오늘 리뷰할 논문은 MobileNetV2다. 어제 리뷰한 MobileNetV1 논문을 먼저 보고 오면 좋다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 읽기] MobileNetV2(2018) 리뷰, MobileNetV2: Inverted Residuals and Linear Bottlenecks
- MobileNetV2 논문 설명(MobileNetsV2 - Inverted Residuals and Linear Bottlenecks 리뷰)
- [논문리뷰] Mobilenet v2
Summary
논문은 mobile, 그리고 resource가 제한된 환경에 맞춘 network architecture MobileNetV2을 제안한다. 모델은 inverted residual(=bottleneck block) 구조에 기반하는데, shortcut connections가 thin bottleneck layers 사이에 있는 것이다. intermediate expansion layer는 features를 filter하기 위해 lightweight depthwise convolutions을 non-linearity의 source로 사용한다.
bottleneck block 모듈은 low-dimensional compressed representation를 input으로 받아 high demension으로 확장하고 lightweight depthwise convolution으로 filter한다. 그 다음 features는 linear convolution을 통해 다시 low-dimensional representation로 project된다. 이 모듈은 mobile design에 적합한데, large intermediate tensor를 사용하지 않음으로써 inference에 필요한 memory를 감소하기 때문이다.
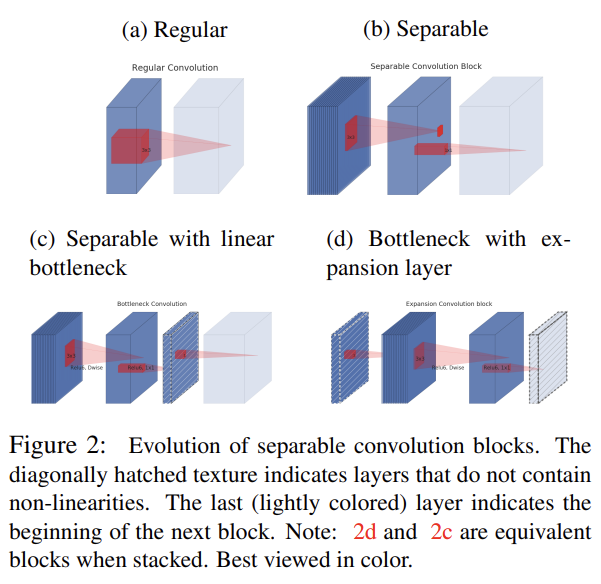
(Depthwise Separable Convolutions은 어제 리뷰한 MobileNet 논문에서 이미 다뤘으므로 설명을 생략하겠다)
차원 activation tensor를 가진 n layers 로 이루어진 네트워크를 생각해보자. 이 activation tensors은 차원을 갖는 “pixels”의 containers로 생각할 수 있다. input set of real images에 대해 set of layer activations이 “manifold of interest”를 형성한다고 볼 수 있다. neural network의 manifold of interest가 low-dimensional subspaces에 embedded될 수 있다는 건 오랜 가정이다. 즉 deep convolutional layer의 모든 individual d-channel pixels를 관찰하면 그 값들에 encode된 정보는 어떤 manifold에 위치하며 이를 low-dimensional subspace에 embed할 수 있다는 것이다.
처음에는 단순히 layer의 dimensionality를 줄여 operating space의 dimensionality를 줄이는 방법으로 위의 사실을 이용할 수 있다고 생각했다. 이를 따른 MobileNetV1은 효과적으로 연산량과 정확도를 tradeoff했다.

그런데 network가 coordinate transformations마다(convolution을 의미하는 듯) ReLU 같은 non-linear를 가짐을 생각해보면 이 통찰은 부서진다. ReLU를 예로 들면 network는 (ReLU의) output domain의 non-zero volume part에 대한 linear classifier 능력만 지니기 때문이다.
한편 ReLU가 channel을 collapse하면(input이 음수라 output이 zero라면) 그 channel에 대한 정보를 잃게 된다. 그런데 channel이 충분히 많다면 해당 정보가 다른 채널에 살아있을 수도 있다.
요약하자면 higher-dimensional activation space의 low-dimensional subspace에 manifold of interest가 존재할 두 가지 경우는 다음과 같다.
- manifold of interest가 ReLU transformation 이후 non-zero volume에 남아있다면, 이는 linear transformation에 상응한다.
- ReLU가 input manifold에 대한 완전한 정보를 보존하는 경우는 input manifold가 input space의 low-dimensional subspace에 위치할 때만 가능하다.
이 두 가지 통찰은 기존의 network를 최적화하는 힌트를 준다. manifold of interest가 low-dimensional이라는 가정 하에 convolutional blocks에 linear bottleneck layers를 삽입하는 것으로 manifold를 포착하는 것이다. 실험 결과 non-linearites가 너무 많은 정보를 파괴하지 않게 linear layers를 사용하는 게 중요하다는 것을 관찰했다.
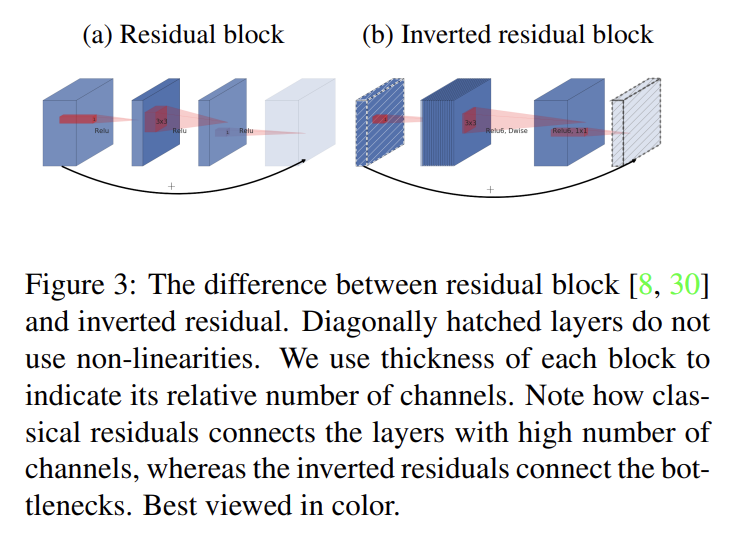
bottleneck block은 residual block과 비슷한데, 각 block의 input이 여러 bottlenecks을 거치고 expansion [8]이 된다. 그러나 bottlenecks이 사실 필요한 모든 정보를 담고 있다는 (앞서 설명한) intuition에 따라 논문은 bottlenecks 사이 직접 shortcuts을 사용한다. (expansion layer은 나중에 나올 implementation detail 섹션에서 설명하는대로 non-linear transformation을 동반한다)
Fig 3이 두 디자인의 차이를 보여준다. shortcut을 도입한 동기는 기존처럼 gradient가 여러 layers를 건너 전파되는 능력을 향상하기 위해서다. 그러나 inverted design이 상당히 더 메모리 효율적이고 실험에서 성능도 약간 더 좋다.
(그러니까 Fig 3을 보면 기존의 residual block(=bottleneck block)은 channel이 많고-적고-많고 순서인데 논문은 channel이 적으면 non-linearity를 사용하면 안되고 channel이 많으면 사용해도 manifold 정보가 손실되지 않는다고 생각했기 때문에 inverted residual block을 channel이 적고-많고-적고 순서가 되게 설계하고 채널이 적은 것들에 non-linearity를 사용하지 않고 shortcut을 형성했다. 그리고 중간의 expansion layer은 충분히 커서 ReLU에 의한 information loss에 resistant하므로 ReLU6를 사용한다.)

크기의 block에 대해 expansion factor t, kernel size k, d' input channels and d'' output channels일 때 multiply add 연산의 횟수는 이다. extra 1 × 1 convolution가 있기 때문에 MobileNetV1의 depthwise separable convolution의 연산량 식보다 항이 하나 많지만 대신 더 작은 input, output dimension을 사용할 수 있다.
이 architecture의 한 가지 흥미로운 점은 building blocks (bottleneck layers)의 input/output domains 사이 자연스러운 분리와 (input을 output으로 전환하는 non-linear function인) layer transformation을 제공한다는 것이다. 전자는 network의 각 layer에서 capacity라고 볼 수 있고 후자는 expressiveness라고 볼 수 있다. 이는 expressiveness와 capacity가 tangle되어 output layer depth의 함수였던 전통적인 convolutional blocks와 대비된다.
특히 inner layer depth가 0이면 underlying convolution은 shortcut connection에 의해 identity function이 된다. expansion ratio가 1보다 작으면 classical residual convolutional block이 된다. (그러나 이후 실험에서 expansion ratio가 1보다 큰 쪽이 효과적임을 보인다) 이 해석은 expressiveness와 capacity를 분리해서 연구할 수 있게 한다.
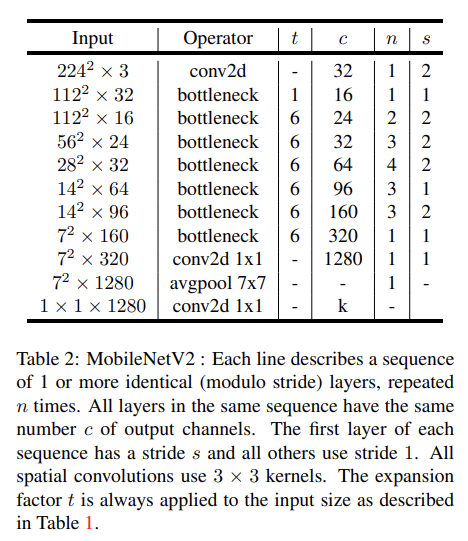
이제 architecture을 자세히 알아보자. basic building block은 Table 1과 같은 bottleneck depth-separable convolution with residuals이다. initial fully convolution layer with 32 filters 이후 19 residual bottleneck layers이 뒤따른다. low-precision computation과 사용했을 때의 robustness 때문에 non-linearity는 ReLU6를 사용했다. kernel size는 항상 3x3이고 training 중 dropout과 batch normalization을 사용했다.
첫 층을 제외하면 constant expansion rate를 사용했다. 실험으로 expansion rate 5~10 정도가 거의 동일한 performance curve를 보임을 찾았다. 작은 네트워크는 expansion rate가 작으면 성능이 약간 더 좋았고 큰 네트워크는 rate가 크면 성능이 약간 더 좋았다. 모든 실험에서 expansion factor=6을 사용했다.
desired accuracy/performance trade-offs를 맞추기 위해 MobileNetV1처럼 input image resolution and width multiplier를 tunable hyper-parameter로 삼았다. 한 가지 차이점이라면 1보다 작은 multiplier에 대해선 마지막 convolutional layer을 제외하고 width multiplier을 적용했다는 것이다. 이는 smaller model에서 성능을 향상시켰다.
(5. Implementation Notes 부분 생략)
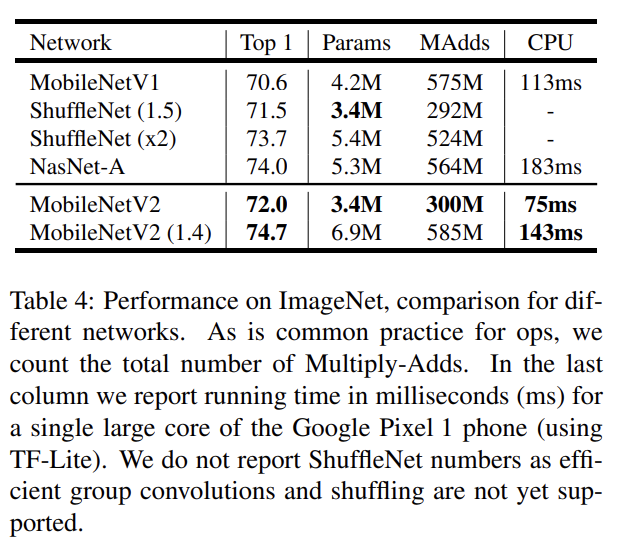
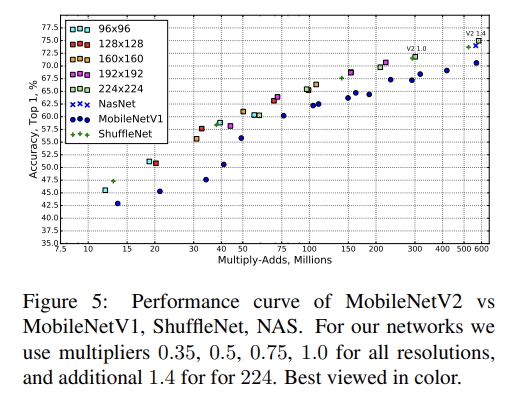
위는 ImageNet classification 실험 결과다. RMSPropOptimizer를 사용했고 모든 layer 이후에 batch normalization을 사용했다.
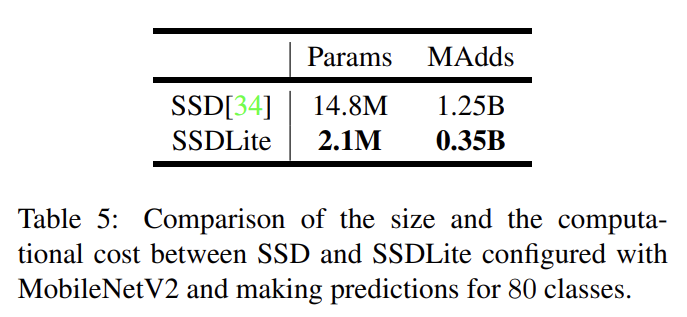
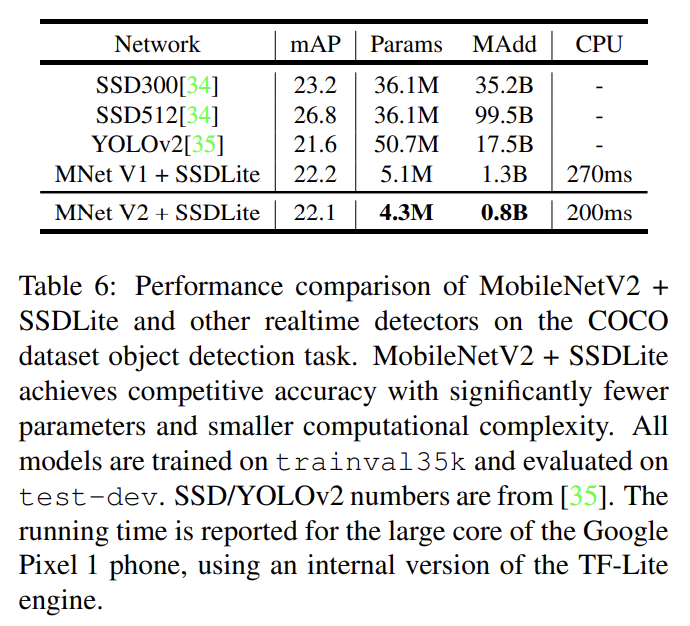
object detection에 대해 MobileNetV2와 MobileNetV1를 feature extractor로 사용해서 COCO dataset에 Single Shot Detector (SSD)의 modified version을 평가한다. YOLOv2와 original SSD도 baseline으로 사용한다. MobileNetV2 SSDLite는 가장 효율적일뿐 아니라 가장 정확도도 높다. 자세한 설명은 생략한다.

mobile semantic segmentation 과제를 위해 DeepLabv3의 feature extractors로 MobileNetV1와 MobileNetV2 models을 사용해 PASCAL VOC 2012 dataset에 성능을 비교한다. 설명은 생략한다.
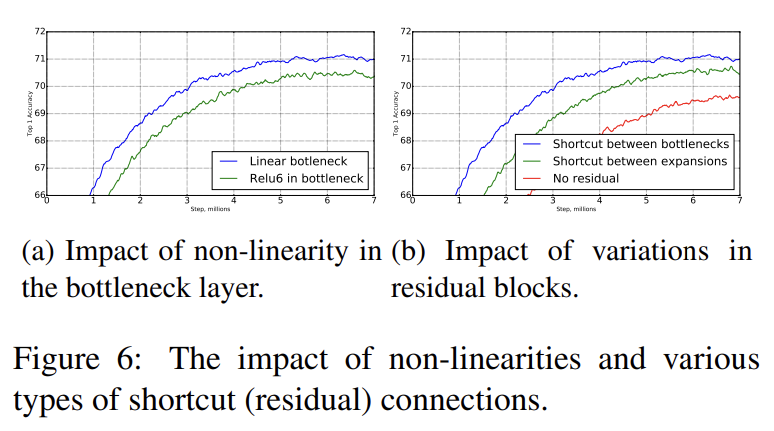
두 가지 ablation study를 진행한다. 첫째로 Inverted residual connections의 중요성을 확인했다. Fig 6b처럼 bottleneck을 연결하는 shortcut이 expanded layers를 연결하는 shortcut보다 성능이 좋았다. 둘째로 linear bottlenecks의 중요성을 확인했다. activation이 linear 영역에서만 작동하기 때문에 linear bottleneck model은 non-linearity를 가진 model보다 덜 강력하다. 그러나 Fig 6a는 linear bottleneck이 성능을 향상시킴을 보인다. 이는 non-linearity가 low-dimensional space에서 정보를 파괴함을 시사한다.
Strengths
- expressiveness (encoded by expansion layers)와 capacity (encoded by bottleneck inputs)를 분리하는 convolutional block을 제안했다. 사실 이 경우에만 특수한 것인지 알 수 없지만 적어도 이후 연구 방향과 가능성을 제시했다.
- 연산량, 메모리 효율적이다.
- 통찰과 적용이 훌륭하다. 이미 정보가 풍부한 wide layer 사이가 아닌 정보가 손실되기 쉬운 narrow layers 사이 shortcut을 설립하고 ReLU를 선택적으로 사용해서 뛰어난 성능을 보였다.
Weaknesses
- 논문에선 모든 non-linearity가 정보 손실을 유발하는 것처럼 말했지만 사실 ReLU(또는 그런 계열)의 문제인 것 같다. 표현이 약간 부정확한 듯하다. tanh처럼 평평한 0 부분이 없는 경우엔 정보 손실 문제가 일어나지 않을 테니까.
- 오타가 제법 보인다. 심지어 abstract에조차!
논문 설명이 헷갈리는 것 같아서 내가 이해한 바를 다시 정리한다.
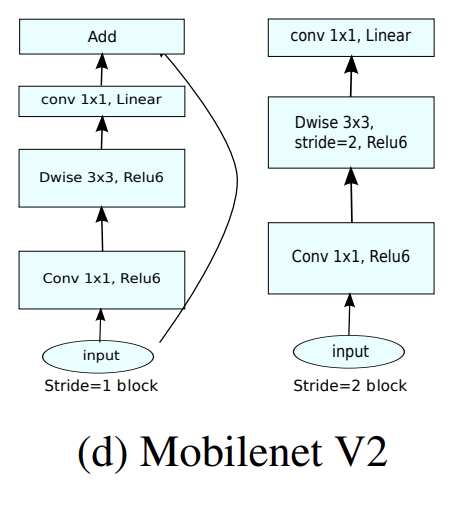
expansion layer은 input보다 output dimension이 더 큰 layer를 의미한다.
논문의 bottleneck block에는 두 가지 stride를 사용하는데, (shortcut을 연결하려면 input, output 크기가 동일해야하므로) 2인 경우는 단순히 feature 크기를 절반으로 줄이고 1일 때만 shortcut을 적용했다.
곧바로 depthwise separable convolution(=depthwise convolution + pointwise convolution)을 적용하는 MobileNetV1과 달리 MobileNetV2는 먼저 conv 1x1로 channel을 expansion factor(=expansion ratio) t배로 키우고 나서 depthwise convolution과 pointwise convolution을 적용하는 것이다. 이렇게 중간에 channel 수가 늘어난 expansion layers는 manifold 정보를 보존할 channel 수가 충분하므로 ReLU를 사용해도 된다. channel 수가 작을 때는 ReLU를 사용하지 않고 linear하게 두며, stride=1인 경우엔 skip connection을 연결한다. 이러면 MobileNetV1에서 바로 depthwise separable convolution할 때보다 오히려 연산량이 줄어든다고 한다.
depthwise separable convolution의 설명은 어제 리뷰한 MobileNetV1 논문을 참고하자.
해당 포스트에서 연산량 비교, manifold 설명, 코드 실습까지 있으니 참고하면 좋을 것이다.
