SIFT에 관해서는 주한별 교수님의 AI 강의시간에 배운 바가 있기 때문에 비교적 논문을 읽기 수월할 것으로 기대됐다.
SIFT는 사진에서 invariant feature를 extract하는 방법인데, 이로써 서로 다른 크기와 각도에서 찍은 사진들에서 동일한 feature를 뽑아내어 matching할 수도 있고 object detection을 할 수도 있다.
해당 두 포스트를 먼저 읽으면 이해하기 편리하다.
- SIFT (Scale Invariant Feature Transform)의 원리 - 코딩재개발
- [Vision] SIFT (Scale-Invariant Feature Transform)의 원리.txt
Summary
SIFT는 4단계를 거친다.

간단히 요약하자면, DoG를 통해 사진에서 potential interest point를 여럿 추출한다.(아 interst point들이 여러 사진에서 공통적일 것으로 기대되는 위치들이다). 이는 local 극대/극소값인 keypoint(blur scale와 pixel위치)를 찾는 것이다.
각 keypoint는 여러 scale에 대해 찾았기 때문에 scale invariant하다. 이들이 orientation에 대해서도 invariant하게 만들어주기 위해 keypoint 주위로 윈도우를 설정해 해당 scale로 gaussian blur해주고, (histogram of oriented gradients, HoG를 이용해서) 히스토그램을 추출한다. 히스토그램에서 가장 높은 bin의 방향이 keypoint의 peak/dominant orientation이 되는 것이다.
최종적으로 각 keypoint마다 4x4모양 윈도우의 descriptor를 계산해준다. 하나의 작은 윈도우가 또한 4x4 윈도우인데, 여기서 (HoG를 이용해) 8방향짜리 histogram을 만들고, peak orientation을 빼준다. 이럼으로써 keypoint의 descriptor은 1. peak orientation을 가지며 2. 내부적으로는 그 peak orientation에 상대적인 16x8개의 숫자(feature vector)을 가지게 된다.
이 128차원의 feature를 nearest neighbor로 다른 이미지의 keypoint들과 비교하여 matching게 되는 것이다.
SIFT를 이용한 object recognition은 approximate nearest-neighbor lookup, a Hough transform for identifying clusters that agree on object pose, least-squares pose determination, and final verification 순서로 이루어진다. 논문에서는 데이터베이스에서 어떻게 matching을 해서 object detection을 하는지 자세히 다루는데, 나는 그 부분을 완벽하게 이해하지 못해서 이렇게 간단하게만 요약하고 넘어가겠다.
Strengths
- 기존에 scale이나 orientation 각각에 robust한 방법들은 있었는데 이건 둘을 결합시킨 데 의미가 있는 것 같다.
참고로 위에서 scale invariance에 대한 설명을 대충 넘어갔는데, 논문에서는 Lindeberg(1994)의 study가 DoG가 scale-normalized LoG와 close approximation을 제공한다고 한다.
- scale-normalized LoG
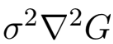
- DoG
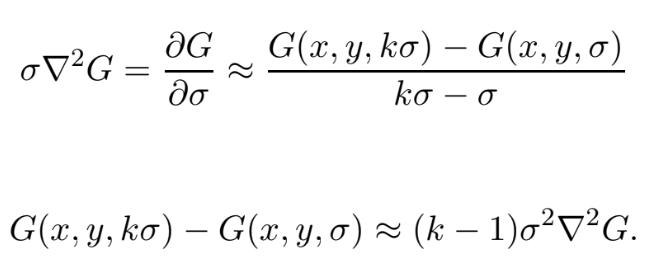
즉 LoG에 scale-normalize를 통해 scale invariance를 획득하는데, DoG는 태생적으로 이를 가지고 있음을 확인할 수 있다.
-
또 feature을 대량으로 추출할 수 있는데, object detection에서 최소 3개의 feature이 옳게 match되어야하기 때문에 대량의 feature을 얻을 수 있는 것이 유리하다.
-
computational cost를 줄이려는 노력이 곳곳에 보인다. 예를 들면 3.2 Frequency of sampling in scale에서 실험을 통해 octave당 3 종류의 scale만 사용해도 충분히 유의미한 keypoint를 찾을 수 있음을 짚은 것이나, 4.1에서 Harris and Stephens(1988)의 방법을 빌려 Hessian matrix의 eigenvalue를 직접 구하는 게 아니라 Trace와 Determinant를 통해 두 eigenvalue의 비율(r)을 costly effecient하게 판별 가능하게 했다.
유명한 논문이라 SIFT에 대한 포스트가 여럿 있기도 했고, 강의 시간에 배운 내용이기도 해서 배경 지식을 갖고 논문을 읽으니 비교적 읽기 수월했다.
수업 중엔 일부 간추려 설명한 부분도 있는 것 같은데, 좀 더 디테일을 알 수 있던 점이 좋았다.
첫 논문 리뷰라 퀄리티는 허접하고 논문에 대한 이해가 완벽했으리라고는 보장할 수 없겠지만 그래도 얼추 만족스러웠던 것 같다. 차차 실력이 늘면 좋겠다.
원래는 weakness, rating 등의 항목도 넣으려 했지만 당장 비판적으로 볼 눈이 부족한 상황에서 그래봤자 제대로 된 비판이 안 나올 것 같아서 충분히 경험이 쌓이기 전까지는 생략하기로 했다.
