PAPER
Abstract
- 다변량 시계열 예측 및 self-supervised representation learning을 위한 효율적인 transformer 기반 모델 설계를 제안한다.
- 시계열을 부분 subseries-level patches으로 분할하여 transformer의 입력 토큰으로 사용
- patch 설계의 3가지(three-fold) 이점
- 임베딩에서 지역적 의미 정보를 보존
- 동일한 과거 윈도우 길이에서 주의 맵의 계산 및 메모리 사용량을 제곱으로 줄임
- 모델이 더 긴 과거 데이터를 참조할 수 있음
- patch 설계의 3가지(three-fold) 이점
- 채널 독립성이 각 채널은 단일 변수 시계열로 구성되며, 모든 시리즈에 대해 동일한 임베딩과 transformer 가중치를 공유
- 시계열을 부분 subseries-level patches으로 분할하여 transformer의 입력 토큰으로 사용
- 우리는 채널 독립 패치 시계열 transformer(Patch Time Series Transformer)는 기존 SOTA transformer 기반 모델에 비해 장기 예측 정확도를 크게 향상시킨다. 또한 이 모델을 자기 지도 학습 태스크에 적용하여 대규모 데이터셋에서 감독 학습을 능가하는 뛰어난 파인 튜닝 성능을 얻었다.
- 하나의 데이터셋에서 마스킹된 사전 학습 표현을 다른 데이터셋으로 전이하는 경우에도 SOTA 수준의 예측 정확도를 제공한다.
Introduce
- transformer 기반의 모델들은 자연어처리분야와 컴퓨터 비전 분야에서 두루 활용되는 방안이자만, 시계열 데이터 예측에서만큼은 MLP 기반 모델(N-BEATS, N-HiTS)이 더 뛰어난 성능을 보여주었다. 이 논문은 트랜스포머 기반의 모델을 통해 시계열 데이터 예측을 수행하고자 한다.
- Patching
- 시계열 예측은 다른 time steps 사이의 관계를 이해하고자 한다.
- 하지만 단일 시점은 문장 내 단어처럼 명확한 의미를 가지지 않음
- 그렇기에 로컬 의미 정보를 추출하여 데이터 간의 연결성을 분석하는 것이 중요하다.
- 기존 연구들은 주로 점 단위(point-wise) 입력 토큰이나 수작업으로 설계된 정보를 사용했지만, 본 연구는 시계열을 세분화하여 subseries-level patches로 나눠 더 포괄적인 의미 정보를 포착
- Channel Independence
- 다변량 시계열은 다중 채널 신호로, 각 transformer 입력 토큰은 단일 채널 또는 다중 채널 데이터를 나타낼 수 있다.
- 기존 모델들은 다중 채널 데이터를 혼합하여 처리하는 경우가 많았지만, 본 연구는 각 입력 토큰이 단일 채널 데이터만 포함하는 독립적 접근법을 사용한다.
- 다중 채널 데이터를 혼합하여 처리하는 방식(channel-mixing): 입력 토큰이 모든 시계열 특성의 벡터를 받아 임베딩 공간에 투영(projection)하여 정보를 혼합하는 경우를 의미한다.
- 반대로, channel-independence: 각 입력 토큰은 단일 채널에 대한 정보만을 함유한다.
- 이는 기존 CNN 및 선형 모델에서 효과적임이 증명되었으며, transformer 모델에 처음으로 적용됨
- Traffic, Electricity, Weather dataset을 활용한 사례 연구
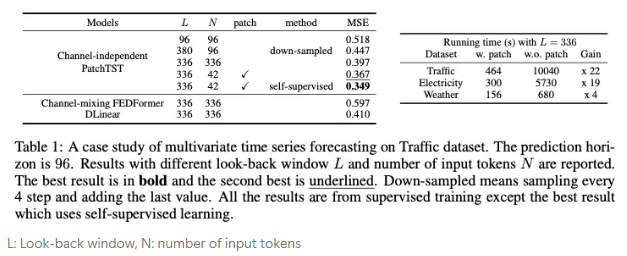
- 시간 및 공간 복잡성 감소: 기존 transformer는 입력 토큰의 개수를 N이라고 할 때, 시간 및 공간 복잡성이 O(N^2)에 비례한다.
- 하지만 patching을 적용하면 N을 stride 크기로 나누어 로 줄일 수 있다.
- 이는 복잡성을 제곱 단위로 감소시킨다.
- 더 긴 과거 데이터의 학습 능력: Table 1에서 L을 96 → 336으로 증가하였을 때, MSE는 0.518→0.397로 감소했음을 보여준다. 하지만 단순히 L을 확장시키면, 메모리와 계산 비용 요구가 더 많이 됨
- 이를 해결 하기 위한 기존의 연구
-
downsampling: 0.447(MSE)
→ 입력 토큰 수가 줄어들었지만, MSE는 감소하였다.
: 이는 더 긴 과거 데이터가 중요한 정보를 더 많이 포함하고 있음을 나타낸다. (입력 토큰의 개수보다)
-
- 값을 버리지 않고, 더 긴 과거 데이터를 유지하는 방법으로 patching이 적합하다.
- L이 336, N이 42가 되도록 patching을 적용하였을 때 MSE가 더욱 내려감(0.367)
- 이를 해결 하기 위한 기존의 연구
- 표현 학습 능력: 강력한 자기 지도 학습 기술의 출현으로 인해, 데이터의 추상적 표현을 캡처하려면 다층 비선형 모델이 필요하다.
- 그 모델이 transformer 기반 모델이다.
- self-supervised 방법론까지 적용하니 더욱 내려갔다.(0.349)
Related Work
- Transformer 기반 모델에서의 patch
- 모든 응용 분야 중에서, 패치는 지역적 의미 정보가 중요한 경우 필수적인 요소가 됨
- In NLP, BERT: 문자 기반 토큰화 대신 하위 단어 기반 토큰화
- In CV, ViT가 이미지를 16x16 패치로 분할하여 Transformer 모델에 입력
- 이후 BEiT와 Masked AE에서도 패치를 입력으로 사용함
- In speech researcher, 원시 오디오 입력에서 하위 시퀀스 수준의 정보를 추출하기 위해 컨볼루션 사용
- 모든 응용 분야 중에서, 패치는 지역적 의미 정보가 중요한 경우 필수적인 요소가 됨
- Transformer 기반 장기 시계열 예측
- 최근 몇 년 동안 transformer 모델을 장기 시계열 예측에 적용하려는 많은 연구가 있었음
- LogTrans, 로컬 정보를 캡처하고, 공간 복잡성을 줄이기 위해 컨볼루션 기반의 self-attention layers과 Log Sparse 설계를 사용
- 키와 쿼리 간 dot product를 회피했지만, 값은 여전히 단일 시간 단계에 기반
- Informer, 중요한 key를 효율적으로 추출하기 위해 ProbSparse self-attention과 distilling 기법 제안
- Autoformer, 전통적인 시계열 분석 방법에서 분해 및 auto-correlation idea 차용
- 수작업으로 설계되었으며, 패치 내의 모든 의미 정보를 포함하진 못함
- FEDformer은 선형 복잡도를 구하기 위한 푸리에 기반 설계를 사용
- Pyraformer, 피라미드 주의 모듈과 스케일 간 혹은 스케일 내 연결을 적용하여 선형 복잡성을 달성
- Tiformer, patch attention을 제안했지만, 이는 패치 내 가상 스탬프를 쿼리로 사용하여 복잡성을 줄이는 목적이었으며, 패치를 입력 단위로 처리하거나 패치 뒤의 의미적 중요성을 드러내지 못하였다.
- LogTrans, 로컬 정보를 캡처하고, 공간 복잡성을 줄이기 위해 컨볼루션 기반의 self-attention layers과 Log Sparse 설계를 사용
- 대부분의 모델이 point-wise attention을 사용하여 패치의 중요성 간과
- 최근 몇 년 동안 transformer 모델을 장기 시계열 예측에 적용하려는 많은 연구가 있었음
- 시계열 표현 학습
- supervised learning 외에도 자기 지도 학습은 다운스트림 작업에 유용한 표현을 학습할 수 있는 잠재력을 보여주었기 때문에 중요한 연구 주제이다.
- transformer는 범용 표현 학습을 위한 이상적인 후보이다.
- 하지만, transformer를 사용하지 않는 모델들이 시계열 표현 학습을 위해 많이 제안되었고, 시도 된 모델에서 조차 잠재력은 아직 충분히 실현되지 않았다.
Proposed Method
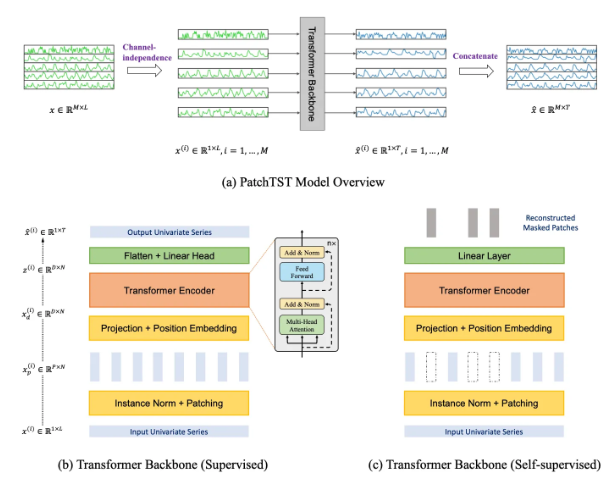
Model Structure
정리
- 길이가 L인 다변량 시계열 샘플이 주어졌을 때, 각 시간 단계 t에서의 벡터 는 차원 M을 가지며, T개의 미래 값를 예측하고자 한다.
- 제안된 모델의 구조는 다음과 같으며, 기본적으로 transformer의 encoder를 핵심 아키텍처로 사용한다.
-
Forward Process:
-
i번째 단일 변수 시계열의 길이:
-
입력은 M개의 단일 변수 시계열 로 분리되며, 각각의 시계열이 transformer backbone(Encoder)으로 독립적으로 전달됨
-
transformer backbone은 각 채널에 대해 형태로 예측 결과를 생성한다.
-
-
Patching:
- x는 겹치는 패치 혹은 겹치지 않는 패치로 분할된다. (overlapped or non-overlapped)
- patch 길이를 P, stride(연속 패치 간 비중복 영역)를 S라고 하면, 패칭 과정은 형태의 패치 시퀀스를 생성
- 여기서 패치 개수 N은
- 원래 시퀀스 끝부분에 마지막 값 을 패딩하여 S만큼 반복한 후 패칭이 진행됨
- 패칭을 적용하면 입력 토큰의 개수가 L에서 약 L/S로 줄어들개 된다.
- 이는 attention map의 메모리 사용량과 계산 복잡도를 S배만큼 줄이는 효과가 있다.
- 따라서, 패칭 설계로 긴 과거 시퀀스를 학습할 수 있으며, 예측 성능을 크게 향상한다.
-
Transformer Encoder:
-
관측된 신호를 latent representation으로 mapping
-
패치는 linear projection과 positional encoding을 통해 잠재 공간으로 mapping
-
이 과정을 통해 이 생성되며, 은 인코더로 전달
-
Multi-Head Attention:
-
transformer의 각 head는 다음과 같이 Q, K, V 반환
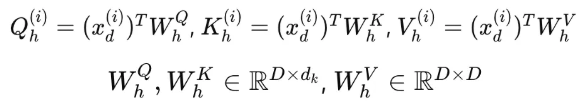
-
BatchNorm, feed-forword network, residual connections가 포함된다
-
이 작업을 통해 잠재 표현 z가 생성이 되며, 마지막으로 flatten, linear를 통해 를 얻을 수 있다.
-
-
-
loss function:
- MSE
- 각 채널에 대한 손실을 계산하고, M개의 시계열에 대해 평균하여 전체 손실을 얻음
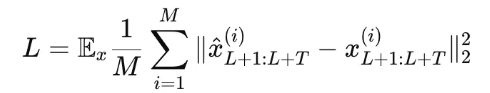
-
Instance Normalization:
- 인스턴스 정규화는 학습 및 테스트 데이터 간 분포 변화 문제를 완화하기 위해 사용된다.
- 각 시계열은 패칭 이전 평균이 0이고, 표준편차가 1이 되도록 정규화한다.
- 이후 예측 결과에는 값을 되돌림
Representation Learning
정리
- 자기 지도 표현 학습은 레이블이 없는 데이터에서 고수준의 추상적 표현을 추출하기 위한 인기있는 접근 방식
- 이 섹션에서는 제안 모델을 적용하여 다변량 시계열의 유용한 표현을 얻는 방법을 설명
- 예측 task에 효과적으로 전이될 수 있음을 보여줌
- Masked AE:
- NLP, CV에선 사용 많음
- 입력 시퀀스의 일부를 랜덤하게 제거한 후, 모델이 제거된 콘텐츠를 복구하도록 학습
- 마스킹된 표현 학습의 문제점 또한 존재
- 단일 시점 수준에서의 마스킹 적용
- 기존 연구에서는 각 시계열과 시간 단계에 무작위로 마스킹을 적용했으나, 이는 다음과 같은 문제를 야기할 수 있음
- 현재 시간 단계의 마스킹된 값을 이전 또는 이후 값으로 쉽게 보간할 수 있어, 시계열 전체를 고수준으로 이해할 필요성이 줄어든다.
- 이를 해결하기 위해 복잡한 무작위화 전략(다양한 크기의 그룹 마스킹 등)이 제안되었지만, 이는 구현이 복잡함
- 기존 연구에서는 각 시계열과 시간 단계에 무작위로 마스킹을 적용했으나, 이는 다음과 같은 문제를 야기할 수 있음
- 출력 레이어 설계 문재
- 예측 태스크를 위한 출력 레이어 설계에 어려움이 있을 수 있다.
- 각 시점의 잠재 벡터를 MxT 크기의 예측 벡터로 매핑하려면, 크기가 (LxD)x(MxT)인 매개변수 행렬 W가 필요하다
- 이 매개변수 행렬은 L, D, M, T 중 하나라도 큰 경우, 크기가 지나치게 커질 수 있으며, 특히 학습 샘플 수가 적을 때 과적합을 초래할 수 있다.
- 예측 태스크를 위한 출력 레이어 설계에 어려움이 있을 수 있다.
- 단일 시점 수준에서의 마스킹 적용
- PatchTST의 해결 방법
- Tranformer encoder structure 재사용(2번 문제 해결 방안)
- supervised learning 설정에서 사용된 동일한 인코더를 사용한다.
- 단, 예측 헤드는 제거되며, 대신 DxP 크기의 선형 레이어만 추가된다.
- 패치 기반 마스킹(1번 문제 해결 방안)
- 겹치는 패치를 사용하는 supervised learning model과는 달리, 표현학습에서는 non-overlapped patch를 사용하여 마스킹된 패치와 관측된 패치가 정보적으로 독립되도록 보장한다.
- 무작위로 선택된 패치 인덱스를 따라 해당 패치를 0으로 설정하여 마스킹을 수행
- MSE를 통해 복원
- Tranformer encoder structure 재사용(2번 문제 해결 방안)
- 제안 모델은 각 시계열에 대해 자체적인 잠재 표현을 생성하며, 이는 공유 가중치 메커니즘을 통해 학습된다.
- 이 설계는 사전 학습 데이터와 다운 스트림 데이터가 서로 다른 수의 시계열을 포함하더라도 모델이 작동할 수 있도록 한다. 이는 다른 모델과 다른 차별점이다.
Experiments
4.1 Long-Term Times Series Forecasting
- Results:
- SOTA
- Transformer 기반 모델과 비교할 때, PatchTST/64는 MSE에서 약 21.0%, MAE에서 약 16.7% 개선을 보여줌
- DLinear와 비교했을 때, 특히 대구모 데이터셋에서 전반적으로 더 나은 성능을 보여줌
4.2 Representation Learning
- self-supervised Pre-Training
- non-overlapped patch를 사용하여 입력 시퀀스 길이를 512, 패치 크기 12로 설정하여 총 42개의 패치를 생성
- 전체 패치 중 40%를 무작위로 선택하여 0으로 마스킹, MSE를 통해 복원
- 두가지 방식으로 평가
-
Linear Probing: 네트워크의 나머지 부분을 고정하고, 헤드만 학습
-
End-to-End Fine-Tuning: 초기 10 epoch 동안 선형 프로빙을 수행한 뒤, 전체 네트워크를 추가로 20 epoch 동안 학습
→ 대규모 데이터 셋에서 사전 학습이 지도 학습보다 명확한 개선 효과를 보였으며, 단순히 모델 헤드만 학습(linear probing)했을 때도 성능이 비슷하거나 더 좋았음. end-to-end fine-tuning이 가장 좋은 성능을 보였으며, 모든 데이터셋에서 transformer 기반 모델을 크게 능가
-
- 사전 학습된 모델을 다른 데이터셋으로 전이하여 테스트한 결과, 같은 데이터셋에서 사전 학습 및 미세 조정을 수행한 경우보다는 약간 낮은 성능을 보임
- 하지만, 여전히 다른 모델들보다 우수한 예측 성능을 보였으며, 학습 시간도 크게 단축됨
4.3 Ablation Study
- Patching and Channel-Independence
- 이 때가 제일 성능이 좋음
- 패칭은 입력 길이를 줄이고, 학습 속도와 효율성을 크게 향상
- 채널 독립성은 기술적 이점이 직관적이지 않을 수 있지만, 상세한 분석에서 예측 성능 향상에 중요한 역할을 하는 것을 보여줌
- Varying Look-Back Window
- 과거 윈도우 길이 L 증가에 따라 일관되게 성능이 향상됨을 보여줌
- Transformer 기반 기존 모델들은 일관된 성능 향상 X(충분히 윈도우 크기를 활용하고 있다고 입증하지 못함)
Conclusion and Future Work
- patching과 channel-independence structure라는 구성 요소를 포함함
- 지역적 의미 정보를 포착하고 더 긴 돠거 데이터를 활용할 수 있는 장점을 제공
- 지도 학습을 비지도학습이 능가할 수 있다는 것을 보여줬을 뿐만 아니라, 전이 학습에서도 유망하다는 것을 입증
- 주요 성과
- Transformer 기반 예측 모델로 활용될 잠재력 입증
- 패칭이라는 단순하고 효과적인 연산 기법
- 채널 독립성은 다중 채널 간 상호 연관성을 통합할 수 있는 가능성을 보여주었으며, 이는 미래 연구에서 교차 채널 의존성(cross-channel depencencies)을 적절히 모델링하는 중요한 단계가 될 것이라 예측
Appendix
GPT..?
- 이것도 출처가 불분명합니다..
- 다음에 기회가 된다면, PPT 자료도 올려보겠습니다. (지금은 노션만 동기화 중...)
- 감사합니다. 좋은 하루 보내세요!
박시연 드림
