
오늘 리뷰할 논문은 SPADE(Spatially-Adaptive Denormalization), GauGAN 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] Semantic Image Synthesis with Spatially-Adaptive Normalization
- [논문리뷰]Semantic Image Synthesis with Spatially-Adaptive Normalization: GauGAN
Summary
논문은 특정 input data에 conditioning하여 photorealisstic image를 생성하는 Conditional image synthesis task 중에서 특히 semantic segmentation mask를 photorealistic image로 변환하는 semantic image synthesis 과제에 집중한다.
기존의 방법들은 convolutional, normalization, nonlinearity layers로 이루어진 deep network에 semantic layout을 input으로 넣는 방식인데 이는 normalization layers가 semantic mask에 실린 정보를 "wash away"하는 문제 때문에 suboptimal하다. 논문은 이 문제를 해결하기 위해 spatially adaptive, learned transformation을 통해 activations을 조절하는 spatially-adaptive normalization layer을 사용한다.
L을 semantic label을 의미하는 정수들의 집합, 을 semantic segmentation mask라고 두자. m의 각 entry는 pixel의 semantic label을 의미한다. 과제의 목표는 input segmentation mask m을 photorealistic image로 변환하는 mapping function을 배우는 것이다.
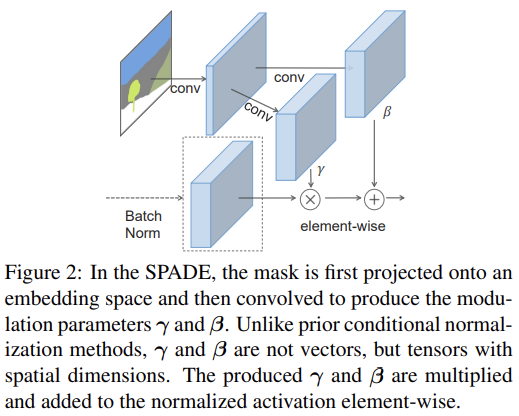
를 N samples을 가진 batch에 대한 network의 i-th layer의 activation이라고 하자. 논문은 SPatially-Adaptive (DE)normalization (SPADE)이라는 새로운 conditional normalization 방식을 제안한다. Batch Normalization과 비슷하게 activation이 channel-wise manner로 normalize되고 learned scale(γ)과 bias(β)로 조절된다. 위치 에서 activation value는 식 (1)과 같다.
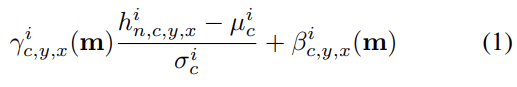
h는 normalization하기 이전 activation이고 는 channel c에서 activation의 mean과 standard deviation이다.
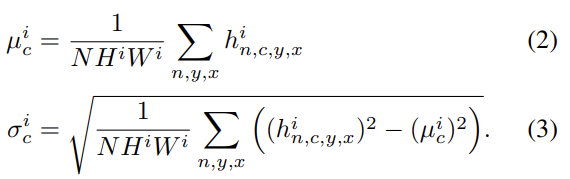
는 normalization layer의 learned modulation parameters이다. BatchNorm과 달리 이들은 input segmentation mask에 의존하고 위치 (y, x)에 따라 달라진다. m을 i-th activation map에서 scaling, bias value로 변환하는 함수 를 구현하는 것은 단순히 two-layer convolutional network으로 사용했다.
사실 SPADE는 이미 존재하는 normalization layers들의 일반화라고 볼 수 있다. segmentation mask m을 image class label로 교체하고 modulation parameters를 spatially-invariant하게 설정하면 Conditional BatchNorm이 된다. 그러니 spatially-invariant conditional data를 넣으면 SPADE는 Conditional BatchNorm과 같은 결과를 만든다. m을 real image로 바꾸고 modulation parameters를 spatially-invariant하게 두고 N = 1로 세팅하면 AdaIN이 된다. modulation parameters가 input segmentation mask에 adaptive하기 때문에 SPADE는 semantic image synthesis에 더 잘 suit되어있다.
SPADE를 사용하면 generator의 첫 layer에 segmentation map을 input으로 넣을 필요가 없다. learned modulation parameters가 이미 label layout에 대한 충분한 정보를 encode했기 때문이다. 따라서 논문은 generator의 encoder 부분을 버리고 더 가벼운 network로 만들었다. 또 기존의 class-conditional generators와 비슷하게 SPADE generator도 random vector을 input으로 넣어서 multi-modal synthesis를 위한 간단하고 자연스러운 방법을 제공한다.
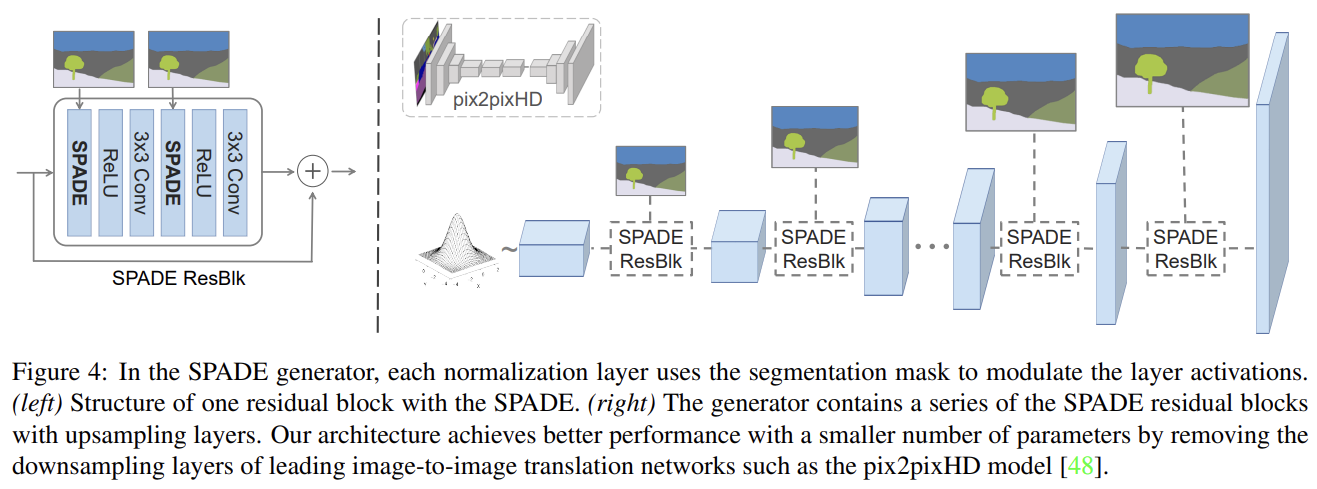
Fig 4는 여러 ResNet blocks과 upsampling layers를 가진 generator의 architecture다. 모든 normaliztion layers의 modulation parameters는 SPADE를 통해 학습된다. 각 residual block이 다른 scale에서 작동하기 때문에 spatial resolution을 맞추기 위해 semantic mask를 downsample한다.
pix2pixHD [48]에서 사용한 것과 동일한 multi-scale discriminator와 loss function을 학습시키되 least squared loss term만 hinge
loss term으로 교체했다.

SPADE가 잘 작동하는 이유는 semantic information을 더 잘 보존하기 때문이다. single label을 지닌 segmentation mask에 convolution을 적용한 후 normalization하는 간단한 module을 생각해보자. 이 세팅 하에 convolution output은 또 (서로 다른 label이 서로 다른 uniform value를 가지는 식으로) uniform하다. output에 InstanceNorm을 적용하면 input semantic label이 무엇인지 상관없이 normalized activation이 모두 0이 될 것이다. 따라서 semantic information이 전부 사라진다. 일반적으로 segmentation mask가 적은 uniform region을 지니기 때문에 normaliztion을 적용할 때 information loss 문제가 발생하게 된다.
이 문제를 지닌 pix2pixHD의 generator과 달리 SPADE Generator에선 segmentation mask가 normalization 없이 spatially adaptive modulation를 통해 feed된다. 이전 layer로부터의 activation만이 normalize된다. 따라서 SPADE generator가 semantic information을 더 잘 보존하면서 normalization의 이점을 누릴 수 있다.
random vector을 input으로 넣음으로써 generator은 multi-modal synthesis를 하는 간단한 방법을 제공한다. 즉 real image를 random vector로 가공하는 encoder를 붙여서 generator에 넣을 수 있다. encoder와 generator은 VAE를 형성한다. encoder은 이미지의 style을 포착하고 generator은 original image를 재구성하기 위해 SPADE를 사용해서 encoded style과 segmentation mask information을 결합한다. Fig 1처럼 encoder는 test time에 style guidance network로 작동하여 target image의 style을 포착한다. training에는 KL-Divergence loss term을 추가했다.
generator와 discriminator 모두 Spectral Norm를 적용했고 ADAM optimizer을 사용했다. 데이터셋은 COCO-Stuff, ADE20K, ADE20K-outdoor, Cityscapes dataset, Flickr Landscapes를 사용했다.
평가는 합성된 이미지에 semantic segmentation model를 돌려서 predicted segmentation mask가 ground truth input과 얼마나 맞는지 비교한다. segmentation accuracy를 측정하기 위해선 mean Intersection-over-Union (mIoU)과 pixel accuracy (accu)를 사용한다. 각 데이터셋에 대한 SOTA segmentation network를 사용했다. (DeepLabV2 for COCO-Stuff, UperNet101 for
ADE20K, DRN-D-105 for Cityscapes) mIoU, accu에 추가로 Frechet Inception Distance (FID)를 사용해서 합성된 결과의 분포와 real image distribution의 거리를 측정했다.
baseline으로는 pix2pixHD model, cascaded refinement network (CRN), semiparametric image synthesis method (SIMS) 3개를 사용했다.

Table 1에서 볼 수 있듯이 GauGAN은 모든 데이터셋에서 SOTA 모델들보다 성능이 좋다.

visual quality도 더 좋고 artifact도 더 적음을 볼 수 있다.
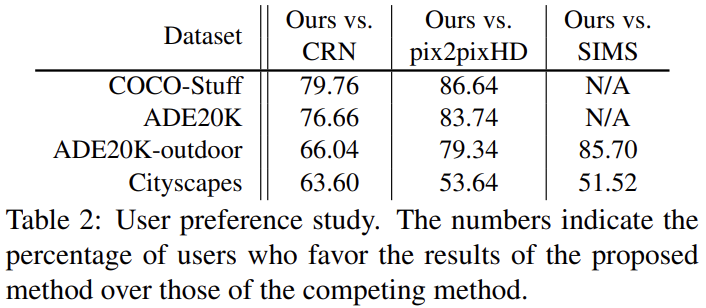
Amazon Mechanical Turk (AMT)를 사용해 visual fidelity를 평가하기도 했다. AMT workers에게 input segmentation mask과 두 syntehsis output을 주고 둘 중 segmentation mask에 상응하는 쪽을 고르라고 했다. Table 2는 모든 데이터셋에서 사용자들이 baseline에 비해 GauGAN의 결과를 선호함을 보여준다.
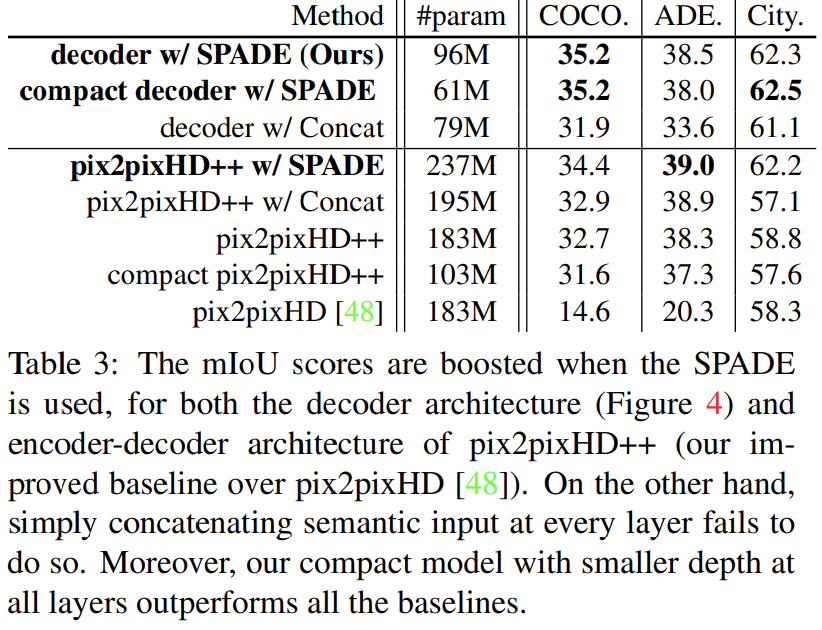
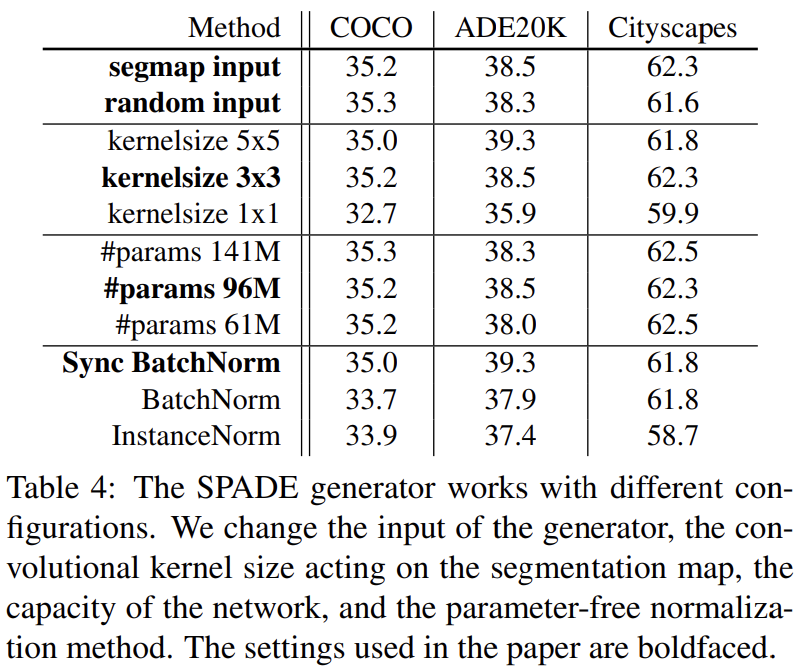
Table 3는 SPADE의 효과를 확인하기 위해 SPADE를 적용 할 때와 안할 때를 비교하고, Table 4는 여러 세팅에서 성능을 비교한다. 자세한 설명은 생략하겠다.

Fig 9는 Flickr Landscape dataset에 대한 multi-modal synthesis 결과다. 동일한 input segmentation mask에 대해 다른 noise input을 sample에서 서로 다른 output을 얻었다.
Fig 1처럼 유저가 segmentation mask를 그려서 상응하는 landscape image를 render할 수도 있다. 추가로 input noise를 image encoder로 얻은 embedding vector로 대체하여 유저가 external style image를 고를 수도 있다.
Strengths
- Conditional BatchNorm의 spatial-invariant한 속성을 Spatially-Adaptive하게 바꾼((y, x) 위치마다 γ, β를 다르게 학습) SPADE으로 wash away 문제를 해결했다.
- SPADE를 여러 normalization 방식에 적용할 수 있어 다양하게 사용할 수 있는 것 같다. (대신 SPADE의 용도 자체가 semantic image synthesis 과제에서 wash away를 해결하기 위한 것이라 범용성이 좋지는 않을 수도)
- 질적 평가, 양적 평가 둘 다 baseline보다 뛰어난 결과를 보였다.
- multi-modal 결과도 우수했다.
