
오늘 리뷰할 논문은 SRGAN 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문] SRGAN 리뷰 : Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
- SRGAN
Summary
low-resolution (LR) 이미지에서 high-resolution (HR) image를 추정하는 과제를 super-resolution (SR)라고 부른다. 특히 논문은 single image super-resolution (SISR) 과제에 집중한다.
문제는 large upscaling factor로 SR을 할 때 어떻게 finer texture detail을 복구하느냐다. 기존의 방식들은 recovered HR image와 ground truth 사이 mean squared error (MSE)를 최소화해서 SR 알고리즘을 평가하는 척도인 peak signal-to-noise ratio (PSNR)를 극대화한다.

그러나 MSE(와 PSNR)는 pixel-wise image difference에 정의되어 있으므로 high texture detail 같은 perceptually relevant differences를 잘 포착하지 못한다.
논문은 super-resolution generative adversarial network (SRGAN)을 제안한다. skip network를 가진 ResNet을 활용하며 MSE를 유일한 optimization target으로 사용하지 않는다. 대신 VGGNet의 high-level feature map을 사용하는 새로운 perceptual loss를 정의하고 HR reference image와 perceptually 구분하기 어려운 solution을 격려하는 discriminator와 함께 사용한다.
논문의 기여는 다음과 같다.

SISR의 목표는 low-resolution input image 에서 high-resolution, superresolved image 를 얻는 것이다. 은 high resolution counterpart 의 저해상도 버전이며 은 training 중에만 제공된다. training 중에 에 Gaussian filter를 적용하고 downsampling factor r로 downsampling operation을 수행해 를 얻는다. 의 크기는 W × H × C, 의 크기는 rW × rH × C가 된다.
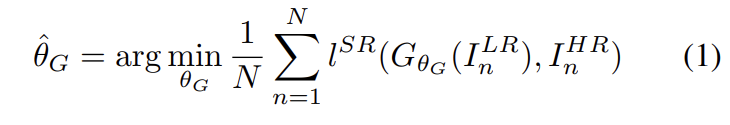
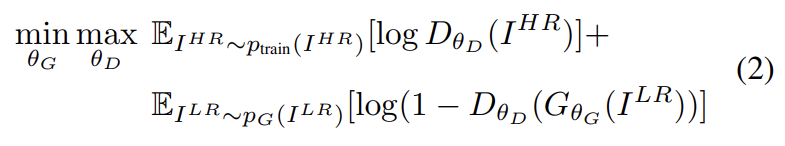
feed-forward CNN 를 학습시키며 parameter 는 L-layer deep network의 weight와 bias를 의미하고 SR-specific loss function 를 최적화하여 얻어진다.
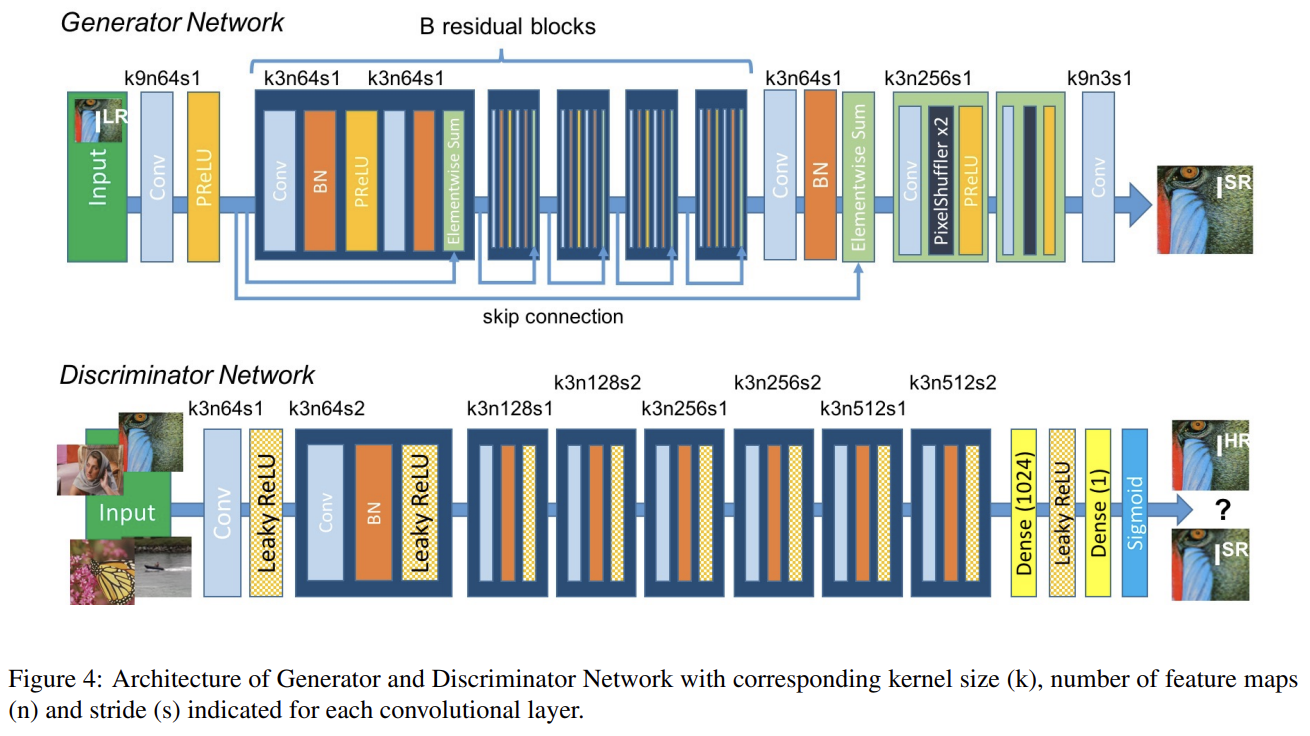
G는 identical layout를 가진 B residual blocks으로 이루어진다. Gross and Wilber [24]에 의해 제안된 block layout을 사용했다. 구체적으로는 3 x 3 kernel 64 feature maps의 convolutional layers 2개와 batch-normalization layers, ParametricReLU를 사용했다. input image의 resolution을 높이기 위해 Shi et al. [48]이 제안한 2 trained sub-pixel convolution layers를 사용했다.
D는 Radford et al. [44]이 요약한 architectural guidelines를 따랐으며 LeakyReLU activation (α = 0.2)를 쓰고 max-pooling은 쓰지 않았다. 8 conv layer가 있으며 3 x 3 kernel의 개수가 VGGNet처럼 64개에서 512개까지 2배씩 오른다. feature의 수가 2배가 될 때마다 image resolution을 감소시키기 위해 strided convolution이 사용된다. 512 feature maps 이후 2 dense layer와 sample classification을 위한 probability를 얻는 final sigmoid activation function이 뒤따른다.
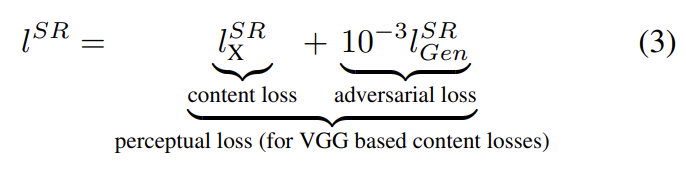
G의 성능에 perceptual loss function 의 정의가 아주 중요하다. 는 MSE에 기반하지만 Johnson et al. [33]과 Bruna et al. [5]에서 발전시켜 perceptually relevant characteristics에 관해 loss function을 정의한다. perceptual loss는 위와 같이 content loss ()와 adversarial loss component의 weighted sum으로 이루어진다.
이제 content loss와 adversarial loss를 알아보자.
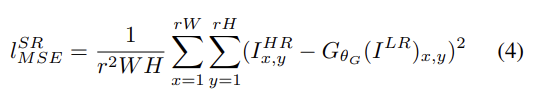
SOTA에서 content loss로 자주 사용되는 pixel-wise MSE loss는 높은 PSNR을 얻지만 종종 high-frequency content가 부족하고 smooth textures를 가진 perceptually 불만족스러운 결과를 보인다.
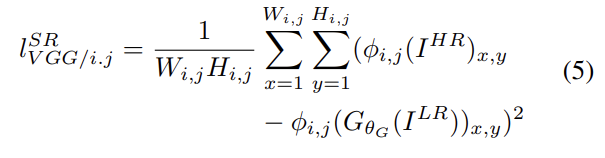
대신 논문은 pre-trained 19 layer VGG network의 ReLU activation layers에 기반하는 VGG loss를 정의한다. 는 VGGNet 내의 i번째 max-pooling layer 이전 j번째 convolution(과 activation)에서 얻은 feature map을 의미한다. 그리고 reconstructed image 와 reference image 의 feature representations 사이 euclidean distance로 VGG loss를 정의한다.
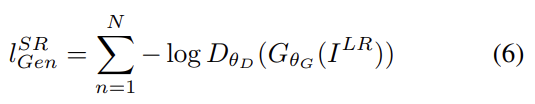
generative loss(=adversarial loss)는 discriminator를 속이게 함으로써 네트워크가 natural images의 manifold 위의 solution을 선호하게 한다. generative loss 는 모든 training samples에 대한 discriminator의 probabilities 에 기반해 정의된다. 는 reconstructed image 가 natural HR image일 확률이다. 더 좋은 gradient behavior를 위해 대신 를 최소화한다.
실험은 benchmark datasets Set5, Set14, BSD100에 수행된다(test image인듯). 학습은 ImageNet database로 했다. 모든 실험은 scale factor of 4×로 수행됐다. 즉 픽셀 수는 16× reduction에 해당한다. 이하 training detail 설명은 생략하겠다.
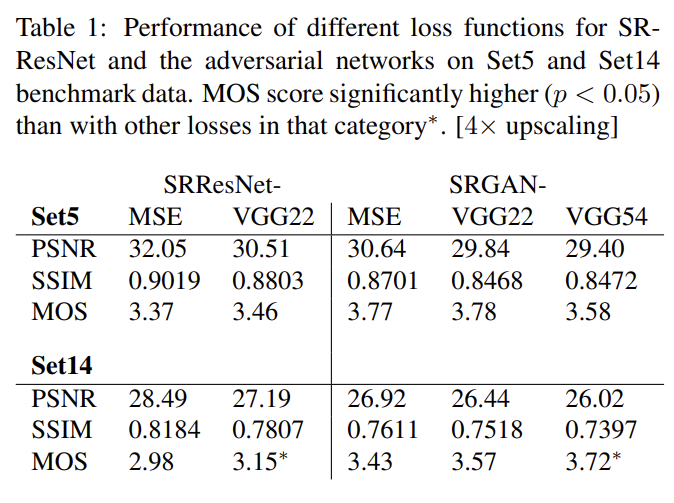
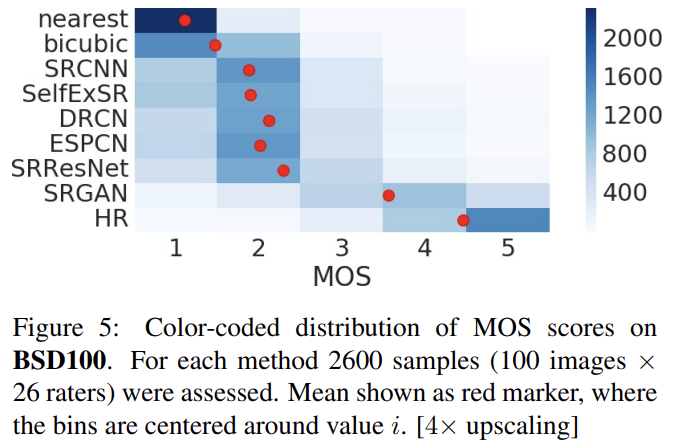
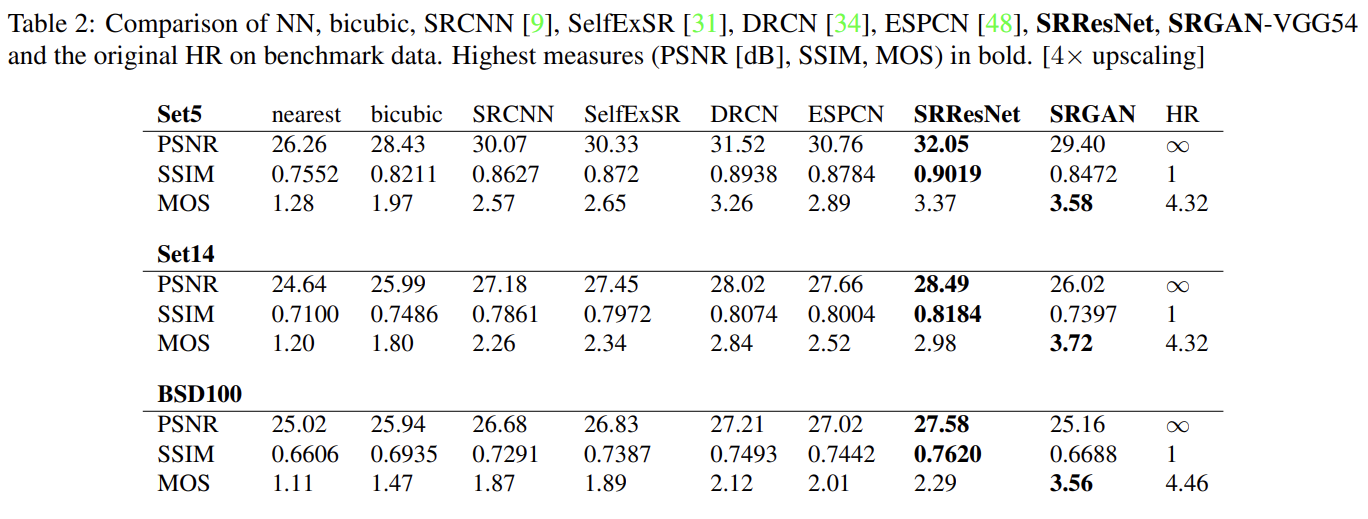
perceptually convincing images를 생성하는 여러 모델의 능력을 수치화하기 위해 Mean opinion score (MOS) test를 수행했다. 26 raters에게 1 (bad quality)에서 5 (excellent quality)까지 integral score을 할당하게 했다. raters는 Set5, Set14 and BSD100의 각 이미지의 12가지 버전 nearest neighbor (NN), bicubic, SRCNN [9], SelfExSR [31], DRCN [34], ESPCN[48], SRResNet-MSE, SRResNet-VGG22∗ (∗not rated on BSD100), SRGAN-MSE∗, SRGAN-VGG22∗, SRGANVGG54, original HR image를 평가했다. 결과는 Table 1, Table 2, Fig 5와 같다.


GAN-based network의 perceptual loss 내에서 content loss 선택지의 차이를 비교하기 위해 조사를 수행했다. adversarial loss와 결합하더라도 MSE는 높은 PSNR values를 가지나 perceptually smooth, less convincing results를 보였다. 이는 MSE-based content loss와 adversarial loss 사이 경쟁 때문으로 추측된다.
논문은 pixel space와 떨어진 features of higher abstraction을 표현할 능력이 deeper network layers에 있다고 생각했고 deeper layers의 feature maps가 순전히 content에 집중하고 adversarial loss가 texture details에 집중한다고 생각했다. 그리고 ideal loss function은 application에 의존한다는 것도 언급한다.
Strengths
- MSE를 쓰되 pixel을 직접 비교한 게 아니라 식 (5)처럼 feature map을 비교한 게 high quality에 영향을 준 것 같다.
- fully convolutional이기 때문에 generator을 임의의 크기의 input image에 사용할 수 있다.
