
시작하기
대규모 트래픽 환경에서 안정적인 서비스를 운영하기 위해 신규 API에 대한 부하테스트는 필수적이라고 할 수 있습니다.
현재 진행 중인 프로젝트에 부하 테스트를 진행하기 위해 Naver에서 개발한 APM 도구인 Pinpoint와 부하테스트 오픈소스 nGrinder를 활용하였습니다.
이 글을 통해 테스트 환경 세팅을 하면서 습득한 지식과 경험에 대해 작성해보았습니다.
환경
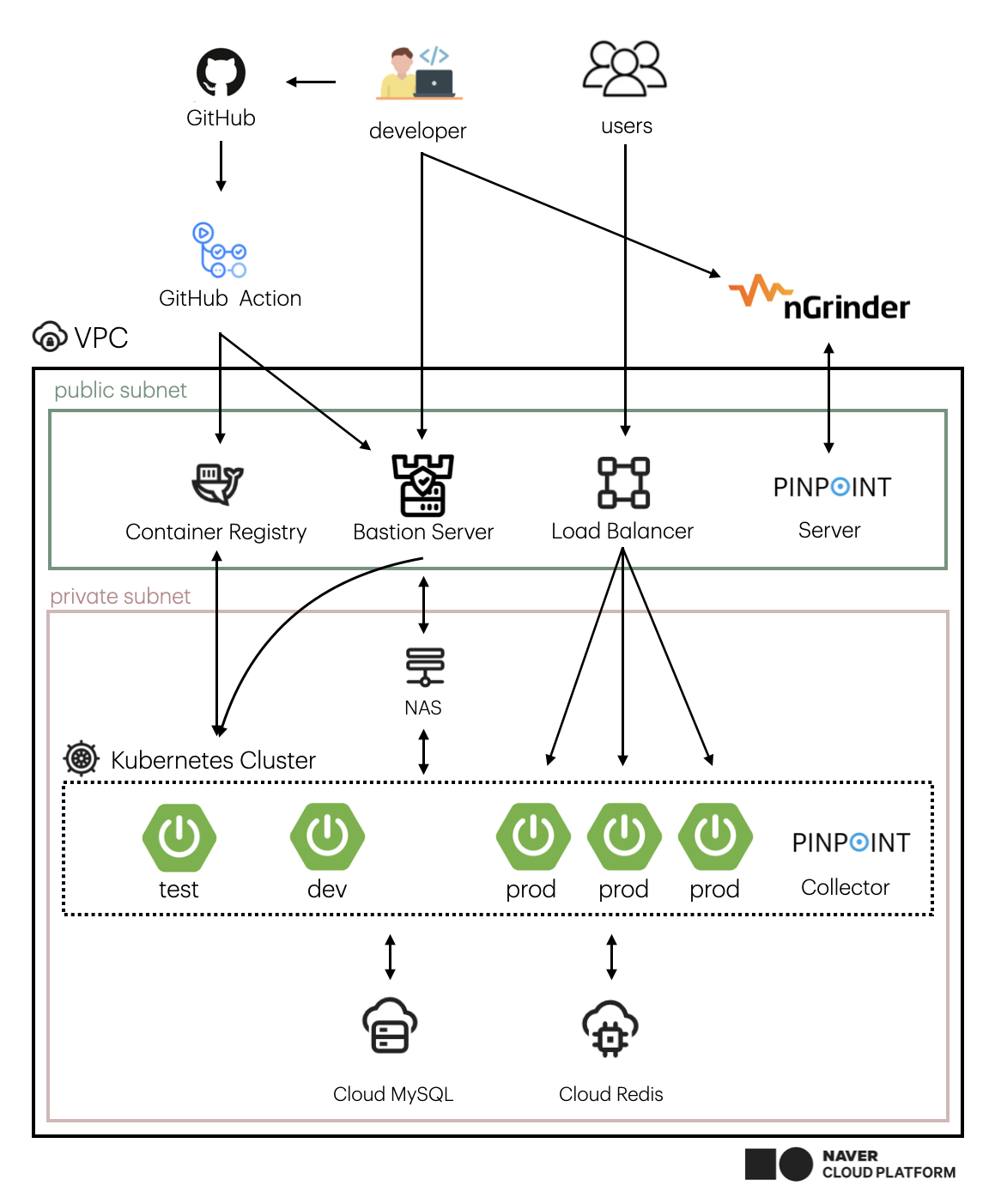
위와 같이 구성되어 있습니다.
nGrinder 알아보기
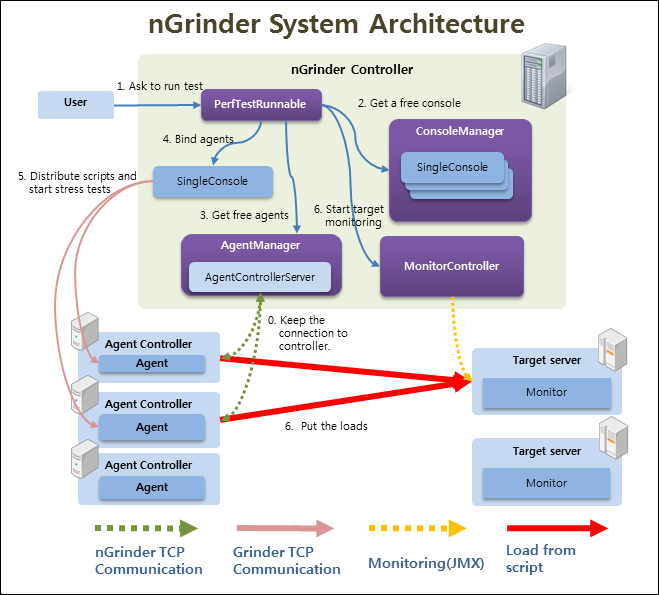
nGrinder의 구조는 위와 같지만 이해하기 쉽게 추상화 해보면 아래와 같은 구조와 같습니다.
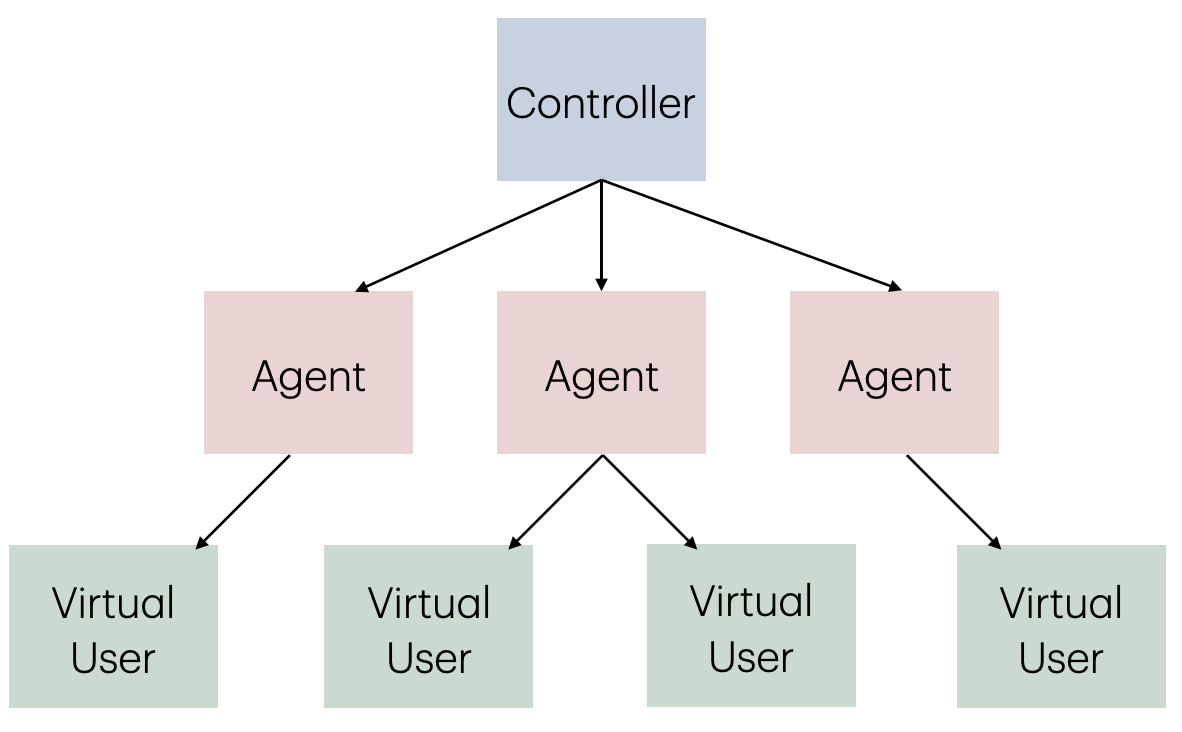
- Controller: 부하 테스트를 제어하고 모니터링
- Agent: 부하를 발생하는 Virtual User를 생성
- Vitual User: 가상 유저 수를 의미 (Agent x Process x Thread)
nGrinder는 성능 측정 목적으로 개발된 오픈 소스 프로젝트로
- 테스트 프로세스를 제공
- 부하를 줄 수 있는 웹 인터페이스 제공
- 테스트 결과를 수집하여 통계로 제공
등의 기능을 제공합니다.
성능 측정 도구로 nGrinder를 채택한 이유는 groovy 스크립트로 테스트 시나리오를 작성할 수 있다는 것 입니다.
Pinpoint 알아보기
Pinpoint는 대규모 분산 시스템의 성능을 분석하고 문제를 진단, 처리하는 플랫폼입니다.
PinPoint 는 현재 인터넷 서비스가 발전하면서 대규모 사용자를 지원하면서 많은 기능과 서비스 간에 유기적인 연동이 필요하게 되었고, SOA나 MSA 형식의 아키텍처와 같은 시스템 복잡도가 높은 문제를 해결하게 위해 n계층 아키텍처를 효과적으로 추적할 수 있도록 개발되었습니다.
Pinpoint 는 다음과 같은 특징을 가지고 있습니다.
- 분산된 애플리케이션의 메시지를 추적할 수 있는 분산 트랜잭션 추적
- 애플리케이션 구성을 파악할 수 있는 애플리케이션 토폴로지 자동 발견
- 대규모 서버군을 지원할 수 있는 수평 확장성
- 코드 수준의 가시성을 제공해 문제 발생 지점과 병목 구간을 쉽게 발견
- bytecode instrumentation 기법으로 코드를 수정하지 않고 원하는 기능을 추가
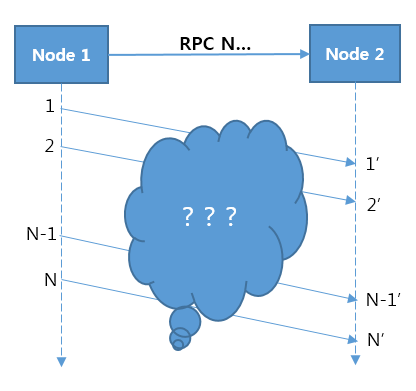
Pinpoint는 Google Dapper 스타일의 추적 방식을 사용해, 분산된 요청을 하나의 트랜잭션으로 추적합니다.
Google Dapper의 분산 트랜잭션 추적 방법
분산 트랜잭션 추적의 핵심은 위의 그림처럼 Node 1에서 Node 2로 메시지를 전송했을 때, Node 1과 Node 2가 처리한 메시지의 관계를 찾아내는 것입니다.
Google Dapper의 방법으로 메시지 전송 시 메시지를 엮을 수 있는 태그를 메세지에 추가하여 Node 1과 Node 2 메시지 간의 관계를 엮었습니다.
자세한 내용은 기술 블로그에서 확인할 수 있습니다.
https://d2.naver.com/helloworld/1194202
테스트 계획
테스트에 들어가기 전에 테스트 계획을 세웠습니다.
- 쿠버네티스 Pod이 1개일 때
- 쿠버네티스 Pod이 4개일 때
그리고 LoadBalancer를 통한 분산 트래픽의 성능을 확인해보겠습니다.
- VUser 약 300명, 테스트 시간 10분
테스트 실행
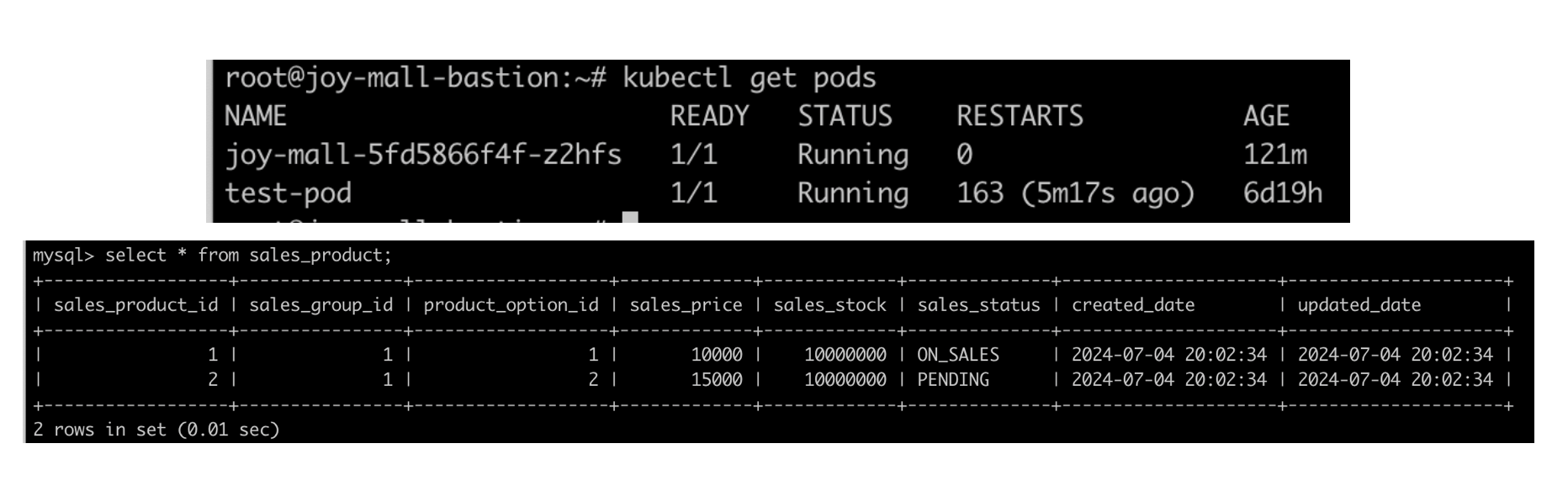
Pod 1개를 실행시키고, 주문에 대한 재고 1천만건을 가정합니다.
nGrinder 실행
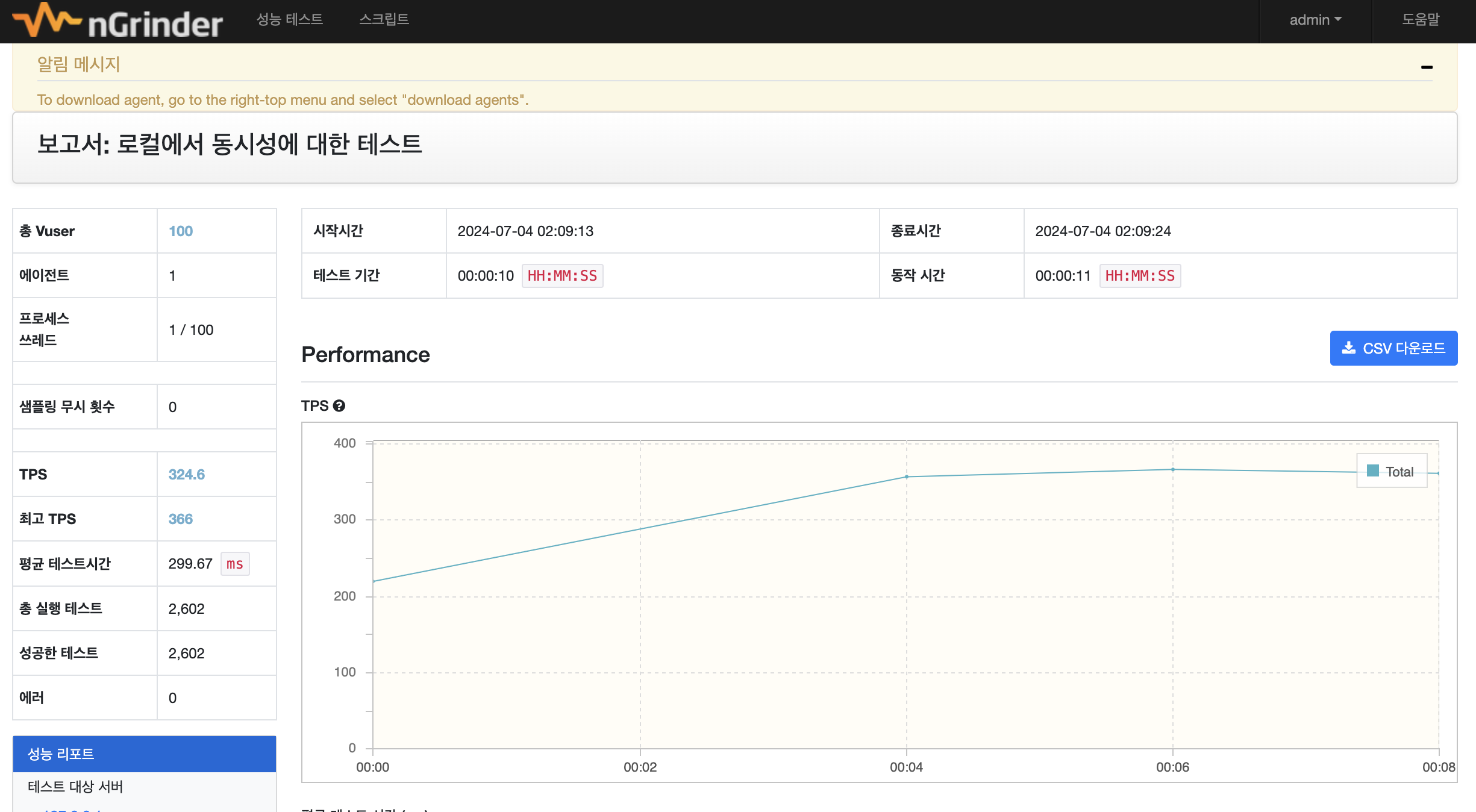
nGrinder 결과
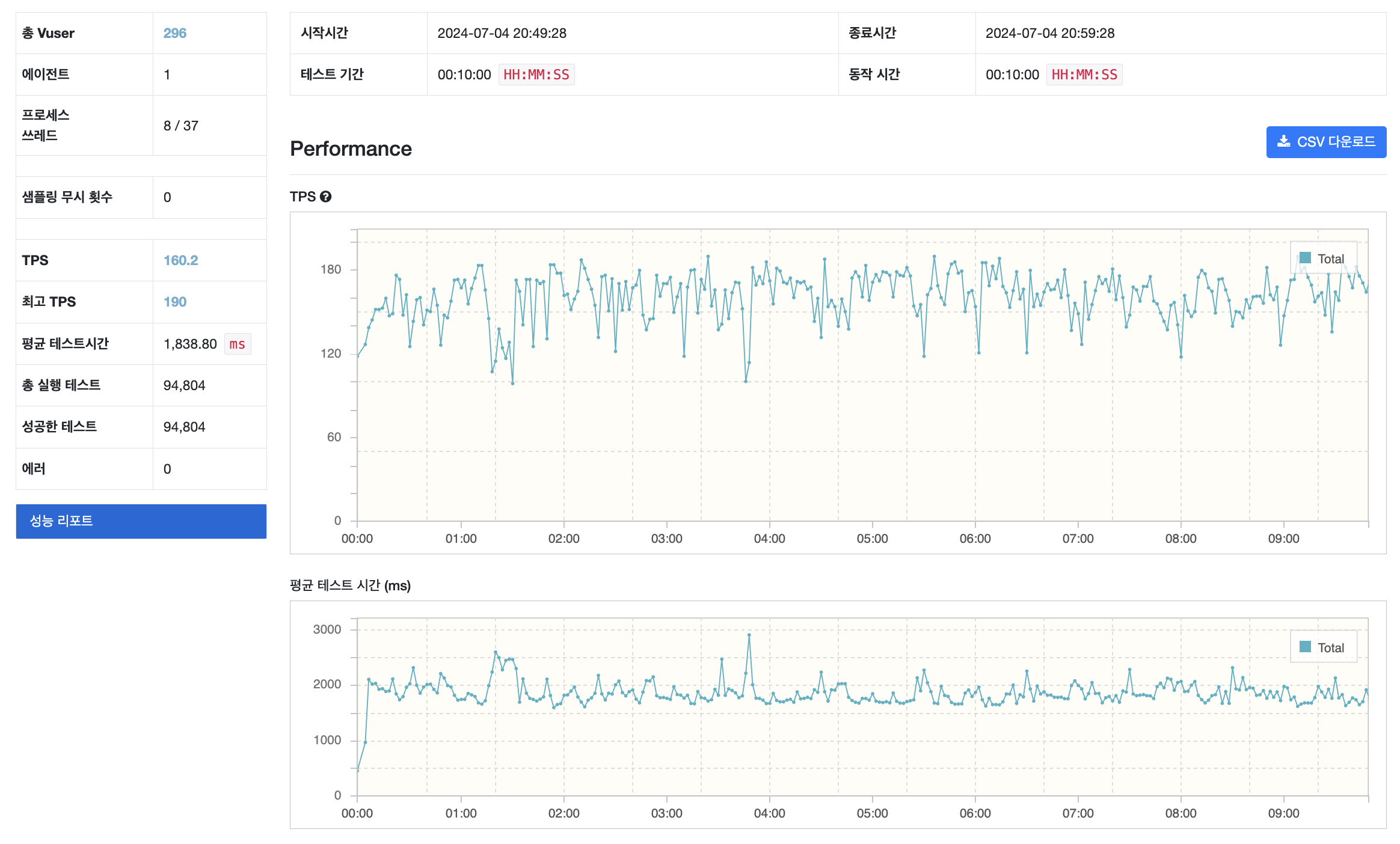
TPS 160.2, 평균 테스트 시간 1,838 ms 초당 160번의 API 요청을 처리하는걸 확인할 수 있습니다.
Pinpoint 결과
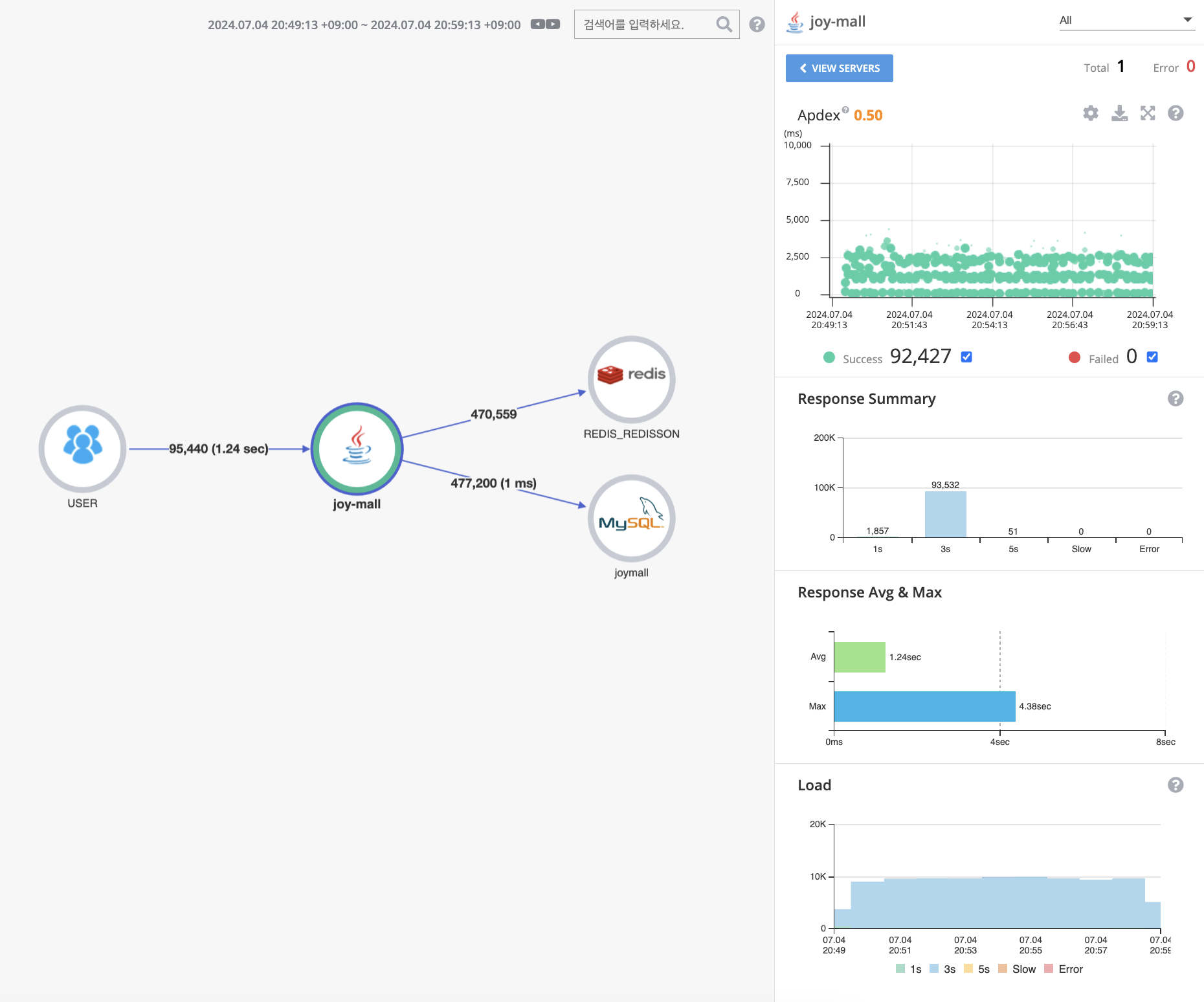
응답시간이 평균 1.24초, 최대 4.38초 인것을 확인할 수 있습니다. API 성능이 좋지 않다는걸 확인할 수 있습니다.
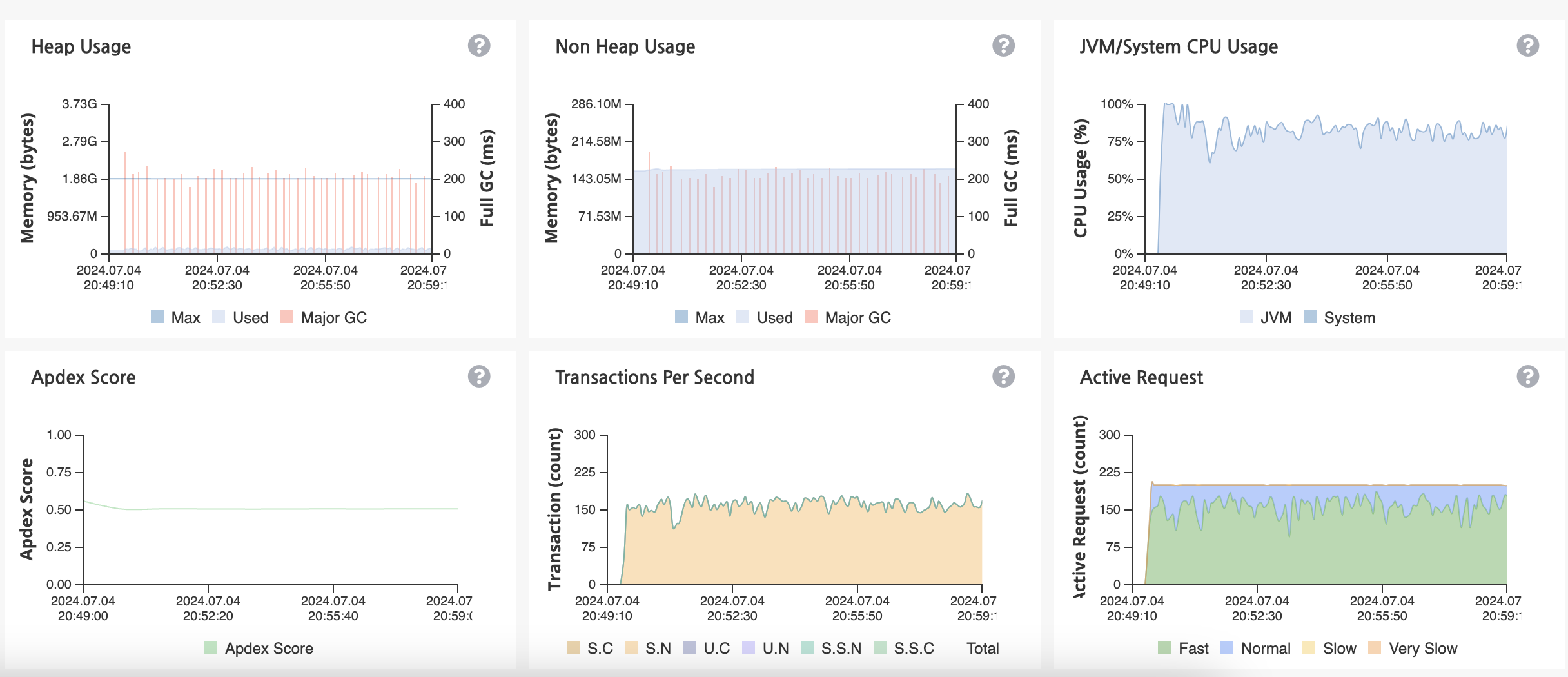
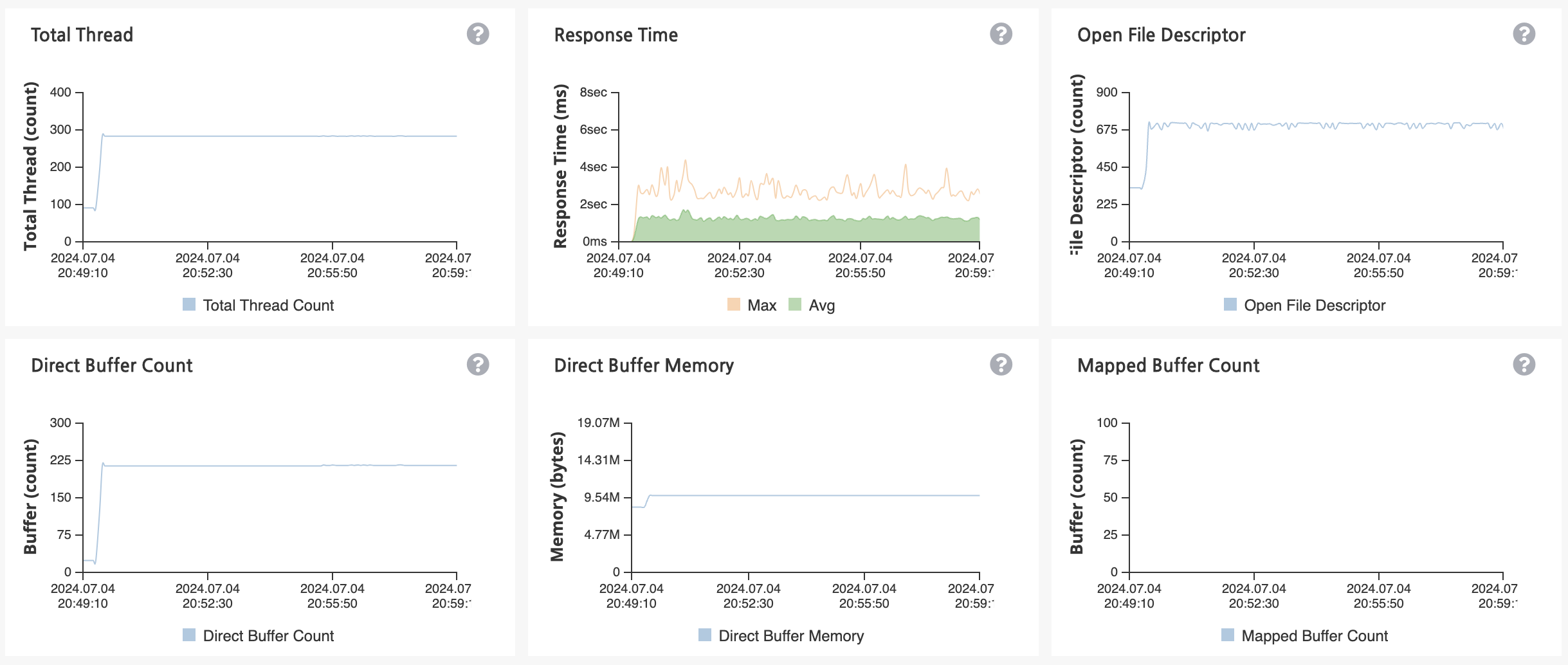
Heap 메모리 사용량은 임계 영역을 넘을 때가 많고 CPU 사용량도 80프로 가까이 사용되는 걸 확인할 수 있습니다.
pod 개수 늘려서 테스트해보기
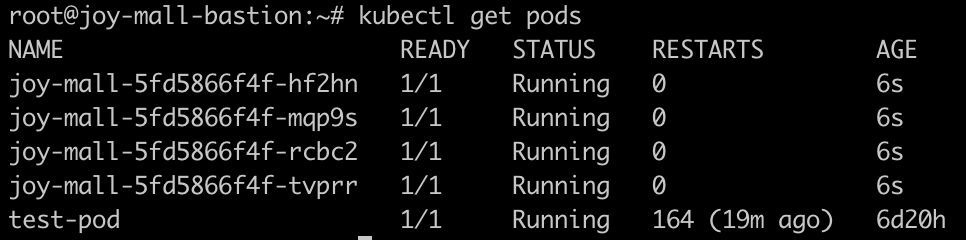
팟을 4개로 늘렸습니다.
nGrinder 실행
nGrinder 결과
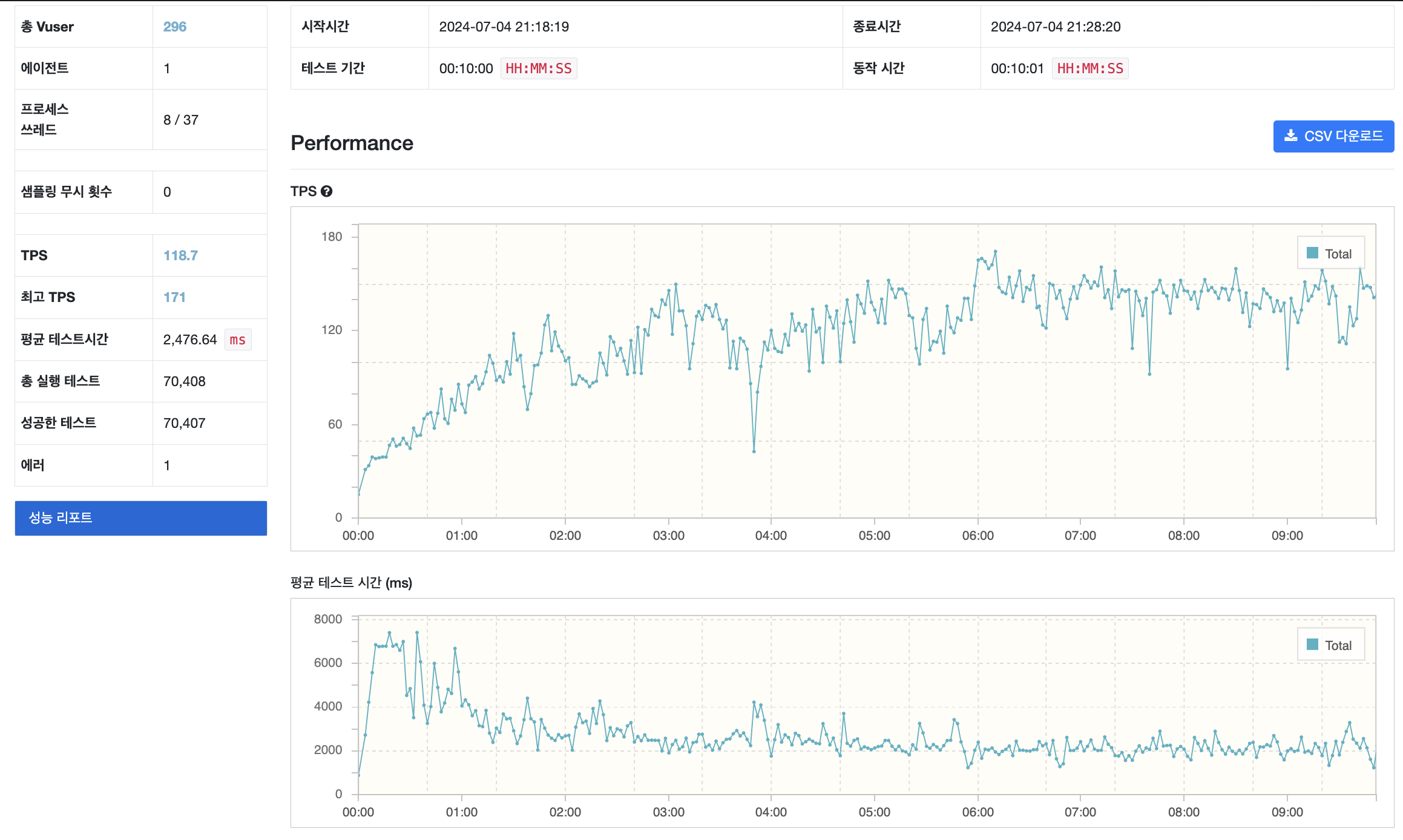
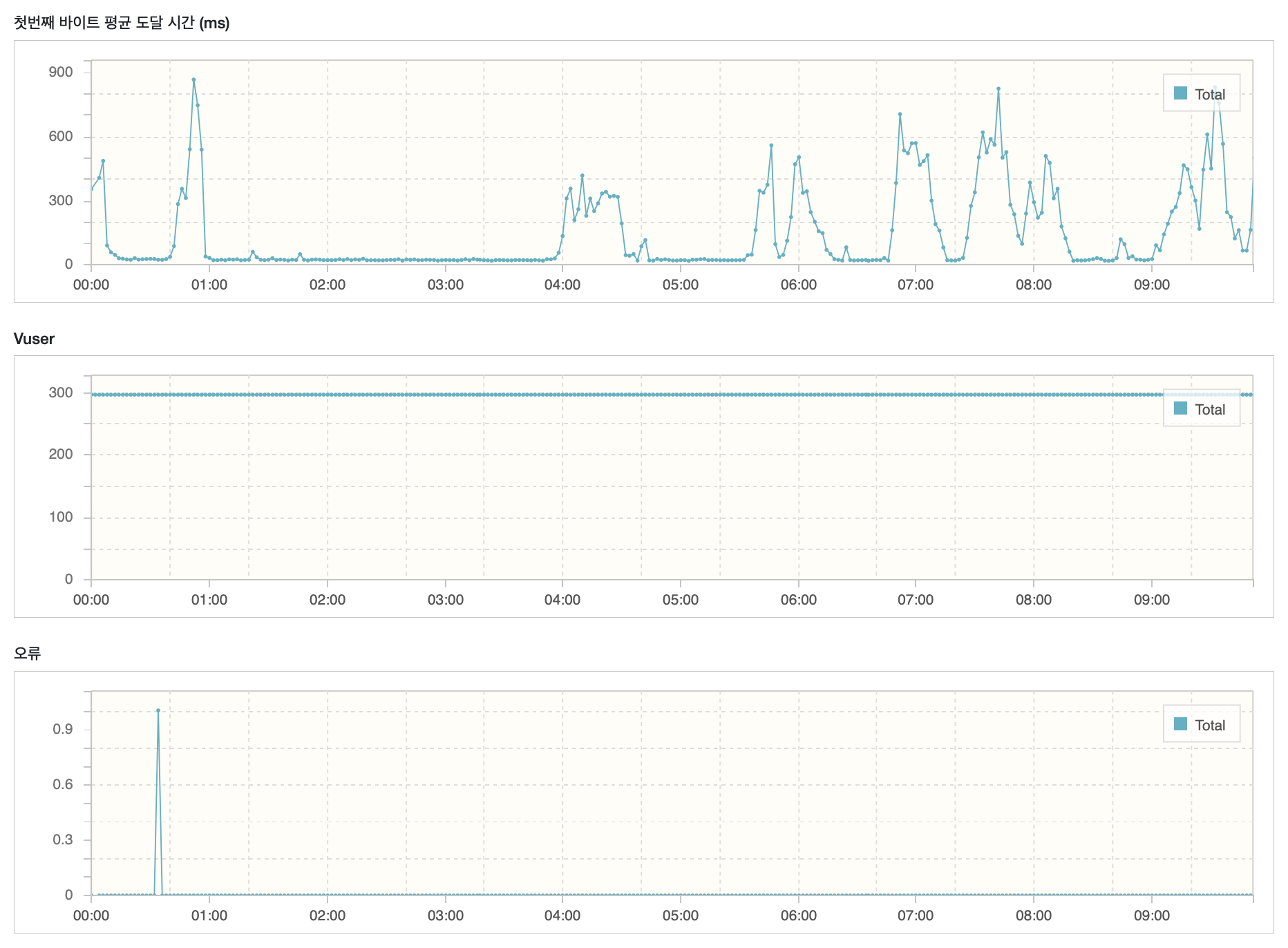
TPS 171.2, 평균 테스트 시간 2,476 ms 초당 170번의 API 요청을 처리하는걸 확인할 수 있습니다. TPS는 10회정도 늘어났습니다.
Pinpoint 결과
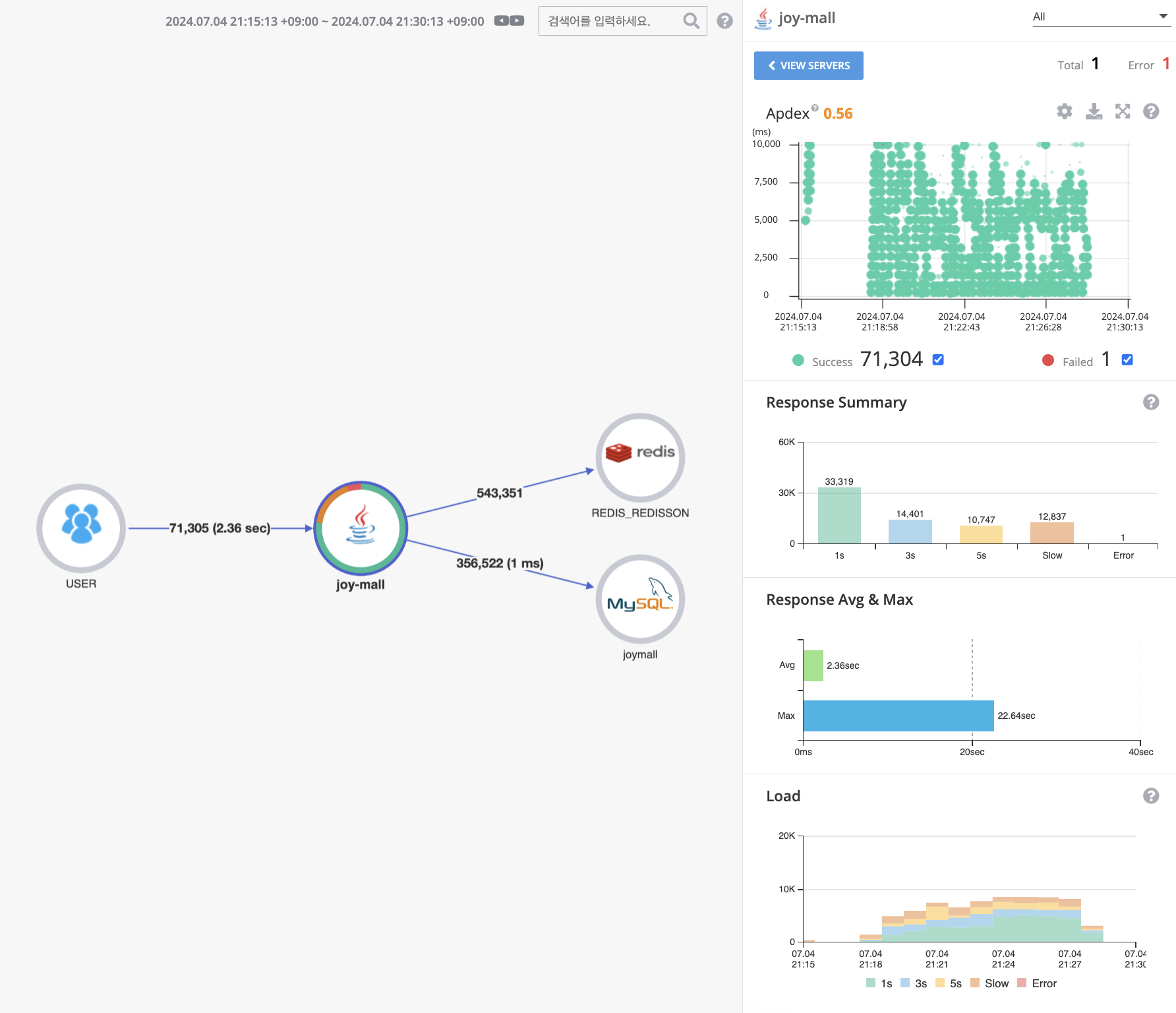
응답시간이 평균 2.36초, 최대 22.64초 인것을 확인할 수 있습니다. API 성능이 더 안좋아졌습니다.
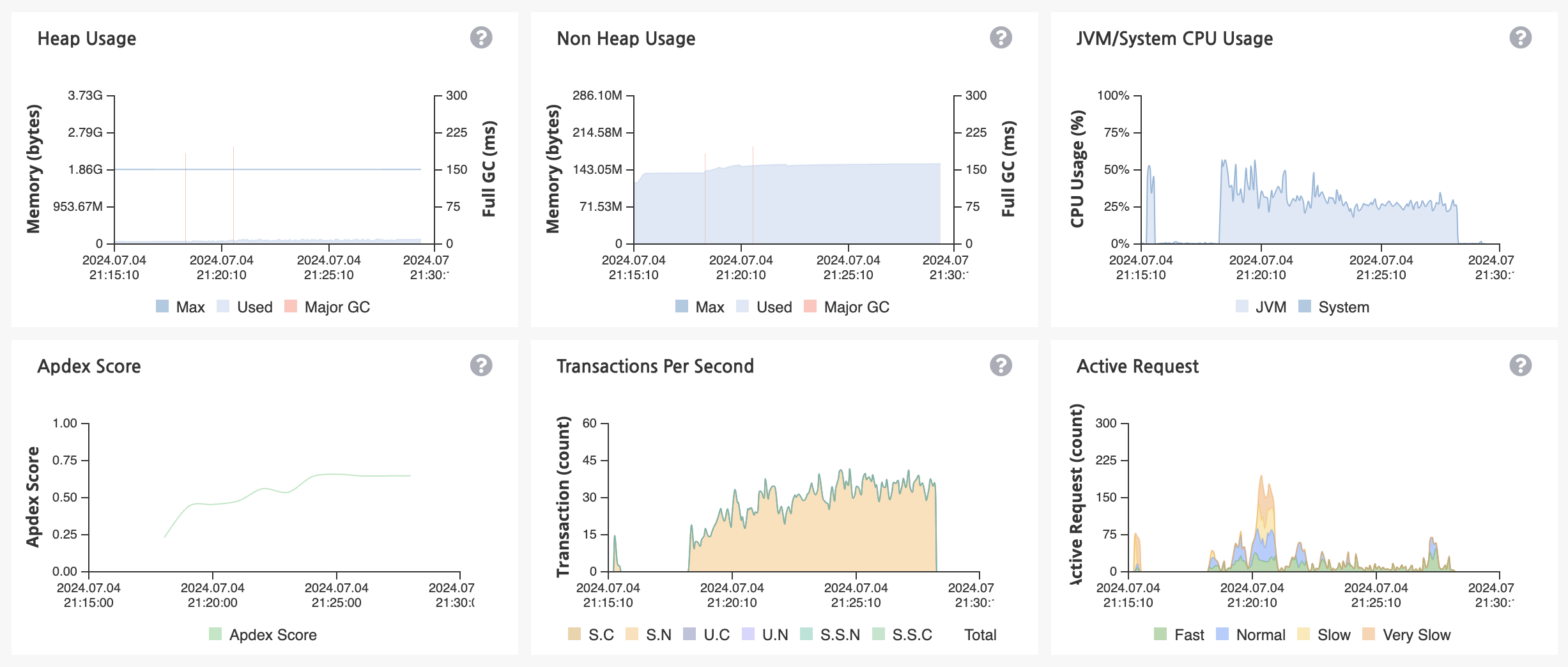
Heap 메모리 사용량은 임계 영역을 넘는 횟수가 줄었고 CPU 사용량도 50프로로 안정화된 것을 확인할 수 있습니다.
분석
서버에 자원 사용률에 대한 부분은 절반 가까이 개선이 되었는데 왜 API 응답속도가 늦어졌을까요?
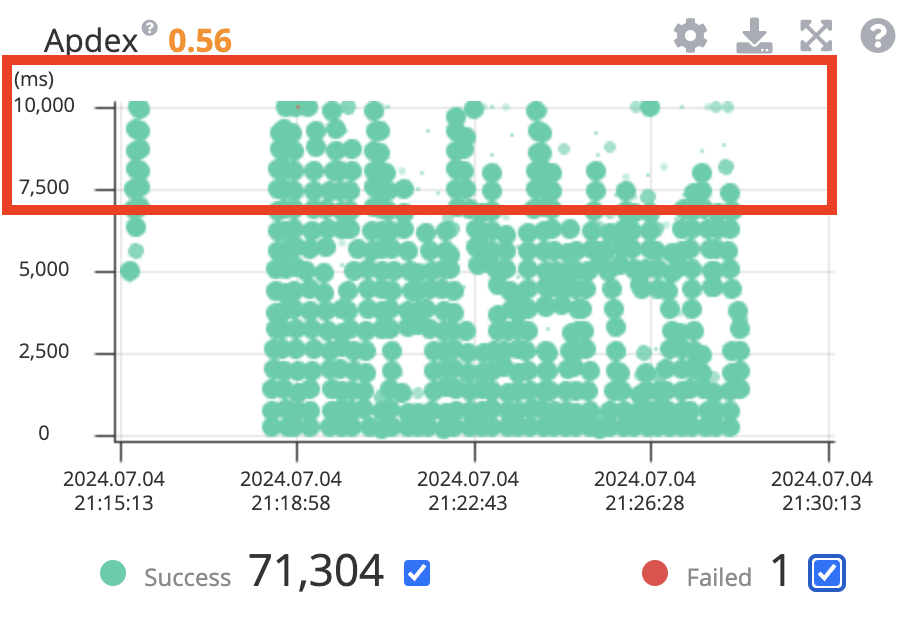
Apdex (Application Performance Index) 애플리케이션 성능이 느려진 부분을 확인해보겠습니다.
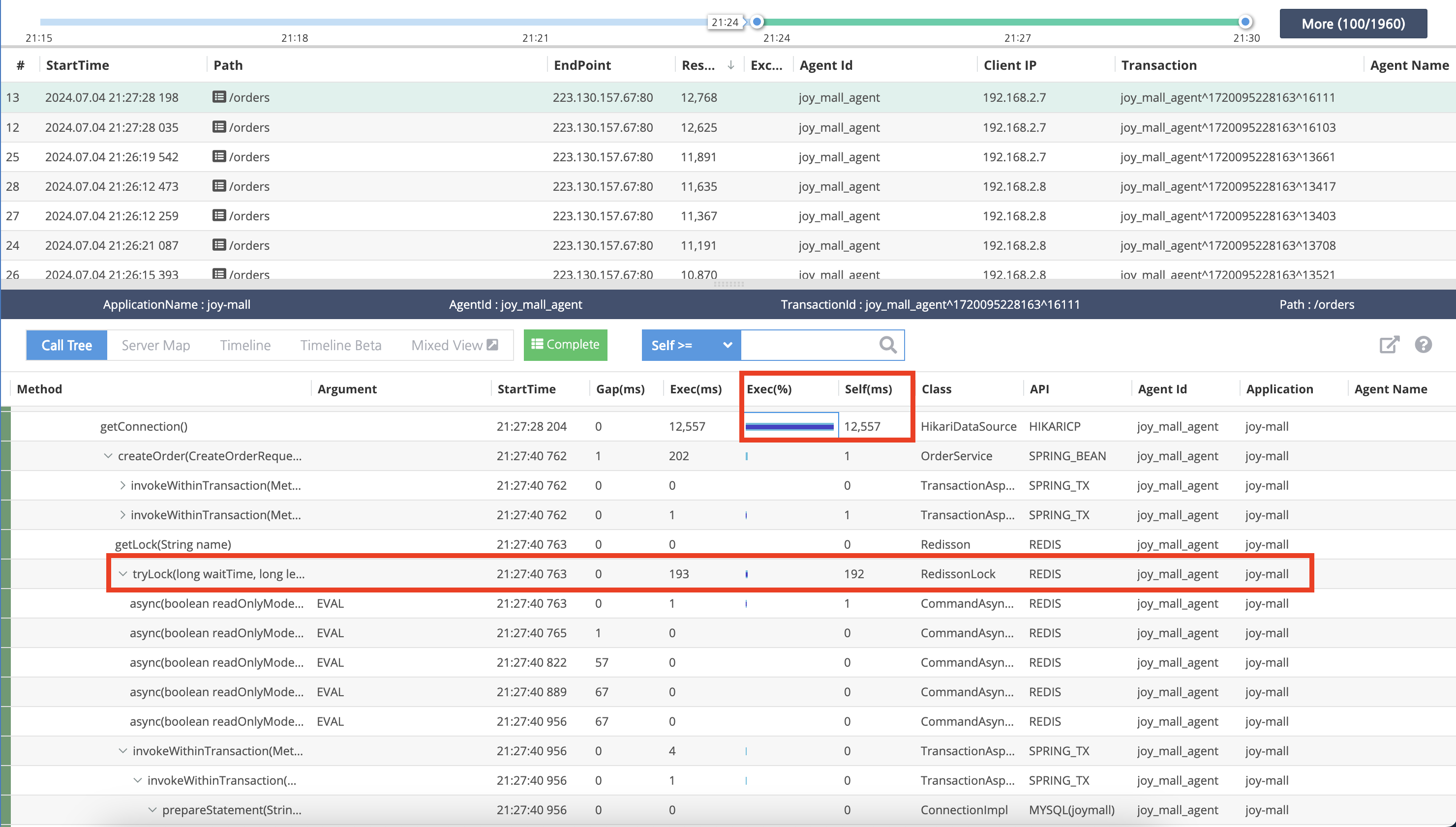
느려진 부분을 보니 Connection 을 맺는 부분에서 12초가 걸렸습니다.
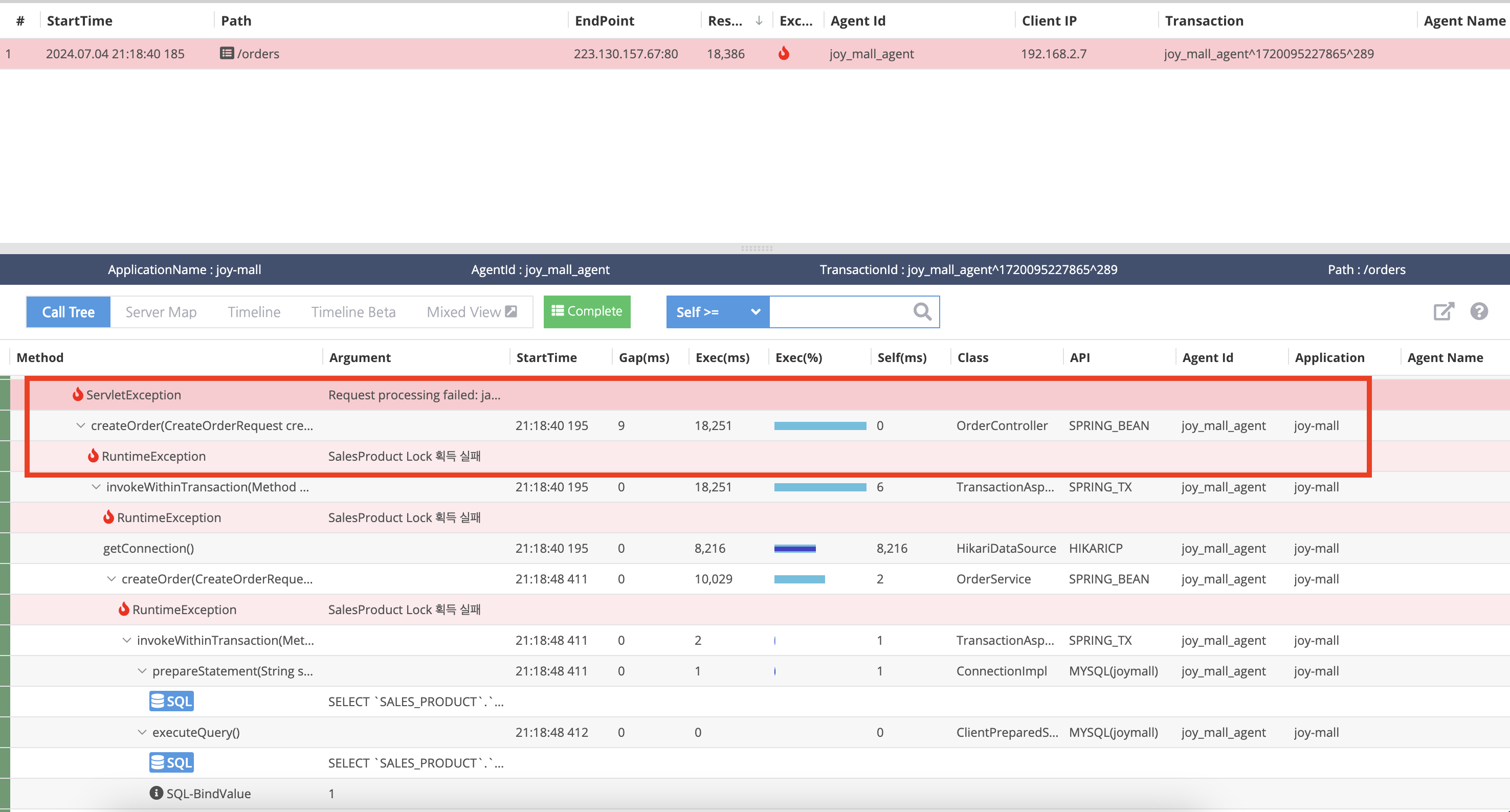
오류난 API를 확인해보면 18초 걸렸는데 Lock을 획득하는데 실패하여 Exception이 발생했습니다.
예측 가는 부분은 재고 감소 로직에 단일 Redis 서버에 대한 분산락 로직이 있다는 것이 생각났습니다.
4개의 서버가 1개의 Redis 단일 서버에 접근하면서 아래와 같은 문제점들이 발생하는 걸 예상할 수 있습니다.
- 병목 현상: Redis 서버가 단일 지점이 되어 여러 팟에서 오는 요청을 처리하느라 병목 현상이 발생
- 네트워크 지연: 팟이 4개로 늘어나면서 각 팟에서 Redis 서버로의 네트워크 요청이 증가하고, 이로 인한 지연이 발생
- 락 경합: 여러 팟에서 동시에 같은 리소스에 접근하려고 할 때, 분산락을 얻기 위한 경합이 심해짐
- 동기화 오버헤드: 분산 환경에서 데이터 일관성을 유지하기 위한 동기화 작업이 증가하여 전체적인 성능 저하로 이어질 수 있습니다.
개선 점
부하 테스트를 해보고 다중 서버에 대한 문제점을 알 수 있었습니다. redis를 이용해 분산 락을 구현해서 데이터 정합성을 유지하려고 했지만 락 획득에 대한 병목 현상 때문에 API 성능에 대한 이슈가 생겼다는 걸 확인했습니다.
이를 해결하기 위해서는 메세지 큐(Kafka, RabbitMQ) 을 도입하거나 락 획득 및 해제 시간을 최적화하여 락 경합에 대한 문제를 해결할 수 있을거 같습니다.
또 알아낸 방법은 재고 감소에 대한 부분을 DB에서 수행하는 것이 아닌 Redis에서 수행하는 것입니다.
위와 같은 방법들로 개선을 해봐야겠습니다.
참고
https://azelhhh.tistory.com/m/122
https://velog.io/@max9106/nGrinderPinpoint-test1#%ED%85%8C%EC%8A%A4%ED%8A%B8-%EB%AA%A9%ED%91%9C
https://hamryt.tistory.com/11
https://blog.imqa.io/pinpoint/
