
오늘 리뷰할 논문은 Feature Pyramid Network (FPN) 논문이다. Mask R-CNN에 FPN이 쓰인다고 하여 먼저 읽게 되었다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
Summary
Feature pyramids built upon image pyramids (= featurized image pyramids)는 object recognition에서 다양한 scale의 사물을 인식하는 기본적인 방법이다.
scale이 다른 image pyramid의 각 층(level)에서 feature을 뽑아 high-resolution levels을 포함한 모든 층이 semantically strong한 multi-scale feature representation을 얻을 수 있다.
하지만 inference time이 상당히 증가하여 실사용하기엔 부적절하고, deep network를 end-to-end로 학습하기에는 메모리 측면에서 실현 불가능하다. 만약 학습한다고 해도, image pyramid는 test time에만 사용되서 train/test-time inference 사이에 불균형을 초래한다.
image pyramid가 multi-scale feature representation을 얻는 유일한 방법은 아니다. deep ConvNet은 층층이 feature hierarchy를 계산하여 내재적인 multiscale, pyramidal shape을 가지고 있다. 이러한 in-network feature hierarchy는 다양한 spatial resolution의 feature maps을 형성하지만 다른 깊이에서 유발된 커다란 semantic gap을 야기한다. 다시 말해 high-resolution maps는 representational capacity가 뒤떨어지는 low-level features를 가지고 있는 것이다.
이 논문의 목표는 ConvNet의 feature hierarchy의 피라미드 모양을 사용하면서도 모든 scale에서 강한 semantics를 지닌 feature pyramid를 만드는 것이다. 이를 위해 top-down pathway와 lateral connections을 통해 low-resolution, semantically strong features와 high-resolution, semantically weak features를 조합하는 architecture을 고안했다.
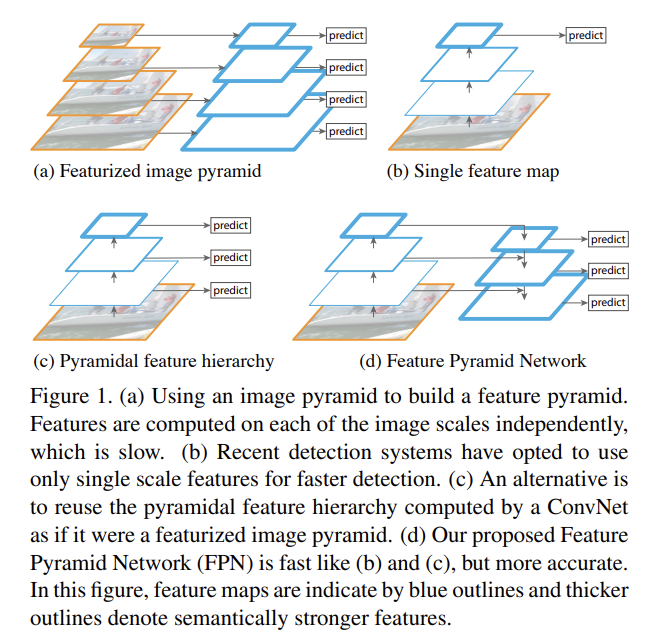
이는 모든 level에서 풍부한 semantics를 가지고 single input image scale에서 빠르게 얻을 수 있는 feature pyramid다. 즉, representational power, speed, memory를 희생하지 않고도 featurized image pyramids를 대체할 수 있는 in-network feature pyramids다.
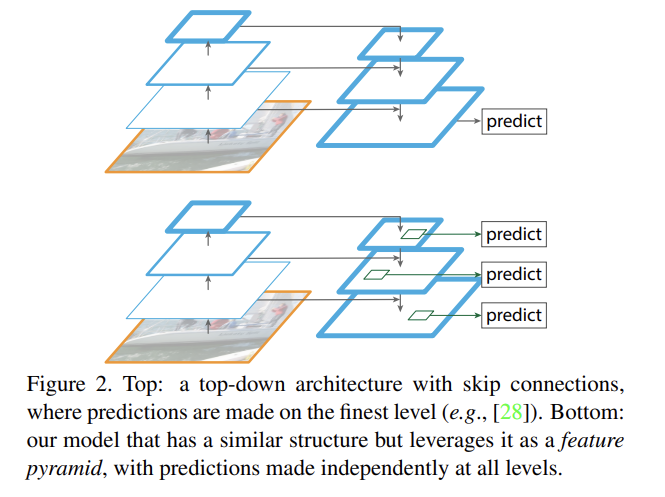
기존의 연구들은 Fig 2의 위쪽 사진처럼 top-down과 skip connections을 적용하여 fine resolution을 지닌 single high-level feature map을 만들고 거기서 prediction을 한다. 하지만 이 논문의 방법은 prediction이 각 level에서 독립적으로 만들어진다.
FPN은 임의의 크기의 single-scale image를 넣어 multiple level에서 fully convolutional fashion으로 proportionally sized feature maps를 산출한다. (이 과정은 backbone convolutional architectures과 독립적이며 논문에선 backbone으로 ResNet을 사용한다.) pyramid 구조는 bottom-up pathway, top-down pathway, lateral connections로 구성된다.
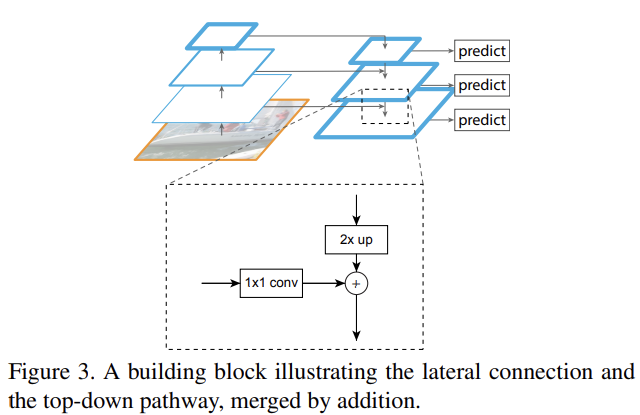
bottom-up pathway는 backbone ConvNet의 feedforward computation를 의미한다. 여기선 (scaling step of 2로) 여러 scale의 feature maps를 가진 feature hierarchy를 계산한다. 종종 같은 크기의 output map을 생산하는 여러 layer들이 있는데 이들을 같은 stage에 있다고 말한다. 각 stage마다 하나의 pyramid level이 정의된다. 각 stage의 마지막 layer이 (나중에 pyramid를 만드는 데 사용될) feature maps의 reference set이 된다.
특히 ResNet의 경우 각 stage의 마지막 residual block이 만든 feature activations output을 사용하고 conv2, conv3, conv4, conv5의 output을 {C2, C3, C4, C5}로 표기한다. 이들은 {4, 8, 16, 32} pixels의 stride를 가지며, 메모리 상의 이유로 conv1는 pyramid에 포함되지 않는다.
top-down pathway는 higher pyramid levels에서 온 spatially coarser, semantically stronger한(즉 convnet을 더 많이 통과해서 localize는 나쁘지만 semantically 정확한) feature maps를 upsampling하여 higher resolution features를 hallucinate한다. 이 feature들은 1x1 lateral connections을 통해 bottom-up pathway에서 온 feature와 합쳐져 강화된다. 각 lateral connection은 bottom-up pathway와 top-down pathway에서 온 동일한 spatial size의 feature maps를 합친다. bottom-up feature map은 lower-level semantics이지만, activation이 subsample된 횟수가 더 적기 때문에 더 정확하게 localize되어있다.
Fig 3처럼 coarser-resolution feature map에 nearest neighbor upsampling를 적용해 spatial resolution를 2배로 upsample하여 상응하는(즉 크기가 같은) bottom-up map과 element-wise하게 더한다. 이때 bottom-up map은 channel dimensions을 위해 1×1 convolutional layer을 거친다.
finest resolution map을 생성할 때까지 이 과정이 반복되며, C5에 단순히 1×1 convolutional layer를 붙여 coarsest resolution map를 생산하는 것으로 iteration이 시작된다. 그리고 각 merged map마다 3×3 convolution을 붙여 final feature map을 생성하는데, upsampling의 aliasing effect를 줄이기 위함이다. {C2, C3, C4, C5}에 상응하는 최종 feature map들은 {P2, P3, P4, P5}로 표기하며 각각 같은 spatial size를 가진다.
traditional featurized image pyramid처럼 pyramid의 모든 level이 classifiers/regressors를 공유하기 때문에 모든 feature map에서 feature dimension(=numbers of channels, d)을 동일하게 고정시킨다. 논문에선 모든 extra convolutional layers에 d=256를 사용하고 extra layers에 non-linearities를 사용하지 않는다(경험적으로 별 효과 없다는 걸 알아서).
논문은 Faster R-CNN의 RPN과 Fast R-CNN에 각각 FPN을 적용해 실험한다. RPN은 sliding-window class-agnostic object detector이다. single-scale feature map을 FPN으로 교체하여 RPN을 adapt한다. RPN과 같은 디자인의 head(3×3 conv과 2 sibling 1×1 convs)를 feature pyramid의 각 level에 부착한다. head가 모든 level의 모든 location을 densely하게 sliding하므로 Faster R-CNN과 같은 multi-scale anchor가 필요 없다. 대신 각 level에 single scale의, multiple aspect ratios {1:2, 1:1, 2:1}를 가진 anchors를 할당해줬다.
training label은 ground-truth box와의 IoU에 따라 anchor에 할당해줬다. 이때 ground-truth box의 scale은 pyramid level에 할당하는 데 명시적으로 쓰이는 게 아니고, ground-truth box는 pyramid level에 할당된 anchor와 연관된다.
그리고 모든 feature pyramid level이 heads의 parameters를 공유한다(사실 공유 안해도 비슷한 정확도가 나오긴 했다). parameter 공유의 좋은 성능은 모든 level이 비슷한 semantic 수준(level)을 공유한다는 것을 나타낸다. 이 장점은 featurized image pyramid와 유사하다.
Fast R-CNN은 Region-of-Interest (RoI) pooling으로 feature extract를 하는 region-based object detector이다. 이를 FPN과 사용하기 위해 pyramid levels에 다양한 scale의 RoI를 할당한다. RoI의 w, h로 level k를 결정한다.
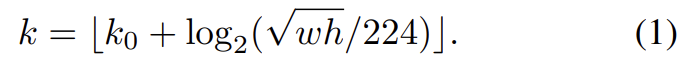
predictor heads(=class-specific classifiers와 bounding box regressors)를 모든 level의 모든 RoI에 붙여준다. 여기서도 head는 level에 상관없이 parameter을 공유한다. 그리고 RoI pooling으로 7×7 features을 추출하고 최종 classification, bounding box regression layers 전에 2개의 hidden 1,024-d FC layers를 붙인다.
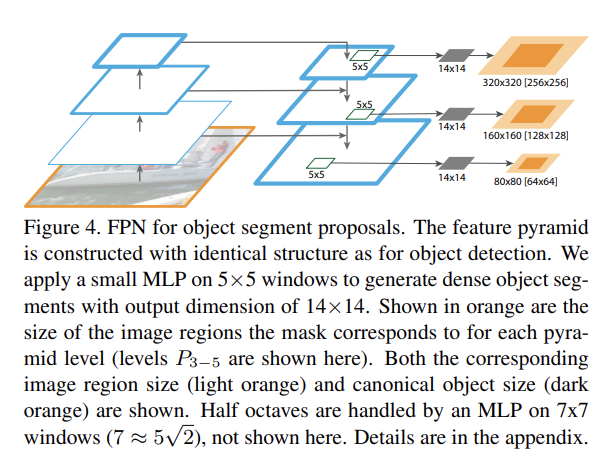
FPN은 object detection뿐 아니라 segmentation proposals을 생성하는 데도 사용될 수 있다.
Strengths
- top-down pathway를 통해 semantic feature와 fine resolution을 보장하면서 down-top pathway에서 1×1 lateral connections를 받아와 location의 정확도를 높이는 방법이 참신했다. 여러 층의 feature를 사용한다는 점에서 SSD와 비슷하면서도, 두 pathway의 값을 합한다는 점에서 달랐다.
- ConvNet이라면 누구에게든 부착시켜 범용적으로 사용할 수 있어서 좋다.
Weaknesses
- 두 pathway의 값을 단순히 합치는 게 아니라 차라리 U-Net처럼 concatenate하는 게 더 낫지 않았을까?
