positions도 reset한다.
이제 다음과 같은 것들을 얻기 위해 어떻게 cross-lingual language models이 사용될 수 있는지 알아보자.

- Cross-lingual classification
pretrained XLM models은 범용적인 cross-lingual text representations을 제공한다. English classification tasks로의 monolingual language model fine-tuning과 비슷하게 XLMs을 cross-lingual classification benchmark에 fine-tune한다. 평가를 위해 cross-lingual natural language inference (XNLI) dataset을 사용한다. 구체적으론 pretrained Transformer의 first hidden state 꼭대기에 linear classifier을 추가하고 English NLI training dataset에 모든 parameters를 fine-tune한다. 그 다음 모델이 정확한 NLI predictions을 만들 수 있는지 15 XNLI languages에 평가한다. Conneau et al. (2018b)을 따라 train과 test sets의 machine translation baselines도 포함한다.
- Unsupervised Machine Translation
pretraining은 unsupervised neural machine translation (UNMT)의 핵심 요소다. Lample et al. (2018b)는 lookup table을 초기화하기 위한 pretrained crosslingual word embeddings의 질이 unsupervised machine translation model의 성능에 상당한 효과가 있다고 보였다. 논문은 UNMT의 iterative process를 bootstrap하기 위해 cross-lingual language model을 가지고 전체 encoder와 decoder를 pretraining한다. 여러 initialization schemes을 탐구하고 WMT’14 English-French, WMT’16 English-German와 WMT’16 English-Romanian을 포함하는 여러 standard machine translation benchmarks에 그들의 영향을 평가한다.
- Supervised Machine Translation
supervised machine translation에 대한 cross-lingual language modeling pretraining의 효과도 조사하고 Ramachandran et al. (2016)의 방법을 multilingual NMT로 확장한다. WMT’16 Romanian-English에 CLM과 MLM pretraining의 효과를 평가한다.
- Low-resource language modeling
low-resource languages의 경우 비슷하지만 higher-resource languages의 data를(특히 둘이 상당한 부분의 vocabulary를 공유할 때) leverage하는 것이 도움이 된다.
- Unsupervised cross-lingual word embeddings
(생략) 논문은 shared vocabulary을 사용하지만 word embeddings는 우리의 cross-lingual language model (XLM)의 lookup table을 통해 얻어진다.
(training detail, data preprocessing 생략)
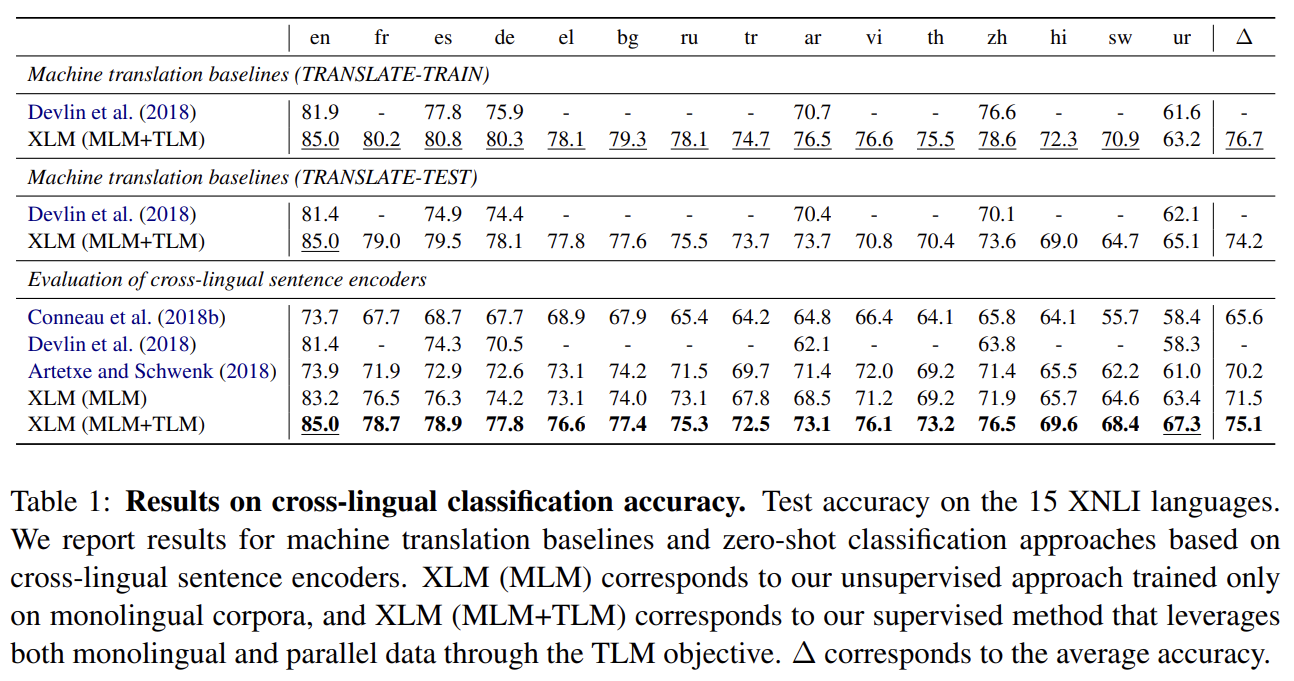
Tab 1에서 2종류 pretrained cross-lingual encoders을 평가한다. monolingual corpora에만 MLM을 사용하는 unsupervised cross-lingual language model과 추가적인 parallel data를 사용해 MLM과 TLM을 결합한 supervised cross-lingual language model이다. fully unsupervised MLM method은 zero-shot cross-lingual classification에 SOTA를 달성한다. TLM으로 parallel data을 leverage함으로써 성능이 더 향상된다.
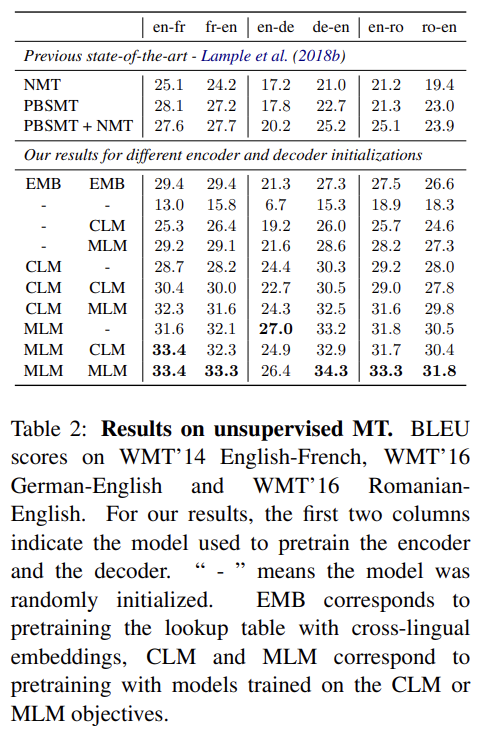
supervised machine translation task는 3가지 language pairs를, 즉 English-French, English-German, English-Romanian을 고려한다. encoder와 decoder 양쪽에 대해 여러 가능한 initializations을 고려한다. CLM pretraining, MLM pretraining, random initialization을 조합해 9가지 세팅이 나온다. lookup table (EMB)만 pretraining하는 것에 비해 encoder와 decoder 모두 MLM에 pretraining하면 일관적인 성능 향상이 있었다. MLM objective pretraining은 일관적으로 CLM을 능가했으며 이는 BERT 논문의 결과와도 일치한다. 또 encoder와 decoder 둘 다 pretraining하는 것에 비해 decoder만 pretraining하면 성능 하락이 컸는데 encoder만 pretraining하면 영향이 적어서 encoder가 pretrain에 가장 중요한 요소임을 알 수 있었다.
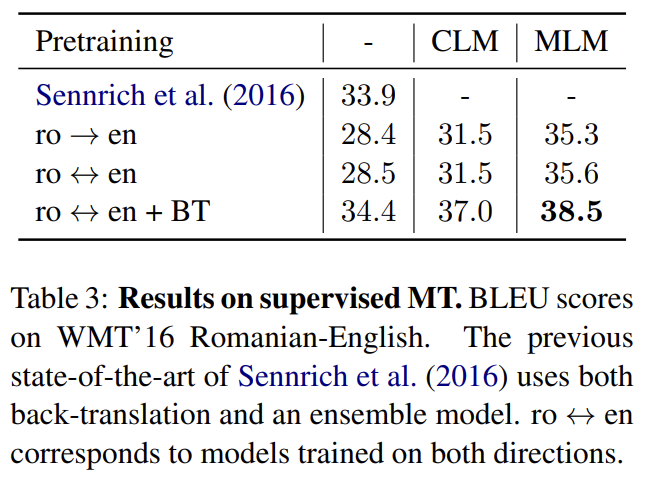
Romanian-English WMT’16에 여러 supervised training configurations을, 즉 mono-directional (ro→en), bidirectional (ro↔en, en→ro와 ro→en 둘 다에 학습된 multi-NMT model)와 bidirectional with back-translation (ro↔en + BT)을 평가한다. back-translation을 가진 bidirectional model이 SOTA를 달성한다.
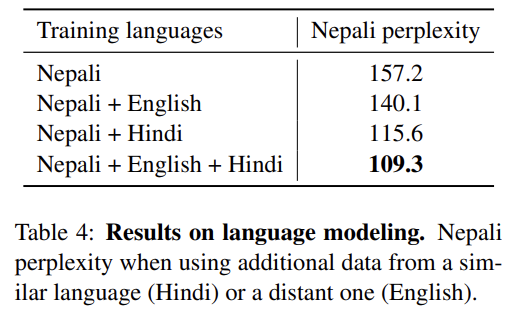
Nepali language model의 perplexity를 향상시키기 위한 cross-lingual language modeling의 영향을 조사한다. cross-lingual language model은 Nepali language model을 향상시키기 위해 anchor points를 통해 Hindi나 English monolingual corpora로부터 제공된 추가적인 context를 transfer할 수 있다.
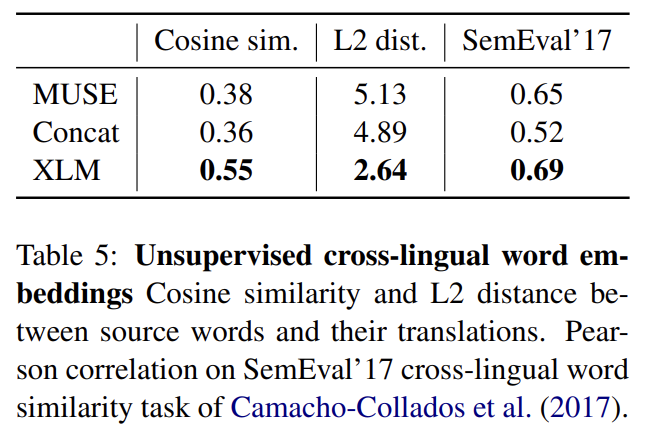
MUSE, Concat와 XLM (MLM)는 서로 다른 특징을 가지는 unsupervised cross-lingual word embedding spaces을 제공한다. 동일한 word vocabulary를 사용해 이 세 방법을 연구하고 MUSE dictionaries로부터의 word translation pairs 사이 cosine similarity와 L2 distance를 계산한다. 또한 SemEval’17 cross-lingual word similarity task를 통해 cosine similarity measure의 quality도 평가한다. cross-lingual word similarity에서 XLM이 MUSE와 Concat를 능가했다.
Strengths
- MLM을 여러 언어로 확장한 TLM이 흥미로웠다. 언어 간에 구조가 유사성이 있다 보니 서로 다른 언어로 학습하더라도 성능이 좋아지는 것 같다.
- resource가 적은 언어를 학습하기 위해 resource가 많은 비슷한 언어를 사용한 점이 인상적이었다.
