오늘 리뷰할 논문은 SPPNet 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] SPPNet(2014) 설명 (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
- [논문 리뷰] SPPnet (2014) 리뷰, Spatial Pyramid Pooling Network
Summary
현존하는 CNN은 fixed-size (e.g., 224×224) input image을 요구한다. 이는 인위적인 요구이며, 임의의 크기의 사진을 인식하는 정확도를 감소시킬 수 있다. 논문은 이런 요구를 제거하기 위해 네트워크를 다른 pooling strategy, “spatial pyramid pooling”로 무장시킨다. SPPNet은 image size/scale에 무관하게 fixed-length representation을 생성할 수 있다. pyramid pooling은 object deformations에도 강인하다. SPPNet은 CNN 기반 image classification 방법들을 향상시킨다. ImageNet 2012 dataset에서 SPPNet은 다양한 CNN의 정확도를 향상시킨다. Pascal VOC 2007와 Caltech101 datasets에서 SPPNet은 single full-image representation을 사용하고 fine-tuning을 사용하지 않고 SOTA를 달성한다.
SPPNet의 효과는 object detection에도 상당하다. SPPNet을 사용해 전체 사진에서 한 번에 feature maps을 계산하고 detectors을 학습시키기 위한 fixed-length representations을 생성하기 위해 arbitrary regions (sub-images)에서 features를 pool한다. 이 방법은 반복적으로 convolutional features을 계산하는 것을 피한다. Pascal VOC 2007에서 test image를 처리할 때 이 방법은 R-CNN보다 24-102배 빠르고 성능은 비슷하거나 더 좋다.
ImageNet Large Scale Visual Recognition Challenge (ILSVRC) 2014에서 SPPNet은 object detection에서 2등, image classification에서 3등을 차지한다.
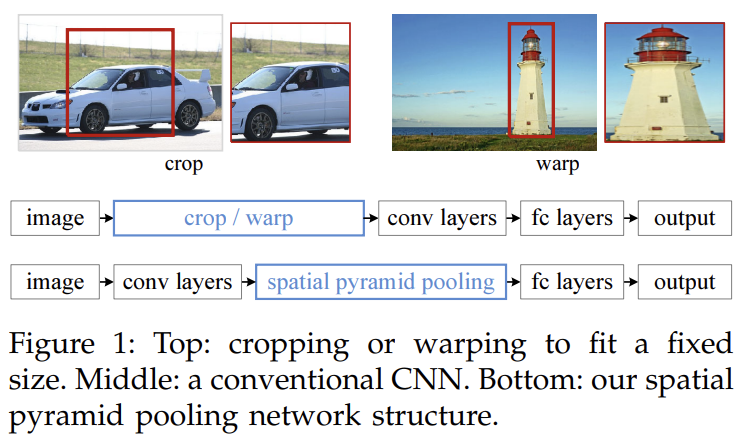
최근 CNN은 임의의 크기의 사진에 적용되었을 때 cropping이나 warping으로 input image를 고정된 크기로 조정한다. 그러나 cropped region은 전체 object를 보유하지 않을 수 있고 warped content는 원치 않는 지리적 왜곡을 초래할 수 있다.
논문은 네트워크의 fixed-size constraint를 제거하기 위해 spatial pyramid pooling (SPP)을 도입한다. 구체적으로는 SPP layer를 마지막 convolutional layer 꼭대기에 추가한다. SPP layer은 features를 pool해서 fixed-length outputs을 생성하고 이는 fully-connected layers나 다른 classifiers에 먹여진다. 다시 말해 처음에 cropping/warping를 피하기 위해 conv layers와 FC layers 사이에서 information “aggregation”을 수행하는 것이다.
Bag-of-Words (BoW) model의 확장형으로서 Spatial pyramid pooling은 CV에서 가장 성공적인 방법 중 하나다. 이는 사진을 finer에서 coarser levels로 분할하고 그들 내의 local features을 종합한다. 논문은 SPPNet의 여러 주목할만한 특징을 짚는다. 1) 기존의 sliding window pooling은 못하는 반면 SPPNet은 input size에 무관하게 fixed-length output을 생성할 수 있다. 2) SPP는 multi-level spatial bins을 사용하고 반대로 sliding window pooling는 single window size만 사용한다. Multi-level pooling은 object deformations에 강인하다. 3) SPP는 input scales의 유연성에 고맙게도 variable scales에서 추출된 features를 pool할 수 있다.
testing뿐 아니라 training에서도 임의의 크기의 images/windows에서 representations을 생성할 수 있어 scale-invariance을 향상시키고 overfitting을 감소한다. 논문은 간단한 multi-size training method을 고안했다. single network가 variable input sizes를 수용하기 위해 모든 parameters를 공유하는 multiple networks로 single network를 근사했다. 각 networks는 fixed input size을 이용해 학습된다. 각 epoch에서 network를 주어진 input size로 학습시키고 다음 epoch에 다른 input size로 전환한다. 실험은 이런 multi-size training이 전통적인 single-size training처럼 수렴하고 더 좋은 정확도로 이끔을 보여준다.

conv layers는 임의의 input size를 수용하지만 variable sizes의 output을 생성한다. classifiers (SVM/softmax)나 fully-connected layers는 fixed-length vectors를 요구한다. 그런 vectors는 features를 함께 pool하는 Bag-of-Words (BoW) approach로 생성될 수 있다. Spatial pyramid pooling은 local spatial bins 내에서 pooling함으로써 spatial information을 유지한다는 점에서 BoW를 향상시킨다. 이 spatial bins는 image size에 비례하는 sizes를 가지며 따라서 bins의 수는 image size에 무관하게 고정된다. 이는 sliding window 개수가 input size에 의존한 기존 sliding window pooling와 대비된다.
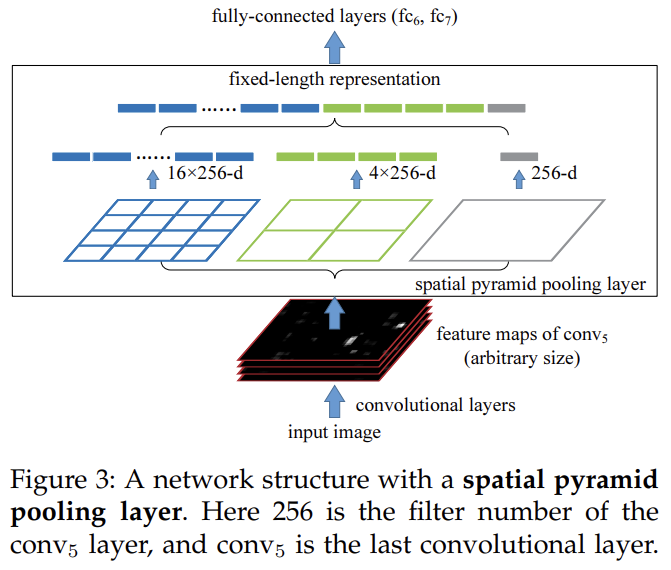
last pooling layer를 (예컨대 마지막 conv layer 다음의 pool5를) spatial pyramid pooling layer로 교체한다. 각 spatial bin에서 각 filter의 responses를 pool한다(논문에선 max pooling을 사용한다). SPP의 output은 kM-dimensional vectors이다. M은 bins의 개수, k는 마지막 conv layer의 filter 개수다. fixed-dimensional vectors는 FC layer로의 input이다.
흥미롭게도 coarsest pyramid level은 전체 image를 cover하는 single bin을 가진다. 이는 사실 “global pooling” operation이며 전통적인 Bag-of-Words method에 해당한다.
Single-size training, Multi-size training 등 네트워크 훈련 설명은 생략하겠다.
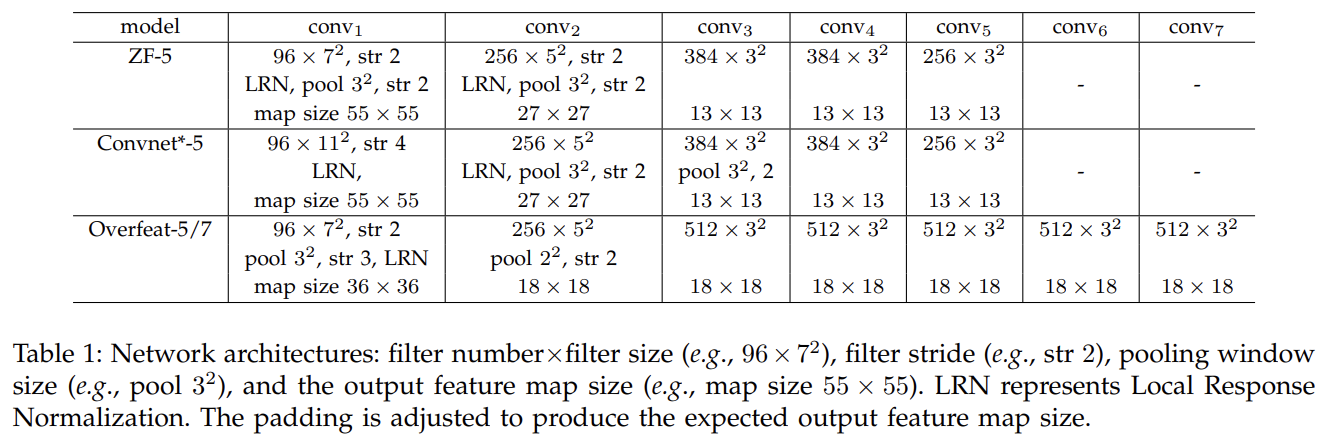
ImageNet 2012 Classification 실험에 사용한 baseline architectures은 위와 같다.
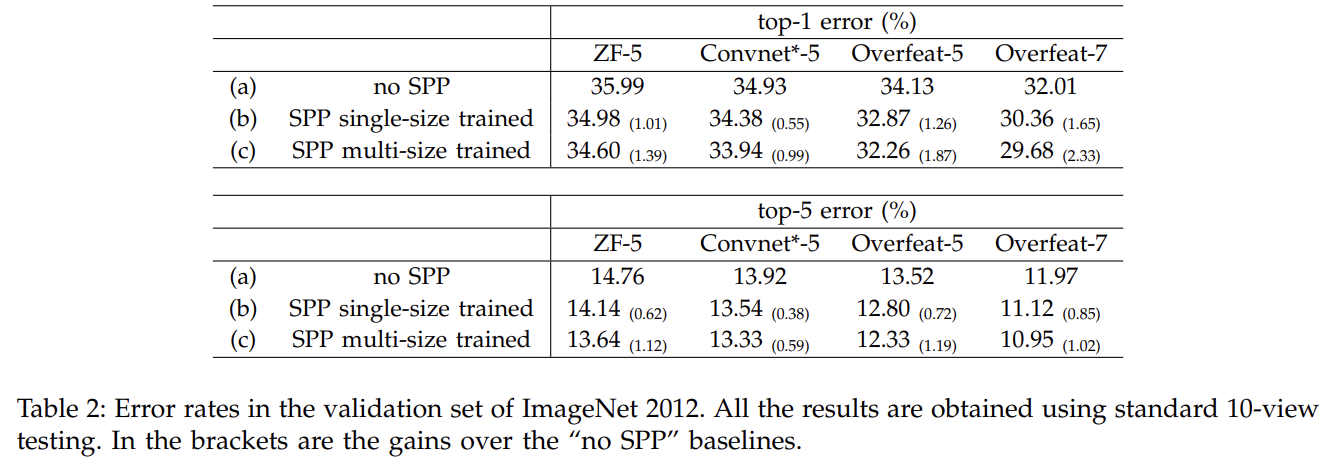
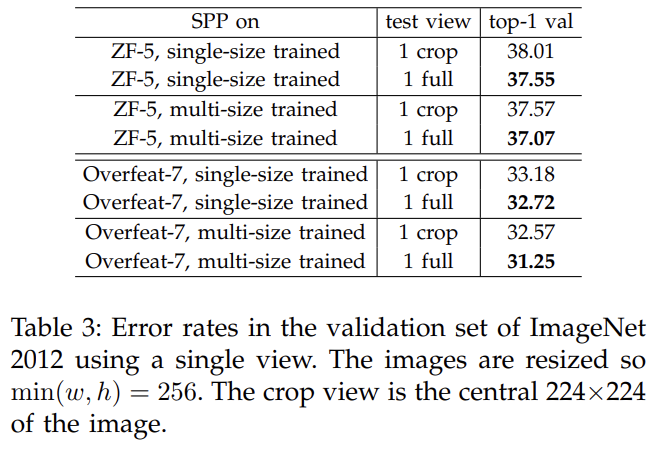
실험 설명은 생략한다. Multi-level Pooling과 Multi-size Training과 Full-image Representations이 정확도를 향상시켰다.
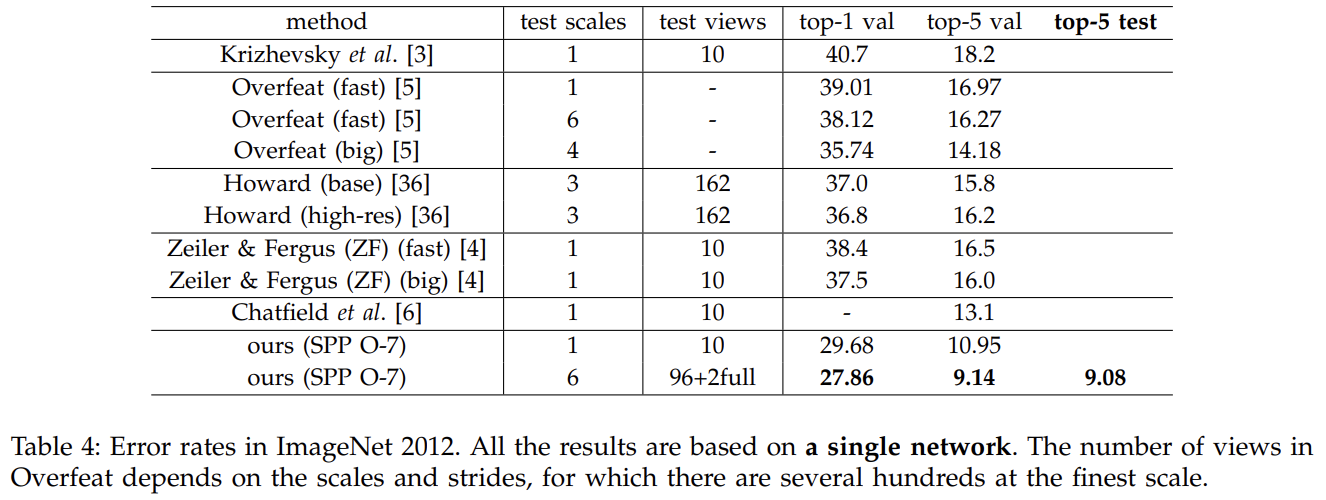
Tab 4는 ILSVRC 2012에 기존 SOTA와 비교한 결과다.
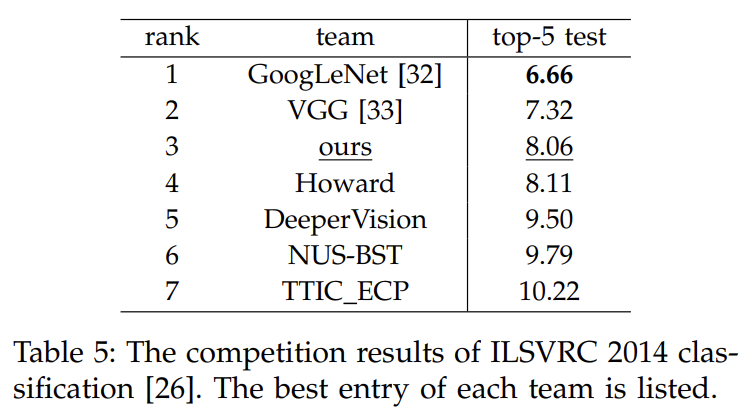
Tab 5는 ILSVRC 2014에 제출한 결과다. testing set에 single model top-5 error rate는 9.08%이고 11 모델을 결합한 결과가 8.06%이다.
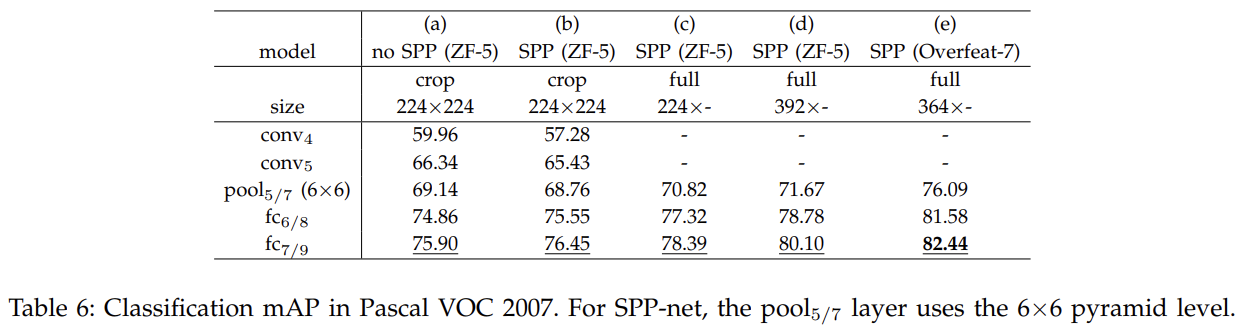
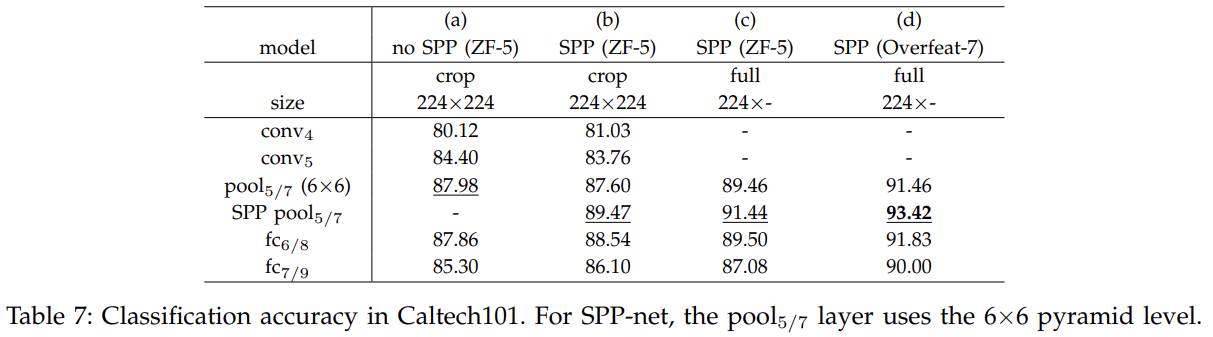
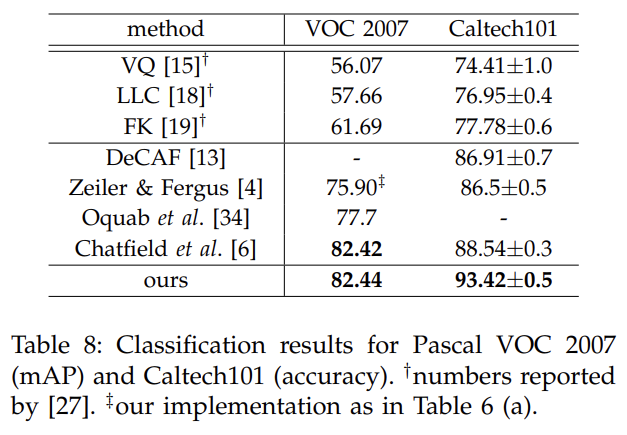
VOC 2007 Classification와 Caltech101에도 실험한다.
object detection의 SOTA인 R-CNN의 경우 먼저 selective search를 통해 각 image에서 2,000 candidate windows을 추출한다. 그 다음 각 window 내 image region은 fixed size (227×227)로 warp된다. 각 window의 feature를 추출하기 위해 pre-trained deep network이 사용된다. 그 다음 detection을 위해 binary SVM classifier이 이 features에 학습된다. R-CNN은 강력하지만 이미지당 2000 windows에 CNN을 반복적으로 적용해서 시간이 소모된다. testing에서 Feature extraction이 주요 timing bottleneck이다.
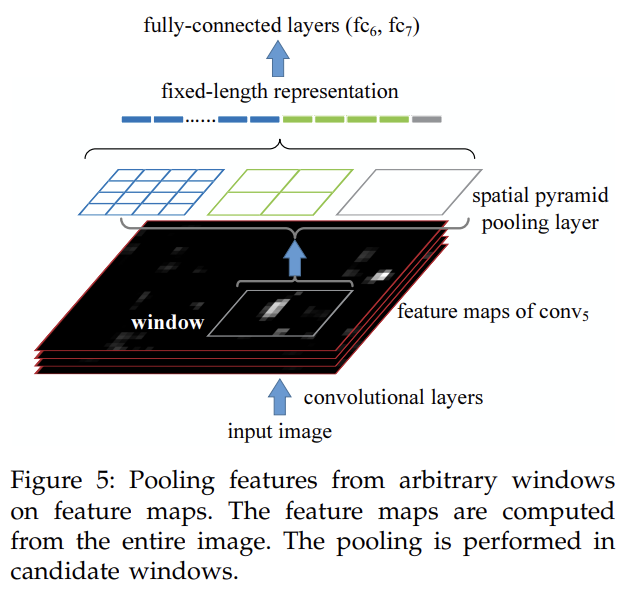
SPPNet도 object detection에 사용될 수 있다. 전체 image로부터 한 번만 feature maps를 추출하고 feature maps의 각 candidate window에 이 window의 fixed-length representation을 pool하기 위해 spatial pyramid pooling을 적용한다. time-consuming convolutions이 한 번만 적용되기 때문에 orders of magnitude 빠르다.
R-CNN은 image regions에서 직접 window-wise features을 추출하는 반면 우리 방법은 feature maps의 regions에서 추출한다.
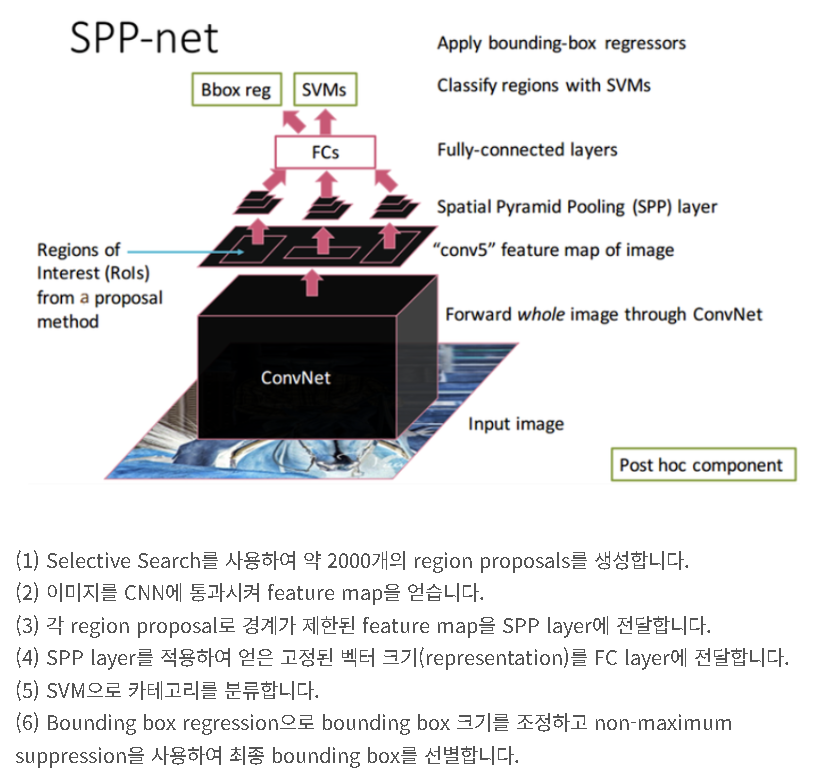
이 포스트에서 정리를 잘해놨다.
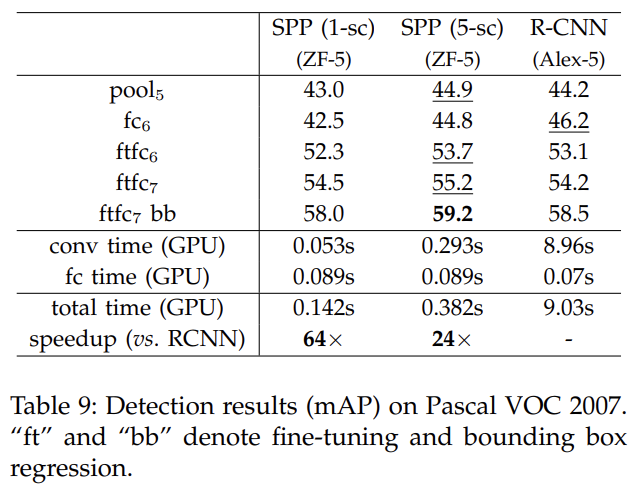
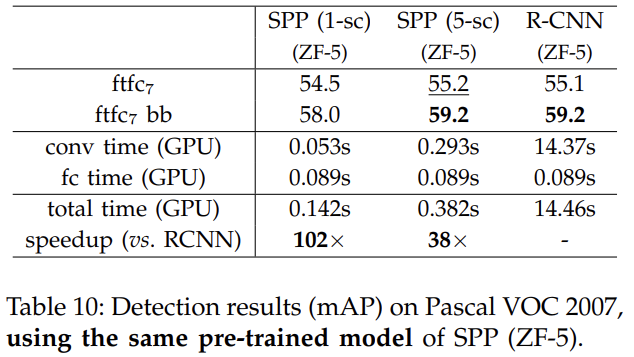
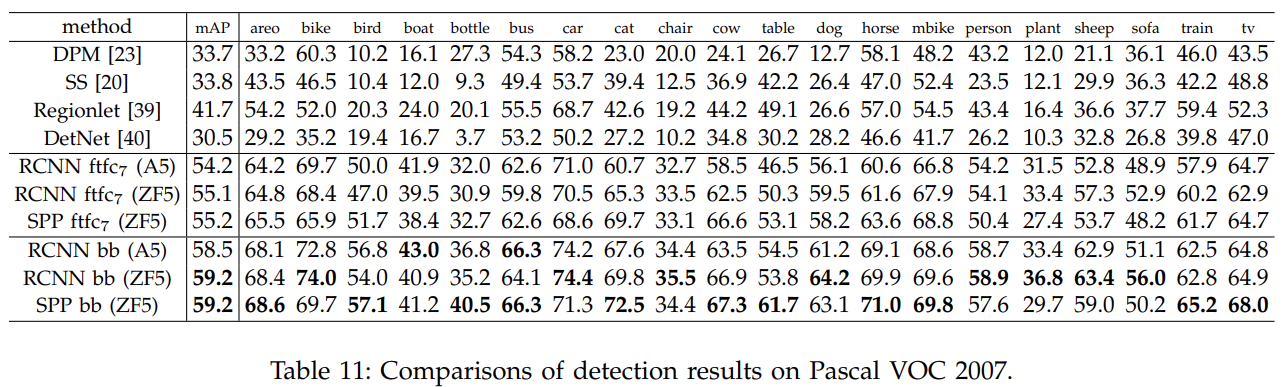

실험 결과 설명은 생략한다.
Strengths
- R-CNN보다 시간/연산 효율적이다.
- spatial pyramid pooling 아이디어가 간단해서 범용적으로 적용하기 쉽다.
- 다양한 size/scale의 input image를 받을 수 있다.
2014년 논문이라 아이디어가 단순했다. 단순히 다양한 scale로 pool해서 aggregate하는 거라 corse/fine 정보를 더 사용해서 기존보다 성능이 좋은 것 같다.
