오늘 리뷰할 논문은 DeepLabV1 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- (Deeplab v1) Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully connected CRFs 논문 리뷰
- Semantic Image Segmentation With Deep Convolutional Nets And Fully Connected CRF (DeepLabv1)
- [논문 리뷰]DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRF
- [베이스리뷰 1주차] DeepLab V1 “Semantic Image Segmentation With Deep Convolutional Nets And Fully Connected CRFs”
Summary
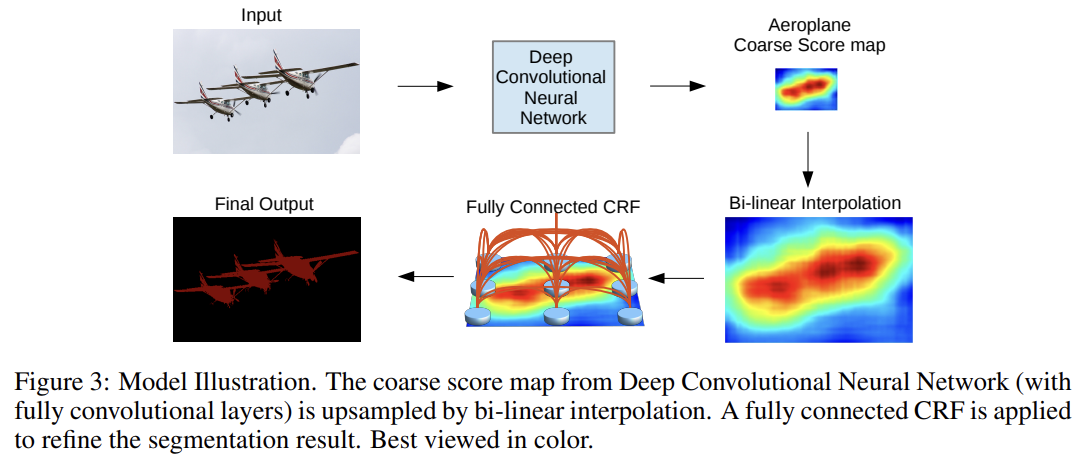
논문은 deep CNN(이하 DCNN)과 probabilistic graphical models을 사용해 pixel-level classification (=semantic image segmentation) task를 다루고자 한다. 논문은 DCNN의 final layer에서의 response가 정확한 object segmentation을 위해 충분히 localize되지 않았음을 보인다. final layer의 response를 fully connected Conditional Random Field (CRF)와 결합함으로써 이 나쁜 localization을 극복한다. DeepLab는 PASCAL VOC-2012 semantic image segmentation task에서 SOTA를 달성한다.
DCNN을 image labeling task에 적용하는 데 2가지 기술적 난점이 있는데, signal downsampling과 spatial ‘insensitivity’ (invariance)이다. 첫째는 DCNN의 layer마다 max-pooling과 downsampling(striding)으로 인해 signal resolution이 감소하는 것이다. 논문은 대신 Papandreou et al. (2014)처럼 (본래 undecimated discrete wavelet transform (Mallat, 1999).을 효율적으로 계산하기 위해 개발된) ‘atrous’ (with holes) algorithm을 사용한다. 이는 기존의 해결책들보다 더 간단한 방식으로 DCNN response의 효율적인 dense computation를 가능하게 한다.
둘째 문제는 classifier로부터 object-centric decisions를 얻는 것이 spatial transformations로의 invariance를 요구하여 내재적으로 DCNN의 spatial accuracy를 제한한다는 사실과 관련있다. 논문은 fully-connected Conditional Random Field (CRF)을 사용해 fine detail을 포착하는 모델의 능력을 키우고자 한다.
CRF는 multi-way classifiers가 계산한 class scores와 (pixels와 edges의 local interactions이나 superpixels로 포착되는) low-level information를 결합하기 위해 semantic segmentation에서 널리 사용된다. 논문은 효율적인 연산, fine edge details를 포착하는 능력, long range dependencies 요구를 만족하는 능력을 위해 Krahenb ¨ uhl & Koltun (2011)의 fully connected pairwise CRF를 사용한다.
DeepLab의 3가지 주요 장점은 속도, 정확도, 간단성이다.
논문은 Imagenetpretrained state-of-art 16-layer classification network인 VGG-16을 dense semantic image segmentation system을 위한 dense feature extractor로 repurpose하고 finetune했다.
- EFFICIENT DENSE SLIDING WINDOW FEATURE EXTRACTION WITH THE HOLE ALGORITHM
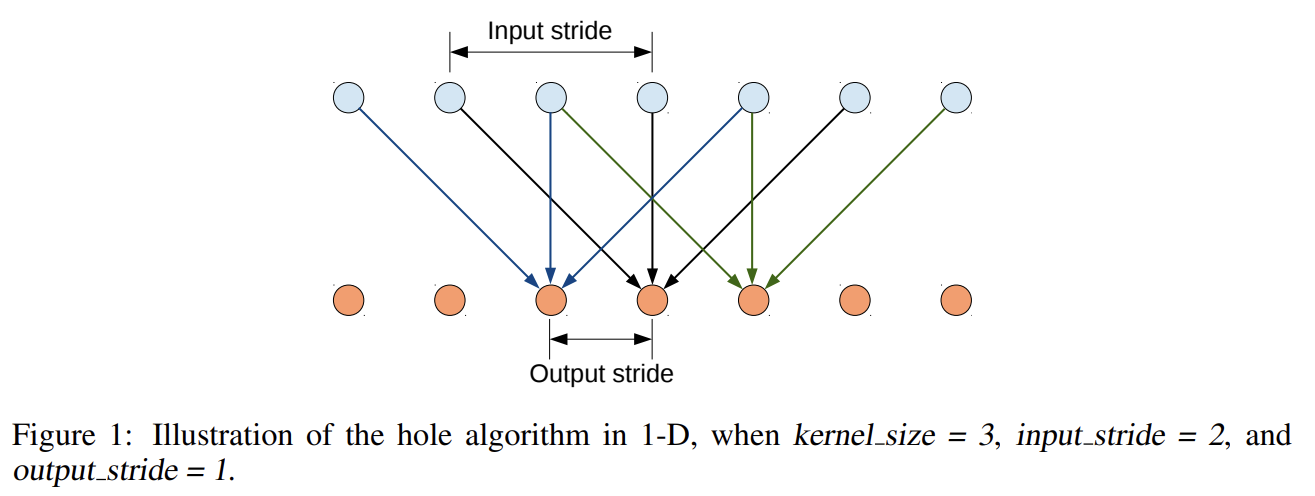
Dense spatial score evaluation은 우리의 dense CNN feature extractor의 성공에 중요하다. 이를 구현하기 위한 첫 단계로 VGG-16의 fully-connected layers를 convolutional layers로 전환하고 image의 원본 해상도에 네트워크를 실행한다. 그러나 이는 (32 pixels의 stride를 가진) sparsely computed detection scores를 만들기 때문에 불충분하다. target stride of 8 pixels로 더 dense하게 scores를 계산하기 위해 Giusti et al. (2013)와 Sermanet et al. (2013)가 사용한 방법을 변형한다. Simonyan & Zisserman (2014)의 네트워크에서 마지막 2 max-pooling layers 이후 subsampling을 생략하고 그들을 뒤따르는 layers의 convolutional filters를 (그들의 length를 (마지막 3 conv layers에서는 2배로 첫 FC layer에서는 4배로) 증가시키기 위해 0을 도입함으로써) 변경한다. 이를 더 효율적으로 구현할 수 있는데, filters를 건드리지 않고 대신 각각 input stride 2나 4 pixels를 사용해 feature maps를 sparsely sample하면 된다. 이것이 ‘hole algorithm’ (‘atrous algorithm’)이며 undecimated wavelet transform의 효율적인 연산을 위해 개발되었다.
Imagenet-pretrained VGG-16 network를 image classification task에 적용하기 위해 Long et al. (2014)의 간단한 방법을 따라 finetune한다. 마지막 layer의 1000-way Imagenet classifier를 21-way classifier로 교체한다. loss function은 (원본 image의 8배로 subsample된) CNN output map 내 각 spatial position의 cross-entropy terms의 합이다. target은 (8배로 subsample된) ground truth labels이다.
testing의 경우, 원본 해상도로 class score maps가 필요하다. Fig 2에서 볼 수 있듯 class score maps이 smooth하기 때문에 8배로 해상도를 늘리기 위해 simple bilinear interpolation를 사용한다.
- CONTROLLING THE RECEPTIVE FIELD SIZE AND ACCELERATING DENSE COMPUTATION WITH CONVOLUTIONAL NETS
dense score computation을 위해 네트워크를 repurpose하는 다른 핵심 요소는 네트워크의 receptive field size를 명시적으로 조절하는 것이다. 네트워크를 fully convolutional one로 바꾸고 나면 첫번째 FC layer는 큰 7×7 spatial size의 4096 filters를 가지게 되어 dense score map 연산에 병목이 된다.
이 문제를 (simple decimation로) 첫번째 FC layer를 4×4 (또는 3×3) spatial size로 spatially subsample함으로써 다룬다. 이는 네트워크의 receptive field를 128×128 (with zero-padding)나 308×308 (in convolutional mode)로 감소시키고 첫 FC layer의 연산 시간을 2-3배 감소시킨다.
- DEEP CONVOLUTIONAL NETWORKS AND THE LOCALIZATION CHALLENGE
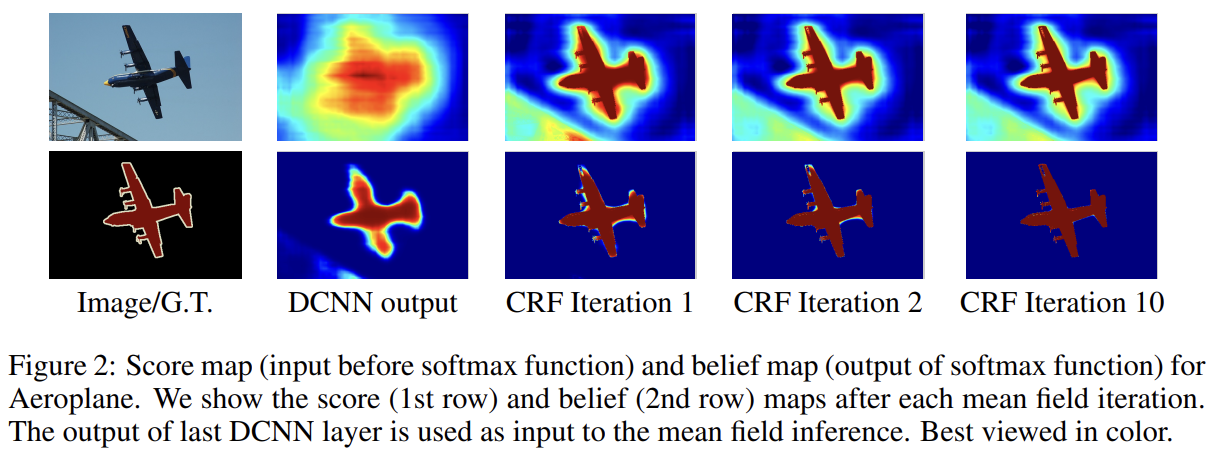
Fig 2에서 볼 수 있듯 DCNN score maps는 사물의 존재와 거친 위치를 예측할 수 있지만 정확한 윤곽을 짚는 데는 덜 적합하다. classification accuracy와 localization accuracy 사이에는 자연적인 tradeoff가 있는데, max-pooling layers가 많아 CNN이 깊을수록 classification tasks는 성공적이지만 증가된 (spatial) invariance와 큰 receptive field가 scores로부터 position을 추론하기 힘들게 한다.
논문은 DCNN의 recognition capacity와 fully connected CRFs의 fine-grained localization accuracy를 결합하는 새로운 방법을 도입해 localization challenge를 다루는 데 성공적임을 보일 것이다.
- FULLY-CONNECTED CONDITIONAL RANDOM FIELDS FOR ACCURATE LOCALIZATION
FIg 2에서 볼 수 있듯 score maps이 smooth하고 homogeneous classification results를 생성하기 때문에 short-range CRFs를 사용하는 것이 해로울 수 있다. short-range CRFs의 한계를 극복하기 위해 논문은 Krahenbuhl & Koltun (2011)의 fully connected CRF model를 논문의 시스템에 통합한다. 모델은 다음과 같은 energy function을 사용한다.
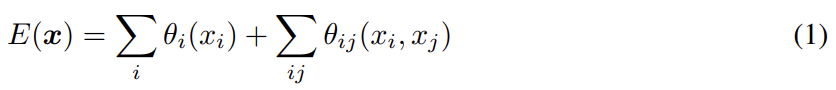
x는 pixels에 대한 label assignment다. unary potential 를 사용하며 P(xi)는 DCNN에 의해 계산된 pixel i에서의 label assignment probability이다. pairwise potential은 이며 일 때 이고 아니면 0이다(즉 Potts Model). pixel i, j가 얼마나 멀리 있든 각 pair에 대한 하나의 pairwise term이 있다. 즉, 모델의 factor graph는 fully connected다. 각 k^m은 Gaussian kernel이고 pixel i와 j로부터 추출된 features f에 의존하며 parameter w_m으로 weight된다. bilateral position와 color terms를 사용하며 kernel은 다음과 같다.
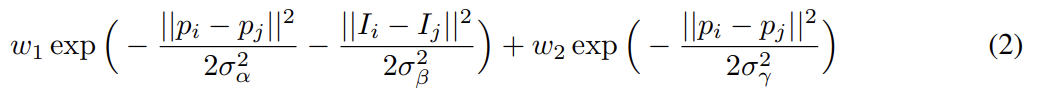
첫째 kernel은 pixel positions p와 pixel color intensities I에 의존하며 둘째 kernel은 pixel positions에만 의존한다. hyper parameters σα, σβ, σγ는 Gaussian kernels의 "scale"을 조절한다.
boundary localization accuracy를 향상시키기 위해 multi-scale prediction method도 탐구했다. 구체적으로는 input image와 첫 4개 max pooling layers의 각 output에 two-layer MLP (first layer: 128 3x3 convolutional filters, second layer: 128 1x1 convolutional filters)를 부착한다. 이들의 feature map은 main network의 last layer feature map에 concatenate된다. aggregate feature map은 softmax layer에 먹여진 후 5 * 128 = 640 channels로 된다. 새로 추가된 weights만 조정하고 네트워크의 다른 parameters는 앞선 방법으로 학습한 값으로 유지한다. fine-resolution layers로부터 extra direct connections를 도입하는 것은 (fully-connected CRF의 효과만큼 극적이지는 않지만) localization performance를 향상시킨다.
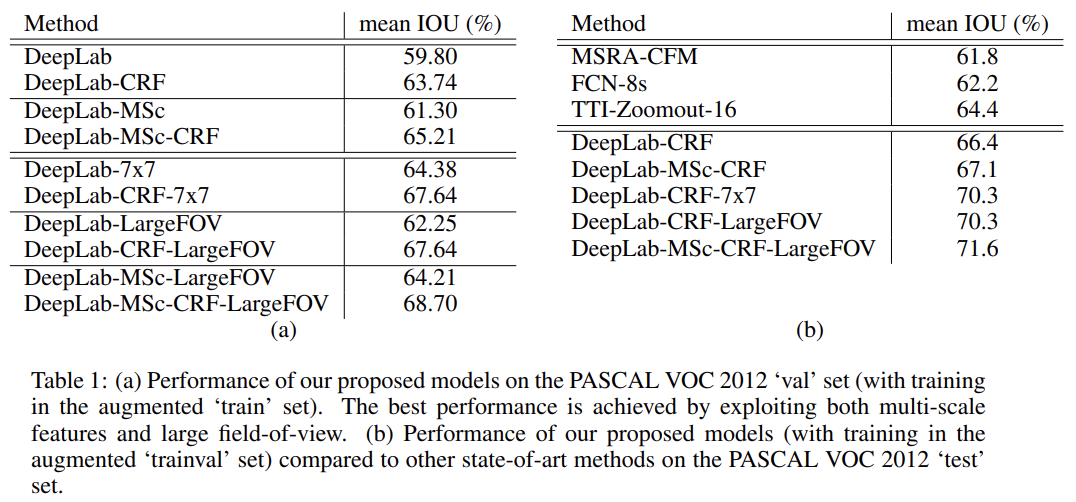
PASCAL VOC 2012 segmentation benchmark에 DeepLab를 실험한다.
학습은 DCNN과 CRF training stages를 나눠 piecewise training을 하며 CRF training 도중 DCNN에 의해 제공된 unary terms는 고정되었다고 가정한다.
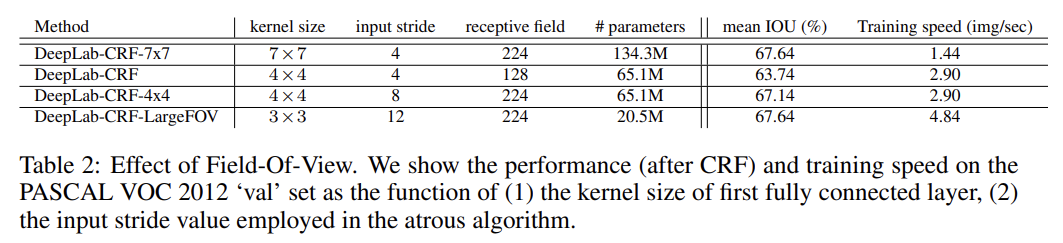

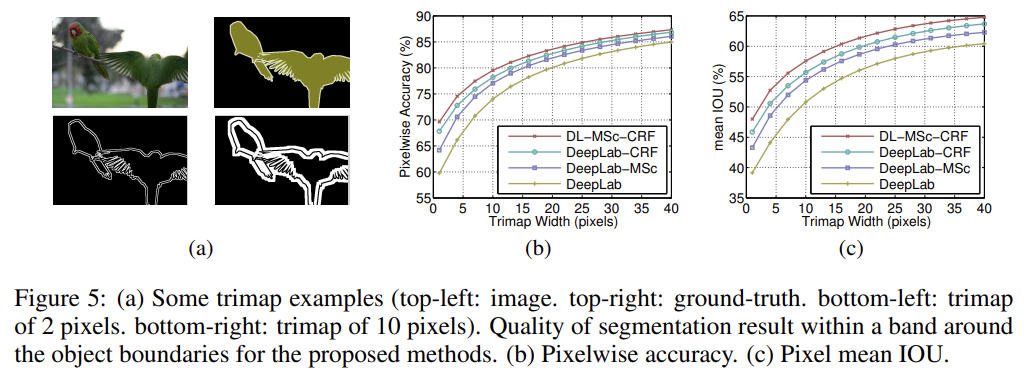


실험 결과 설명은 생략한다.
atrous 알고리즘이나 CRF, kernel 식에 대해서는 첨부한 포스트들이 설명을 잘 해놨다.
Fig 3에 잘 나와있듯 DCNN으로 score map을 뽑고 이걸 bilinear interpolation으로 해상도를 원본 크기로 늘린 후 CRF를 통해 후처리해서 sharpening하는 것이다.
