오늘 리뷰할 논문은 Facebook AI Research (FAIR)의 FLAVA 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
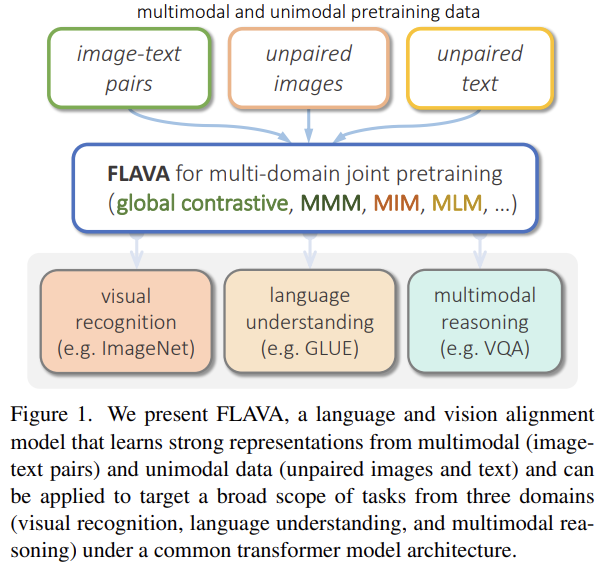
SOTA vision/vision-and-language models은 여러 downstream task에서 좋은 성능을 얻기 위해 large-scale visio-linguistic pretraining에 의존한다. 일반적으로 그런 모델들은 cross-modal (contrastive)하거나 multi-modal (with earlier fusion)하지만 둘 다는 아니다. 또 그들은 보통 특정 modalities나 task만을 target한다. 유망한(promising) 방식은 single holistic universal model을 모든 modalities를 한 번에 target하는 "foundation"으로 사용하는 것이다(진정한 vision and language foundation model은 vision tasks, language tasks, cross- and multi-modal vision and language tasks 모두에 좋아야 한다). 논문은 그런 모델으로 FLAVA를 소개한다.
CLIP, ALIGN 같은 constrastive models은 natural language supervision이 고품질 visual models을 만들 수 있음을 보였다. 그러나 순수히(purely) contrastive methods는 중요한 단점이 있다. 그들의 cross-modal nature은 두 modalities를 동시에 다루기를 요구하는 multimodal problems에 쉽게 사용할 수 없다는 것이다.
반면 최신 문헌들은 earlier fusion과 shared selfattention across modalities을 가짐으로써 multimodal vision-and-language domain를 명시적으로 target하는 transformer models이 풍부하다. 그러나 이런 경우는 unimodal vision-only나 language-only performance가 별로다.
만약 이 분야의 미래가 많은 능력을 가진 generalized “foundation models”나 “universal” transformers에 있다면 다음 한계가 극복되어야 한다. vision과 language space의 진정한 foundation model은 vision이나 language이나 vision-and-language problems 하나에만 성능이 좋은 게 아니라 셋 모두에 동시에 좋아야 한다.
여러 modalities의 정보를 하나의 universal architecture로 조합하는 것은 유망한데, 단지 사람이 세계를 인지하는 방법과 비슷하기 때문만이 아니라 더 좋은 sample efficiency와 더 풍부한 representation을 얻기 때문이다.
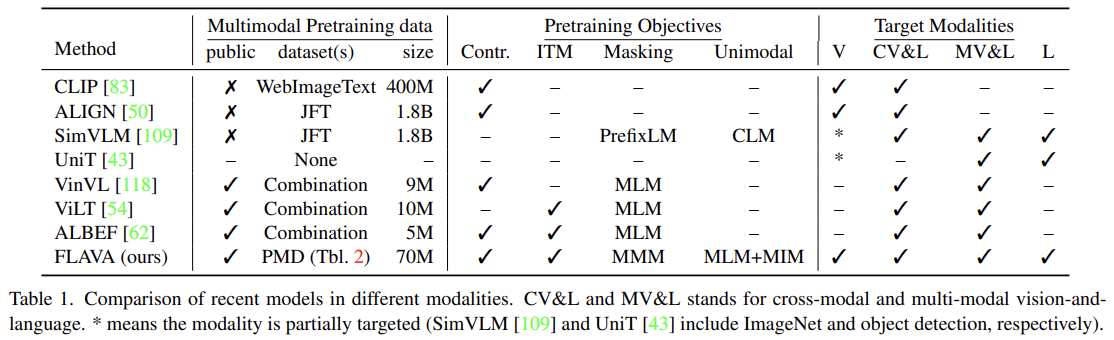
논문은 vision, language와 그들의 multimodal combination을 한 번에 명시적으로 target하는 FLAVA (foundational language and vision alignment model)를 소개한다. FLAVA는 unimodal과 multimodal data 둘 모두에 joint pretraining을 통해 강한 representation을 배우는 한편 cross-modal “alignment” objectives와 multimodal “fusion” objectives를 포함한다(encompass). FLAVA를 vision, NLP, multimodal domains에 걸친 35 tasks에 적용해 인상적인 성능을 보인다. 이 방식의 중요한 장점은 (CLIP이나 ALIGN과 달리) openly available datasets의 corpus에 학습되었고 데이터셋이 comparable models에 사용된 datasets보다 order of magnitude 작다는 것이다.
일반적으로 vision-and-language space의 model들은 두 종류로 분류된다. 첫째는 image와 text가 따로 encode된 후 downstream task를 위한 shallow interaction layer를 거치는 dual encoders고 둘째는 modalities에 걸쳐 self-attention spanning을 가지는 fusion encoder다. dual encoder 방식은 unimodal과 cross-modal retrieval tasks에 잘 작동하지만 fusion이 부족하기 때문에 보통 (fusion encoder 기반 모델이 활약하는) visual reasoning과 question answering 같은 task에 약하다.
fusion encoder도 두 종류로 구분할 수 있는데, modalities 간 early and unconstrained fusion을 위해 single transformer을 사용하는 모델과(VisualBERT, UNITER, VLBERT, OSCAR 등) 특정 co-attention transformer layers에서만 cross-attention을 허용하고 몇 modality specific layers를 가지는 모델이(LXMERT, ViLBERT, ERNIE-ViL 등) 있다.
dual encoder models는 N^2 가능성 중에 올바른 N 쌍의 조합을 예측하기 위해 contrastive pretraining을 사용한다. 반면 fusion encoders을 가지고는, masked language modeling, masked image modeling, causal language modeling 같은 unimodal pretraining schemes에서 영감을 받아 다양한 pretraining task가 탐구되었다.
FLAVA는 dual, fusion encoder 방식을 조합해 (양쪽 encoder 카테고리의 pretraining objectives를 leverage하는) 새로운 FLAVA pretraining scheme으로 pretrain할 수 있는 하나의 holistic model을 만든다. FLAVA는 unpaired unimodal data와 multimodal paired data를 모두 활용할 수 있어 unimodal, retrieval tasks뿐 아니라 cross-modal, multimodal vision-and-language tasks도 다룰 수 있다.
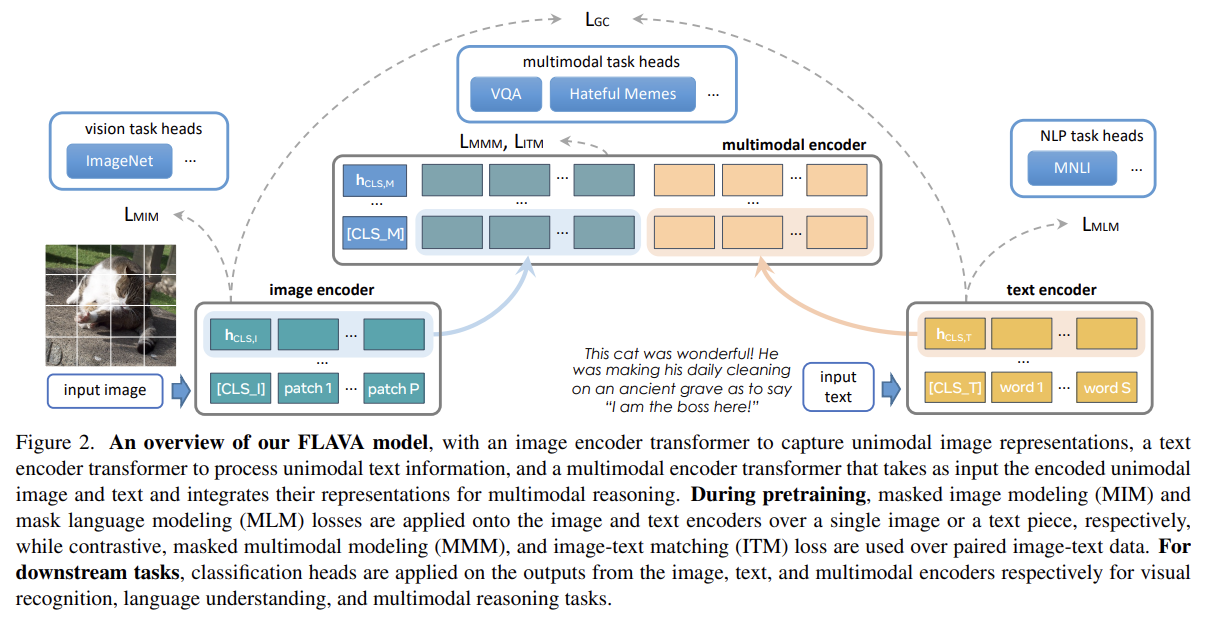
FLAVA는 unimodal image representation을 추출하기 위해 image encoder을 포함하고 unimodal text representation을 추출하기 위해 text encoder을 포함하고 multimodal reasoning을 위한 image representation과 text representation을 fuse하고 align하기 위해 multimodal encoder을 포함한다. 셋 모두 transformer을 기반으로 한다.
image encoder는 ViT architecture을 채택했다. 구체적으로는 ViT-B/16을 사용했다. 주어진 input image를 fixed image size로 resize하고 image를 patches로 split해서 patches를 linearly embed하고 (positional embeddings와 extra image classification token [CLS_I]와 함께) transformer model에 먹인다. image encoder output은 (각각이 각 image patch에 상응하는) image hidden state vectors {}의 list에다가 [CLS_I]에 대한 추가적인 을 덧붙인 것이다.
text encoder는 (sentence나 pair of sentences 같은) input piece of text가 주어지면 먼저 이를 tokenize하고 BERT 논문을 따라 list of word vectors로 embed한다. 다음으로 word vectors에 transformer model을 적용해 (text classification [CLS T] token에 대한 를 포함하는) list of hidden state vectors {}로 encode한다. 중요한 점은 기존 연구와 달리 FLAVA의 text encoder가 visual encoder와 동일한 architecture을 가진다는 것이다. 즉, text encoder도 ViT-B/16을 사용한다. (당연히 visual encoder와 text encoder의 parameter은 별개다)
image와 text hidden states을 융합하기 위해 독립적인(separate) transformer을 사용한다. 구체적으로는 Fig 2처럼 {}와 {} 내의 각 hidden states에 대해(over) 2 learned linear projections을 적용하고 그들을 single list로 concatenate하고 additional [CLS M] token도 덧붙인다. 이 concatenated list는 (마찬가지로 ViT에 기반한) multimodal encoder transformer에 넣어져 projected unimodal image와 text representation 사이 cross-attention을 허용하고 두 modalities를 융합한다. multimodal encoder의 output은 (각각이 {}, {}, [CLS_M]에 대한 vector 에서 온 unimodal vector에 상응하는) list of hidden states {hM}이다.
FLAVA는 간단한 방법으로 unimodal과 multimodal tasks 모두에 적용할 수 있다. (ImageNet classification 같은) visual recognition
tasks는 image encoder에서 unimodal 꼭대기에 (linear layer나 multi-layer perceptron 같은) classifier head을 적용한다. 비슷하게 language understanding과 multimodal reasoning tasks에는 각각 text encoder에서 와 multimodal encoder에서 꼭대기에 classifier head를 적용한다. 논문은 FLAVA를 한 번 pretrain하고 각 downstream task에 따로 평가한다.
multimodal data (paired image and text)와 unimodal data (unpaired images or text) 모두에 pretraining해서 강한 representation을 얻고자 한다. FLAVA pretraining은 다음과 같은 multimodal objectives를 포함한다.
- Global contrastive (GC) loss
FLAVA의 image-text contrastive loss는 CLIP의 것을 닮았다. images와 text의 batch가 주어졌을 떄, matched image and text pairs 사이 cosine similarities를 최대화하고 unmatched pairs 사이 cosine similarities를 최소화한다. 이는 와 를 각각 (하나의) embedding space로 linearly project하고 차례로 L2-normalization, dot-product, temperature로 scale된 softmax loss를 적용함으로써 성취된다.
large models는 보통 multiple GPUs data parallelism을 사용해 학습되는데, batch 내의 samples이 GPU들에 쪼개지는(split across) 것이다. image와 text contrastive objective를 위해 embeddings을 모을 때는 open-source CLIP implementation는 contrastive loss의 gradients만 (dot-product가 수행되는 local GPU에서 온) embeddings로 역전파한다. 반면 논문은 실험을 통해 역전파를 locally하는 것보다 GPUs에 걸친(across) full backpropagation에서 뚜렷한 성능 인상을 발견했다. 논문은 이 loss를 "local contrastive" 방식과 구분하기 위해 "global contrastive" 라고 이름 붙였다.
- Masked multimodal modeling (MMM)
기존의 여러 vision-and-language pretraining 방식이 (multimodal input로부터 masked tokens을 재구성함으로써) text modality의 masked modeling에 집중했다. 그러나 그들은 대부분 (end-to-end manner로 image pixel level에서 직접) image modality에 masked learning을 포함하지 않는다. 논문은 image patches와 text tokens 모두를 mask하고 양쪽 modalities에서 공동으로 동작하는 새로운 masked multimodal modeling (MMM) pretraining objective 을 도입한다.
구체적으로는 image와 text input이 주어졌을 때, 먼저 (word dictionary와 비슷한) visual codebook 내의 index로 각 image patch를 map하는 pretrained dVAE tokenizer을 사용해 input image patches를 tokenize한다. 다음으로 BEiT를 따라 rectangular block image regions에 기반한 subset of image patches와 BERT를 따라 15%의 text tokens를 special [MASK] token로 대체한다. 다음으로 multimodal encoder의 output {}에서 masked image patches의 visual codebook index을 예측하거나 masked text tokens에서 word vocabulary index를 예측하기 위해 multilayer perceptron을 적용한다.
이 objective는 multimodal masked language modeling의 확장형이라 볼 수 있다. 실험을 통해 논문은 MMM pretraining이 특히 VQA 같은 multimodal downstream tasks에서 multimodal downstream tasks을 넘어 추가로 성능을 향상시킴을 발견했다. 이때 image patches와 text tokens에 masking 없이, MMM loss와 별개로 image와 text encoders을 통해 순전파되어 global contrastive loss를 적용함에 주의하라.
- Image-text matching (ITM)
마지막으로 앞선 vision-and-language pretraining 연구를 따라 image-text matching loss 을 추가한다. pretraining 도중 matched와 unmatched image-text pairs를 모두 포함하는 batch of samples를 먹인다. 그리고 multimodal encoder에서 꼭대기에 input image와 text가 서로 match하는지 결정할 classifier을 적용한다.
앞선 세 loss들이 FLAVA가 paired image-and-text data에 pretrain할 수 있게 허용하지만 대다수 방대한 dataset은 다른 modality로부터의 paired data가 없이 unimodal하다. 다양한 downstream tasks을 위한 representation을 효과적으로 배우기 위해 이 데이터셋을 활용해 unimodal, unaligned information을 representation에 통합하고 싶다.
논문은 이를 위해 1. 먼저 image encoder와 text encoder를 unimodal datasets에 pretrain하거나 2. entire FLAVA model을 unimodal, multimodal datasets 모두에 공동으로 pretrain하거나 3. 두 방법 모두 사용해 pretrained encoders에서 시작해 jointly training하는 방식을 사용한다. stand-alone(=unimodal) image나 text data에 적용되었을 때 image와 text encoders 각각에서 masked image modeling (MIM)와 masked language modeling (MLM) losses를 채택한다.
- Masked image modeling (MIM)
unimodal image datasets에서 BEiT의 rectangular block-wise masking를 따라 set of image patches를 mask하고 다른 image patches로부터 그들을 재구성한다. input image가 먼저 (MMM objective에서 사용된 것과 동일한) pretrained dVAE tokenizer를 사용해 tokenize되고 masked patches의 dVAE tokens를 예측하기 위해 image encoder outputs {}에 classifier가 적용된다.
- Masked language modeling (MLM)
stand-alone text datasets에 pretrain하기 위해 text encoder 꼭대기에 masked language modeling loss를 적용한다. 15%의 text tokens이 input에서 mask되고 unimodal text hidden states output {}에 대한 classifier을 사용해 다른 tokens로부터 재구성된다.
- Encoder initialization from unimodal pretraining
pretraining을 위해 3 종류 source의 data를 사용한다. unimodal image data (ImageNet-1K [90]), unimodal text data (CCNews [68] and BookCorpus [121]), 그리고 multimodal image-text paired data이다. 먼저 unimodal text dataset에 MLM objective를 사용해 text encoder를 pretrain한다. image encoder를 pretrain할 때는 다양한 방법을 실험해 봤다. (unimodal과 multimodal datasets 모두에 joint training하기 전에) unpaired image datasets에 MIM이나 DINO objective를 가지고 image encoder를 pretrain했는데, 초기화 이후에 (joint training에서) MIM objective로 바꾸더라도 경험적으로 DINO가 더 잘 작동했다. 다음으로 전체 FLAVA model을 2 respective unimodally-pretrained encoders을 가지고 초기화했고 혹은 밑바닥에서부터 학습을 시작할 때는 랜덤하게 초기화했다. pretraining에서 multimodal encoder는 항상 랜덤하게 초기화했다.
- Joint unimodal and multimodal training
image와 text encoders의 unimodal pretraining 후에 전체 FLAVA model을 3 종류 데이터셋에 round-robin sampling를 가지고 공동으로 학습시켰다. 각 training iteration에서 경험적으로 결정하는 sampling ratio에 따라 dataset을 선택하고 batch of samples을 얻는다. 그 다음 dataset 종류에 따라 image data에는 unimodal MIM을, text data에는 unimodal MLM을, image-text pairs에는 multimodal losses (contrastive, MMM, ITM)을 적용한다.
(Implementation details 생략)
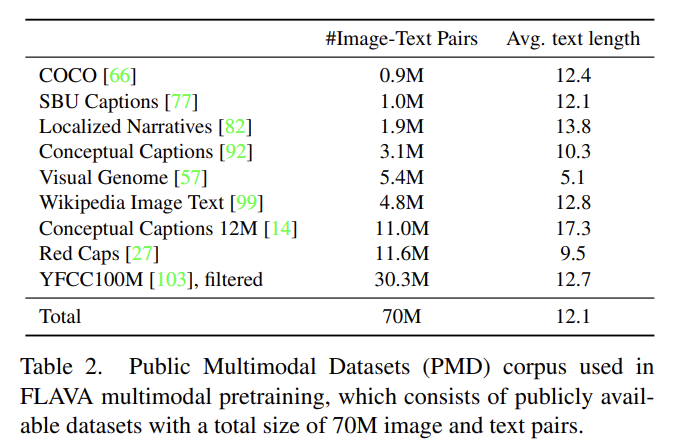
- Data: Public Multimodal Datasets (PMD)
multimodal pretraining을 위해 publicly available한 image-text data로 corpus를 구성했다. 이하 설명은 생략한다.

FLAVA를 22 common vision tasks, NLP는 GLUE benchmark에서 8 tasks, multimodal은 VQAv2 [39], SNLI-VE [114], Hateful Memes [53], Flickr30K [81], COCO [66] image and text retrieval에 실험한다. Tab 3, 4에서 joint pretraining method을 다른 setting과 비교한다.
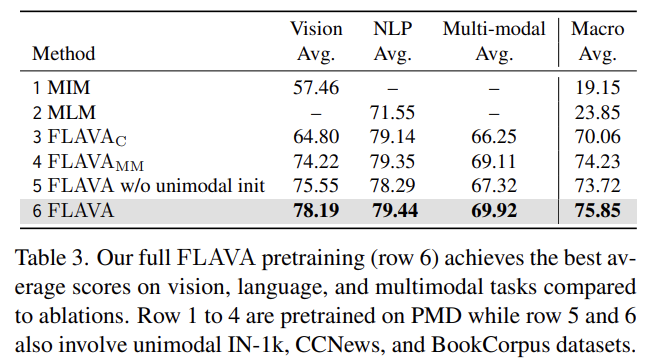
- Full FLAVA pretraining achieves the best results
Tab 3이 FLAVA baseline과 다양한 ablation setting을 보여준다. unimodal MIM과 MLM losses로 학습된 모델, image-text contrastive loss로만 학습된 FLAVA_C, multimodal data로만 학습된 FLAVA_MM, unimodal initialization이 없는 모델과 full 모델이다. full FLAVA model이 다른 모든 setting을 능가한다.
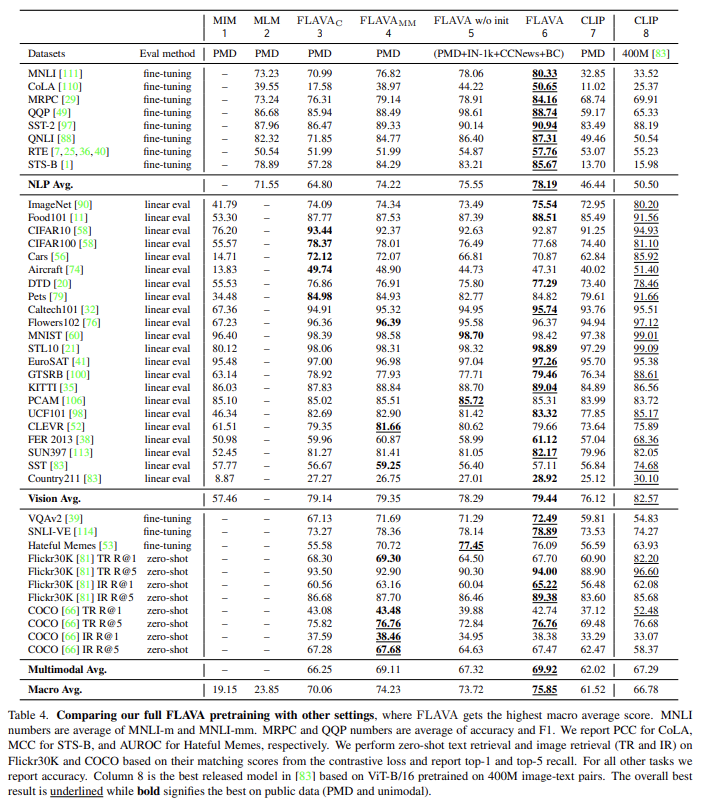
- Effective global contrastive loss in FLAVA
다음으로 Tab 4에서 step-by-step ablation을 한다. 먼저 multimodal data에 global contrastive loss L_GC만 사용한 FLAVA_C다. 이 restricted setting은 마찬가지로 contrastive loss을 포함하는 CLIP과 개념적으로 비슷한 모델인데, 동일한 PMD 데이터로 학습되고 동일한 ViT-B/16 image encoder를 baseline으로 사용한 CLIP과 비교한다. 표의 3열과 7열을 비교하면 가 모든 vision, language, multimodal domains에서 성능이 더 좋음을 볼 수 있다. 이는 두 요인으로 설명할 수 있는데, text encoder hidden size 같이 CLIP과 다른 FLAVA의 model details과 앞서 언급한 것처럼 global back-propagation을 모든 GPU workers에 걸쳐 수행한 것 때문이다. 더 자세한 분석에서 후자가 작은 연산 overhead만을 가지고 vision, NLP, and multi-modal tasks의 macro average을 +1.65% 향상시킴을 발견했다. 이는 contrastive loss에서 global back-propagation implementation이 중요함을 보여준다.
- MMM and ITM objectives benefit multimodal tasks
다음으로 다른 multimodal objectives도 포함해서 , 을 와 함께 사용한다. FLAVA_C에 비해 FLAVA_MM은 multimodal average score을 +2.86%, NLP average score을 +9%, vision average score을 +0.3% 향상시킨다.
추가로 FLAVA_MM을 MIM loss만 또는 MLM loss만 사용한 세팅과 비교한다. FLAVA_MM과 MIM, MLM을 크게 능가했는데 이는 combined multimodal objectives (contrastive, MMM, ITM)이 FLAVA가 unimodal과 multimodal downstream tasks 양쪽 모두에 대한 강력한 representation을 배울 수 있게 함을 나타낸다.
- Joint unimodal & multimodal pretraining helps NLP
full FLAVA pretraining을 위해 unimodal image data는 ImageNet-1k (IN-1k)에서 도입하고 text data는 CCNews와 BookCorpus (BC)에서 도입했다. 이 세팅에서 FLAVAMM losses 을 PMD data batches에, MIM loss를 IN-1k unimodal image data에, MLM loss를 CCNews text data에 적용해 Tab 4 5열에 표현했다. multimodal pretraining만 한 4열의 FLAVA_MM과 비교해 이 joint unimodal and multimodal pretraining은 NLP average score을 74.22에서 75.55로 향상시킨다. 이는 CCNews와 BookCorpus에서 온 추가적인 text data가 MLM objective을 통해 언어 이해에 도움이 됨을 의미한다.
그러나 4열과 5열의 비교에서 또한 모든 tasks의 macro average가 약간 감소한다. 이는 objective 조합(mix)에 다른 task를 추가하는 것이 특히 전체 모델이 랜덤하게 초기화되었을 때 optimization problem을 어렵게 만들기 때문으로 추측된다. 또 round-robin sampling은 tasks의 learning sequence를 order하는 특정 커리큘럼을 따르지 않는다. multimodal task를 배우기 전에 vision과 language에 어느 정도 이해를 가지는 것이 더 자연스럽다. 이는 바로 밑에서 기술할 것처럼 joint training 이전에 먼저 unimodal pretraining을 leverage하도록 동기를 부여한다.
- Better image and text encoders via unimodal pretraining
joint training 전에 unimodal learning을 leverage하기 위해 vision과 language encoder 모두에 대한 pretrained self-supervised weights로 모델을 초기화한다. vision encoder는 ImageNet-1k로 pretrain된 off-the-shelf DINO model로부터 초기화한다. language encoder는 MLM loss를 가진 ViT 모델을 CCNews와 BookCorpus datasets에 pretrain해서 weight을 사용한다. 표의 5열과 6열을 비교하면 pretrained encoders가 모든 task에서 FLAVA의 성능을 향상시킴을 알 수 있다. 경험적으로 BEiT self-supervised model보다 DINO self-supervised model로부터 vision encoder를 초기화하는 것이 더 좋은 성능을 보였다.
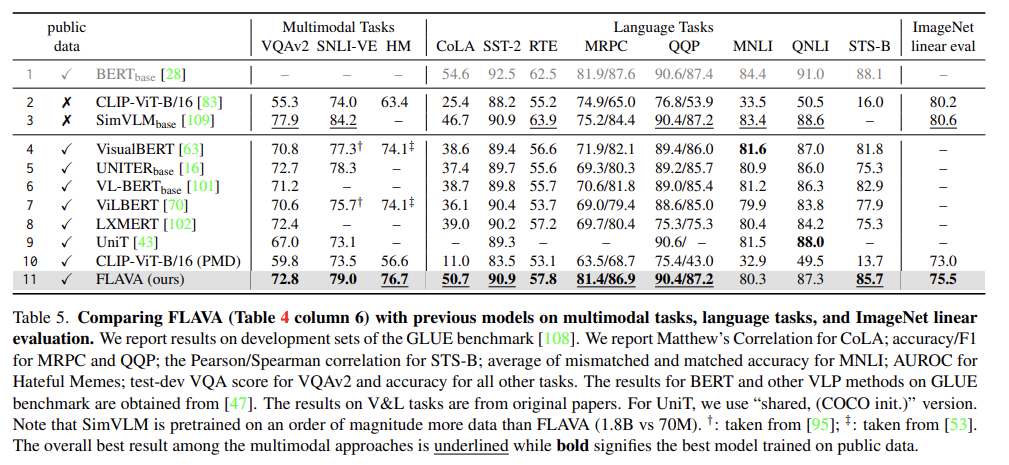
Tab 5에서 full FLAVA model을 multimodal tasks, language tasks, ImageNet linear evaluation에 여러 SOTA 모델과 비교한다. FLAVA는 public data에 pretrain된 4-11행의 모델을 language와 multimodal tasks 모두 크게 능가하고 well-established BERT model를 여러 GLUE task에서 근접한다.
best released CLIP [83] ViT-B/16 model도 2행에서 평가한다. CLIP에 비해 FLAVA는 약 6배 작은 70M data에 학습한다. Fig 4는 FLAVA가 CLIP보다 language와 multimodal tasks에서 상당히 잘 작동하고 몇 vision-only tasks에서 성능이 약간 나쁨을 볼 수 있다. 추가로 FLAVA는 PMD dataset에만 학습된 CLIP보다 성능이 좋았다.
또한 FLAVA는 Tab 5 3행의 SimVLM와 language tasks에서 비교할 만한 성능을 가지며 multimodal tasks와 ImageNet linear evaluation에서는 성능이 나쁘다. FLAVA는 SimVLM의 1.8B image-text pairs보다 훨씬 작은 데이터셋으로 pretrain되었고 pretraining 데이터셋 크기가 커지면 FLAVA 성능도 향상될 것으로 기대된다.
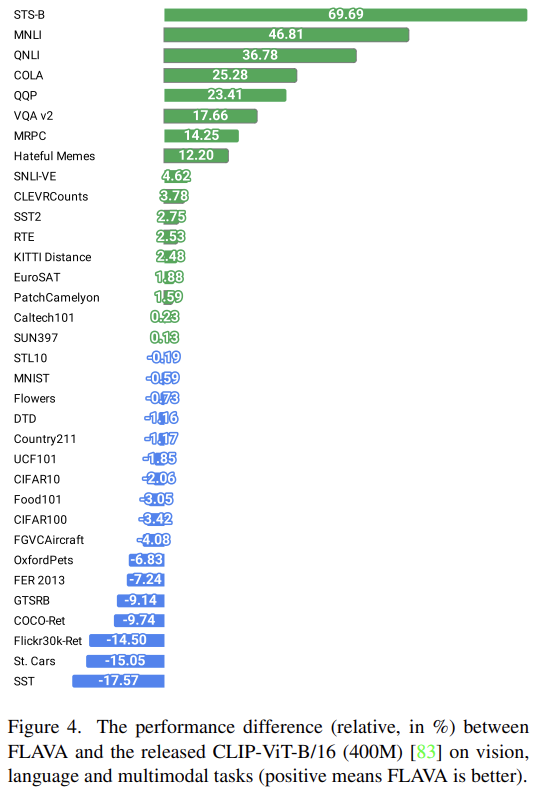
Strengths
- 모델이 vision이나 language이나 vision-and-language problems 하나에만 성능이 좋은 게 아니라 셋 모두에 동시에 좋아야 한다는 근본적인 목표와 포부가 좋았다.
- image와 text 정보를 조합하는 multimodal encoder를 image encoder, text encoder와 별개로 만든 구조가 좋았다. 덕분에 순수한 image encoder와 text encoder의 output도 objective에 사용할 수 있었다.
- 적은 dataset 크기로 SOTA와 경쟁적인 성능을 낼 수 있다.
Weaknesses
- objective이 너무 많은 것 같다. 논문에서 언급한 것처럼 이를 balance해서 optimize하는 것이 많이 힘들 것 같다.
별개로 나는 평소에 modality마다 encoder가 따로 있고, 그 결과물을 하나의 space에서 조합하는 방식이 맞다고 생각했기 때문에 이 방법이 마음에 들었다. 음성처럼 다른 새로운 modality가 들어올 때 추가로 덧붙일 수도 있기 때문이다. 인간의 뇌도 그렇게 작동하지 않을까.
또 multi-modal과 cross-modal의 차이도 알게 됐다. 챗gpt 선생님한테 물어보니 multi-modal은 여러 유형의 데이터를 다루는 것이고 cross-modal은 여러 유형의 데이터 간 상호작용이나 연결을 강조하는 것이라서 cross-modal이 multi-modal의 일종에 속했다. 예를 들어 텍스트와 이미지를 받아 감정분석을 하는데 이들의 통합이나 상호작용보다는 단순히 각 모드에서 얻은 정보를 분석하면 multi-modal은 맞지만 cross-modal은 아니다.
