아이디어, 내 감상 메모용

위와 같은 BigToM dataset을 사용한다. Mistral-7B-Instruct라는 SOTA instruction fine-tuned autoregressive language model을 학습.
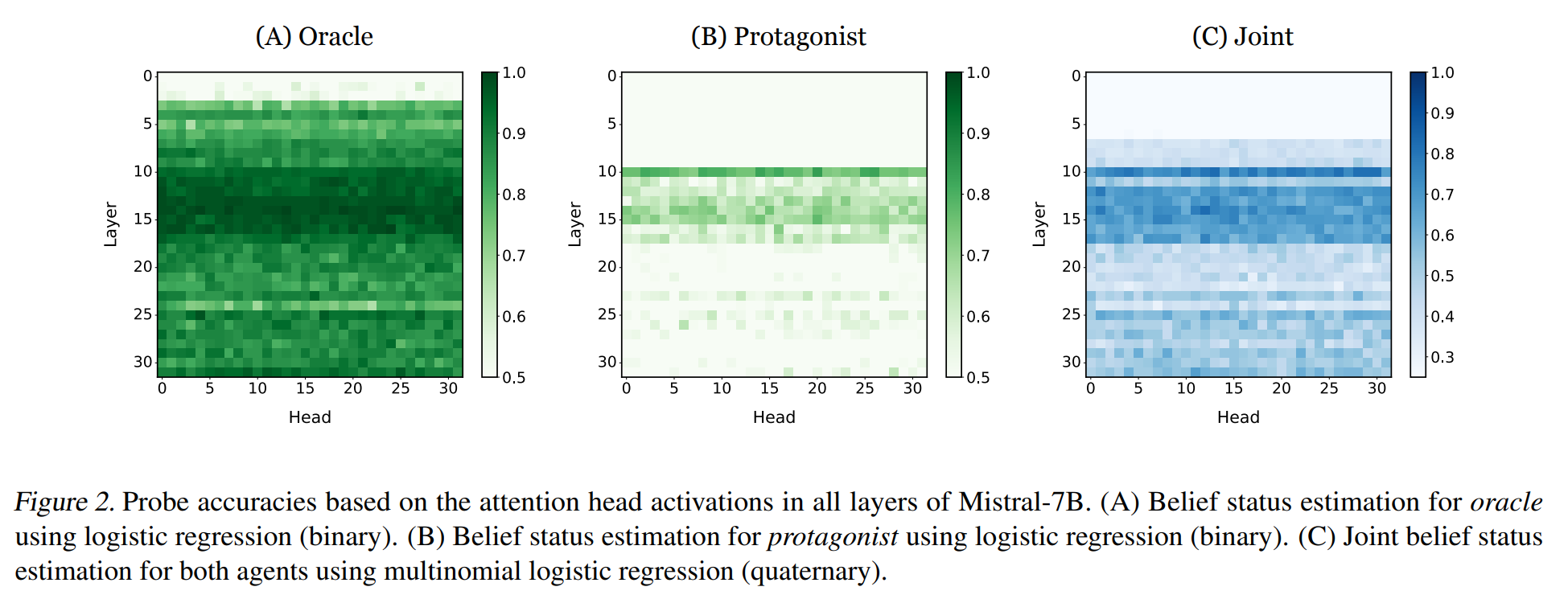

각 head, layer마다 선형 probe를 붙여서 학습시켰더니 figure 2에서 볼 수 있듯 (다른 부분에선 맞출 확률 0.5, 즉 반반인데) 특정 layer에서는 유독 잘 맞춘다. latent space에 belief가 encoding된다는 의미. 특히 fig 2(C)는 protagonist(주인공)와 oracle(전지적작가시점)을 동시에 맞추도록 한 건데 역시 유의미하게 잘 맞추는 head가 중간 layer쯤에 있었다. 즉 해당 head는 각 belief를 독립적으로가 아니라 in conjunction하게 인코딩한다.
(그런데 단지 이걸로 belief가 존재한다고 주장하기엔... 너무 문제가 단순하지 않나?)
(애초에 논문이 '믿음이 무엇인가'란 중요한 질문부터 무시하고 착수되기 때문에...)
(만약 실험 결과가 지금처럼 head 하나로 유의미하게 예측가능한게 아니라, 한 layer 층의 head 전부를 linear하게 연결해서 유의미한 추측을 성공하는 결과가 나왔다면, 그때는 belief가 head 전체에 spread되어있다고 말했을 것 아닌가? 혹은 여러 layer 층의 임의의 head들에 probe를 연결하는 식으로 성공했다면? 결국 llm이 결과적으로 ToM 행동에 성공한다면, 최소한 그 부분 역시 어느정도 성공적이어야 할테고, 그 당연한 걸 확인한 것에 불과하지 않나?)
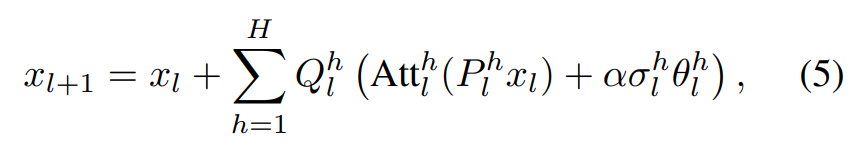
논문은 다음으로 저 belief representations를 조작해서 저것들의 기능을 살펴본다. multihead attention 중에 위의 식처럼 activation을 특정 방향으로 조작하는데, P는 저차원으로 map하고 Q는 다시 복구하는 mapping이다. Px를 attention한 이후에 조작이 들어가는데, alpha는 step length, sigma는 target direction으로의 activation의 standard deviation, theta는 target direction이다.
(GPT)
연구자들은 세 가지 질문에 답하고자 했습니다:
내부 표현을 조작하여 언어 모델의 사회적 추론 능력을 변화시킬 수 있는가?
만약 가능하다면, 어떻게 이것을 달성할 수 있는가?
이러한 조작이 다른 유형의 사회적 추론 작업에 어떤 영향을 미치는가?4.1. ToM Evaluation (마음 이론 평가)
연구자들은 BigToM 벤치마크를 사용하여 언어 모델의 마음 이론 능력을 평가했습니다. 세 가지 사회적 추론 작업을 연구했습니다:
- Forward Belief: 에이전트의 지각(percept)을 바탕으로 그의 신념을 추론하는 작업
- Forward Action: 에이전트의 지각을 바탕으로 그의 미래 행동을 예측하는 작업
- Backward Belief: 관찰된 행동을 바탕으로 에이전트의 신념을 역추론하는 작업
각 작업에 대해 True Belief(TB)와 False Belief(FB) 두 가지 조건을 평가했습니다.
4.2. Activation Intervention (활성화 개입)
4.2.1. 전략
연구자들은 "inference-time intervention"이라는 기법을 적용했습니다:
1. 검증 세트에서 프로빙 정확도가 높은 상위 K개의 어텐션 헤드를 선택
2. 다음 토큰 예측 시 이들 헤드의 활성화를 특정 방향으로 조작
3. 이 과정을 자기회귀적(autoregressively)으로 반복연구자들은 다양한 개입 방향을 탐색했습니다:
1. Random directions: 활성화 공간 내의 무작위 방향
2. Weight directions for oracle and protagonist: 이진 프로빙에서 도출된 방향
- 주인공의 신념을 참으로 예측할 확률을 최대화하는 방향 (+ protagonist)
- 전지적 관찰자의 신념을 참으로 예측할 확률을 최소화하는 방향 (- oracle)
- Weight directions for joint belief status: 다항 프로빙에서 도출된 방향
- 주인공의 신념은 참이고 전지적 관찰자의 신념과 구별되도록 하는 방향 (+ TpFo)
4.2.2. 결과
Table 1에 제시된 결과에 따르면:
1. 무작위 방향(+ random): 모델 성능에 미미한 영향
2. 주인공 신념 방향(+ protagonist): 유의미한 성능 변화 없음
3. 전지적 관찰자 신념 방향의 역방향(- oracle): 모델 행동에 주목할 만한 변화 발생
4. 공동 신념 상태 방향(+ TpFo): 가장 효과적으로 모델 성능 변화, 전반적인 ToM 추론 능력 향상Figure 5는 개입 강도(α)에 따른 성능 변화를 보여줍니다:
(+ TpFo) 방향으로의 개입은 False Belief 경우의 ToM 정확도를 일관되게 향상시킴
True Belief 정확도는 약간 감소 (부분적으로 유효하지 않은 응답의 증가 때문)
Figure 7은 특정 방향으로의 활성화 조작이 다음 토큰 예측 확률에 어떤 영향을 미치는지 보여줍니다.4.3. Varying Social Reasoning Tasks
연구자들은 다양한 사회적 추론 작업 간의 표현 관계를 탐구했습니다:
Figure 6은 서로 다른 작업 간의 프로빙 정확도에 강한 상관관계가 있음을 보여줍니다.
한 작업에서 상위 성능을 보이는 헤드들은 다른 작업에서도 예측적 특성을 포함하는 경향이 있습니다.
Table 2는 한 작업에서 식별된 방향이 다른 작업으로 일반화될 수 있음을 보여줍니다.
Figure 8은 왜 이런 방향들이 일반화 가능한지 이해하기 위한 분석을 제공합니다:
식별된 방향들은 주로 주요 인과 변수(욕구, 행동, 인과 사건, 지각 상태)를 나타내는 토큰에 집중합니다.
이 요소들은 서로 다른 사회적 추론 작업에서 공통적으로 중요하며, 이것이 표현의 일반화 가능성을 설명합니다.
이 연구를 통해 언어 모델이 내부적으로 자신과 타인의 신념을 구별하고 표현하는 능력을 가지고 있으며, 이러한 표현을 조작하여 모델의 마음 이론 성능을 향상시킬 수 있다는 것이 입증되었습니다.
또 의아한 부분이 있는데,
4.1 ToM Evaluation에서
"As the baseline results in Table 1 show, both models exhibit a distinct performance gap between True Belief and False Belief conditions when tested directly. It suggests that the models fail to recognize that other agents may hold beliefs different from their own due to perception differences. Specifically, in the classical False Belief test, Mistral is more biased towards the wrong answer, while DeepSeek's choices are closer to random guess."
이 문장은 모델들이 True Belief와 False Belief 조건 사이에 뚜렷한 성능 차이를 보이며, 이는 모델들이 다른 에이전트가 지각 차이로 인해 자신과 다른 신념을 가질 수 있다는 것을 인식하지 못한다는 것을 시사한다고 설명합니다. (GPT)
이 부분은 그럼 LLM이 ToM이 없다는 의미 아닌가?
(GPT)
그 해석은 중요한 질문을 제기합니다. "모델이 False Belief 상황에서 성능이 낮다"는 사실이 "LLM에 ToM 기능이 없다"는 의미인지 생각해봐야 합니다.
논문의 결과를 자세히 살펴보면:
부분적 ToM 능력: 모델들은 True Belief 상황에서는 높은 성능을 보였습니다. 이는 적어도 어떤 형태의 마음 이론 능력이 있음을 시사합니다. 모델이 완전히 ToM 능력이 없다면 True Belief 상황에서도 정확한 예측을 하기 어려울 것입니다.
제한된 ToM 능력: False Belief 상황에서 낮은 성능은 모델의 ToM 능력이 제한적이거나 불완전하다는 것을 의미합니다. 인간의 완전한 ToM은 타인이 자신과 다른 신념을 가질 수 있음을 이해하는 것을 포함합니다.
내부 표현의 존재: 연구의 핵심은 비록 모델의 출력(output)이 False Belief 상황에서 부정확할지라도, 모델 내부에 타인의 신념을 표현하는 능력이 존재한다는 것입니다. 이는 프로빙 분석을 통해 확인되었습니다.
개선 가능성: 연구자들이 내부 표현을 조작하여 False Belief 성능을 향상시킬 수 있었다는 사실은, ToM 능력의 요소들이 모델 내에 존재하지만 기본 출력 과정에서 적절히 활용되지 않고 있다는 것을 시사합니다.
따라서, 이 연구 결과는 LLM에 ToM 기능이 "전혀 없다"기보다는 "불완전하고 편향된 ToM 능력이 있다"고 해석하는 것이 더 정확합니다. 모델은 자신의 신념(전지적 관찰자 시점)과 다른 신념을 가진 에이전트를 이해하는 데 어려움을 겪지만, 적절한 조작을 통해 이 능력을 향상시킬 수 있다는 것이 연구의 핵심 주장입니다.
이는 인간의 ToM 발달과도 유사한 면이 있습니다. 어린 아이들도 처음에는 다른 사람이 자신과 다른 정보나 신념을 가질 수 있다는 것을 이해하는 데 어려움을 겪지만, 발달과 함께 이 능력이 향상됩니다.
ToM을 all or nothing으로 봐야하는 것 아닌가? 최소한 LLM은 엄청난 training을 이미 거쳤는데. 그정도 '경험'하고도 아직 못하는 거면 architecture부터 문제인 것 아닌가?
단순 True/False로 belief를 논하니까 이걸 belief나 ToM이라고 말할 수 있는지 의심이 간다. benchmark가 너무 단순한 것 같다. toy problem스럽다.
주인공 한 명만이 아닌 훨씬 여러 명의 mind를 추론해야한다면?
벤치마크에 학습하지 않았음에도(probe만 학습하며, zero-shot 평가함) 특정 layer의 head들이 유독 높은 probability를 가지는 결과가 흥미롭긴한데 문제-특이적인 결과인건 아닌지 의심스럽다. 상황 자체가 다르다면? 좀 더 복잡한 문제/상황이어도 동일한 layer의 동일 head가 반응할까? 또 단순히 특정 단어 token에 반응하는 head인 건 아닌가? 본문에서 말하듯이 인과 변수(욕구, 행동, 인과 사건, 지각 상태)를 나타내는 토큰에 반응하는 head를 찾은거지 '믿음'에 관여하는 head는 아닐 수 있지않나?
차라리 representation 조작을 한 후 true/false 답을 내놓는 게 아니라 autoregressive 문장을 생성시켜서 qualitative한 결과를 좀 보여주면 좋겠는데.
내용이 흥미롭지만 이것으로 ToM을 단정짓기는 너무 이르지 않을까? 차라리 상대의 생각/믿음을 예측해야만 성공하는 게임이 있고 거기에 뛰어난 승률을 보인다면 LLM의 ToM을 인정할 수 있다~이런 접근은 안되나?
