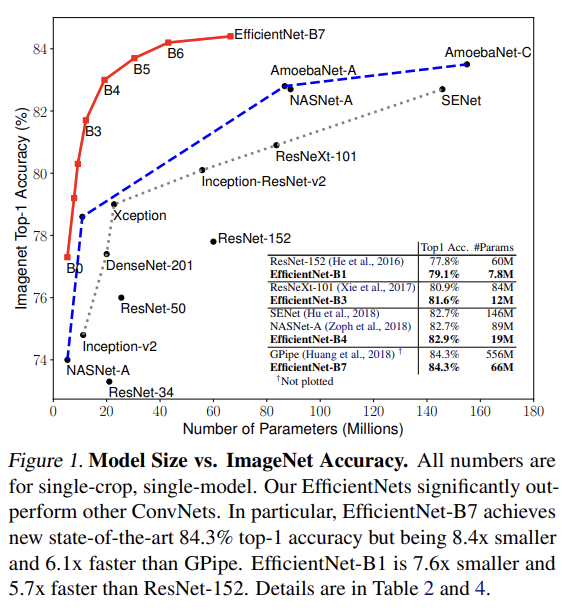
오늘 리뷰할 논문은 EfficientNet 논문이다. 논문의 목표는 주어진 resource constraint에서 model accuracy를 최대화하는 최적화를 찾는 것이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- EfficientNet
- EfficientNet 논문 설명(EfficientNet - Rethinking Model Scaling for Convolutional Neural Networks)
Summary
기존의 ConvNet은 한정된 resource budget에서 개발된 후 더 많은 resource가 가능해지면 네트워크의 depth/width/resolution를 scale up하여 accuracy를 늘렸다. 논문은 간단하고 효율적인 'compound coefficient' scaling method를 제안해 depth/width/resolution의 모든 dimension을 균일하게 scale하여 최적의 balance를 찾는다.
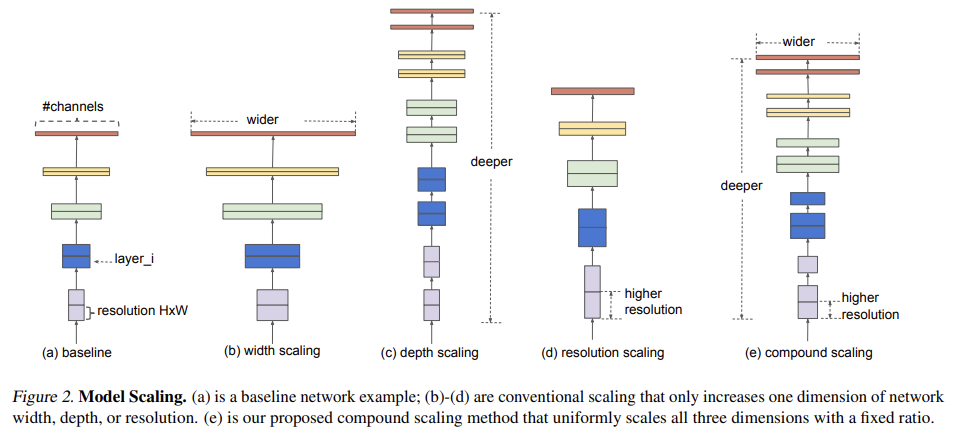
이때 기존에는 depth/width/resolution을 arbitrary scale했는데 여기서는 set of fixed scaling coefficients로 scale한다.
compound scaling method는 직관적으로 말이 되는데, input image가 클수록 receptive field를 키우기 위해 더 많은 layer가 필요하고 더 fine-grained pattern을 찾기 위해 더 많은 channel이 필요하기 때문이다.
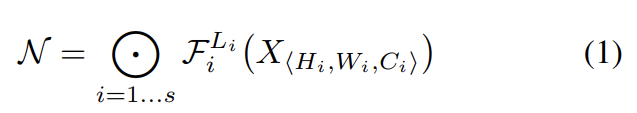
best layer architecture Fi를 찾는 기존 ConvNet과 달리 model scaling은 baseline network에 predefined된 Fi 변화 없이(즉 고정된 Fi에 대해 최적화된) network length (Li), width (Ci), resolution (Hi, Wi)를 찾고자 한다. Fi를 고정시킴으로써 model scaling은 design problem을 간단하게 만들지만 여전히 각 layer의 L, C, H, W를 결정해야하는 큰 design space가 남아있다. design space를 축소하기 위해 논문은 모든 layer가 constant ratio로 uniformly scale되어야 한다는 제약을 건다.
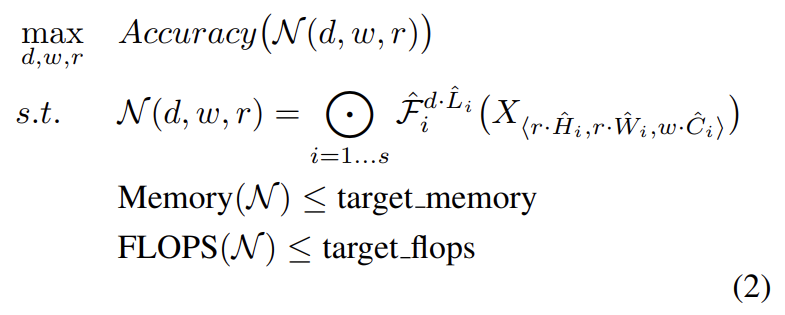
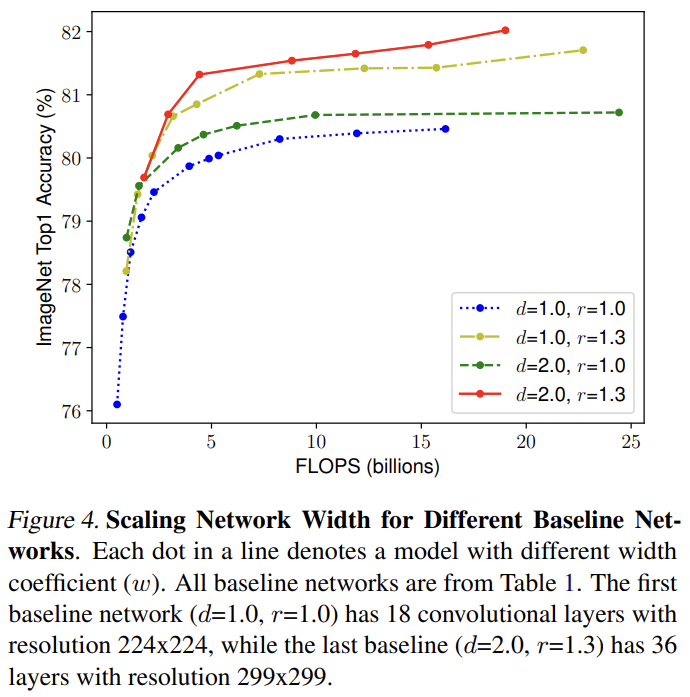
이 최적화의 주요 난점은 coefficient인 d, w, r의 optimal 값이 서로에 의존한다는 것과 resource constraint에 따라 달라진다는 점이다. 그래서 기존의 ConvNet들은 이들 중 하나만 scale한다. width/depth/resolution의 dimension을 scale up하는 것은 accuracy를 향상시키지만, bigger models에 대해 accuracy gain은 줄어든다. 논문은 앞서 말한 직관을 이유로 conventional single-dimension scaling보다 여러 scaling dimension을 balance해야 한다고 주장한다. Fig 4에서 width를 scale했을 때 d, r가 그대로인 것보다 d, r를 2로 늘렸을 때 같은 FLOPS cost에서 accuracy가 높음을 볼 수 있다.
논문은 network width, depth, resolution를 uniformly scale하기 위해 compound coefficient φ를 사용하는 compound scaling method를 제안한다.
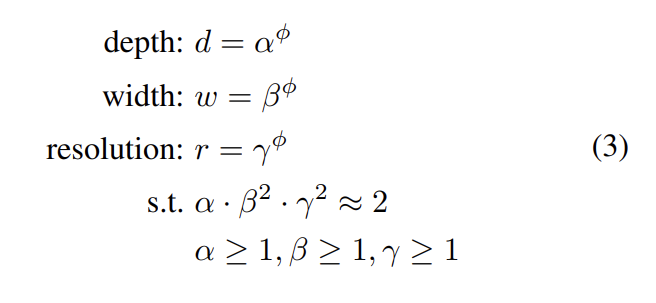
α, β, γ는 small grid search로 결정되는 constant다. φ는 model scaling에 얼마나 더 많은 resource가 가능한지 조절하는 user-specified coefficient고 α, β, γ는 extra resource를 width/depth/resolution에 얼마나 할당할지 명시한다. regular convolution operation에서 FLOPS는 에 비례한다. convolution 연산이 보통 ConvNet의 연산량을 dominate하기 때문에 식 (3)은 전체 FLOPS를 배로 늘린다. 논문에선 라는 제한을 두어 FLOPS가 배로 늘게 했다.
model scaling이 layer operator Fi를 바꾸지 않기 때문에 좋은 baseline network를 가지는 것도 중요하다. 논문은 여러 baseline에 model scaling을 실험해보고 EfficientNet이라는 new mobile-size baseline도 개발한다. EfficientNet 구조는 Tan et al.의 영감을 받아 accuracy와 FLOPS를 최적화하는 multi-objective neural architecture search를 leverage하여 개발했다고 한다.
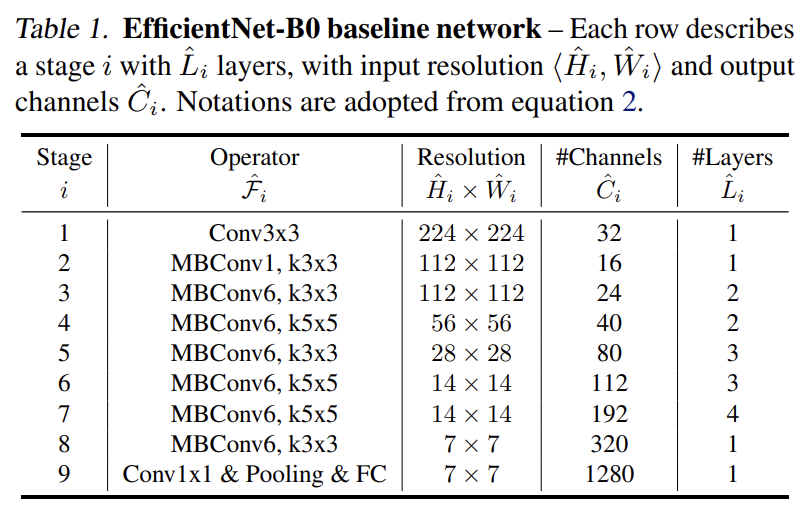
baseline EfficientNet-B0에서 시작해 두 단계로 compound scaling method를 적용했다.

large model에서 직접 α, β, γ를 찾는 식으로 더 좋은 성능을 얻을 수도 있겠지만 search cost가 엄청 클 것이다. 논문은 대신 step 1에서 작은 baseline network에서 search를 한 번 하고 step 2에서 동일한 scaling coefficients를 다른 모든 models에 사용한다.
실험으로 논문은 먼저 MobileNets와 ResNets에 scaling method를 적용해본다. 다른 single-dimension scaling method와 달리 compound scaling method는 모든 model에서 accuracy를 향상시킨다.
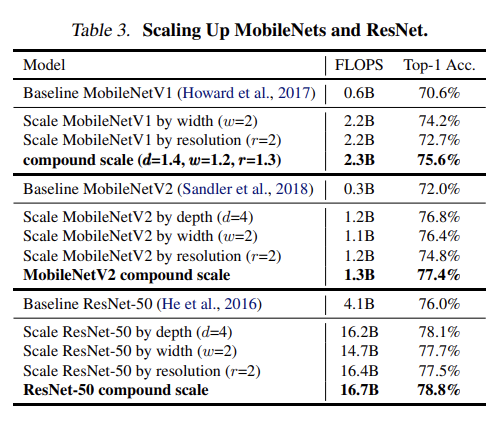
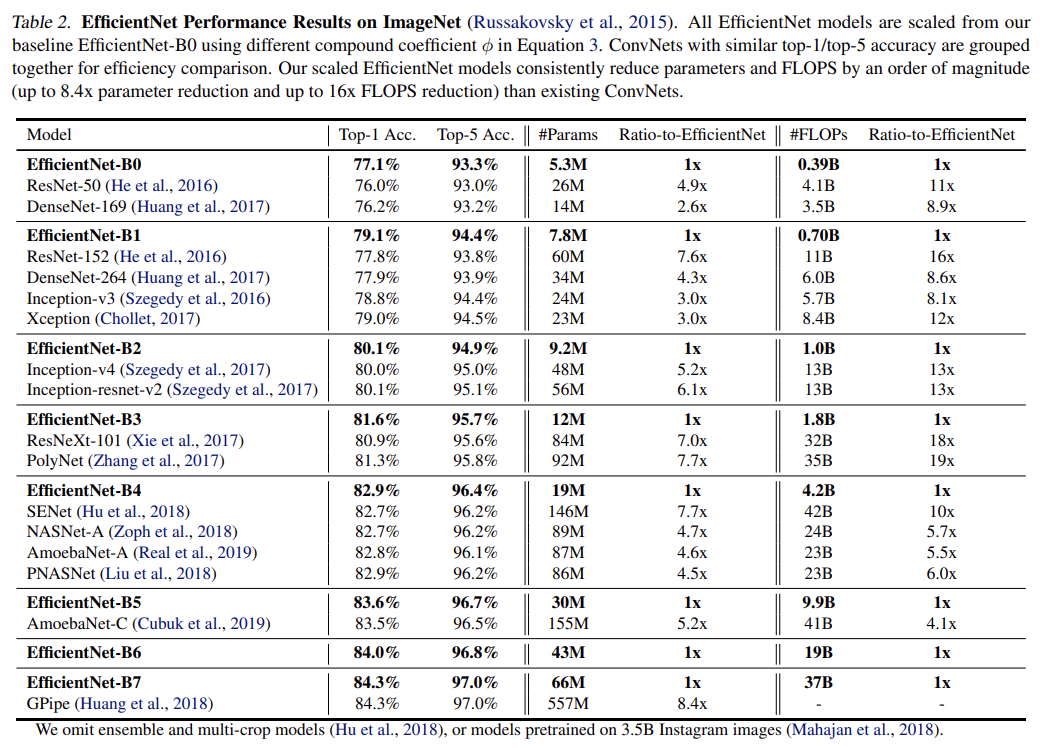
Table 2를 보면 EfficientNet이 다른 ConvNet보다 자릿수가 적은 parameters와 FLOPS를 사용하면서 비슷한 accuracy를 얻음을 볼 수 있다.

latency를 validate하기 위해 real CPU에서 few representative CovNets에 대해 inference latency를 측정했다. EfficientNet-B1은 ResNet-152보다 5.7배 빨랐고 EfficientNet-B7은 GPipe보다 6.1배 빨랐다.
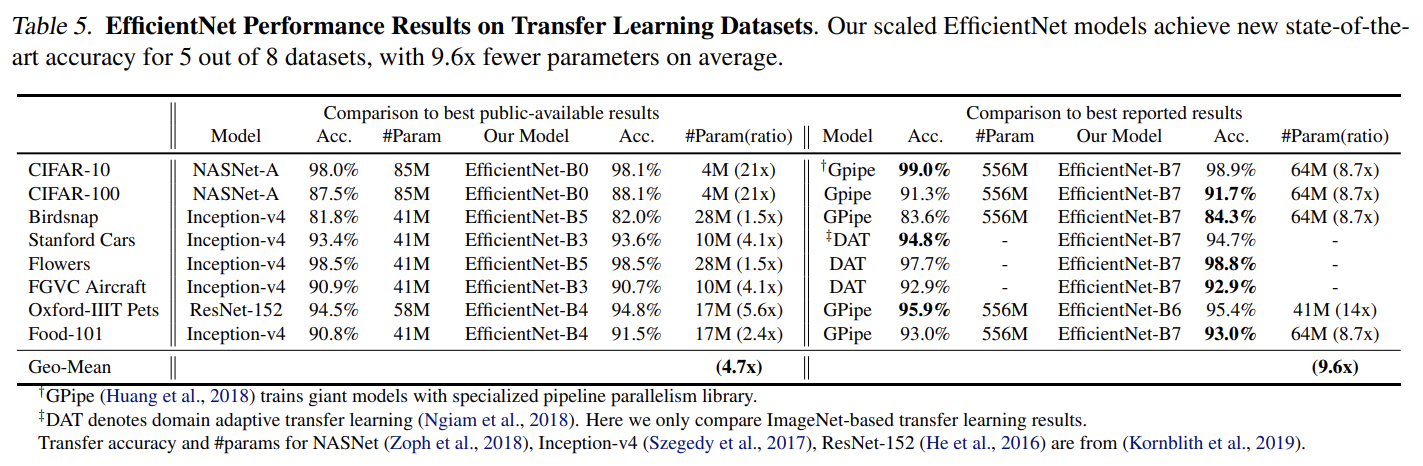
EfficientNet을 transfer learning dataset에 실험하기도 했다. 설명은 생략한다.
Strengths
- 아이디어가 굉장히 간단하고 강력하다.
- model을 scaling up하는 데 있어서 depth/width/resolution 하나만 조절하는 것보다 복합적으로 조절하는 것이 더 좋은 이유를 직관적으로 설명하고 compound coefficient scaling method를 식으로 제시해 성능을 실험으로 증명했다.
- 아이디어가 단순하다보니 여러 모델에 범용적으로 적용 가능한 방법 같다.
