코드는 Github에서 보실 수 있습니다.
분산 락
이전 글에서 알아본 synchronized는 단일 서버 환경에서만 동시성 문제를 해결할 수 있었습니다. 이번 글에서는 다중 서버 환경에서 동시성 문제를 해결할 수 있는 방법에 대해 알아보겠습니다.
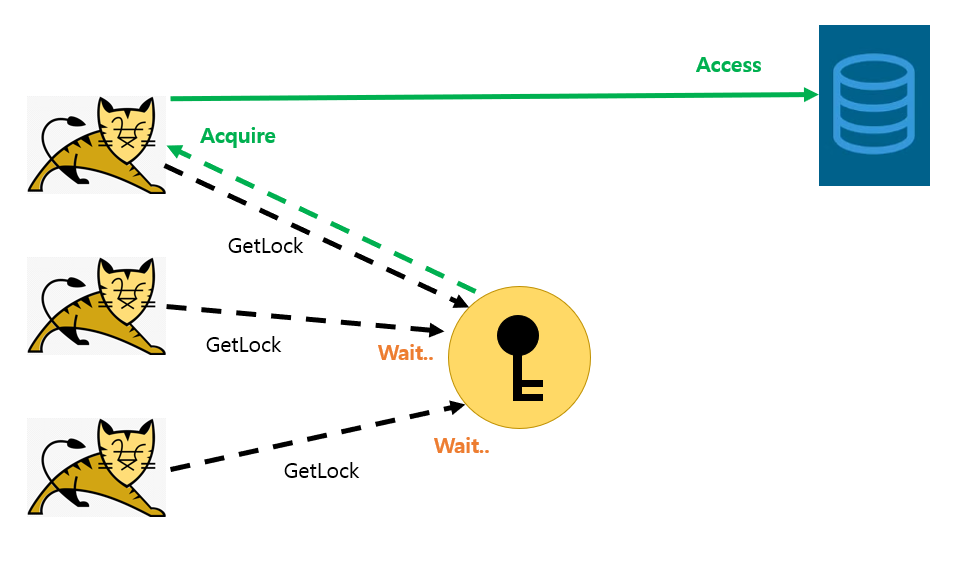
여러 대의 서버에서 동일한 자원에 접근하는 경우, 동시에 한 개의 프로세스(혹은 쓰레드)만 접근 가능하도록 하기 위해 사용하는 Lock을 분산 락(Distributed Lock)이라고 합니다.
분산락의 장점은 서버 분산 환경에서도 프로세스들의 원자적인 연산이 가능한 것 입니다. 이로서 데이터의 일관성과 정합성을 지킬 수 있게 합니다.
분산 락을 구현하는 방법엔 뭐가 있을까요?
- 비관적 락(Pessimistic Lock)
- 낙관적 락(Optimistic Lock)
- My SQL(User Level Lock)
- Zookeeper
- Redis
...
이번 글에서는 비관적 락과 낙관적 락 구현을 해보겠습니다.
비관적 락(Pessimistic Lock)과 낙관적 락(Optimistic Lock)
이름 그대로 비관적 락은 자원 경쟁을 비관적으로, 낙관적 락은 낙관적으로 바라봅니다.
비관적 락(Pessimistic Lock)은 트랜잭션이 시작될 때 공유 락(S-Lock, Shared Lock) 또는 배타락 (X-Lock, Exclusive Lock)을 걸고 시작합니다.
- 공유 락(S-Lock, Shared Lock): Read Lock이라고도 불리는 S-Lock은 트랜잭션이 읽기를 할 때 사용하는 락이며, 데이터를 읽기만하기 때문에 같은 S-Lock 끼리는 동시에 접근이 가능하지만, write 작업은 막습니다.
- 배타 락 (X-Lock, Exclusive Lock): Write Lock이라고도 불리며, 데이터를 변경할 때 사용하는 락입니다. 트랜잭션이 완료될 때까지 유지되며, X-Lock이 끝나기 전까지 read/write를 모두 막습니다.
비관적 락을 사용하게 되면 동시성 문제를 방지할 수 있으나, 데드락이 걸릴 수 있기 때문에 주의해야 합니다.
데드락(Deadlock)이란 둘 이상의 프로세스가 서로를 기다리는 상황이 발생하여 프로세스가 영원히 멈춰버리는 현상
낙관적 락(Optimistic Lock)은 실제로 Lock을 사용하지 않고 version을 통해 데이터의 정합성을 맞춥니다.
먼저 데이터를 읽은 후에 update를 수행할 때 내가 현재 읽은 버전이 변경되지 않았는지 확인하며 업데이트를 진행합니다.
내가 읽은 버전에서 수정사항이 생겼을 경우에는 application에서 다시 읽은 후에 작업을 수행해야 합니다.
비관적 락(Pessimistic Lock) 구현
ProductRepository에 아래와 같은 메서드를 추가합니다.
public interface ProductRepository extends JpaRepository<Product, Long> {
default Product getById(Long id) {
return findById(id)
.orElseThrow(NoSuchElementException::new);
}
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select p from Product p where p.id = :id")
Product findByIdWithPessimisticLock(Long id);
}이를 사용하는 서비스 코드를 작성합니다.
@Service
@RequiredArgsConstructor
public class PessimisticLockService {
private final ProductRepository productRepository;
@Transactional
public void decrease(Long id) {
Product product = productRepository.findByIdWithPessimisticLock(id);
product.decrease();
productRepository.saveAndFlush(product);
}
}테스트 코드를 작성하겠습니다.
@SpringBootTest
class PessimisticLockServiceTest {
@Autowired
PessimisticLockService pessimisticLockService;
@Autowired
ProductRepository productRepository;
@Test
void 비관적_락_테스트() throws InterruptedException {
// given
Long id = productRepository.saveAndFlush(new Product(1L, 100)).getId();
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
// when
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
pessimisticLockService.decrease(id);
} finally {
latch.countDown();
}
});
}
latch.await();
// then
Product product = productRepository.getById(id);
assertThat(product.getQuantity()).isEqualTo(0);
productRepository.deleteAll();
}
}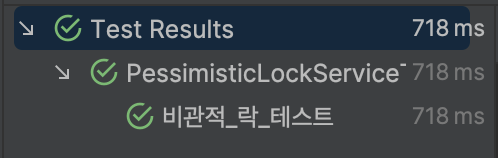
위와 같이 100개의 쓰레드를 동시에 실행하는 테스트 코드는 성공한다는걸 확인할 수 있습니다.
Repository에 등록한 findByIdWithPessimisticLock 메서드의 쿼리를 살펴보면 아래와 같습니다.
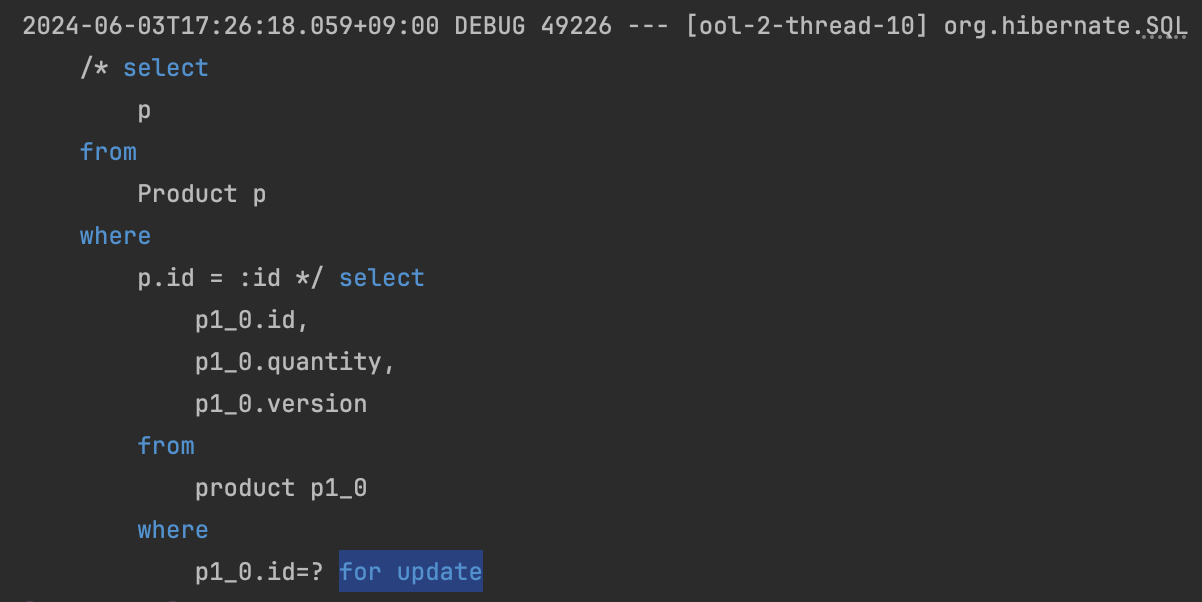
select for update 쿼리를 통해 X-lock을 획득하는 것을 확인할 수 있습니다.
다중 서버 환경에서의 테스트
Controller에서 PessimisticLockService를 사용하도록 수정합니다.
@RestController
@RequiredArgsConstructor
public class ProductController {
private final ProductService productService;
private final ProductRepository productRepository;
private final PessimisticLockService pessimisticLockService;
@GetMapping("/products")
public void createProduct() {
productRepository.save(new Product(1L, 100));
}
@GetMapping("products/{id}")
public Product getProduct(@PathVariable Long id) {
return productRepository.getById(id);
}
@GetMapping("/products/{id}/decrease")
public void decreaseProduct(@PathVariable Long id) {
pessimisticLockService.decrease(id);
}
}이후 localhost:8080/products으로 get 요청을 보내고 localhost:8080/products/1에서 확인해봅니다.
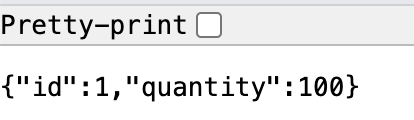
위와 같이 상품이 생성되었다면, 100개의 요청을 동시에 보내겠습니다.
다중 서버에서의 테스트 코드는 이전 글과 동일합니다.
@Test
void 다중_서버_환경에서의_테스트() throws InterruptedException {
// given
int threadCount = 100;
RestTemplate restTemplate = new RestTemplate();
ExecutorService executorService = Executors.newFixedThreadPool(40);
CountDownLatch latch = new CountDownLatch(threadCount);
// when
for (int i = 0; i < threadCount; i++) {
final int ii = i;
executorService.submit(() -> {
try {
int port = (ii % 2 == 0) ? 8080 : 8085;
ResponseEntity<Void> forEntity = restTemplate
.getForEntity("http://localhost:" + port + "/products/1/decrease", Void.class);
} finally {
latch.countDown();
}
});
}
latch.await();
}
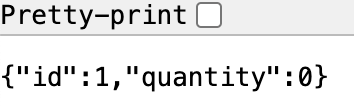
테스트가 실행되었고 100개의 재고가 줄어든 걸 확인할 수 있습니다.
낙관적 락(Optimistic Lock) 구현
낙관적 락은 실제 Lock을 이용하는 것이 아닌 버전을 이용하는 것이므로, version에 대한 필드가 추가됩니다.
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
public class Product {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private int quantity;
@Version
private int version;
public Product(Long id, int quantity) {
this.id = id;
this.quantity = quantity;
}
public void decrease() {
if (this.quantity == 0) {
throw new RuntimeException("재고는 0 이하가 될 수 없습니다.");
}
this.quantity --;
}
}ProductRepository에 다음과 같은 메서드를 추가합니다.
public interface ProductRepository extends JpaRepository<Product, Long> {
...
@Lock(LockModeType.OPTIMISTIC)
@Query("select p from Product p where p.id = :id")
Product findByWithOptimisticLock(Long id);
...
}이를 사용하는 서비스 코드를 작성합니다.
@Service
@RequiredArgsConstructor
public class OptimisticLockService {
private final ProductRepository productRepository;
@Transactional
public void decrease(Long id) {
Product product = productRepository.findByWithOptimisticLock(id);
product.decrease();
productRepository.saveAndFlush(product);
}
}낙관적 락은 실패 시 예외가 발생하는데 이 때 재시도를 해주어야 합니다.
재시도를 하는 OptimisticLockFacade를 작성해줍니다.
@Service
@RequiredArgsConstructor
public class OptimisticLockFacade {
private final OptimisticLockService optimisticLockService;
public void decrease(Long id) {
while (true) {
try {
optimisticLockService.decrease(id);
break;
} catch (Exception e) {
try {
Thread.sleep(50);
} catch (StaleObjectStateException | InterruptedException ex) {
System.out.println("ERROR!!!");
throw new RuntimeException(ex);
}
}
}
}
}이제 테스트 코드를 작성해보겠습니다.
@SpringBootTest
class OptimisticLockFacadeTest {
@Autowired
private OptimisticLockFacade optimisticLockFacade;
@Autowired
private ProductRepository productRepository;
@Test
void 낙관적_락_테스트() throws InterruptedException {
// given
Long id = productRepository.saveAndFlush(new Product(1L, 100)).getId();
int threadCount = 100;
ExecutorService executorService = Executors.newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
//when
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
optimisticLockFacade.decrease(id);
} finally {
latch.countDown();
}
});
}
latch.await();
// then
Product product = productRepository.getById(id);
assertThat(product.getQuantity()).isEqualTo(0);
productRepository.deleteAll();
}
}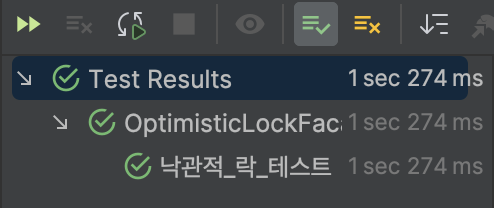
테스트에 성공하는 것을 확인할 수 있습니다.
다중 서버 환경에서의 테스트
컨트롤러 코드를 수정해줍니다.
@RestController
@RequiredArgsConstructor
public class ProductController {
private final ProductService productService;
private final ProductRepository productRepository;
private final PessimisticLockService pessimisticLockService;
private final OptimisticLockFacade optimisticLockFacade;
...
@GetMapping("/products/{id}/decrease")
public void decreaseProduct(@PathVariable Long id) {
optimisticLockFacade.decrease(id);
}
...
}아까와 마찬가지로 서버를 2개를 띄운 후, 동시에 100개의 요청을 보내는 테스트를 실행하면 결과는 다음과 같습니다.

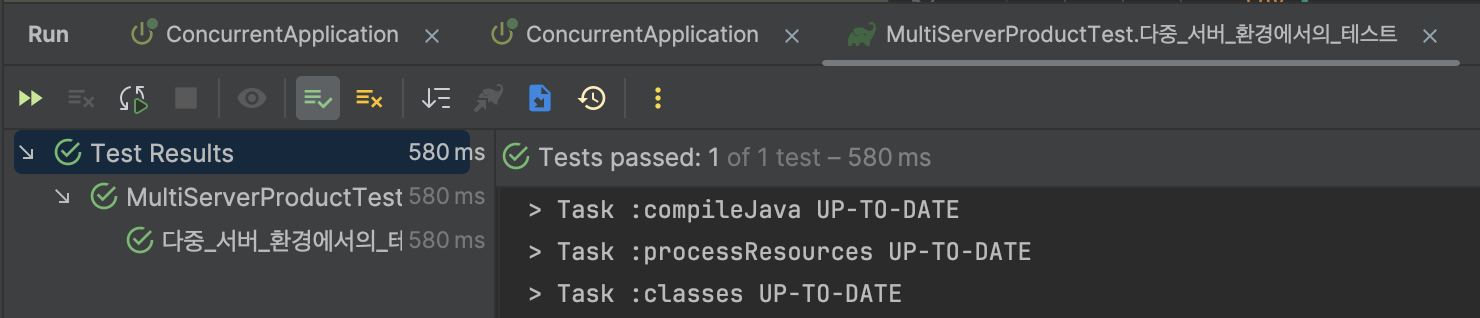
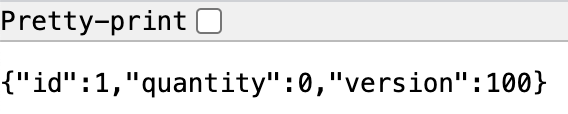
수량은 100개가 줄었고 수량이 업데이트 된 횟수만큼 version 컬럼의 값이 증가한 것을 확인할 수 있습니다.
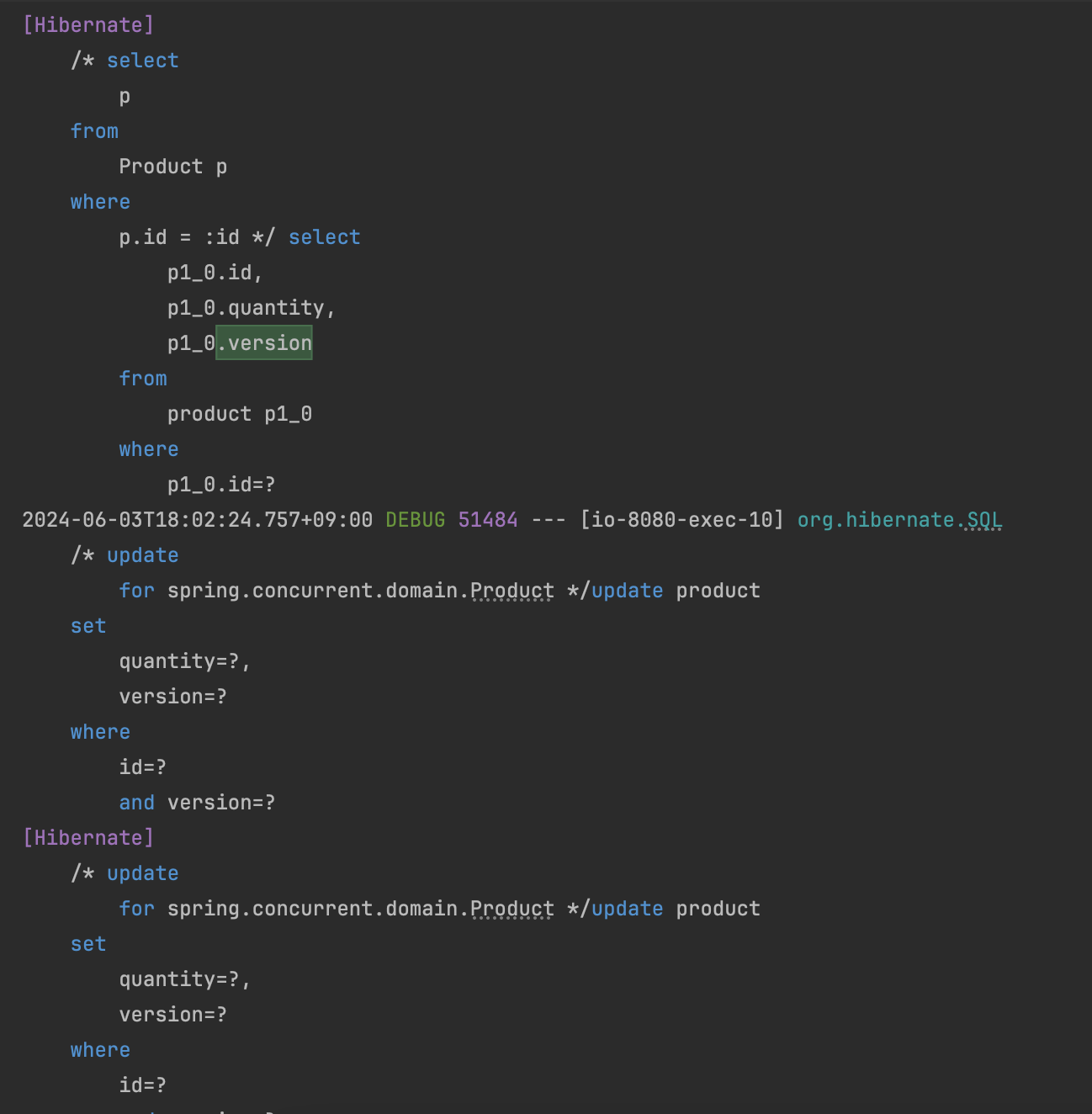
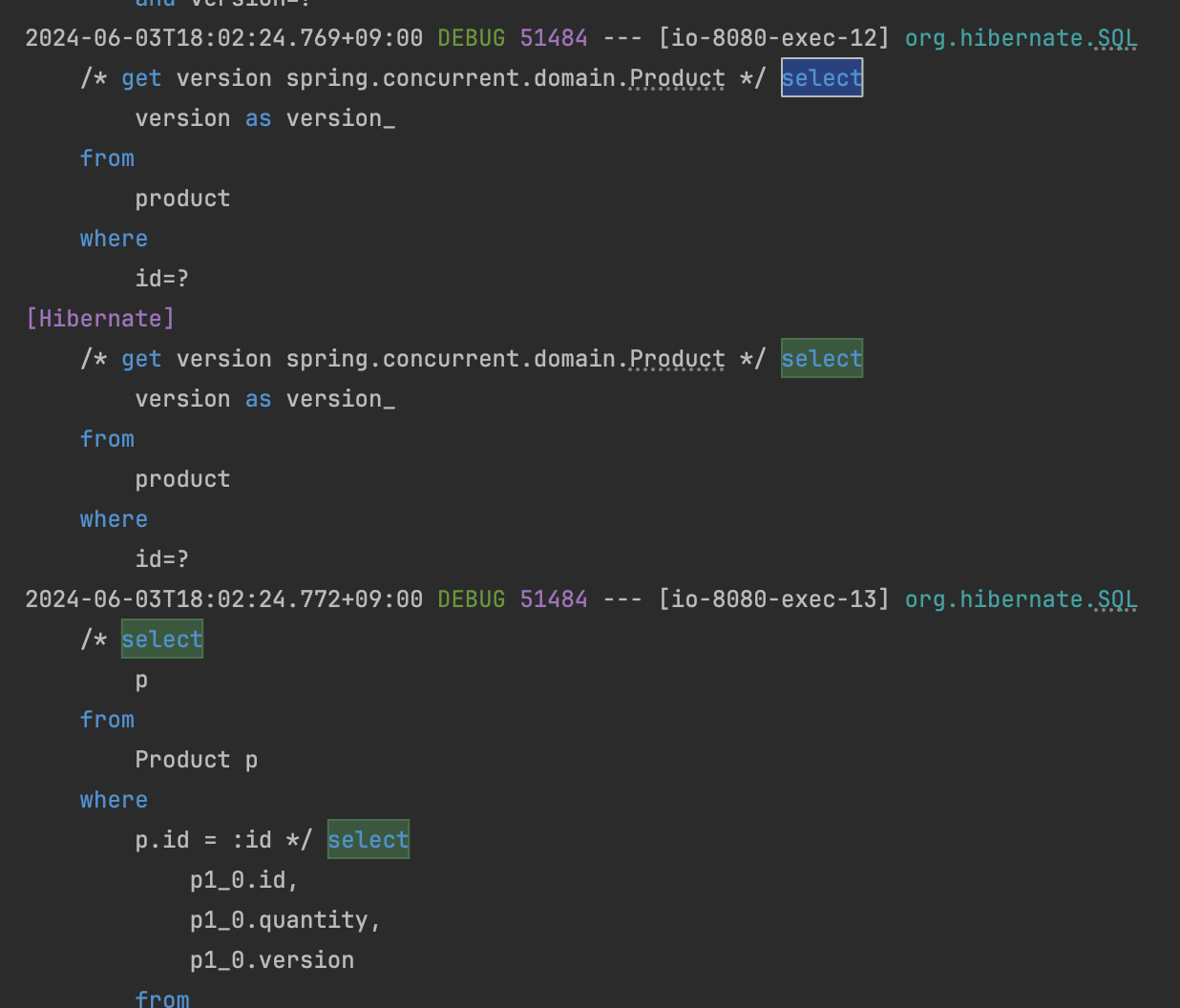
또한 발생한 쿼리를 확인해보면 Product를 조회하고 update를 해주고 또한 version에 대한 정보를 지속적으로 확인하는 것을 알 수 있습니다.
낙관적 락과 비관적 락 장단점과 비교
성능
비관적 락은 데이터 자체에 락을 걸기 때문에 성능이 많이 저하되며, 서로의 자원이 필요한 경우에는 데드락이 발생할 수 있습니다.
낙관적 락은 트랜잭션을 사용하지 않기 때문에 성능적으로 비관적 락보다 좋다고 볼 수 있습니다.
어떤 상황에서 어떤 전략을 사용?
자원에 대한 충돌이 많이 발생하는 경우에는 비관적 락이 더 효과적입니다.
비관적 락은 자원에 접근하기 전에 먼저 Lock을 획득합니다. 이를 통해 다른 트랜잭션이 동시에 같은 자원에 접근하는 것을 방지할 수 있습니다.
하지만 낙관적 락은 데이터 변경 시 version을 통한 충돌을 감지하고 처리하는 방식이므로, 충돌이 자주 발생하면 롤백이 필요해집니다.
낙관적 락과 비관적 락 사용 시 문제
낙관적 락 혹은 비관적 락을 사용하는 경우, 단일 웹 서버 환경 뿐만 아니라 다중 웹 서버 환경에서도 동시성 문제를 방지할 수 있었습니다.
그러나 스케일 아웃된 DB환경에서는 이들을 통해서 동시성 제어를 할 수 없다는 문제점이 있습니다. DB가 스케일 아웃된 환경이라면 Redis 혹은 Zookeeper를 이용한 분산락을 구현해야 합니다.
이들을 사용하는 방법을 알아보기 전에, 다음 글에서는 MySQL에서 사용할 수 있는 Named Lock을 통해 분산 락을 구현하는 방법에 대해 알아보도록 하겠습니다.
Named Lock도 역시 스케일아웃된 DB 환경에서는 동시성 제어를 할 수 없습니다.
정리
이번 글에서는 데이터베이스의 낙관적 락과 비관적 락에 대한 개념과 구현 방법에 대해 알아보았습니다.
위 두 방법을 사용하면 단일 서버 뿐만 아니라 다중 서버 환경에서도 동시성 문제를 해결할 수 있다는 것을 확인했습니다. 다음 글에서는 MySQL에서 제공하는 USER-LEVEL Lock(Named Lock)을 통한 분산락의 구현방법에 대해 알아보겠습니다.
참고
https://ttl-blog.tistory.com/1568
https://velog.io/@bagt/Database-낙관적-락-비관적-락
https://velog.io/@a01021039107/분산락으로-해결하는-동시성-문제이론편
