PAPER
Abstract
시계열 데이터의 보편적인 표현 학습을 목표로 하는 프레임워크이다.
- 분류, 이상 탐지, 예측 task의 representation learning의 downstream task로 풀고자 하는 모델
- augmented context views(증강된 컨텍스트 뷰)를 사용하여 계층적으로 대조 학습을 수행한다. 이를 통해 타임스탬프에 대해 견고한 문맥적 표현을 학습한다.
- 또한, 특정 시계열 내 하위 시퀀스의 표현은 관련된 타임스탬프 표현에 대해 간단한 집계(aggregation)를 통해 얻을 수 있다.
- UCR 외 5개의 데이터셋에서 기존 비지도 학습 기반 시계열 표현 학습(SOTA) 방법들보다 유의미한 성능 향상을 보여줬다.
- 학습된 타임스탬프 수준의 표현은 시계열 예측 및 이상 탐지 작업에서도 우수한 결과를 기록
- 시계열 분류, 예측, 이상탐지 등 다양한 작업에서 유연하고 보편적인 표현 학습 방법을 제공한다.
1. Introduction
시계열 데이터는 금융 시장, 수요 예측, 기후 모델링과 같은 다양한 산업에서 중요한 역할을 한다. 시계열 데이터를 위한 보편적인 표현을 학습하는 것은 근본적이지만 도전적인 문제이다.
- 많은 연구들(Tonekaboni; 2021, Franceschi; 2019, Wu; 2018)은 시계열 입력 데이터의 전체 구간(segment)을 설명하는 인스턴스 수준의 표현(instance-level representation)을 학습하는 데 초점을 맞췄다. 이러한 접근은 clustering, classification 같은 작업에서 큰 성공을 보였다.
- 또한, 최근 연구(Eldele; 2021, Franceschi; 2019 등)에서는 시계열의 고유 구조를 학습하기 위해 contrastive loss를 사용하였다.
- 첫째, instance 수준의 표현은 세밀한 표현(fine-grained representations)을 필요로 하는 작업에는 적합하지 않을 수 있다. 예를 들어, time series forecasting과 anomaly detection과 같은 작업에서는 특정 타임스탬프 또는 하위 시퀀스(sub-series)에서 목표(target)를 추론해야 한다. 하지만 전체 시계열의 단순화된 표현(coarse-grained representation)만으로는 만족스러운 성능을 달성하기 어렵다.
- 둘째, 기존 방법들 중 일부는 서로 다른 세분화 수준의 multi-scale contextual information을 구분하지 않는다. 예를 들어 TNC는 일정 길이의 segment를 구별하며, T-Loss는 원본 시계열에서 무작위 하위 시퀀스를 positive samples로 사용한다. 하지만 이들 중 어느 것도 시계열의 scale-invariant 정보를 캡처하기 위해 다양한 스케일에서 시계열의 특징을 학습하지 못한다. 직관적으로, multi-scale 특징은 다양한 수준의 의미론적 정보(semantic information)를 제공하며 학습된 표현의 일반화 능력을 향상시킬 수 있다.
- 셋째, 기존의 비지도 시계열 표현 방법 대부분은 CV나 NLP 경험에서 영감을 얻었다. 이러한 domain에서는 transformation invariance(변환 불변성)이나 cropping invariance와 같은 강력한 귀납적 편향(inductive bias)이 있다. 하지만 이러한 가정은 시계열 모델링에서는 항상 적용되지 않을 수 있다. 예를 들어, 자르기는 이미지에 대해 자주 사용되는 데이터 증강 전략이지만, 시계열의 분포와 의미는 시간이 지남에 따라 변화할 수 있으며, 잘린 하위 시퀀스는 원래 시계열과 명백히 다른 분포를 가질 가능성이 크다.
본 논문의 기여(contributions):
- 이러한 문제를 해결하기 위해 TS2Vec이라는 보편적인 대조 학습 framwork를 제안한다. TS2Vec은 모든 의미 수준에서 시계열의 표현 학습을 가능하게 한다. 이 방법은 인스턴스 및 시간 차원에서 양성 및 음성 샘플을 계층적으로 구별한다. 또한, 임의의 하위 시퀀스의 전체 표현은 해당 타임스탬프에 대한 최대 풀링을 통해 얻을 수 있다.
- 또한, TS2Vec의 대조 목적은 증강된 컨텍스트 뷰를 기반으로 하며, 동일한 하위 시퀀스의 표현이 두 증강된 컨텍스트에서 일관되도록 보장한다. 이를 통해, TS2Vec은 불필요한 귀납적 편향을 도입하지 않고 각 하위 시퀀스에 대한 견고한 맥락 표현을 얻을 수 있다.
2. Method
overview
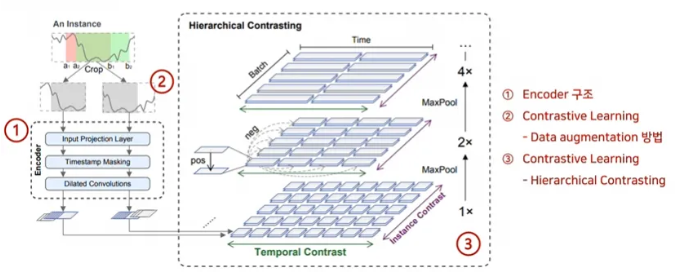
2.1 Problem Definition
- 주어진 시계열 데이터 세트 X = {x1, x2, …, x_N}에서 N개의 instance가 있다.
- 목표는 각 시계열 x를 자신을 가장 잘 설명하는 representation 로 매핑하는 비선형 임베딩 함수 를 학습하는 것이다.
- 입력 시계열 x는 TxF 차원을 가지며, 여기서 T는 시퀀스 길이, F는 feature 차원이다.
- 표현 는 각 타임스탬프 t에 대한 표현 벡터를 포함하며, K는 표현 벡터의 차원이다.
2.2 Model Architecture
- TS2Vec의 전체 Architecture는 Figure 1에 제시되어 있다.
- 입력 시계열 x에서 두 개의 중첩된 하위 시퀀스를 랜덤 샘플링하여 공통 구간에서 문맥 표현의 일관성을 강화한다.
- 원시 입력인 encoder로 전달되며, 인코더는 temporal contrastive loss와 instance-wise contrastive loss를 사용하여 최적화한다.
- 총 손실은 계층적 framework에서 여러 scale에 걸쳐 합산된다.
2.3 Contextual Consistency(일관성)
- 대조 학습에서 positive pairs의 구성은 중요하다.
- 기존 연구들은 다양한 선택 전략을 사용했다.
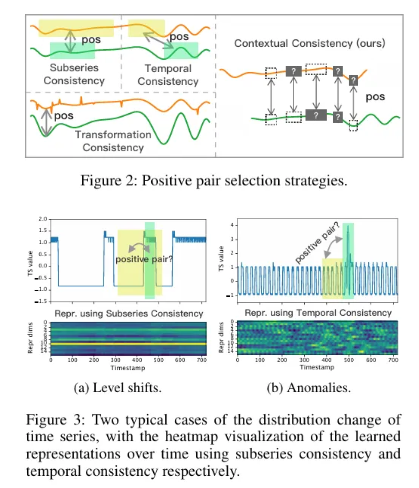
1. [Subseries](https://www.notion.so/Subseries-1727c8c3eb9c8067a466d098171e3d26?pvs=21) Consistency:
- 시계열 표현이 샘플링된 하위 시퀀스와 더 가까워지도록 유도한다.
- level shift가 있을 때 취약
2. Temporal Consistency:
- 인접한 세그먼트를 양성 샘플로 선택하여 local smoothness을 강화한다.
- 이상치(anomalies)가 발생할 때 잘못된 positive pair를 도입할 수 있다.
3. Transformation Consistency:
- 입력 시계열에 다양한 변환(스케일링, 순열 등)을 적용하여 변환 불변 표현을 학습한다.
- 변동성과 scale이 시계열 데이터셋마다 다르다는 점을 고려했을 때, transformation-invariance를 가정하는 것은 적합하지 않음- 그러나 이런 전략들은 데이터 분포에 강한 가정을 기반으로 하며, 이는 시계열 데이터에는 적합하지 않을 수 있다.
- 이를 극복하기 위해 Contextual Consistency라는 새로운 전략을 제안한다.
- 동일한 타임스탬프에서 두 개의 증강된 문맥의 표현을 positive pair로 간주한다.
- 문맥은 timestamp masking과 random cropping을 적용하여 생성한다.
- timestamp masking은 encoder 내부에서 수행되며, random cropping은 pre때 진행한다.
2.4 Hierarchical Contrasting
- 계층적 대조 손실(Hierarchical contrastive loss)을 통해 인코더가 다양한 스케일에서 표현을 학습하도록 한다.
- 학습된 타임스탬프 수준의 표현에 대해 시간 축을 따라 max pooling을 적용하고, 이를 반복적으로 계산한다.
- 특히, 최상위 의미 수준에서의 대조는 모델이 instance-level representation을 학습할 수 있도록 한다.
Temporal Contrast Loss:

- 데이터의 임베딩(표현)을 학습하여 샘플 간의 유사성 또는 불일치를 반영하도록 한다.
- 증강한 시계열끼리 같은 timestamp에 있으면 positive pairs라고 보고, 다른 timestamp에 있으면 negative pairs라고 설정한다.
- positive pair의 유사도를 최대화 하는 방법으로 학습한다.
Instance-wise Contrastive Loss:

- 인스턴스를 여러 개 두고, 같은 timestamp에서 같은 인스턴스끼리는 positive pair, 다른 instance끼리는 negative pair로 둔다.
3. Experiments
TS2Vec으로 학습된 표현을 평가하기 위해 시계열 분류, 예측, 이상 탐지 작업에 대해 실험 결과를 제공한다.
- 방법론 참고
3.1 Time Series Classification
-
목표: instance-level representation 평가
-
방법: 학습된 표현을 최대 풀링을 통해 얻어내어 분류 작업에 사용
- representation의 결과를 max pooling, SVM 모델 사용
- 모든 time series에 대해 label 존재
-
기존의 SOTA unsupervised learning 방법들과 비교:
-
T-Loss(2019): Subseries Consistency
- Triplet loss를 처음으로 도입
-
TS-TCC(2021): Transformation Consistency
-
TST
-
TNC(2021): Temporal Consistency
- Triplet loss를 사용한다.
- ADF test & Positive-Unlabeled learning
-
-
dataset:
- 125 UCR: (현재) 128개의 단변량 데이터
- 29 UEA: (현재) 36개의 다변량 데이터 (class: 3)
-
Figure4에서 모든 데이터셋에 대한 우수함을 시각적으로 보여줌
3.2 Time Series Forecasting
-
목표: 미래의 관찰값을 예측하기 위해 TS2Vec으로 학습된 표현을 활용
-
방법:
- TS2Vec으로 학습된 표현에서 마지막 타임스탬프의 표현을 사용해 선형 회귀를 적용하여 미래 값을 예측
- 단변량(Univariate) 및 다변량(Multivariate) 데이터셋을 사용
- 마지막 timestamp representation을 ridge regression을 이용하여 예측을 하였음
-
비교 기법:
- Informer: 모델의 효율성을 강조한 모델
- Transformer 기반 모델로, 긴 시계열 데이터를 처리하는 데 최적화
- TCN: Temporal Convolution Network
- 시계열 데이터 분석을 위한 CNN 모델
- LogTrans: 로그 스케일 기반의 Transformer 모델
- N-BEATS: Neural Basis Esxpansion Analysis Time Series
- LSTNet: Long- and Short-Term Time-Series Network
- Informer: 모델의 효율성을 강조한 모델
-
datasets:
- 3 ETT: h1, h1, m1
- ETT-small: 부하, 오일 온도를 포함한 2개의 station의 2개 전기 변압기 데이터
- ETT-large: 부하, 오일 온도를 포함한 39개 변전소의 39개 전기 변압기에 대한 데이터
- ETT-full: 부하, 오일 온도, 위치, 기후, 수요를 포함한 39개의 변전소, 69개 변전
- Electricity: 370개의 instance, No missing values
- 3 ETT: h1, h1, m1
-
평가 지표:
- MSE: 제곱 오차
- MAE(Mean Absolute Error, 평균 절대 오차)
-
Figure 5. 주기적 패턴과 장기적 트렌드를 모두 잘 포착함을 시각적으로 보여줌
-
실행 시간 비교(Figure 3)에서 TS2Vec이 Informer보다 훈련 시간 측면에서 더 효율적임
-
예측 길이 H는 다양하게 사용함 → representation이 universality를 가짐 증명
3.3 Time Series Anomaly Detection
-
목표: 시계열 데이터에서 이상값을 탐지
-
방법:
- 각 타임스탬프를 표현으로 변환한 뒤, 과거 점수와 비교하여 이상점 예측
- 데이터셋을 반으로 분리하여 반은 unsupervised training에 사용하고, 반은 evaluation에 사용
- 평균 및 표준 편차 기반의 이상 탐지 점수 계산
-
주요 비교 방법: unsupervised 방법들
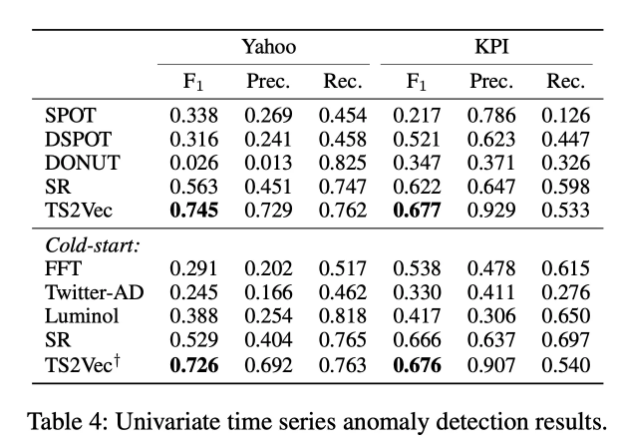
- SPOT: Streaming Peak Over Threshold
- 이상 탐지를 위해 통계적 방법을 사용하는 스트리밍 기반 알고리즘
- Extreme Value Theory를 기반으로, 정상 데이터 분포에서 outliers를 감지한다.
- 이상 탐지 임계값을 자동으로 업데이트 하여 실시간 데이터 스트림에서 이상값이 발생할 확률을 계산하여 탐지
- DSPOT: Dynamical SPOT
- SPOT 알고리즘을 확장한 것으로, 동적 환경에서의 이상 탐지에 최적화된 버전
- 데이터 분포가 시간에 따라 변화하는 환경에서도 이상값을 감지
- 임계값을 데이터 흐름에 따라 동적으로 조정
- DONUT: Deep Outlier Network
- 딥러닝 기반 이상 탐지 모델로, VAE를 활용
- 정상 데이터의 분포를 학습하여, 입력 데이터가 정상 분포에 속하지 않을 확률을 계산
- FFT: Fast Fourier Transform
- 주파수 영역에서서의 이상 탐지에 사용
- 시계열 데이터를 주파수 도메인으로 변환하여 주기적 패턴이나 이상값을 감지
- 데이터의 주요 주파수 성분을 분석하여, 예상 범위를 벗어나는 값을 탐지
- SR: Subsequence Reconstruction
- 시계열 데이터의 하위 시퀀스를 복원하여 이상값을 감지
- 정상 데이터의 하위 시퀀스는 잘 복원되지만, 이상값은 복원 오류가 큼
- AE 또는 딥러닝 기반 모델을 사용해 하위 시퀀스를 학습하고 복원
- 복원 오류를 기반으로 이상값 판단
- SPOT: Streaming Peak Over Threshold
-
datasets:
-
Yahoo: 주식인 거 같긴 한디
-
KPI: 얘도.. 모르겠당
→ 두 데이터셋 모두에 대해서 비슷한 성능 지표 결과를 나타내는 것으로 보아, 데이터셋 간의 transferability가 있다고 볼 수 있다. (저자의 생각)
-
-
평가 지표:
- F1 Score: Precision과 Recall의 조화 평균, 둘 다 비슷하게 성능을 유지해야 할 때 요긴

- Precision: 정밀도, 양성 예측의 신뢰도가 얼마나 높은지 의미

- Recall: 실제로 양성인 데이터 중에서 모델이 양성으로 올바르게 예측한 비율, 실제 양성을 얼마나 잘 찾아냈는지 의미
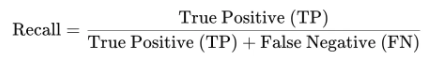
- F1 Score: Precision과 Recall의 조화 평균, 둘 다 비슷하게 성능을 유지해야 할 때 요긴
3.4 Additional Observations
- 전이 가능성(transferability)이 뛰어나며, 다른 데이터셋에서도 일관된 성능을 보임
- 계층적 대조 학습 전략이 시간 축의 다양한 스케일에서 정보를 학습함으로써 성능을 향상시킴
4. Analysis
4.1 Ablation Study
- 목적: TS2Vec의 주요 구성 요소의 효과를 확인하기 위해 실험을 수행
- 비교 모델: 완전한 TS2Vec과 변형 6가지
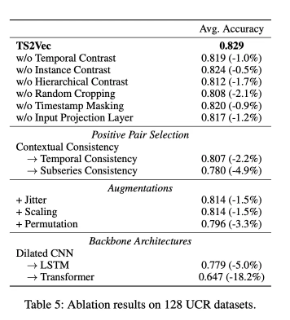
- w/o Temporal Contrast: temporal contrastive loss 제거
- w/o Instance Contrast: instance-wise contrastive loss 제거
- w/o Hierarchical Contrast: 가장 낮은 수준에서만 대조 학습 수행
- w/o Random Cropping: 전체 시퀀스 사용
- representation collapse 현상 발생
- 모델이 contextual information이 아닌, positional embedding에 의존적인 representation을 학습함
- w/o Timestamp Masking: 1로 채움
- w/o Input Projection Layer: input projection layer 제거
- Table 5를 보면 모든 구성 요소가 없으면 안 되는 필수 요소임
- Figure 6: timestamp masking, hierarchical contrastive learning이 없는 경우 크게 감소
4.2 Robustness to Missing Data
- 목적: 실제 데이터에서 흔히 발생하는 결측값에 대한 TS2Vec의 강건성 평가
- 방법: 4개의 대형 UCR dataset에서 input observation의 timestamp에 대해서 특정한 missing rate에 따라 랜덤하게 마스킹하여 훈련과 테스트 진행
- classification accuracy 측정
- Hierarchical Constrast와 Timestamp Masking이 모두 있을 때, missing value에 강건함을 보임
- 결과: 50%의 결측치가 있는 경우에도 높은 정확도 유지
4.3 Visualized Explanation
-
목적: 학습된 표현이 시간적 특성을 어떻게 캡처하는지 시각적으로 설명
-
방법: 3개의 데이터셋(ScreenType, Phoneme, Refrigeration Devices)을 선택하여, 학습된 표현을 시각화
-
Figure 7:
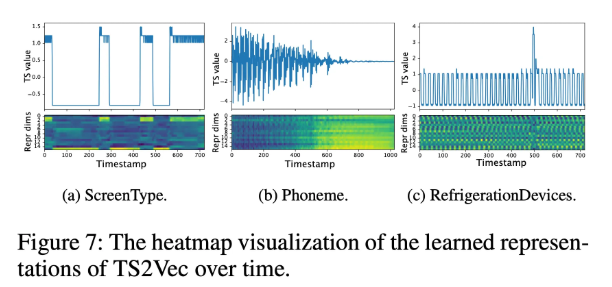
- ScreenType: 고저 신호 차이를 정확히 구별
- Phoneme: 시간 축을 따라 변화하는 오디오 신호의 패턴을 포착
- Refrigeration Devices: 시계열 데이터의 주기적 패턴과 갑작스러운 변화(spike)를 캡처
-
시간적 특성의 변화를 효과적으로 감지함
-
representation이 normal 과 anomaly를 잘 구분할 수 있음을 보임
-
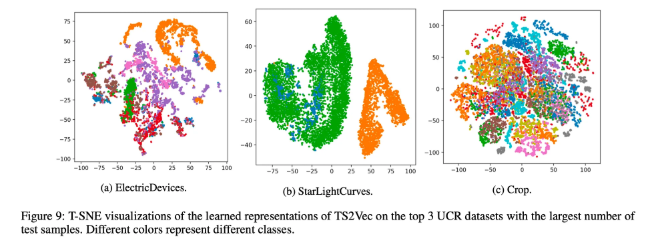
Figure 9: latent space 상에서 서로 다른 class를 잘 구분하고 있음
5. Conclusion:
- TS2Vec의 기여:
- 시계열 데이터를 위한 범용 표현 학습 프레임워크 제안
- 임의의 subseries에 대해서 다영한 semantic level을 반영한 contextual representation learning framework 제안
- 본 논문에서 처음으로 모든 task나 domain에 대해서 보편적이고 유연하게 적용할 수 있는 방법론을 제안함
- 계층적 대조 학습(hierarchical contrastive learning)을 활용하여 스케일 불변 표현(scale-invariant representations)을 학습-instance-wise contrast, temporal contrast loss
- contextual consistency 개념을 기반으로 한 augmentation 기법
- 시계열 데이터를 위한 범용 표현 학습 프레임워크 제안
- 결과:
- 시계열 분류, 예측, 이상 탐지와 같은 태스크에서 TS2Vec가 일관되게 높은 성능을 달성
- 결측값 처리 및 다양한 시간적 맥락(context)을 포착하는 데 탁월한 성능을 보임
- 시각화 결과는 TS2Vec가 시계열 데이터의 동적 특성을 잘 학습했음을 보여줌
- 향후 연구:
- TS2Vec의 프레임워크는 다양한 도메인에 적용할 수 있는 잠재력을 보유
- 추가적인 연구를 통해 다른 도메인에서도 적용 가능성을 탐색할 계획
CODE
Encoder
-
1일 때는 인접한 데이터 포인트 학습, 2일 때는 2칸 간격, … dilation은 2의 k승
-
Input Projection Layer:
- 시계열 데이터가 input으로 들어오게 되면, linear projection을 통해 고차원의 latent vector 로 mapping, nan값이 있다면 0으로 대치(계산하기 위해)
-
Timestamp Masking:
- 선행 연구의 masking 기법과 차이점: raw data에 masking을 하는 것이 아니라 z에 masking을 한다.
- raw time series values는 데이터마다 분포가 다름 → 그렇기에 절대적인 0의 값으로 masking 처리하는 것은 본연의 특징적인 의미 파악을 어렵게 한다.
- z의 각 timestamp에 대하여 random하게 binary masking
- augmented context view를 생성하는 수단
- 선행 연구의 masking 기법과 차이점: raw data에 masking을 하는 것이 아니라 z에 masking을 한다.
-
Dilated Convolution Layer:
- 이 레이어를 통해 최종 contextual representation 도출
- Dilated Convolution Layer의 각 block은 2개의 1D Conv로 구성
- k번째 block의 dilation(팽창) parameter는 2^k가 되도록 설정
- Dilated Convolution으로 Large Receptive(수용) Field 반영이 가능
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
from .dilated_conv import DilatedConvEncoder
def generate_continuous_mask(B, T, n=5, l=0.1): # random masking
res = torch.full((B, T), True, dtype=torch.bool)
if isinstance(n, float):
n = int(n * T)
n = max(min(n, T // 2), 1)
if isinstance(l, float):
l = int(l * T)
l = max(l, 1)
for i in range(B):
for _ in range(n):
t = np.random.randint(T-l+1)
res[i, t:t+l] = False
return res
def generate_binomial_mask(B, T, p=0.5): # 이항 분포
return torch.from_numpy(np.random.binomial(1, p, size=(B, T))).to(torch.bool)
class TSEncoder(nn.Module):
def __init__(self, input_dims, output_dims, hidden_dims=64, depth=10, mask_mode='binomial'):
super().__init__()
self.input_dims = input_dims
self.output_dims = output_dims
self.hidden_dims = hidden_dims
self.mask_mode = mask_mode
self.input_fc = nn.Linear(input_dims, hidden_dims)
self.feature_extractor = DilatedConvEncoder(
hidden_dims,
[hidden_dims] * depth + [output_dims],
kernel_size=3
)
self.repr_dropout = nn.Dropout(p=0.1)
def forward(self, x, mask=None): # x: B x T x input_dims
nan_mask = ~x.isnan().any(axis=-1)
x[~nan_mask] = 0
x = self.input_fc(x) # B x T x Ch
# generate & apply mask
if mask is None:
if self.training:
mask = self.mask_mode
else:
mask = 'all_true'
if mask == 'binomial':
mask = generate_binomial_mask(x.size(0), x.size(1)).to(x.device)
elif mask == 'continuous':
mask = generate_continuous_mask(x.size(0), x.size(1)).to(x.device)
elif mask == 'all_true':
mask = x.new_full((x.size(0), x.size(1)), True, dtype=torch.bool)
elif mask == 'all_false':
mask = x.new_full((x.size(0), x.size(1)), False, dtype=torch.bool)
elif mask == 'mask_last':
mask = x.new_full((x.size(0), x.size(1)), True, dtype=torch.bool)
mask[:, -1] = False
mask &= nan_mask
x[~mask] = 0
# conv encoder
x = x.transpose(1, 2) # B x Ch x T
x = self.repr_dropout(self.feature_extractor(x)) # B x Co x T
x = x.transpose(1, 2) # B x T x Co
return x
-
B: batch size
-
T: sequence length
-
n: masking 구간 수
-
l: 각 구간의 길이 비율
-
True: 사용, False: masking
-
if isinstance문을 통해 l이 float이면, int로 수정한다.
-
l을 통해 T의 l 퍼센트만 masking 할 수 있다.
-
input_fc: fcl로 입력 데이터의 차원을 모델 내부에서 사용할 은닉 차원으로 변환
-
feature extractor: DilatedConvEncoder(Dilated Conv 기반의 시계열 데이터 처리기)를 사용하여 여러 층의 conv layer를 쌓아 깊은 특징을 추출
-
repr_dropout: representation을 드롭아웃하여 과적합 방지
-
forward:
- 결측치 처리
- input_fc 통과
- 마스킹 적용
- feature_extractor 적용 후 드롭아웃, 원래 차원으로 복원(transpose)
Dilated Conv
import torch
from torch import nn
import torch.nn.functional as F
import numpy as np
class SamePadConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation=1, groups=1):
super().__init__()
self.receptive_field = (kernel_size - 1) * dilation + 1
padding = self.receptive_field // 2
self.conv = nn.Conv1d(
in_channels, out_channels, kernel_size,
padding=padding,
dilation=dilation,
groups=groups
)
self.remove = 1 if self.receptive_field % 2 == 0 else 0
def forward(self, x):
out = self.conv(x)
if self.remove > 0:
out = out[:, :, : -self.remove]
return out
class ConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, dilation, final=False):
super().__init__()
self.conv1 = SamePadConv(in_channels, out_channels, kernel_size, dilation=dilation)
self.conv2 = SamePadConv(out_channels, out_channels, kernel_size, dilation=dilation)
self.projector = nn.Conv1d(in_channels, out_channels, 1) if in_channels != out_channels or final else None
def forward(self, x):
residual = x if self.projector is None else self.projector(x)
x = F.gelu(x)
x = self.conv1(x)
x = F.gelu(x)
x = self.conv2(x)
return x + residual
class DilatedConvEncoder(nn.Module):
def __init__(self, in_channels, channels, kernel_size):
super().__init__()
self.net = nn.Sequential(*[
ConvBlock(
channels[i-1] if i > 0 else in_channels,
channels[i],
kernel_size=kernel_size,
dilation=2**i,
final=(i == len(channels)-1)
)
for i in range(len(channels))
])
def forward(self, x):
return self.net(x)
-
Same Pad Conv:
- padding을 맞춰줘야 학습 가능
- 수용 필드는 팽창 정도에 따라 조절됨
- padding은 수용 필드의 절반만 줌
- 홀수 필터 크기를 처리하기 위해 수용 필드가 짝수인 경우 remove
-
ConvBlock:
- 활성화 함수로 gelu 사용
- 시계열 데이터를 처리하기 위한 Residual Block
- conv 2개를 지나 나온 x와 residual을 합쳐 반환
-
DilatedConvEncoder:
- ConvBlock을 여러 개 쌓아 이 과정을 통해 시계열 데이터의 장기적 종속성을 학습
losses
import torch
from torch import nn
import torch.nn.functional as F
def hierarchical_contrastive_loss(z1, z2, alpha=0.5, temporal_unit=0):
loss = torch.tensor(0., device=z1.device)
d = 0
while z1.size(1) > 1:
if alpha != 0:
loss += alpha * instance_contrastive_loss(z1, z2)
if d >= temporal_unit:
if 1 - alpha != 0:
loss += (1 - alpha) * temporal_contrastive_loss(z1, z2)
d += 1
z1 = F.max_pool1d(z1.transpose(1, 2), kernel_size=2).transpose(1, 2)
z2 = F.max_pool1d(z2.transpose(1, 2), kernel_size=2).transpose(1, 2)
if z1.size(1) == 1:
if alpha != 0:
loss += alpha * instance_contrastive_loss(z1, z2)
d += 1
return loss / d
def instance_contrastive_loss(z1, z2):
B, T = z1.size(0), z1.size(1)
if B == 1:
return z1.new_tensor(0.)
z = torch.cat([z1, z2], dim=0) # 2B x T x C
z = z.transpose(0, 1) # T x 2B x C
sim = torch.matmul(z, z.transpose(1, 2)) # T x 2B x 2B
logits = torch.tril(sim, diagonal=-1)[:, :, :-1] # T x 2B x (2B-1)
logits += torch.triu(sim, diagonal=1)[:, :, 1:]
logits = -F.log_softmax(logits, dim=-1)
i = torch.arange(B, device=z1.device)
loss = (logits[:, i, B + i - 1].mean() + logits[:, B + i, i].mean()) / 2
return loss
def temporal_contrastive_loss(z1, z2):
B, T = z1.size(0), z1.size(1)
if T == 1:
return z1.new_tensor(0.)
z = torch.cat([z1, z2], dim=1) # B x 2T x C
sim = torch.matmul(z, z.transpose(1, 2)) # B x 2T x 2T
logits = torch.tril(sim, diagonal=-1)[:, :, :-1] # B x 2T x (2T-1)
logits += torch.triu(sim, diagonal=1)[:, :, 1:]
logits = -F.log_softmax(logits, dim=-1)
t = torch.arange(T, device=z1.device)
loss = (logits[:, t, T + t - 1].mean() + logits[:, T + t, t].mean()) / 2
return loss
-
hierarchical contrastive loss: temporal + instance-wise loss (Weighted sum)
-
시간 축 길이를 줄여가며
-
양성 쌍 z1, z2의 loss 계산
-
instance_contrast_loss:
-
sim: cosine similarity
-
logits: 대조 학습 손실 계산
-
tril: 하 삼각 행렬 추출(diagonal=-1)
-
triu: 상 삼각 행렬 추출 (diagonal=1)

-
[참고]
sim: tensor([[[ 6.6948, 12.4097, 8.1835, ..., 4.2000, 4.5617, 9.4699],
[ 12.4097, 241.6718, 146.1515, ..., 7.9227, 8.1328, 203.1319],
[ 8.1835, 146.1515, 123.6746, ..., 6.8797, 6.9553, 152.5538],
...,
[ 4.8771, 6.5622, 61.5992, ..., 83.5320, 69.7958, 49.2751],
[ 4.3449, 6.3054, 56.5741, ..., 69.7958, 76.8034, 45.2210],
[ 5.7579, 7.8597, 49.5458, ..., 49.2751, 45.2210, 55.6845]]],
device='cuda:0', grad_fn=<UnsafeViewBackward0>)
logits1: tensor([[[ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],Model-TS2Vec
import torch
import torch.nn.functional as F
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
# from models import TSEncoder
# from models.losses import hierarchical_contrastive_loss
# from utils import take_per_row, split_with_nan, centerize_vary_length_series, torch_pad_nan
import math
class TS2Vec:
'''The TS2Vec model'''
def __init__(
self,
input_dims,
output_dims=320,
hidden_dims=64,
depth=10,
device='cuda',
lr=0.001,
batch_size=16,
max_train_length=None,
temporal_unit=0,
after_iter_callback=None,
after_epoch_callback=None
):
''' Initialize a TS2Vec model.
Args:
input_dims (int): The input dimension. For a univariate time series, this should be set to 1.
output_dims (int): The representation dimension.
hidden_dims (int): The hidden dimension of the encoder.
depth (int): The number of hidden residual blocks in the encoder.
device (int): The gpu used for training and inference.
lr (int): The learning rate.
batch_size (int): The batch size.
max_train_length (Union[int, NoneType]): The maximum allowed sequence length for training. For sequence with a length greater than <max_train_length>, it would be cropped into some sequences, each of which has a length less than <max_train_length>.
temporal_unit (int): The minimum unit to perform temporal contrast. When training on a very long sequence, this param helps to reduce the cost of time and memory.
after_iter_callback (Union[Callable, NoneType]): A callback function that would be called after each iteration.
after_epoch_callback (Union[Callable, NoneType]): A callback function that would be called after each epoch.
'''
super().__init__()
self.device = device
self.lr = lr
self.batch_size = batch_size
self.max_train_length = max_train_length
self.temporal_unit = temporal_unit
self._net = TSEncoder(input_dims=input_dims, output_dims=output_dims, hidden_dims=hidden_dims, depth=depth).to(self.device)
self.net = torch.optim.swa_utils.AveragedModel(self._net)
self.net.update_parameters(self._net)
self.after_iter_callback = after_iter_callback
self.after_epoch_callback = after_epoch_callback
self.n_epochs = 0
self.n_iters = 0
def fit(self, train_data, n_epochs=None, n_iters=None, verbose=False):
''' Training the TS2Vec model.
Args:
train_data (numpy.ndarray): The training data. It should have a shape of (n_instance, n_timestamps, n_features). All missing data should be set to NaN.
n_epochs (Union[int, NoneType]): The number of epochs. When this reaches, the training stops.
n_iters (Union[int, NoneType]): The number of iterations. When this reaches, the training stops. If both n_epochs and n_iters are not specified, a default setting would be used that sets n_iters to 200 for a dataset with size <= 100000, 600 otherwise.
verbose (bool): Whether to print the training loss after each epoch.
Returns:
loss_log: a list containing the training losses on each epoch.
'''
assert train_data.ndim == 3
if n_iters is None and n_epochs is None:
n_iters = 200 if train_data.size <= 100000 else 600 # default param for n_iters
if self.max_train_length is not None:
sections = train_data.shape[1] // self.max_train_length
if sections >= 2:
train_data = np.concatenate(split_with_nan(train_data, sections, axis=1), axis=0)
temporal_missing = np.isnan(train_data).all(axis=-1).any(axis=0)
if temporal_missing[0] or temporal_missing[-1]:
train_data = centerize_vary_length_series(train_data)
train_data = train_data[~np.isnan(train_data).all(axis=2).all(axis=1)]
train_dataset = TensorDataset(torch.from_numpy(train_data).to(torch.float))
train_loader = DataLoader(train_dataset, batch_size=min(self.batch_size, len(train_dataset)), shuffle=True, drop_last=True)
optimizer = torch.optim.AdamW(self._net.parameters(), lr=self.lr)
loss_log = []
while True:
if n_epochs is not None and self.n_epochs >= n_epochs:
break
cum_loss = 0
n_epoch_iters = 0
interrupted = False
for batch in train_loader:
if n_iters is not None and self.n_iters >= n_iters:
interrupted = True
break
x = batch[0]
if self.max_train_length is not None and x.size(1) > self.max_train_length:
window_offset = np.random.randint(x.size(1) - self.max_train_length + 1)
x = x[:, window_offset : window_offset + self.max_train_length]
x = x.to(self.device)
ts_l = x.size(1)
crop_l = np.random.randint(low=2 ** (self.temporal_unit + 1), high=ts_l+1)
crop_left = np.random.randint(ts_l - crop_l + 1)
crop_right = crop_left + crop_l
crop_eleft = np.random.randint(crop_left + 1)
crop_eright = np.random.randint(low=crop_right, high=ts_l + 1)
crop_offset = np.random.randint(low=-crop_eleft, high=ts_l - crop_eright + 1, size=x.size(0))
optimizer.zero_grad()
out1 = self._net(take_per_row(x, crop_offset + crop_eleft, crop_right - crop_eleft))
out1 = out1[:, -crop_l:]
out2 = self._net(take_per_row(x, crop_offset + crop_left, crop_eright - crop_left))
out2 = out2[:, :crop_l]
loss = hierarchical_contrastive_loss(
out1,
out2,
temporal_unit=self.temporal_unit
)
loss.backward()
optimizer.step()
self.net.update_parameters(self._net)
cum_loss += loss.item()
n_epoch_iters += 1
self.n_iters += 1
if self.after_iter_callback is not None:
self.after_iter_callback(self, loss.item())
if interrupted:
break
cum_loss /= n_epoch_iters
loss_log.append(cum_loss)
if verbose:
print(f"Epoch #{self.n_epochs}: loss={cum_loss}")
self.n_epochs += 1
if self.after_epoch_callback is not None:
self.after_epoch_callback(self, cum_loss)
return loss_log
def _eval_with_pooling(self, x, mask=None, slicing=None, encoding_window=None):
out = self.net(x.to(self.device, non_blocking=True), mask)
if encoding_window == 'full_series':
if slicing is not None:
out = out[:, slicing]
out = F.max_pool1d(
out.transpose(1, 2),
kernel_size = out.size(1),
).transpose(1, 2)
elif isinstance(encoding_window, int):
out = F.max_pool1d(
out.transpose(1, 2),
kernel_size = encoding_window,
stride = 1,
padding = encoding_window // 2
).transpose(1, 2)
if encoding_window % 2 == 0:
out = out[:, :-1]
if slicing is not None:
out = out[:, slicing]
elif encoding_window == 'multiscale':
p = 0
reprs = []
while (1 << p) + 1 < out.size(1):
t_out = F.max_pool1d(
out.transpose(1, 2),
kernel_size = (1 << (p + 1)) + 1,
stride = 1,
padding = 1 << p
).transpose(1, 2)
if slicing is not None:
t_out = t_out[:, slicing]
reprs.append(t_out)
p += 1
out = torch.cat(reprs, dim=-1)
else:
if slicing is not None:
out = out[:, slicing]
return out.cpu()
def encode(self, data, mask=None, encoding_window=None, causal=False, sliding_length=None, sliding_padding=0, batch_size=None):
''' Compute representations using the model.
Args:
data (numpy.ndarray): This should have a shape of (n_instance, n_timestamps, n_features). All missing data should be set to NaN.
mask (str): The mask used by encoder can be specified with this parameter. This can be set to 'binomial', 'continuous', 'all_true', 'all_false' or 'mask_last'.
encoding_window (Union[str, int]): When this param is specified, the computed representation would the max pooling over this window. This can be set to 'full_series', 'multiscale' or an integer specifying the pooling kernel size.
causal (bool): When this param is set to True, the future informations would not be encoded into representation of each timestamp.
sliding_length (Union[int, NoneType]): The length of sliding window. When this param is specified, a sliding inference would be applied on the time series.
sliding_padding (int): This param specifies the contextual data length used for inference every sliding windows.
batch_size (Union[int, NoneType]): The batch size used for inference. If not specified, this would be the same batch size as training.
Returns:
repr: The representations for data.
'''
assert self.net is not None, 'please train or load a net first'
assert data.ndim == 3
if batch_size is None:
batch_size = self.batch_size
n_samples, ts_l, _ = data.shape
org_training = self.net.training
self.net.eval()
dataset = TensorDataset(torch.from_numpy(data).to(torch.float))
loader = DataLoader(dataset, batch_size=batch_size)
with torch.no_grad():
output = []
for batch in loader:
x = batch[0]
if sliding_length is not None:
reprs = []
if n_samples < batch_size:
calc_buffer = []
calc_buffer_l = 0
for i in range(0, ts_l, sliding_length):
l = i - sliding_padding
r = i + sliding_length + (sliding_padding if not causal else 0)
x_sliding = torch_pad_nan(
x[:, max(l, 0) : min(r, ts_l)],
left=-l if l<0 else 0,
right=r-ts_l if r>ts_l else 0,
dim=1
)
if n_samples < batch_size:
if calc_buffer_l + n_samples > batch_size:
out = self._eval_with_pooling(
torch.cat(calc_buffer, dim=0),
mask,
slicing=slice(sliding_padding, sliding_padding+sliding_length),
encoding_window=encoding_window
)
reprs += torch.split(out, n_samples)
calc_buffer = []
calc_buffer_l = 0
calc_buffer.append(x_sliding)
calc_buffer_l += n_samples
else:
out = self._eval_with_pooling(
x_sliding,
mask,
slicing=slice(sliding_padding, sliding_padding+sliding_length),
encoding_window=encoding_window
)
reprs.append(out)
if n_samples < batch_size:
if calc_buffer_l > 0:
out = self._eval_with_pooling(
torch.cat(calc_buffer, dim=0),
mask,
slicing=slice(sliding_padding, sliding_padding+sliding_length),
encoding_window=encoding_window
)
reprs += torch.split(out, n_samples)
calc_buffer = []
calc_buffer_l = 0
out = torch.cat(reprs, dim=1)
if encoding_window == 'full_series':
out = F.max_pool1d(
out.transpose(1, 2).contiguous(),
kernel_size = out.size(1),
).squeeze(1)
else:
out = self._eval_with_pooling(x, mask, encoding_window=encoding_window)
if encoding_window == 'full_series':
out = out.squeeze(1)
output.append(out)
output = torch.cat(output, dim=0)
self.net.train(org_training)
return output.numpy()
def save(self, fn):
''' Save the model to a file.
Args:
fn (str): filename.
'''
torch.save(self.net.state_dict(), fn)
def load(self, fn):
''' Load the model from a file.
Args:
fn (str): filename.
'''
state_dict = torch.load(fn, map_location=self.device)
self.net.load_state_dict(state_dict)
utils
import os
import numpy as np
import pickle
import torch
import random
from datetime import datetime
def pkl_save(name, var):
with open(name, 'wb') as f:
pickle.dump(var, f)
def pkl_load(name):
with open(name, 'rb') as f:
return pickle.load(f)
def torch_pad_nan(arr, left=0, right=0, dim=0):
if left > 0:
padshape = list(arr.shape)
padshape[dim] = left
arr = torch.cat((torch.full(padshape, np.nan), arr), dim=dim)
if right > 0:
padshape = list(arr.shape)
padshape[dim] = right
arr = torch.cat((arr, torch.full(padshape, np.nan)), dim=dim)
return arr
def pad_nan_to_target(array, target_length, axis=0, both_side=False):
assert array.dtype in [np.float16, np.float32, np.float64]
pad_size = target_length - array.shape[axis]
if pad_size <= 0:
return array
npad = [(0, 0)] * array.ndim
if both_side:
npad[axis] = (pad_size // 2, pad_size - pad_size//2)
else:
npad[axis] = (0, pad_size)
return np.pad(array, pad_width=npad, mode='constant', constant_values=np.nan)
def split_with_nan(x, sections, axis=0):
assert x.dtype in [np.float16, np.float32, np.float64]
arrs = np.array_split(x, sections, axis=axis)
target_length = arrs[0].shape[axis]
for i in range(len(arrs)):
arrs[i] = pad_nan_to_target(arrs[i], target_length, axis=axis)
return arrs
def take_per_row(A, indx, num_elem):
all_indx = indx[:,None] + np.arange(num_elem)
return A[torch.arange(all_indx.shape[0])[:,None], all_indx]
def centerize_vary_length_series(x):
prefix_zeros = np.argmax(~np.isnan(x).all(axis=-1), axis=1)
suffix_zeros = np.argmax(~np.isnan(x[:, ::-1]).all(axis=-1), axis=1)
offset = (prefix_zeros + suffix_zeros) // 2 - prefix_zeros
rows, column_indices = np.ogrid[:x.shape[0], :x.shape[1]]
offset[offset < 0] += x.shape[1]
column_indices = column_indices - offset[:, np.newaxis]
return x[rows, column_indices]
def data_dropout(arr, p):
B, T = arr.shape[0], arr.shape[1]
mask = np.full(B*T, False, dtype=np.bool)
ele_sel = np.random.choice(
B*T,
size=int(B*T*p),
replace=False
)
mask[ele_sel] = True
res = arr.copy()
res[mask.reshape(B, T)] = np.nan
return res
def name_with_datetime(prefix='default'):
now = datetime.now()
return prefix + '_' + now.strftime("%Y%m%d_%H%M%S")
def init_dl_program(
device_name,
seed=None,
use_cudnn=True,
deterministic=False,
benchmark=False,
use_tf32=False,
max_threads=None
):
import torch
if max_threads is not None:
torch.set_num_threads(max_threads) # intraop
if torch.get_num_interop_threads() != max_threads:
torch.set_num_interop_threads(max_threads) # interop
try:
import mkl
except:
pass
else:
mkl.set_num_threads(max_threads)
if seed is not None:
random.seed(seed)
seed += 1
np.random.seed(seed)
seed += 1
torch.manual_seed(seed)
if isinstance(device_name, (str, int)):
device_name = [device_name]
devices = []
for t in reversed(device_name):
t_device = torch.device(t)
devices.append(t_device)
if t_device.type == 'cuda':
assert torch.cuda.is_available()
torch.cuda.set_device(t_device)
if seed is not None:
seed += 1
torch.cuda.manual_seed(seed)
devices.reverse()
torch.backends.cudnn.enabled = use_cudnn
torch.backends.cudnn.deterministic = deterministic
torch.backends.cudnn.benchmark = benchmark
if hasattr(torch.backends.cudnn, 'allow_tf32'):
torch.backends.cudnn.allow_tf32 = use_tf32
torch.backends.cuda.matmul.allow_tf32 = use_tf32
return devices if len(devices) > 1 else devices[0]
Appendix
너무 많아서 출처를 알 수가 없음
-
죄송합니다.. 궁금하신 점은 언제든지 댓글 등으로 문의주세요
-
감사합니다. 좋은 하루 보내세요!
박시연 드림
