오늘 리뷰할 논문은 StackGAN이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [Paper Review] StackGAN
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
- [paper review] StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
논문은 text description에서 high-quality, 256×256 photo-realistic image를 생성하기 위해 Stacked Generative Adversarial Networks (StackGAN)을 제안한다. high-resolution photo-realistic image를 생성한다는 어려운 과제를 sketch-refinement process를 통해 두 subproblems로 분리해 처리한다. Stage-I GAN은 text description에 기반해 low-resolution image를 생성하고 Stage-II GAN은 Stage-I GAN의 결과와 text description을 input으로 받아 high-resolution image를 생성한다. refinement process를 통해 Stage-I GAN의 결과를 바로잡을 수 있고 photo-realistic detail도 더할 수 있다. 생성되는 이미지의 diversity를 늘리고 conditional-GAN의 training을 안정화하기 위해 latent conditioning manifold의 smoothness를 장려하는 새로운 Conditioning Augmentation technique를 소개한다.

GAN이 text description으로부터 high-resolution photo-realistic images를 생성하게 하는 과제는 몹시 어렵다. SOTA model들이 단순히 upsampling layers를 추기하는 방식은 학습 불안정을 초래하여 nonsensical output을 생성한다.
과제의 주된 어려움은 natural image distribution의 support와 implied model distribution의 support가 high dimensional pixel space에서 overlap되지 않을 수 있다는 것이다. 이 문제는 resolution이 커질수록 심해진다. 그래서 논문은 앞서 설명했듯 GAN을 두 단계로 분리한다. roughly aligned low-resolution image에서 생성된 model distribution의 support는 image distribution의 support와 더 잘 겹칠 가능성이 있다. 이것이 Stage-II GAN이 better high-resolution image를 생성할 수 있는 이유다.
또 training text-image pairs의 한정된 개수가 text conditioning manifold에 sparsity를 초래하고 이 sparsity는 GAN을 학습하기 어렵게 한다. 따라서 논문은 latent conditioning manifold의 smoothness를 장려하는 새로운 Conditioning Augmentation technique를 제안한다. 이는 conditioning manifold에 small random perturbations를 허용해 합성된 이미지의 diversity를 증가시킨다.
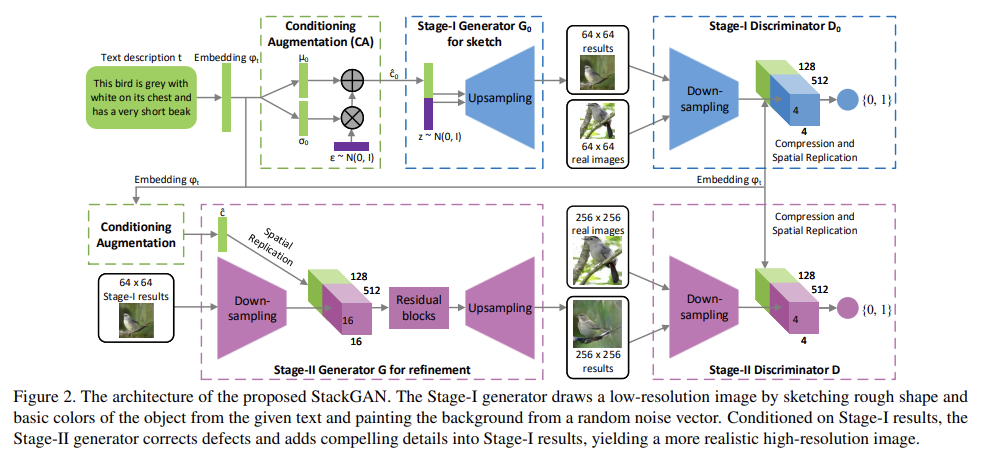

처음으로 text description t가 encoder에 의해 encode되어 text embedding 를 만든다. 기존의 연구에선 text embedding이 nonlinear하게 transform되어 generator의 input으로써 conditioning latent variables를 생성한다. 그러나 text embedding의 latent space는 보통 high-dimensional ( > 100 dimension)해서 한정된 숫자의 data로는 latent data manifold에 discontinuity를 발생하는 문제가 있다. 문제를 해결하기 위해 additional conditioning variables 를 생성하는 Conditioning Augmentation technique을 소개한다. fixed conditioning text variable c와 달리 independent Gaussian distribution 로부터 랜덤하게 latent variables 를 sample한다. 여기서 mean µ(ϕt)과 diagonal covariance matrix Σ(ϕt)는 text embedding ϕt의 함수다. conditioning augmentation은 더 많은 training pairs를 생성함으로써 conditioning manifold 위의(along) 작은 변동(perturbation)에 대한 robustness를 장려한다. conditioning manifold의 smoothness를 더 장려하고 overfitting을 막기 위해 generaotr의 objective에 다음과 같은 regularization term을 추가한다.
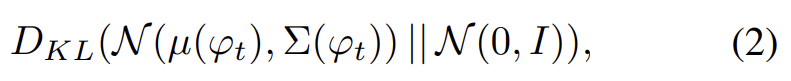
이는 standard Gaussian distribution과 conditioning Gaussian distribution 사이 Kullback-Leibler divergence (KL divergence)이다. 동일한 문장이 보통 다양한 pose와 appearance를 가진 object에 대응되기 때문에 Conditioning Augmentation에 도입된 랜덤성은 text to image translation을 modeling하는데 유용하다.
Stage-I GAN은 object에 대한 rough shape와 correct color을 그리는데 집중한다. variation을 가진 채 의 의미를 포착하기 위해 text embedding에 대한 Gaussian conditioning variables 가 에서 sample된다. 와 random variable z에 condition되어 Stage-I GAN은 번갈아가며 식 (3)을 최대화하여 discriminator을 학습하고 식 (4)를 최소화하여 generator을 학습한다.
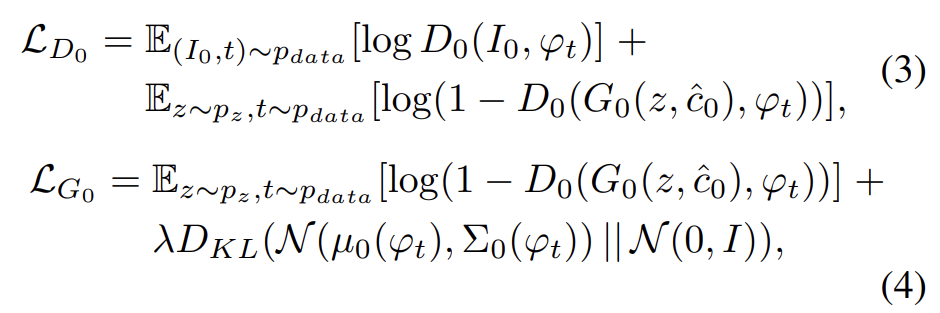
real image 과 text description t는 true data distribution 에서 온 것이다. z는 주어진 distribution (논문에서는 Gaussian)에서 sample한 noise vector다. λ는 식 (4)의 두 항을 balance하는 regularization parameter다(모든 실험에서 λ = 1를 사용했다). reparameterization trick[13]를 사용해서 가 함께 학습된다.
G에서 text conditioning variable 을 얻기 위해 먼저 text embedding 가 fully connected layer로 들어가 Gaussian distribution 을 위해 µ0와 σ0 (σ0는 Σ0의 diagonal values)을 산출한다. 그리고 Gaussian distribution에서 이 sample된다. dimensional conditioning vector 은 다음과 같이 계산된다.
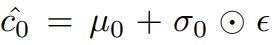
저 연산자는 element-wise multiplication이고 이다.
(다시 말해 Conditioning Augmentation 은 conditioning vector 의 dimension을 조정할 수 있으면서 conditioning vector에 어느 정도의 랜덤한 작은 변동을 부여할 수 있는 방법인 것)
다음으로 은 dimensional noise vector와 concatenate되어 series of up-sampling blocks를 거쳐 image를 생성한다.
D에선 text embedding 가 먼저 fully-connected layer를 통해 dimension으로 축소되고 tensor을 형성하기 위해 공간적으로 복제된다. 한편 image는 spatial dimension을 가질 때까지 series of down-sampling blocks을 통과한다. 그 후 image filter map은 channel dimension을 따라(along) text tensor와 concatenate된다. 결과 tensor는 1×1 convolutional layer에 먹여져 image와 text에 걸쳐(across) feature를 학습한다. 마지막으로 하나의 node를 가진 fully-connected layer가 decision score를 산출한다.
Stage-I GAN의 결과는 주로 vivid object part가 부족하고 shape distortion을 포함한다. text에 있는 몇 detail이 빠져있을 수도 있다. Stage-II GAN는 low-resolution images와 text embedding에 기반해 Stage-I 결과물의 결함을 수정한다.
low-resolution result 과 Gaussian latent variables 에 conditioning하여 Stage-II GAN의 G와 D는 번갈아가며 식 (5)를 최대화하고 식 (6)을 최소화하는 식으로 학습된다.
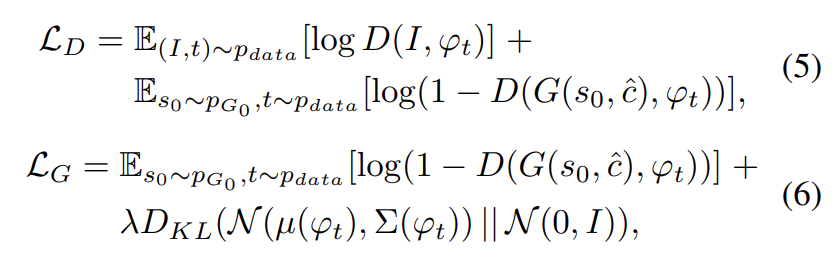
original GAN 식과 달리 여기서는 random noise z를 사용하지 않는데, 이는 randomness가 이미 s0에 포함되어있다고 가정하기 때문이다. Stage-I GAN의 과 여기서의 Gaussian conditioning variables 는 동일한 pre-trained text encoder를 사용하여 동일한 text embedding 를 생성한다. 그러나 Stage-I과 Stage-II Conditioning Augmentation는 (서로 다른 mean과 standard deviation을 산출하는) 서로 다른 fully connected layers를 가진다. 이를 통해 Stage-II GAN는 Stage-I에서 놓친, text embedding 내의 유용한 정보를 포착하도록 학습한다.
Stage-II generator는 residual block을 가진 encoder-decoder 구조로 만든다. Stage-I과 비슷하게 text embedding 는 dimensional text conditioning vector 를 생성하기 위해 사용되며, 이는 공간적으로 복제되어 tensor를 형성한다. 한편 Stage-I result 는 의 spatial size를 가질 때까지 여러 down-sampling blocks (=encoder)를 통과한다. image feature와 text feature이 channel dimension을 따라(along) concatenate된다. text features와 연결된(coupled) encoded image features는 image와 text featues을 걸쳐(across) multi-modal representations를 학습하도록 설계된 여러 residual blocks을 통과한다. 마지막으로 series of up-sampling layers (=decoder)가 W × H high-resolution image를 생성한다.
discriminator은 Stage-I discriminator의 구조와 거의 똑같은데 이 단계에서는 image resolution이 더 크기 때문에 extra down-sampling blocks만 더 붙였다. GAN이 image와 conditioning text 사이 better alignment를 배우도록 강제하기 위해서 vanilla discriminator을 쓰기보단 Reed et al.이 제안한 matching-aware discriminator을 사용했다. training 중 D는 real images와 상응하는 text descriptions을 positive sample pairs로 받는다. negative sample pairs는 두 종류인데 첫째는 real images with mismatched text embeddings이고 둘째는 synthetic images with their corresponding text embeddings이다.
up-sampling blocks은 nearest-neighbor upsampling과 뒤따르는 3×3 stride 1 convolution으로 이루어진다. 마지막 걸 제외하고 모든 convolution 직후에 batch normalization과 ReLU activation이 적용된다. residual blocks는 3×3 stride 1 convolutions, Batch normalization과 ReLU로 구성된다. 128×128 StackGAN에는 residual block 2개, 256×256 models에는 4개가 사용된다. down-sampling blocks는 Batch normalization을 안 하는 첫째 ;ayer만 제외하면 4×4 stride 2 convolutions, Batch normalization, LeakyReLU로 구성된다. 를 default로 사용한다.
평가를 위해 text-to-image synthesis에 두 SOTA 모델인 GAN-INT-CLS [26]와 GAWWN [24]를 비교한다. 또 StackGAN의 전체적인 디자인과 중요한 component를 조사하기 위해 여러 baseline을 사용한다. (설명 생략) 또 두 stage에 inputting text가 유용한지 조사한다.
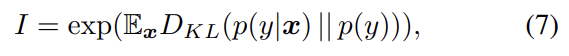
데이터셋은 CUB, Oxford-102, COCO을 사용하고 양적 평가를 위해선 “inception score”를 사용한다. 또 inception score이 sample의 visual quality가 human perception과 일관적인지는 잘 반영해도 주어진 text description에 잘 condition되었는지는 반영하지 못하므로 human evaluation도 한다.
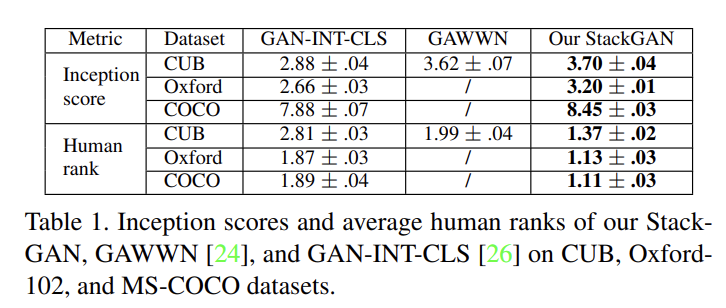


세 데이터셋에서 모두 StackGAN은 best inception score와 average human rank를 얻었다.

StackGAN은 Stage-I image의 background를 transfer해서 Stage-II에서 more realistic, higher resolution이도록 fine-tune하는 능력도 있었다.

또 StackGAN은 단순히 training sample을 memorize하는 것이 아니라 complex underlying language-image relations을 포착했다. Stage-II discriminator에서 generated images와 모든 training images의 visual features를 추출해 각 generated image에 training set에서의 nearest neighbors를 찾아 확인했다. 그 결과 둘이 근본적으로 다름을 확인하여 memorize하는 게 아님을 알 수 있었다.
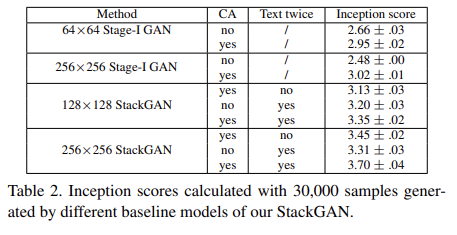


CUB dataset과 baseline models을 가지고 StackGAN의 각 component을 분석했다. 결과는 생략한다.
Strengths
- 복잡한 과제를 두 단계로 나눠서 해결한 점이 인상적이었다.
- conditioning manifold의 smoothness를 향상시키는 conditioning augmentation technique이 신기했다.
- 눈에 보이는 결과 사진이 뛰어나서 흥미로웠다.
내가 리뷰한 첫번째 multimodal 논문이 아닌가 싶다(이전에도 있었나? 기억이 안 난다).
단계별로 해상도를 조금씩 향상시킬 수 있다면 아예 원하는 고해상도가 될 때까지 무한히 recurrent하게 네트워크에 집어넣을 수도 있지 않을까?
