이번 논문은 Disentangling Visual and Written Concepts in CLIP이라는 논문이다. 사실 대학 인공지능 강의 조별과제로 리뷰해서 제출한 것인데, 이참에 여기에도 올리겠다. 영강이었던지라 리뷰도 영어다. 번역은 귀찮아서(...) 안했다.
Summary

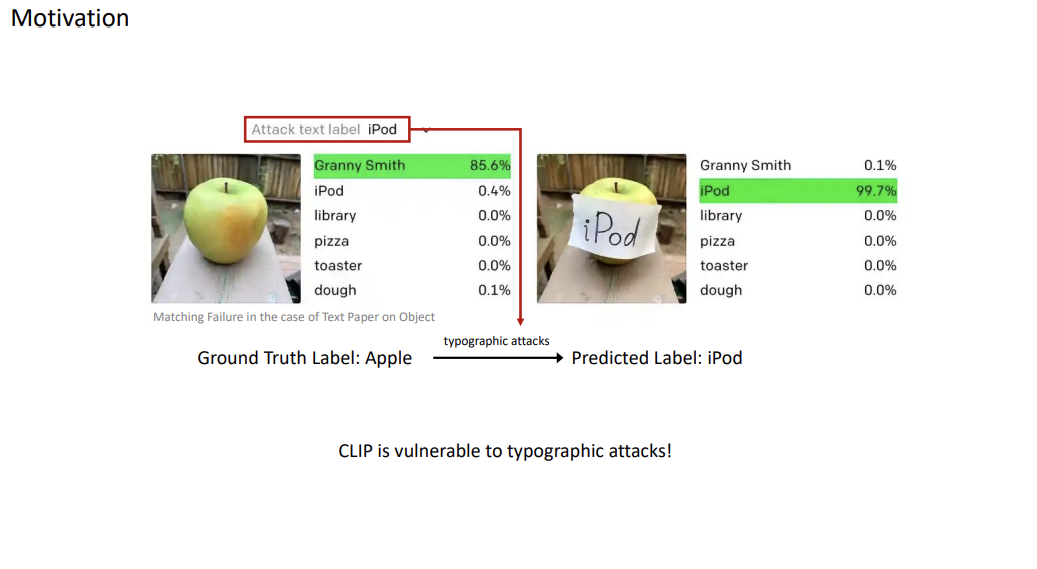
To briefly summarize the paper, it focuses on investigating and improving the CLIP model. CLIP has a problem that visual concepts and written text images are entangled in the embedding space, and this paper is the first attempt to separate the entanglement.
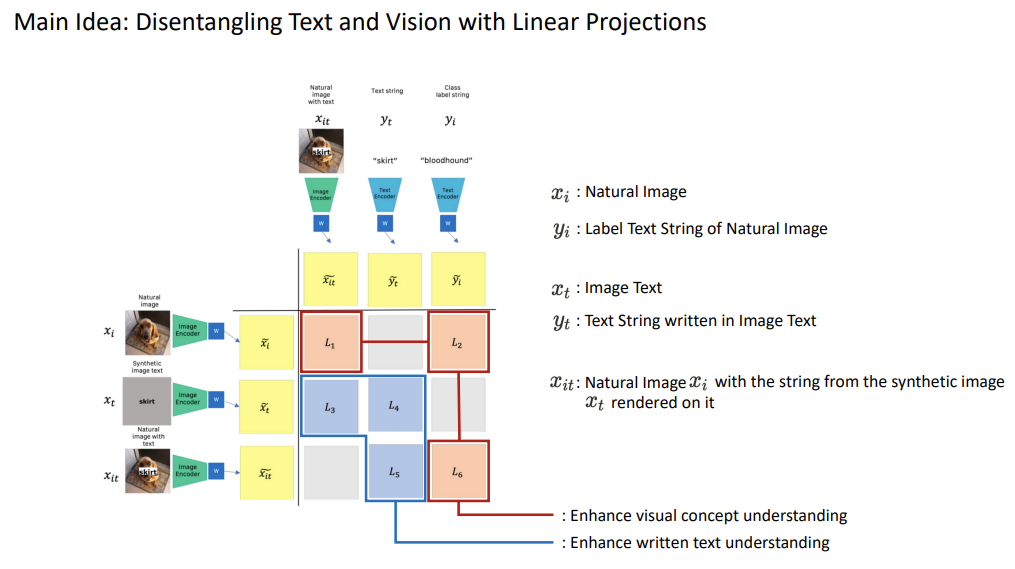
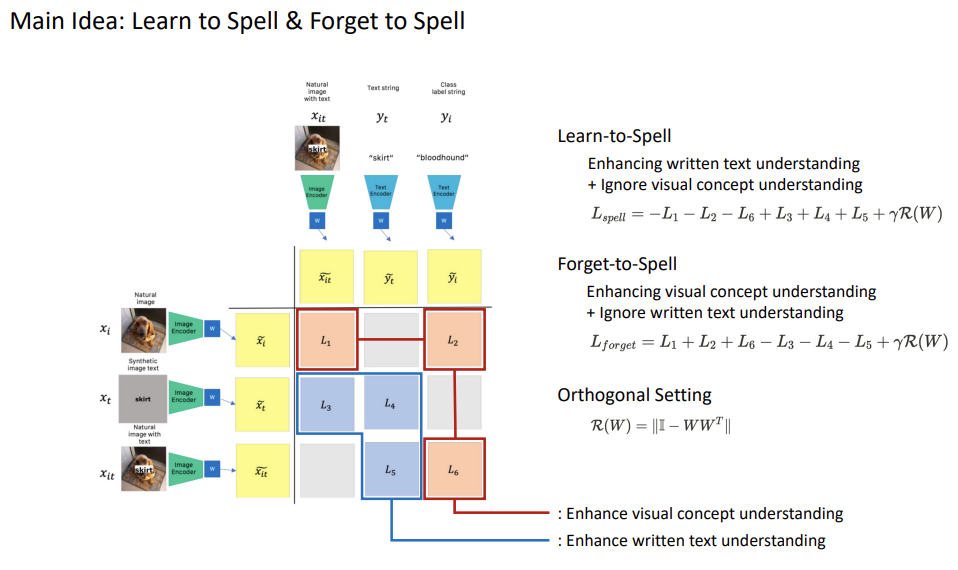
It applied a linear projection onto the image/text embeddings and designed loss terms using the similarity of these projected embeddings. Each loss term serves to enhance understanding of the written text or visual concept, and the study combines these loss term, performing contrastive learning-based optimization. The study suggested two models, Learn-to-Spell and Forget-to-Spell utilizing different loss terms for each purpose; enhance written text & ignore visual concept understanding, enhance visual concept understanding & ignoring written text understanding. Also, the study showed an orthogonal regularization term can enhance disentanglement performance.
Strengths

- The algorithm this paper presents combines various losses. Suggesting learn-to-spell and forget-to-spell models, the study successfully distinguishes visual and written concepts. With the result of image generation using VQGAN, we can verify that the learn-to-spell model generates text images and the forget-to-spell model generates visual objects without texts.
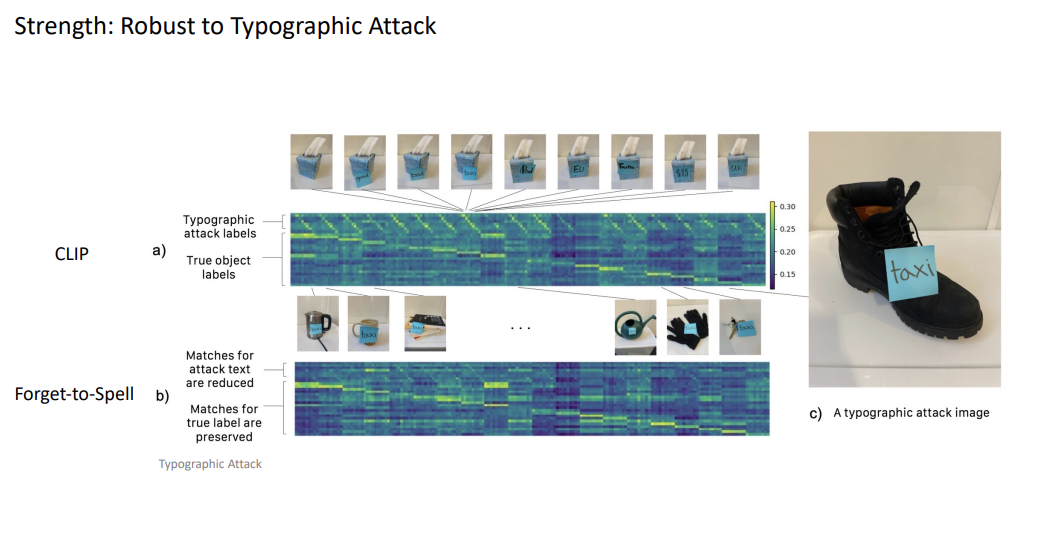
- Compared to CLIP’s vulnerability to typographic attacks, the suggested forget-to-spell model is robust to typographic attacks, which also demonstrates the new model’s ability to segregate visualizing and spelling.
- Table 1 in the paper shows accuracy of classification by replacing text encoding with image encoding of the text image. Rather than just referring to the problematic image generation result, demonstrating that CLIP has an ability to understand written texts through experiments makes the
paper more thorough. - It is not easy to quantitatively evaluate the performance of problems that this paper addresses. Although qualitative evaluations can be weak proof since they are vulnerable to cherry picking, authors thoroughly designed experiments and supplement the qualitative results to prove that the model performs well.
Weaknesses

- The criterion authors used in OCR based evaluation seems quite ambiguous. They only accept the existence of correct text if the detected region is larger than 10% of the image and 2 or more letters are correctly matched. They should clarify the reason for the detailed experimental setting to claim that it is not advantageous to them.
- Authors demonstrated that the linear projection to 64 dimensions vector space shows the best performance through experiment, but there wasn't any quantitative or qualitative interpretation about it, which is a bit disappointing.
- Authors synthesized ‘white-backgrounded centralized’ text on image to make ‘natural image with text’ input, but this particular and artificial form may bias training. There is no reason not to apply augmentations on it.
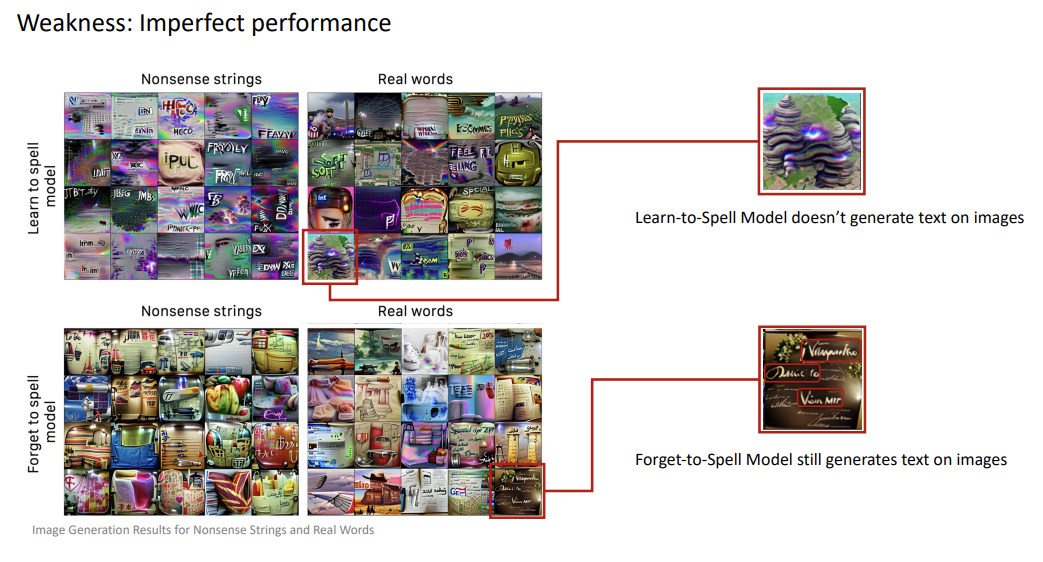
- Although authors meaningfully improve the separation of visualizing and spelling ability, the segregation is not perfect. Forget-to-spell model still generates some images with text inside, and the learn-to-spell model rarely creates images without any text.
- In regard to imperfect performances, forget-to-spell generates images with text resembling asian, arabic letters. However, authors do not present any opinion or explanation why such a consequence appears.
Overall Rating
4 / 5
Justification of Rating
This study is the first attempt to separate visualizing and spelling abilities of CLIP by interesting model design.
Also, the qualitative and quantitative results shown in the paper seems to be supporting the main idea sufficiently. For these reasons, the study deserves high rating.
However, there was some lack of detailed explanation in experimental settings and phenomena. Crucially, since the study relies entirely on the CLIP model, the variations of follow-up studies are limited, and unlikely to have much influence. In consideration of these points, 4 over 5 was finally given.
