
오늘 리뷰할 논문은 R-CNN의 발전형인 R-CNN이다. R-CNN의 단점이었던 속도를 개선하고 정확도도 향상시켰다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
논문은 classify object proposals와 refine spatial locations를 동시에 학습하는 single-stage training algorithm을 제안한다.
논문은 기존 R-CNN의 단점을 세 가지로 제시한다.
- training이 multi-stage pipeline인 것
- training이 space, time적으로 expensive한 것
- object detection이 느린 것
이는 R-CNN의 각 object proposal이 연산을 공유하지 않고 따로 convnet을 수행하기 때문이다. 또 SPPnet도 R-CNN처럼 training이 multi-stage pipeline이라는 점, feature이 disk에 저장된다는 점, fine-tuning algorithm이 spatial pyramid pooling에 선행하는 convolution layer을 update할 수 없다는 단점이 있다.
그래서 Fast R-CNN은 두 모델의 단점을 고치고 속도와 정확도를 향상시킨다. Fast R-CNN은 다음과 같은 장점이 있다.
- R-CNN, SPPnet보다 더 높은 detection quality (mAP)
- multi-task loss를 사용하여 training이 single-stage
- training이 모든 layer를 update 가능
- feature caching을 위한 disk storage가 불필요
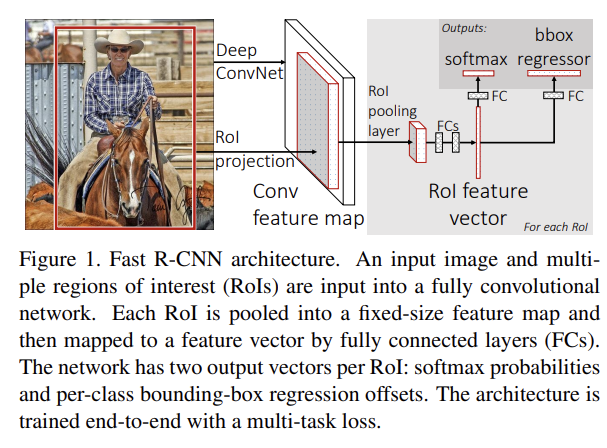
Fig 1은 Fast R-CNN의 architecture이다. 전체 이미지와 set of object proposal을 input으로 넣고, 전체 이미지를 network에 넣어서 feature map을 만든다. 그 후 각 object proposal에 대해 region of interest (RoI) pooling layer이 feature map에서 fixed-length feature vector를 추출한다. 각 feature vector은 FC layer에 넣어져서 K object class + 1 background 확률을 계산하는 softmax 층과 bounding box position을 계산하는 층으로 산출된다.
RoI pooling layer은 max pooling을 사용해 RoI 내의 feature을 고정된 H x W 크기의(H, W는 hyperparameter) 작은 feature map으로 변환한다. RoI는 four-tuple (r, c, h, w)으로 명시되고 r, c는 top-left corner이며 h, w는 height, width이다.
RoI max pooling은 h × w RoI window를 h/H × w/W 크기의 H × W grid of sub-windows로 분할해 각 sub-window에서 max pooling을 하는 것이다. pooling은 각 채널마다 독립적으로 적용된다. RoI pooling은 SPPnet의 spatial pyramid pooling layer의 특수한 경우라고 볼 수 있다.
실험은 ImageNet으로 pre-train된 networks를 사용하며 pre-trained network로 Fast R-CNN을 initialize할 때 3가지 변형이 적용된다. 첫째로 마지막 max pooling layer이 RoI pooling layer로 바껴 첫 FC layer에 호환 가능한 H, W로 맞춰준다. 둘째로, 마지막 FC layer와 softmax layer가 앞서 말한 두 자매 layer(softmax, boundig box regressor)로 대체된다. 셋째로, network가 2종류 input, list of images와 list of RoIs를 받도록 변경된다.
논문은 SPPnet과 달리 training 도중 feature sharing의 이점을 취할 수 있는 효율적인 training 방법을 제시한다. SGD minibatch를 hierarchically sample하는데, 먼저 N images를 sample한 후 각 image마다 R/N RoI를 sample한다. 같은 image에서 온 RoI는 forward, backward pass에서 같은 연산과 메모리를 공유한다. 하지만 한 가지 걱정되는 문제는 같은 image에서 온 RoI들이 서로 연관되어 있기 때문에 training convergence가 느려질 수 있다는 것인데, 실제로 해 보니 practical issue는 없었다고 한다.
그리고 Fast R-CNN은 하나의 fine-tuning stage를 가진 streamlined training process를 해서 세 단계로 softmax classifier, SVMs, regressors를 학습하는 대신 softmax classifier와 bounding-box regressors를 동시에 학습한다.
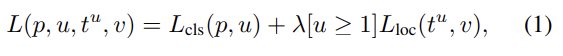
Fast R-CNN은 multi-task loss를 사용한다. 는 discrete probability distribution, 는 k object class의 bounding-box regression offsets이다. t^k는 scale-invariant translation와 object proposal에 상대적인 log-space height/width shift를 명시한다. u는 ground-truth class, v는 ground-truth bounding-box regression target이다.
는 true class u에 대한 log loss이고 은 true bounding-box regression target(v)와 predicted tuple(t)를 비교하는 것이다. Iverson bracket indicator function [u ≥ 1]는 u ≥ 1일 때 1이 되고 아니면 0이다. 관습에 따라 catch-all background class는 0이 된다. 즉 background RoI은 ground-truth bounding box가 없으니 L_loc항을 무시한다는 것이다.
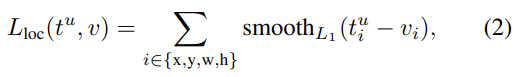
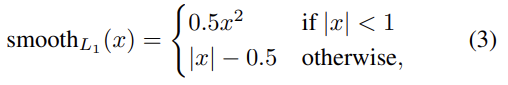
smooth는 robust L1 loss로 R-CNN과 SPPnet에 사용된 L2보다 outlier에 대해 덜 민감하다. lambda는 두 loss 항의 밸런스를 조절하는 hyperparameter인데 실험에서는 모두 lambda=1을 썼다. 그리고 ground-truth regression targets v_i가 zero mean과 unit variance를 가지게 normalize했다.
scale invariant object detection을 위해 2가지 방법을 사용한다. 첫째는 brute-force learning으로, training과 testing 모두에서 각 이미지가 pre-defined pixel size로 처리되고 network는 training data로부터 직접 scale-invariant object detection를 학습해야 한다. 둘째는 image pyramids를 사용한 multi-scale approach이다. test time에는 각 object proposal을 approximately scale-normalize하기 위해 image pyramid를 사용하고 multi-scale training시에는 data augmentation의 형태로 image가 sample될 때마다 랜덤하게 pyramid scale을 sample한다.
test time에 각 test RoI r에 대해 forward pass는 class posterior probability distribution p와 r에 상대적인 set of predicted bounding-box offsets를 생산한다. 즉, k개의 class 각각이 저마다 refined bounding-box prediction를 가진다는 것이다. 그리고 각 class마다 non-maximum suppression를 수행한다.
여러 RoI에 대해 FC layer을 연산하는 것은 conv layer에 비해 오래 걸린다. truncated SVD를 써서 large FC layers를 압축하여 속도를 올릴 수 있다. 아래와 같은 u x v weight matrix W를 top t singular values만 선택하여 u x t U, t x t , v x t V로 분해할 수 있다.

Truncated SVD는 parameter 수를 uv에서 t(u+v)로 줄일 수 있는데, t가 min(u, v)보다 훨씬 작으면 연산량을 상당히 줄일 수 있다. 이를 통해 network를 압축하려면 W에 해당하는 하나의 FC layer을 중간에 non-linearity가 없는 2개의 FC layer로 대체하면 된다. 첫번째 층은 bias 없이 weight matrix 가 되고 두번째 층은 W의 원래 bias를 가지며 U가 된다. 이러면 RoI 개수가 많을 때 속도 향상이 뛰어나다.
논문의 주요 성과는 다음과 같다.
- VOC07, 2010, 2012에서의 State-of-the-art mAP
- R-CNN, SPPnet에 비해 빠른 training과 testing
- VGG16에서 Fine-tuning conv layers의 mAP 향상
실험 결과에서 흥미로웠던 부분은 앞서 언급한 scale invariance를 취득하는 두 가지 방법을 비교한 것이다. 놀랍게도 깊은 convnet은 brute-force 방법으로 scale invariance를 잘 학습했고, multi-scale approach는 크게 늘어난 연산 시간에 비해 mAP는 조금밖에 오르지 않았다. single-scale processing이 tradeoff가 더 좋았기 때문에 이후 실험에도 single-scale training을 사용했다.
또 논문은 SVM과 softmax의 성능도 비교한다. Fast R-CNN은 R-CNN, SPPnet과 달리 one-vs-rest linear SVMs를 학습하는 대신 fine-tuning 도중 학습되는 softmax classifier를 사용한다. 실험 결과 SVM에 비해 softmax의 mAP 향상은 작았지만, 대신 기존의 multi-stage training approach 대신 “one-shot” fine-tuning이 충분하다는 것을 입증한 데 의의가 있다. one-vs-rest SVMs과 달리 softmax는 RoI를 scoring할 때 class 간 competition도 촉진하는 효과도 있다.
그리고 논문은 selective search’s quality mode를 사용해 region proposal의 숫자가 클수록 정확도도 높아지는지 실험헀다. 놀랍게도 proposal이 증가할수록 mAP은 올라가다가 나중엔 약간 감소했다.
Strengths
- 이름처럼 R-CNN보다 수백 배 빠르다.
- 단계를 나누는 대신 multi-task training으로 속도와 정확도 향상 두 마리 토끼를 모두 잡았다.
SVD를 사용해 약간의 정확도를 포기하고 속도를 향상한 게 인상적이었다. 수업 시간에 배운 원리를 실제 기술에 적용한 걸 보니 흥미로웠다.
