오늘 리뷰할 논문은 VideoBERT다.
최초의 video-text pre-training model이라고 한다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- VideoBERT - A Joint Model for Video and Language Representation Learning, CBT(Learning Video Representations using Contrastive Bidirectional Transformer) 논문 설명
- Review — VideoBERT: A Joint Model for Video and Language Representation Learning
- https://books.google.co.kr/books?id=6T9NEAAAQBAJ&pg=PA308&lpg=PA308&dq=videobert&source=bl&ots=Pi2P8DyNp6&sig=ACfU3U2j8tATLWe-2zVcR2ClRqRDCbXieQ&hl=ko&sa=X&ved=2ahUKEwj3k_KCxoOAAxUMZ94KHe_CCioQ6AF6BAgXEAM#v=onepage&q=videobert&f=false
Summary
논문은 명시적인 감독 없이 high-level features를 학습하는 joint visual-linguistic model을 제안한다. (각각 video data와 off-the-shelf speech recognition outputs에서 얻은 vector quantization로부터 이끌어낸) visual/linguistic tokens의 sequence에 대해(over) bidirectional joint distributions를 배우기 위해 BERT 위에(upon) 개발한다. action classification과 video captioning를 비롯한 다양한 tasks에 VideoBERT를 활용한다. openvocabulary classification에 직접 활용될 수 있음을 보이고 대량의 training data와 cross-modal information이 성능에 중요함을 확인한다. video captioning에서 SOTA를 달성하며 정량 평가는 high-level semantic features을 학습함을 입증한다.
기존 self-supervised learning의 proxy tasks는 texture 같은 low level features나 일 초 미만의 motion pattern 같은 short temporal scales에 집중한다. 논문은 분 단위의 longer time scale 동안 진행되는 action/event에 해당하는 high-level semantic features을 발견하고자 한다.
논문은 인간의 언어가 high-level objects와 events를 묘사하기 위해 단어를 발전시켰다는 통찰에 기반한다. 세 off-the-shelf methods을 조합해 visual domain과 linguistic domain 사이 관계를 model하는 방법을 소개한다. 세 방법은 speech를 text로 변환하는 automatic speech recognition (ASR) system, pretrained video classfication models에서 얻은 low-level spatio-temporal visual features에 적용되는 vector quantization (VQ), discrete tokens의 sequence에 대한 joint distribution을 학습하기 위한 BERT model이다.
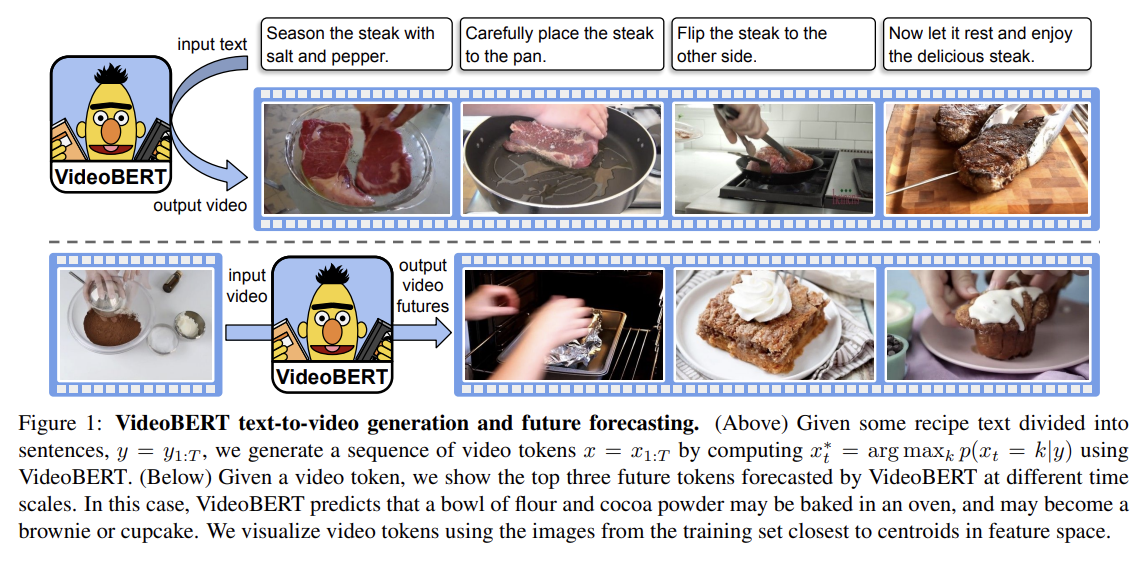
구체적으로 BERT가 p(x, y) 형태를 배우도록 적용하는 방식인데 x는 "visual words"의 sequence, y는 spoken words의 sequence다. 이런 joint model로 다양한 task를 할 수 있는데 예를 들어 Fig 1처럼 text-to-video prediction을 수행할 수도 있고 video-to-text task로 video captioning을 수행할 수도 있다.
모델을 “unimodal” fashion으로 사용할 수도 있다. 예를 들어 implied marginal distribution p(x)은 visual words에 대한 language model인데, 이는 Fig 1 아래처럼 long-range forecasting에 사용할 수 있다. 물론 미래는 불확실하지만 다른 generative models보다 더 높은 수준의 추상을 가지고 그럴듯한 추측을 생성할 수 있다.
BERT는 “masked language model” training objective을 사용해 language representation을 학습한다. 를 set of discrete tokens라고 두자. 이 set에 대한 joint probability distribution을 다음과 같이 정의할 수 있다.
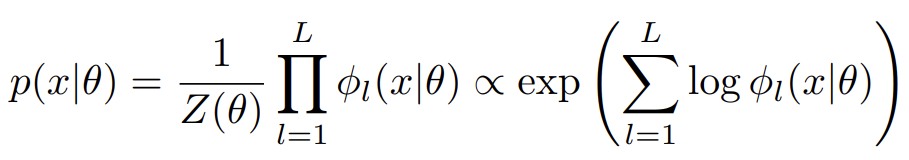
은 parmaeter θ를 가진 l’th potential function이고 Z는 partition function이다.
위의 모델은 permutation invariant하다. order information을 포착하기 위해선 각 word를 sentence 내의 position으로 "tag"해줘야 한다. BERT는 각 word tokens의 embedding과 tag의 embedding을 학습하고 둘을 합쳐 각 token에 대한 continous representation을 얻는다. 각 위치의 log potential (energy) functions은 다음과 같이 정의된다.
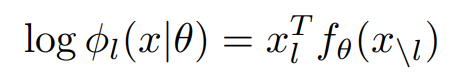
xl은 l'th token과 그것의 tag의 one-hot vector이다.
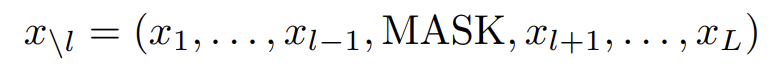
function 은 multi-layer bidirectional transformer model이며 (에 상응하는 D1-dimensional embedding vectors을 가진) tensor을 받아 tensor을 반환한다. D2는 각 transformer node의 output의 크기다. 모델은 대략 pseudo log-likelihood을 최대화하도록 학습된다.
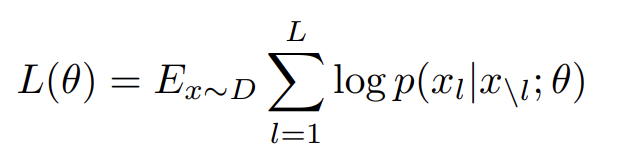
실제로는 sampling locations와 training sentences을 함으로써 (f 함수가 예측한 softmax로 계산한) logloss를 stochastically optimize할 수 있다.
BERT는 두 sentence를 concatenate함으로써 두 문장을 model하도록 확장될 수 있다. 보통 두 문장 사이 관계를 modeling하는 데 관심이 있는데, 모든 sequence에 special classification token [CLS]을 prepending하고 두 문장을 special separator token [SEP]로 연결함으로써 이를 수행한다. [CLS] token에 상응하는 final hidden state은 aggregate sequence representation으로 사용되어 classification tasks을 위한 label을 예측하는 데 사용되거나 그냥 무시할 수도 있다. [SEP] token으로 문장들을 구분하는 것뿐 아니라 BERT는 옵션으로(optionally) 문장이 어디서 왔는지 각 token을 tag하기도 한다. 그런 모델은 p(x, y, c)로 쓸 수 있으며 x는 첫 문장, y는 둘째 문장, c = {0, 1}는 문장이 source document 내에서 separate인지 consecutive인지 나타내는 label이다.
원본 논문과의 일관성을 위해 이 논문도 sequence의 끝에 (반드시 필요한 건 아니지만) [SEP] token을 추가했다.
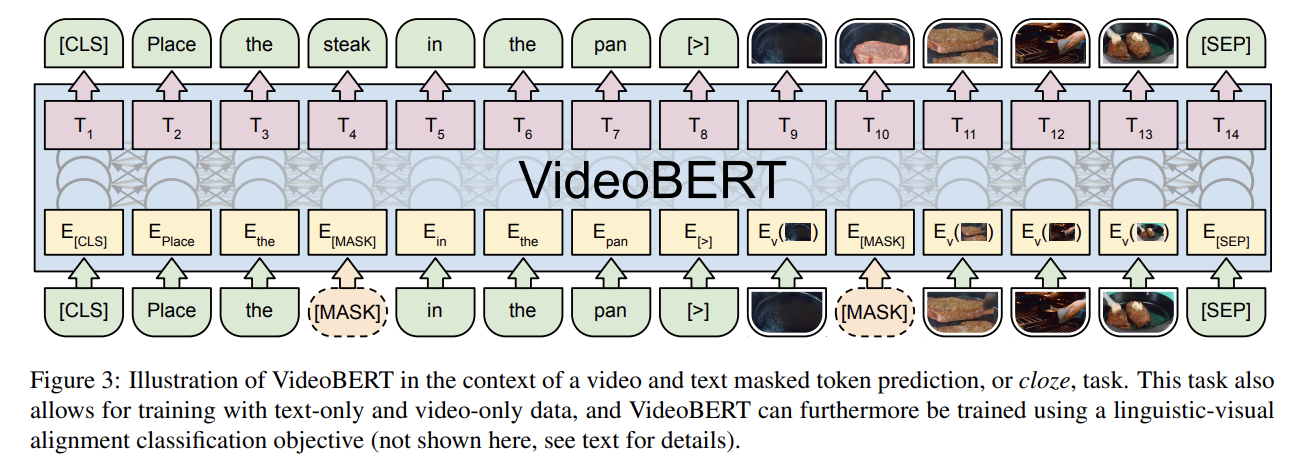
BERT를 VideoBERT로 확장하기 위해 최소한의 변화를 주기로 결정했고 raw visual data를 discrete sequence of tokens로 변환했다. 이를 위해 (pretrained model을 사용해 video에서 얻은) features에 hierarchical vector quantization을 적용하여 sequence of “visual words”을 생성할 것을 제안한다. 이 방식은 간편할뿐 아니라 모델이 video 내의 high level semantics와 longer-range temporal dynamics에 집중하도록 격려한다.
(ASR을 사용해 video로부터 얻은) linguistic sentence와 visual sentence을 조합해 다음 예시와 같은 데이터를 생성할 수 있다.
[CLS] orange chicken with [MASK] sauce [>] v01 [MASK] v08 v72 [SEP]
v01, v08은 visual token이고 [>]은 text sentence와 video sentence을 연결하기 위해 논문이 도입한 special token이다. 이 cloze task(=MLM)가 linguistic/visual tokens의 sequence로 자연스럽게 확장되긴 하지만 BERT처럼 next sentence prediction task를 적용하기엔 쉽지 않다. 그래서 논문은 linguistic-visual alignment task을 제안하며 linguistic sentence이 visual sentence와 temporally align되어있는지 예측하기 위해 [CLS] token의 final hidden state을 사용한다. 이것이 의미적 연관성의 관점에선 noisy한 지표라는 점에 주의하라. 예컨대 instructional videos에서 발화자는 시각적으론 존재하지 않는 사물에 대해 이야기하고 있을 수도 있다.
이를 해결하기 위해 논문은 먼저 neighboring sentences를 single long sentence로 랜덤하게 concatenate하여 모델이 (심지어 둘이 잘 temporally align되어있지 않더라도) semantic correspondence를 학습할 수 있게 한다. 둘째로, 심지어 다른 video의 동일한 action에 대한 state transitions의 속도(pace)도 크게 다를 수 있기 때문에, video tokens에 대해 랜덤하게 1~5 steps의 subsampling rate을 골랐다. 이는 모델이 video speed라는 variation에 더 robust하게 하고 greater time horizons에 걸쳐 temporal dynamics을 포착하게 해서 longer-term state transitions을 학습하게 한다.
전체적으로 서로 다른 input data modalities에 대응하는 세 가지 training regimes, text-only, video-only, video-text이 있다. text-only와 video-only의 경우 일반적인 mask-completion objectives이 학습에 사용된다. text-video의 경우 앞서 설명한 linguistic-visual alignment classification objective을 사용한다. 전체 training objective은 개별 objectives의 weighted sum이다. text objective는 VideoBERT가 language modeling을 잘하도록 강요하고 video objective는 dynamics와 forecasting를 배우는 데 사용할 수 있도록 “language model for video”을 배우게 강요하고 text-video objective는 두 영역 간 correspondence를 배우도록 강요한다.
모델을 학습시킨 후, 이를 다양한 downstream tasks에 사용할 수 있으며 논문에선 2가지 응용을 평가한다. 첫째로 모델을 probabilistic model로 취급해 MASKed out된 symbol을 예측하게 한다. 둘째로 [CLS] token으로부터 predicted representation을 추출해 그 dense vector을 input 전체에 대한 representation으로 사용한다. 이는 input에서 얻은 다른 feature와 조합되어 downstream supervised learning task에 사용될 수 있다.
- Dataset
BERT가 large dataset에서 좋은 성능을 발휘하기 때문에 VideoBERT도 large-scale video dataset로 학습하고 싶다. language와 vision의 연결에 관심이 있기 때문에 spoken words가 visual content를 언급하는 video를 구하고 싶다. 직관적으로 instructional videos가 그런 경우이므로 특히 cooking video에 집중했다. 영상은 유튜브에서 얻었다. video에서 text를 얻기 위해 유튜브의 automatic speech recognition (ASR) toolkit을 사용했다.
- Video and Language Preprocessing
각 input video를 20fps로 frames를 sample하고 video 위(over) 30-frame (1.5 seconds) non-overlapping windows로부터 clips를 생성한다. 각 30-frame clip에 pretrained video ConvNet를 사용해 feature을 추출한다. 이 논문에선 네트워크로 S3D을 사용했다. S3D의 final linear classifier 전에 feature activations를 받아 3D average pooling를 적용해 1024-dimension feature vector을 얻었다. S3D 네트워크는 Kinetics [9] dataset에 pretrain했다.
visual features는 hierarchical k-means로 tokenize했다. clusters의 coherence와 representativeness를 시각적으로 조사하면서 hierarchy levels의 수 d와 level 당 clusters 수 k를 조정했다.

각 ASR word sequence에 대해 off-the-shelf LSTM-based language model을 사용해 punctuation을 추가함으로써 stream of words를 sentence로 쪼갠다. 각 sentence에 대해 BERT 논문의 standard text preprocessing steps을 따라하고 text를 WordPieces로 tokenize한다. BERT와 동일한, 30,000 tokens을 보유한 vocabulary를 사용한다.
문장으로 구분되는 언어와 달리 video를 semantically coherent segments로 쪼개기는 쉽지 않다. 이를 위해 간단한 휴리스틱을 사용하는데, ASR sentence이 존재할 때 이는 starting/ending timestamps와 연관이 있고 그 time period 내의 video tokens을 segment 하나로 취급한다. ASR이 없다면 단순히 16 tokens을 segment로 취급한다.
- Model Pre-training
text pre-trained checkpoint로 BERT weights를 초기화한다. 구체적으론 원본 논문의 model을 동일한 backbone architecture로 사용한다.
(중략)
- Zero-shot action classification
pretrain된 후 VideoBERT는 YouCook II 같은 새로운 데이터셋에 “zero-shot” classification을 위해 사용될 수 있다. 구체적으로는 x가 sequence visual tokens이고 y가 sequence of words일 때 p(y|x)를 계산하고 싶은 것이다. 모델이 sentence를 예측하도록 학습되었으므로 fixed sentence "now let me show you how to [MASK] the [MASK]"가 되게 정의하고 first/second masked slots에 예측된 tokens로부터 verb/noun labels을 추출한다.

정량 평가를 위해 YouCook II dataset을 사용한다.
(중략)
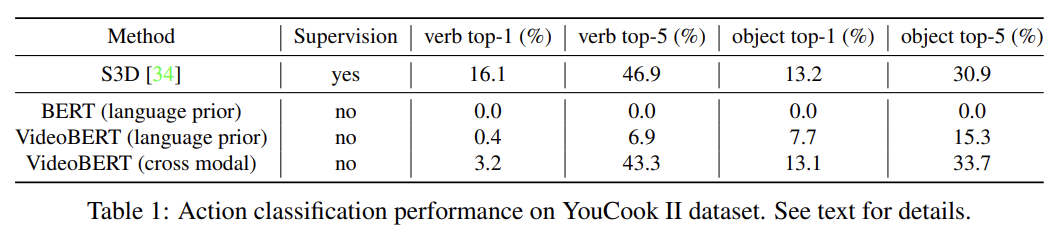

Tab 2는 data 양이 많을수록 정확도가 향상됨을 보여준다.
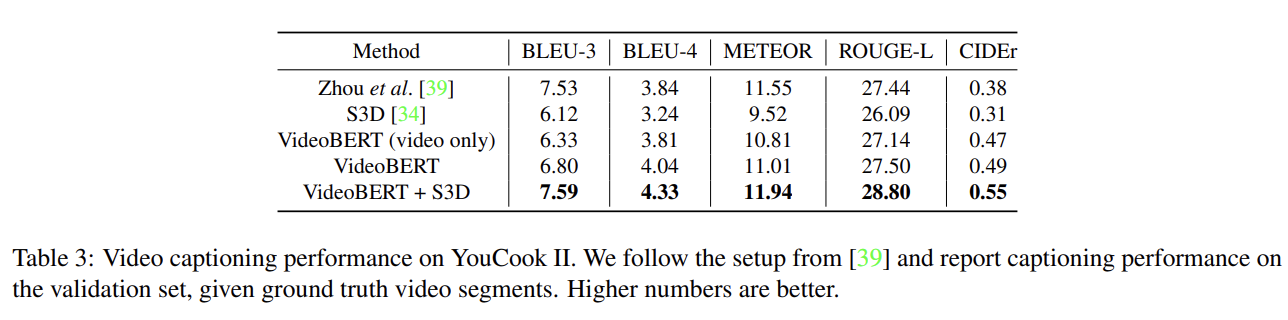

VideoBERT를 feature extractor로 사용했을 때 효과적임을 입증한다. video inputs만 주어졌을 때 features을 추출하기 위해 다시 simple fill-in-the-blank task을 활용한다. 다음과 같은 template sentence에 video tokens을 첨부한다.
“now let’s [MASK] the [MASK] to the [MASK], and then [MASK] the [MASK].”
video tokens와 masked out text tokens에 대한 features를 추출하고 평균을 취해 downstream task의 supervised model에 사용될 수 있도록 둘을 concatenate한다. extracted features를 video captioning에 평가한다.
(하략)
Strengths
- video와 language의 bidirectional joint distribution을 배우는 최초의 BERT 모델이다.
- Linguistic-visual alignment classification objective와 Masked Language Modeling(MLM) objective을 잘 조합해 pre-training했다.
Weaknesses
- (가능한 데이터셋이 많지 않아 어쩔 수 없는 부분이지만) 학습 데이터가 제한적이고 신뢰도가 낮다. 논문에서 지적한 것처럼 video의 speaking이 visual content를 지칭한다는 보장이 없어서 굉장히 noisy한 데이터다.
별개로 captioning에서 정확도를 구할 때 생성한 caption과 ground truth가 의미적으론 동일한데 정확히 일치하지 않아서 정확도가 잘 측정되지 않는 문제의 경우 생성된 caption과 GT를 동일한 특정 모델에 넣어서 그 representation이 일치하는지로 정확도를 측정하면 더 좋지 않을까? 단어 표현은 달라도 의미적으로 동일하다면 latent space에서 representation도 더 가깝지 않을까.
