
지난 글에서 nGrinder, Pinpoint를 통해 부하 테스트를 하고 모니터링도 해봤습니다. 하지만 성능에 대한 이슈가 발생하는걸 확인했고 그거에 대한 해결 방법도 생각했었습니다.
이번 글에서는 Apache Kafka 라는 메시지 큐에 대한 소개와 스프링에서 사용 방법 및 성능 개선을 해본 경험을 작성해보겠습니다.
사실 주문하기에 대한 로직을 메시지 큐를 통해 해결하는 것이 맞지 않다고 생각하지만 학습을 위해 작성했다는 점 참고 부탁드립니다.
메시지 큐란?
메시지 큐는 분산 시스템에서 애플리케이션 간 비동기 통신을 가능하게 하는 소프트웨어 엔지니어링 컴포넌트입니다. 이는 메시지를 임시로 저장하고 전달하는 중간 매개체 역할을 합니다. 메시지 큐를 사용하면 시스템 간의 결합도를 낮추고, 확장성과 신뢰성을 향상시킬 수 있습니다.
대표적인 메시지 큐로는
-
Apache Kafka
분산 스트리밍 플랫폼으로, 고성능과 대용량 데이터 처리에 적합 -
RabbitMQ
AMQP 프로토콜 기반의 메시지 브로커로, 다양한 메시징 패턴 지원
-
Apache ActiveMQ
다중 프로토콜 지원, JMS 구현체로 널리 사용됨 -
Redis
인메모리 데이터 구조 저장소로, pub/sub 기능을 통해 메시지 큐로도 사용 가능
존재합니다.
Apache Kafka vs RabbitMQ
Kafka와 RabbitMQ는 둘 다 인기 있는 메시지 큐 시스템이지만, 설계 철학과 사용 사례에서 차이가 있습니다.
a) 아키텍처:
Kafka: 분산 스트리밍 플랫폼으로, 로그 중심 아키텍처를 가집니다.
RabbitMQ: 전통적인 메시지 브로커로, AMQP 프로토콜을 구현합니다.
b) 성능과 처리량:
Kafka: 대용량 데이터 스트리밍에 최적화되어 있어 높은 처리량을 제공합니다.
RabbitMQ: 낮은 지연 시간과 신뢰성 있는 메시지 전달에 중점을 둡니다.
c) 메시지 보존:
Kafka: 메시지를 디스크에 저장하고 장기간 보존할 수 있습니다.
RabbitMQ: 기본적으로 메시지를 메모리에 저장하며, 소비된 메시지는 즉시 삭제됩니다.
d) 확장성:
Kafka: 수평적 확장이 용이하며, 대규모 클러스터 구성에 적합합니다.
RabbitMQ: 수직적 확장이 더 일반적이지만, 클러스터링도 지원합니다.
e) 사용 사례:
Kafka: 로그 수집, 스트림 처리, 이벤트 소싱 등 대용량 실시간 데이터 처리에 적합합니다.
RabbitMQ: 복잡한 라우팅, 우선순위 큐, 지연 메시지 등 다양한 메시징 패턴에 적합합니다.
Apache Kafka 좀 더 알아보기
카프카는 파이프라인, 스트리밍 분석, 데이터 통합 및 미션 크리티컬 애플리케이션을 위해 설계된 고성능 분산 이벤트 스트리밍 플랫폼입니다.
Pub-Sub 모델의 메시지 큐 형태로 동작하며 분산 환경에 특화되어 있습니다.
Pub-Sub 모델 (메시지 발행 구독 시스템)
메시지 발행 구독 시스템에서는 데이터 발행자가 직접 구독자에게 보내지 않습니다. 대신 발행자는 어떤 형태로든 메시지를 구분해서 발행 구독 시스템에 전송하면 구독자는 특정 부류의 메시지를 구독할 수 있게 하는데 이때 발행된 메시지를 저장하고 중계하는 역할을 브로커가 합니다.
카프카는 Pub-Sub 모델에서 브로커 broker)의 역할을 하고 있습니다. 발행자는 (Publisher)와 구독자 (Consumer) 사이에서 이벤트라 불리는 메시지를 카프카는 전달하게 됩니다.
카프카 탄생 배경
카프카는 소셜 SNS 서비스를 제공하는 링크드인에서 개발했습니다.
아래 그림은 카프카 개발 전 링크드인의 데이터 처리 시스템입니다.
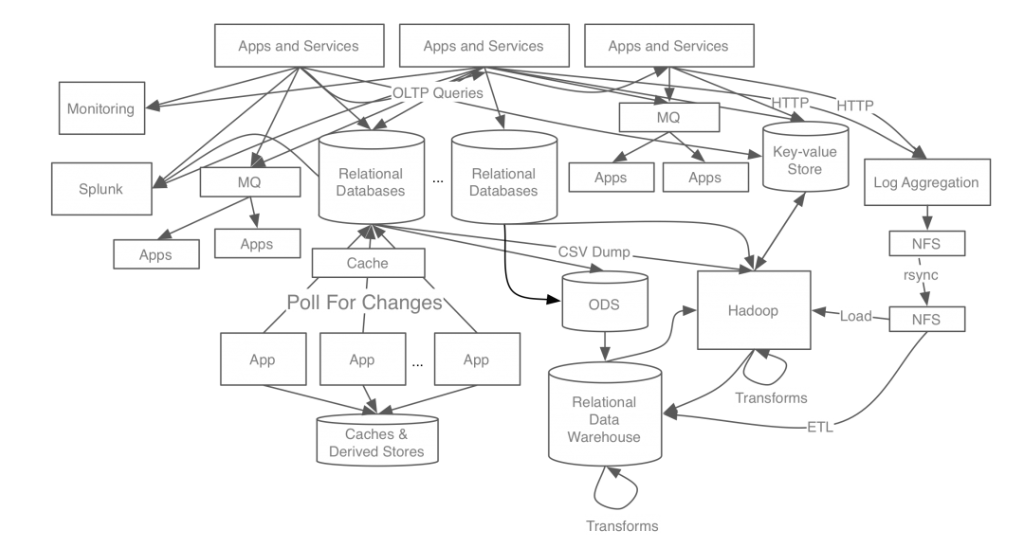
위 시스템을 보면 각 애플리케이션과 DB가 각각 end-to-end로 연결되어있고, 요구사항이 늘어남에 따라 시스템이 복잡해지면서 문제가 발생하기 시작했습니다.
- 시스템 복잡도 증가
- 데이터 파이프라인 관리의 어려움
이런 문제들을 해결하기 위해 모든 이벤트/데이터 흐름을 중앙에서 관리하는 카프카를 개발하게 되었습니다.
카프카 개발/적용 후
카프카를 적용한 후 링크드인의 데이터 처리 파이프라인입니다.
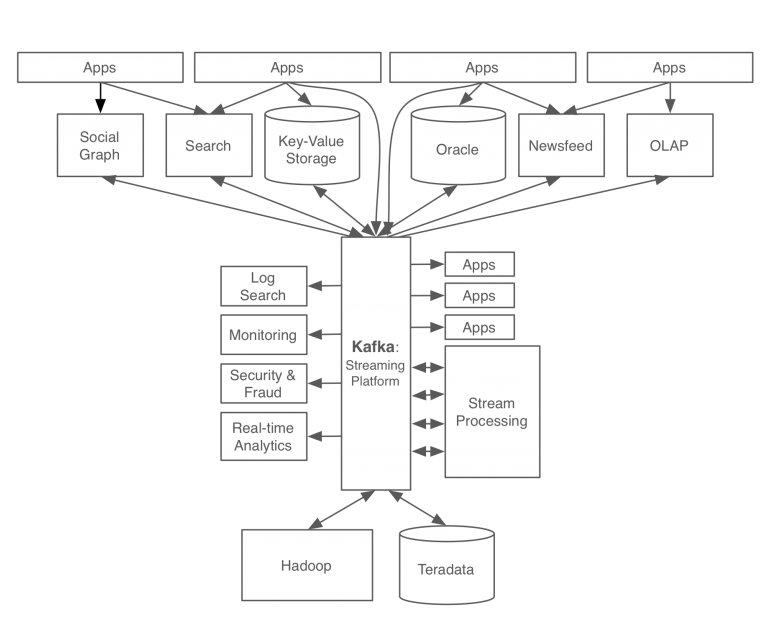
카프카를 적용함으로서 모든 이벤트/데이터 흐름을 중앙에서 관리할 수 있게 되었습니다.
새로운 서비스가 추가되어도 카프카가 요구하는 표준 포맷으로 연결하면 되므로 확장성과 신뢰성이 증가하였고 개발자는 각 서비스간의 연결이 아닌, 각 서비스의 비즈니스 로직에 집중할 수 있게 되었습니다.
카프카의 구성
아래 그림은 기본적인 카프카에 대한 구성을 나타내고 있습니다.
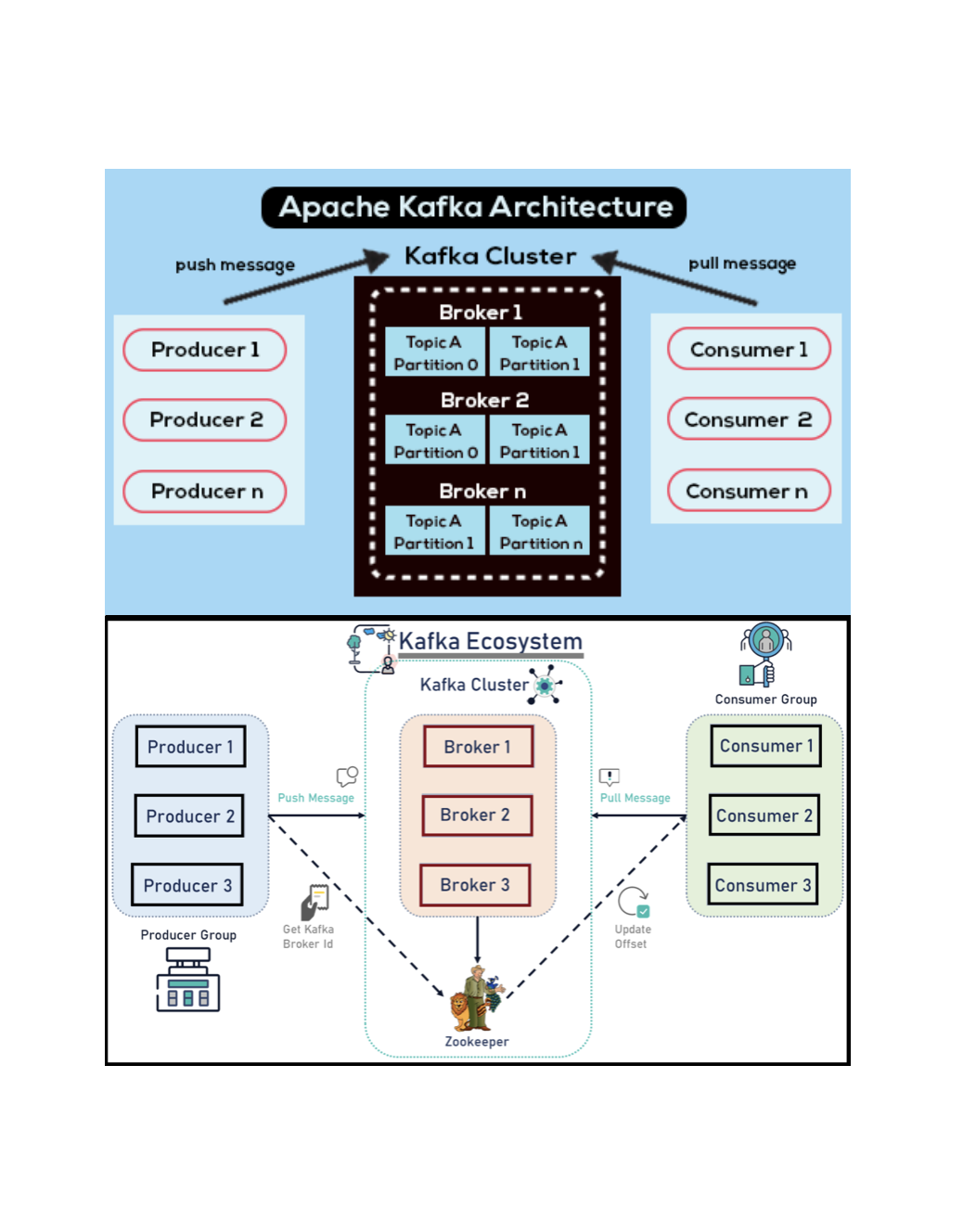
- Producer: Producer는 데이터의 생산자입니다. 애플리케이션에서 발생하는 이벤트나 로그 등의 데이터를 Kafka로 보내는 역할을 합니다. 프로듀서는 데이터를 특정 토픽으로 발행합니다.
- Topic: Topic은 데이터를 구분하는 논리적인 채널입니다. 예를 들면
주문, 결제, 배송등의 토픽을 만들어 각각의 이벤트를 분리할 수 있습니다. 토픽은 여러 개의 파티션으로 나뉩니다. - Partition: Partition은 토픽의 물리적인 분할 단위입니다. 각 파티션은 순서가 보장된 로그 파일로, 데이터가 순차적으로 추가됩니다. 파티션을 통해 병렬 처리와 확장성을 확보할 수 있습니다.
- Broker: Broker는 Kafka 서버입니다. 여러 Broker가 모여 Kafka 클러스터를 구성합니다. 각 Broker는 특정 토픽의 파티션을 저장하고 관리합니다.
- ZooKeeper: ZooKeeper는 Kafka 클러스터의 메타데이터를 관리합니다. 브로커의 상태, 토픽 정보, 파티션 할당 등을 저장하고 관리합니다.
- Consumer: Consumer는 데이터의 소비자입니다. 특정 토픽을 구독하고 해당 토픽의 데이터를 읽어 처리합니다.
- Consumer Group: 여러 Consumer를 그룹화한 것입니다. 하나의 파티션은 Consumer 그룹 내의 하나의 컨슈머만 읽을 수 있어, 병렬 처리가 가능합니다.
카프카의 데이터 처리흐름
- 데이터 생성
- 프로듀서가 데이터를 생성하여 특정 토픽으로 전송합니다. - 데이터 수신 및 저장
- Kafka 브로커가 해당 토픽의 파티션에 데이터를 저장합니다. - 데이터 소비
- 컨슈머 또는 컨슈머 그룹이 토픽을 구독하여 데이터를 읽습니다.
- 여러 컨슈머가 병렬로 데이터를 처리할 수 있습니다. - 데이터 처리 및 추가 작업
- 컨슈머가 읽은 데이터를 처리합니다.
- 처리 결과에 따라 새로운 데이터를 다른 토픽으로 전송할 수 있습니다.
이 과정에서 주키퍼는 지속적으로 클러스터의 메타데이터를 관리하며, 브로커의 상태와 파티션 할당 등을 조정합니다.
Spring에 적용하기
모든 소스코드는 Github 에서 확인할 수 있습니다.
https://github.com/f-lab-edu/joy-mall
https://github.com/f-lab-edu/joy-mall-kafka
적용 순서는
1. docker-compose.yml 파일을 통한 로컬에서 Kafka, Zookeeper 실행
2. application.yml 설정
3. 기존 서버에서 kafka topic으로 데이터 전송
4. 새롭게 만든 카프카 수신 서버에서 재고 감소 처리
5. 네이버 클라우드 카프카 서비스 생성 후 prod 프로파일 적용
1. docker-compose.yml
version: "3" # docker-compose 버전 지정
services:
zookeeper:
image: wurstmeister/zookeeper
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181 # kafka가 zookeeper에 커넥션하기 위한 대상을 지정
volumes:
- /var/run/docker.sock:/var/run/docker.sockdocker-compose.yml 은 컨테이너의 구성을 정의하고 관리하는데 사용됩니다. 자세한 설정방법은 생략하겠습니다.
2. application.yml 설정
로컬 프로파일
spring:
kafka:
bootstrap-servers: localhost:9092
consumer:
group-id: stock-decrease-group
auto-offset-reset: earliest
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
properties:
spring:
json:
trusted:
packages: "*"
json:
default:
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer3. 기존 서버에서 kafka topic으로 데이터 전송
@Component("salesProductFacadeKafka")
@RequiredArgsConstructor
public class SalesProductFacadeKafka implements SalesProductFacade {
private final KafkaTemplate<String, String> kafkaTemplate;
private static final String TOPIC = "new-stock-decrease";
private final Gson gson = new Gson();
@Override
public void decreaseStock(Set<OrderItem> orderItems) {
Set<OrderItemDTO> items = orderItems.stream().map(OrderItemDTO::from).collect(Collectors.toSet());
String json = gson.toJson(items);
kafkaTemplate.send(TOPIC, json);
}
}new-stock-decrease 라는 이름의 토픽으로 주문 상품 객체를 전달합니다.
@Configuration
public class KafkaTopicConfig {
@Bean
public NewTopic newStockDecreaseTopic() {
return TopicBuilder.name("new-stock-decrease")
.partitions(1)
.replicas(3)
.build();
}
}저는 new-stock-decrease 토픽의 파티션 1개를 유지하기 위해서 추가로 설정하였습니
다.
파티션을 2개 이상으로 사용한다면 분산 락을 적용했기 때문에 병렬로 Lock을 획득하려고 하니까 병목 현상이 발생하므로 1개로 설정한 것 입니다.
4. 새롭게 만든 카프카 수신 서버에서 재고 감소 처리
@Component
@RequiredArgsConstructor
public class SalesProductListener {
private final RedissonClient redissonClient;
private final SalesProductService salesProductService;
private final Gson gson = new Gson();
private static final String LOCK_KEY_PREFIX = "salesProduct:";
@KafkaListener(topics = "new-stock-decrease", groupId = "stock-decrease-group")
public void decreaseStock(ConsumerRecord<String, String> record) {
Type orderItemSetType = new TypeToken<List<OrderItemDTO>>(){}.getType();
List<OrderItemDTO> orderItems = gson.fromJson(record.value(), orderItemSetType);
for (OrderItemDTO orderItemDTO : orderItems) {
String lockKey = LOCK_KEY_PREFIX + orderItemDTO.getSalesProductId();
RLock lock = redissonClient.getLock(lockKey);
try {
boolean acquireLock = lock.tryLock(10, 1, TimeUnit.SECONDS);
if (!acquireLock) {
throw new RuntimeException("SalesProduct Lock 획득 실패");
}
salesProductService.decreaseStock(orderItemDTO);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
throw new RuntimeException("Lock 획득 중 인터럽트 발생");
} finally {
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
}
}이전 분산락을 적용한 코드 그대로 사용하였습니다.
5. 네이버 클라우드 카프카 서비스 생성 후 prod 프로파일 적용
부하 테스트
이전 테스트와 동일하게 Vuser를 약 300명, 10분 동안 부하 테스트를 진행하였습니다.
ngrinder 실행
ngrinder 실행 결과
이전 테스트에선
평균 TPS: 118
최고 TPS: 171
평균 테스트 시간 2,476 ms
의 결과가 나왔는데
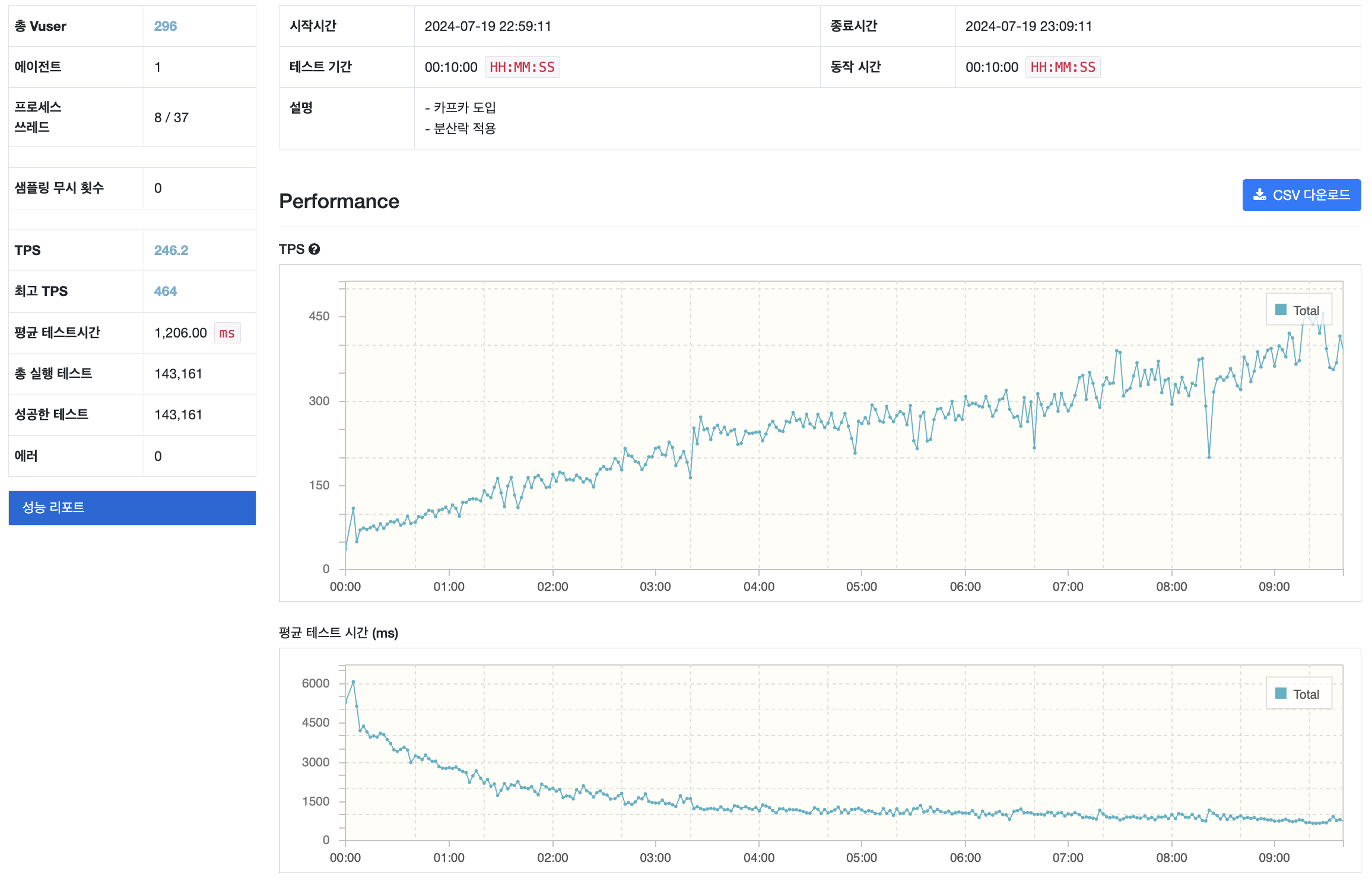
카프카 도입후
평균 TPS: 246
최고 TPS: 464
평균 테스트 시간 1,206 ms
의 성능이 향상된 결과를 확인할 수 있었습니다.
Pinpoint 결과 확인
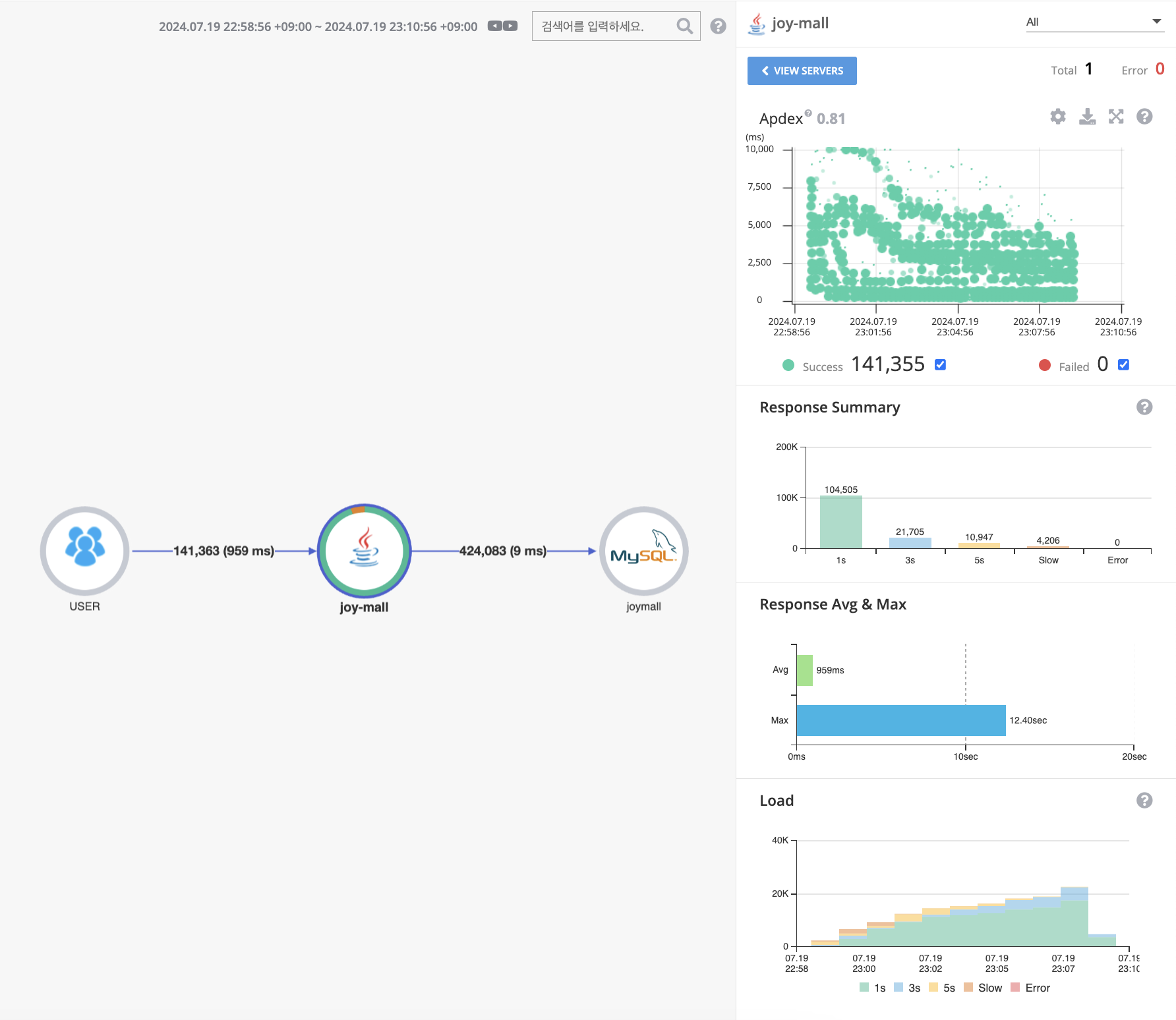
이전 테스트의 결과는
응답시간이 평균 2.36초, 최대 22.64초 였습니다.
카프카 도입 후
응답시간이 평균 0.95초, 최대 12.64초 인것을 확인할 수 있습니다. 성능이 확실히 개선되었습니다.
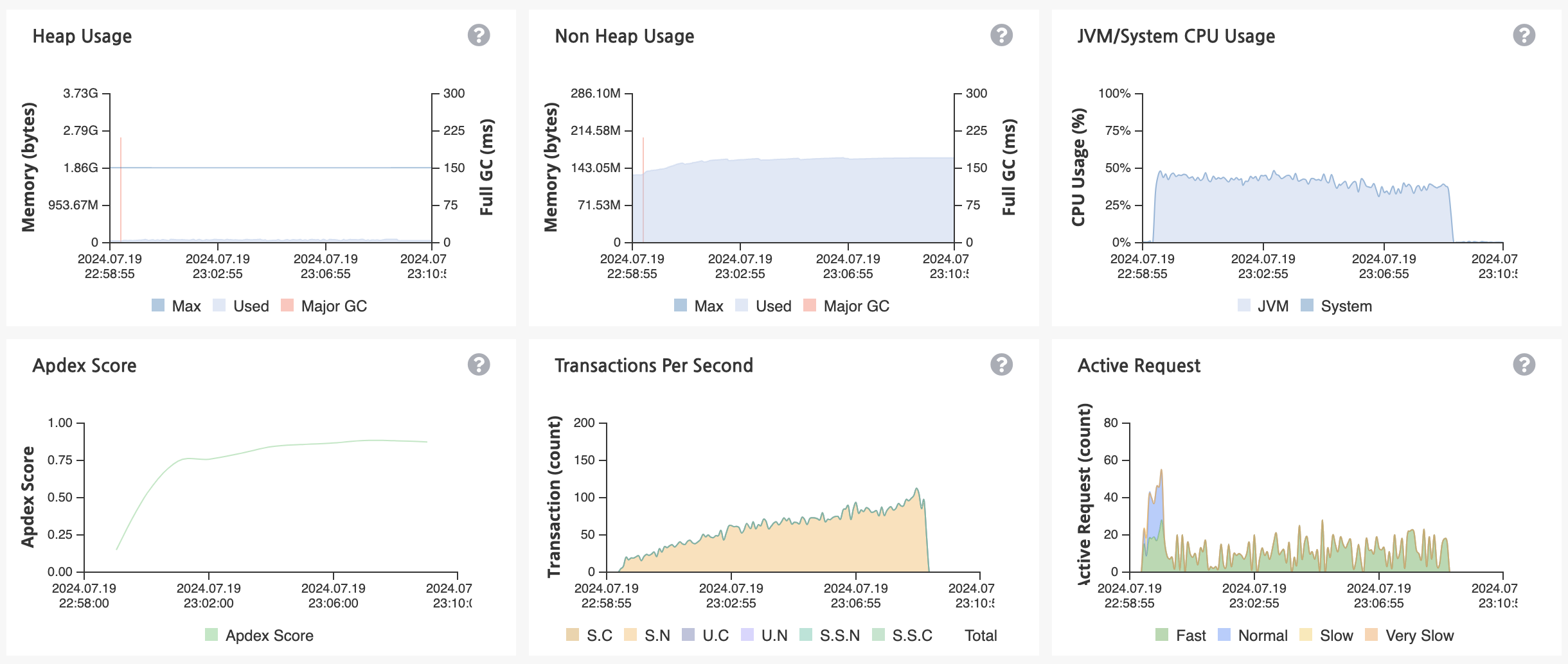
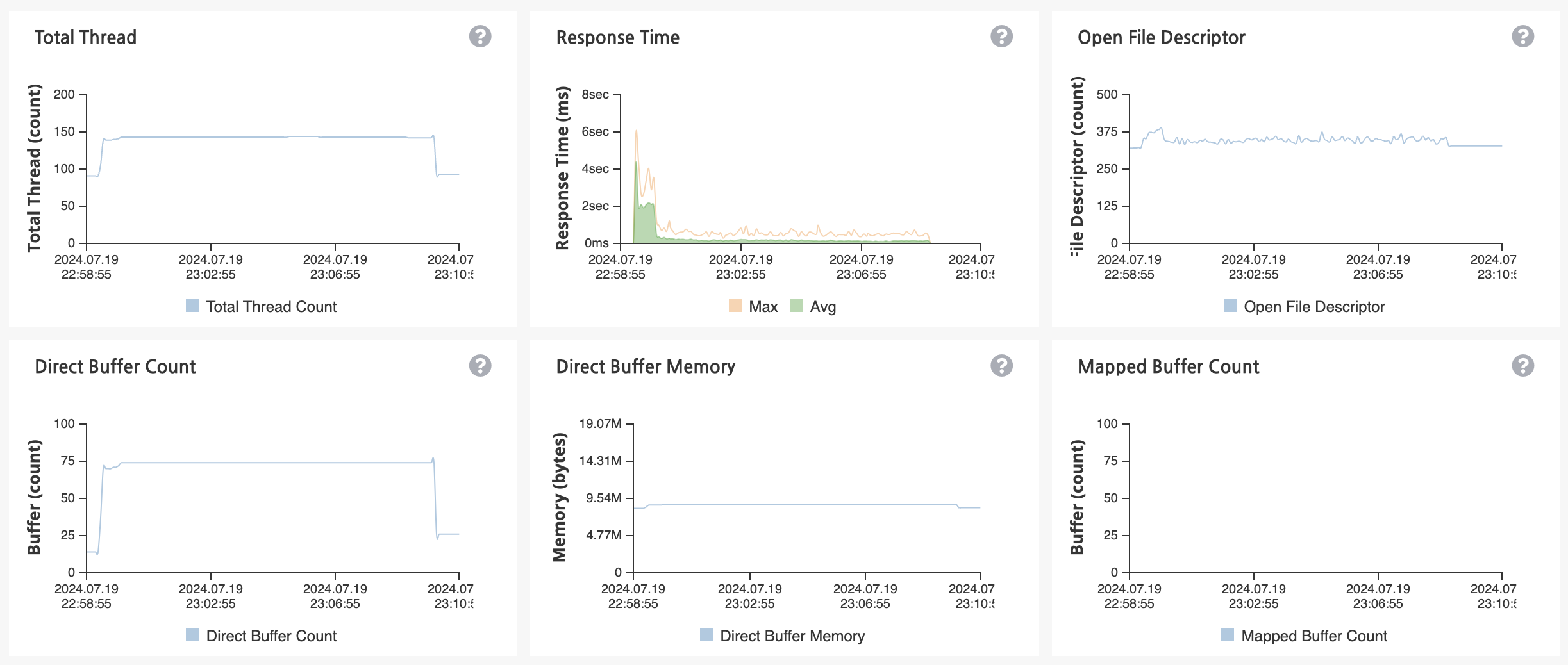
카프카 도입을 통해 애플리케이션의 부하를 줄이니 Heap 메모리 사용량과 CPU 사용량이 매우 안정화되었습니다.
마무리
이렇게 테스트를 해보니까 확실히 카프카를 도입하니까 성능이 향상되는걸 알 수 있었습니다.
그래도 고민이 생기는게 파티션을 1개로 처리하면 Redis의 분산락을 적용하는 의미가 없지 않나.. 이라는 생각이 들었습니다. 왜냐하면 어차피 메시지 큐를 통해 순차적으로 재고감소가 이루어질거라고 생각이 듭니다.
뭔가 도입을 하거나 해결하려고 해도 항상 고민이 되는 부분들이 생기는거 같습니다.
다음 글에서는 Kafka가 아닌 재고 감소에 대한 부분을 Redis 에서 처리하는 방식으로 한번 테스트를 해보고 결과를 작성해보겠습니다.
