Paper
Abstract
- 최근 시계열 사전 학습은 라벨링 비용을 절감하고 다운스트림 작업에서 성능을 향상시킬 수 있는 잠재력으로 인해 큰 주목을 받고 있음 명시
- 시계열 사전 학습은 주로 비전이나 자연어처리에서 널리 사용되는 사전학습기법을 기반으로 사용
- 마스킹 모델링
- TST
- TI-MAE
- PatchTST
- SimMTM
- 대조 학습
- TS2Vec
- CoST
- LAST
- TF-C
- COMET
- 마스킹 모델링
- 하지만 시계열 데이터를 무작위로 마스킹하거나 전체 시리즈 수준에서 유사도를 계산하는 방식은 시계열 데이터에서 내재하는 중요한 시간적 상관관계를 왜곡하거나 무시할 수 있다.
- 그렇기에 Siamese network를 기반으로 한 자기지도학습 사전 학습 프레임워크인 TimeSiam을 제안한다.
- TimeSiam은 무작위로 샘플링된 past subseries, current subseries 간의 내재적 시간적 상관관계를 포착하도록 Siamese Enc를 사전 학습하는 방법이다.
- 간단한 데이터 증강 기법을 활용하여 다영한 증강된 하위 시퀀스를 생성하고, 과거 시퀀스로부터 현재 시퀀스를 재구성하는 방식으로 시간 종속 표현 학습을 수행한다.
1. Introduction
배경지식
- 대규모로 수집된 시계열 데이터를 활용하려면, 라벨이 없는 데이터로부터 유용한 정보를 추출하여 다양한 다운스트림 작업의 성능을 향상시킬 수 있는 시계열 자기지도학습 기법이 필수적이다.
- 본 논문에서는 이러한 시계열 사전 학습의 가능성에 주목하고, 새로운 실용적 자기지도학습 사전 학습 방법을 제안
- 기존의 시계열 사전 학습 방법의 문제점
- 마스킹 모델링
- 모델이 가려진 부분을 복원하도록 최적화함으로써 표현 학습을 가능하게 한다.
- 하지만, 시계열 데이터를 무작위로 마스킹하면 핵심적인 시간적 상관관계를 심각하게 왜곡 시켜, 재구성 작업 자체가 너무 어려워지는 문제가 발생한다고 밝힘
- 대조 학습
- 개별 샘플(instance-level)에 대한 표현 하습에 강점을 가진다.
- 이 방법은 pos sample과 neg sample을 구별하도록 최적화하는 방식
- 그러나 이 방식은 유용한 불변성을 학습하기 위해 신중한 데이터 증강이 필요하다는 점에서 큰 단점
- 또한 대조 학습의 개별 샘플 기반 설계는 세밀한 시간적 병화를 포착하는 데 한계를 가지며, 이는 다양한 다운스트림 작업에서 실용성을 제한할 수 있다.
- 마스킹 모델링
- 시계열 데이터의 본질적인 특성과 최적의 학습 방법
- 시계열 데이터는 이미지나 텍스트의 중요한 차이점이 있다.
- 각 타임 스텝에서는 유한한 개수의 스칼라 값만 포함될 수 있기 때문에, 시계열 데이터에서 가장 중요한 정보는 시간적 상관관계에 있다. → 즉, t라는 시점에서 데이터는 한정적이고, 유한하기에 소화할 수 있는 양이 정해져 있고, 이러한 것들을 정하는 것이 타임 스텝?
- 따라서, 시계열 사전 학습에서 가장 중요한 점은 인코더를 최적화하여 시간적 상관관계를 정확하게 포착하도록 하는 것이다.
Timesiam의 장점:
- 기존 방법들과 달리, Timesiam은 시계열의 “시간적 거리”를 활용하는 방식
- 대부분의 기존 방법들은 인접산 시퀀스를 활용하지만, Timesiam은 멀리 떨어진 두 시퀀스 사이의 관계까지 모델링할 수 있다.
- 이는 시계열 데이터를 보다 깊이 이해할 수 있도록 도움
- 기존의 사전 학습 방법 대비 단순하면서 일관된 성능 향상을 보인다.
- 다양한 다운스트림 작업(시계열 예측 및 분류 등)에서 최신 시계열 사전 학습 기법 대비 일관되게 우수한 성능을 보임
- 특히, 동일 도메인(in-domain) 뿐만 아니라, 서로 다른 도메인(cross-domain)에서도 강력한 성능을 입증하였다.
Contributions:
- 시간적 상관관계를 학습할 수 있도록 Siamese 네트워크를 활용한 간단하지만 효과적인 사전 학습 프레임워크 제안
- 동일한 시계열 내에서 서로 다른 타임스탬프에서 하위 시퀀스 쌍을 샘플링하는 방식을 사용한다. 이를 “Siamese Subseries”라고 한다.
- 이렇게 샘플링된 하위 시퀀스들을 Siamese 네트워크를 활용한 인코더로 학습된다. 이를 통해 시간적으로 떨어져 있는 두 하위 시퀀스 사이의 상관관계를 포착할 수 있다.
- 간단한 데이터 증강 기법(마스킹 등)을 추가하면, Siamese Subseries의 다양성과 구별성이 더욱 향상된다.
- 이를 통해, 자연스럽게 과거 → 현재 방향으로 복원하는 학습을 수행하게 되며, 이 과정에서 모델은 시간적으로 관련된 정보를 학습하고, 과거 시리즈와 현재 시리즈 간의 상관관계를 포착할 수 있다.
- Siamese 인코더를 활용하여 현재 마스킹된 시퀀스를 과거 시퀀스로부터 복원하는 구조를 설계하였으며, 계통 임베딩(Lineage Embeddings)을 통해 다양한 시간적 표현 학습이 가능하도록 하였다.
- 이를 통해 인코더는 다양한 시간 종속(time-dependent) 표현을 학습할 수 있는 능력을 갖게 된다.
- 마지막으로, cross-attention과 self-attention 메커니즘을 결합한 디코더를 적용하여, masking Siamese Subseries를 보다 정확하게 reconstruction할 수 있도록 한다.
- TimeSiam은 13개 벤치마크 데이터셋에서 기존 사전 학습 방법 대비 일관되게 뛰어난 성능을 달성하였으며, 시계열 분석 분야에서 강력한 도구임을 입증함
2. Related Work
시계열 데이터의 자기지도 학습 사전 기법 및 Siamese 네트워크에 대한 연구들을 정리
2.1 시계열 자기지도 학습
- SSL은 라벨이 없는 대규모 데이터로부터 일반적인 표현을 학습하는 방법으로, NLP, CV에서 매우 성공적으로 적용되었다.
- 마스킹 모델링과 대조 학습이 주요하게 연구되고 있다.
- 마스킹 모델
- TST (Zerveas et al., 2021): 임의로 시계열 데이터의 일부 세그먼트(segment)와 포인트(point)를 마스킹한 후 이를 복원하는 방식 으로 모델을 사전 학습
- Ti-MAE (Li et al., 2023b): Transformer 기반의 시계열 마스킹 오토인코더(autoencoder) 구조 를 도입하여 사전 학습을 수행
- PatchTST (Nie et al., 2023): 시계열을 패치(patch) 단위로 분할한 후, 비연속적인 패치 단위 마스킹을 적용하는 방법 을 사용
- HiMTM (Zhao et al., 2024): 시계열의 다중 스케일(multi-scale) 특성을 반영한 계층적(hierarchical) 마스킹 모델을 제안
- SimMTM (Dong et al., 2023): 마스킹된 다중 시계열을 가중합(weighted aggregation)하여 원래의 시계열을 복원하는 방법 으로, 개별 포인트(point-wise) 및 시리즈(series-wise) 레벨의 학습이 가능
- 대조 학습
- CPC (Oord et al., 2018): 대조 예측 코딩(Contrastive Predictive Coding, CPC) 방법을 통해 미래 시퀀스를 예측하는 방식으로 학습
- TNC (Tonekaboni et al., 2021): 시간적으로 가까운(neighbor) 샘플과 멀리 떨어진 샘플을 구별하는 방식 으로 시계열 표현을 학습
- TS2Vec (Yue et al., 2022): 시계열을 패치 단위로 나눈 후, 각 패치 간의 대조 학습을 수행하여 표현을 학습
- Mixing-up (Wickstrom et al., 2022): 두 개의 서로 다른 시계열 데이터를 혼합(mixing)하여 새로운 샘플을 생성하고, 이를 대조 학습의 양의 샘플로 활용
- LaST (Wang et al., 2022): 시계열 데이터를 계절적(seasonal) 요소와 추세적(trend) 요소로 분리한 후, 이들을 개별적으로 대조 학습하는 방식
- CoST (Woo et al., 2022): 시간 도메인과 주파수 도메인에서 각각 대조 학습을 수행하여 더 나은 시계열 표현을 학습
- TF-C (Zhang et al., 2022): 시계열 데이터를 시간(time) 및 주파수(frequency) 기반으로 변환한 후, 두 표현을 일관되게 유지하는 방식으로 학습
- 마스킹 모델
2.2 Siamese Network
- 두 개의 입력 샘플을 비교하고, 이들 간의 관계를 학습하도록 설계된 신경망 구조(Bromley et al., 1993)
- 이러한 네트워크 구조는 대조 학습과 결합하여 두 샘플 간의 관계를 학습하는 데 널리 사용된다.
- 기존에는 주로 이미지 비교, 얼굴 인식, 유사한 문서 검색 등에서 사용되었으나, 최근 시계열 학습에도 활용되기 시작함
- 기존 연구들의 한계점
- 기존 시계열 연구에서는 Siamese Network가 주로 대조학습과 결합되어 활용되었지만, 본질적인 시계열 특성인 “시간적 상관관계”를 충분히 반영하지 못함
- Timesiam은 공유 가중치를 가지는 Siamese AutoEncoder를 활용하여 과거-현재 하위 시퀀스 간의 상관관계를 효과적으로 학습할 수 있도록 함
3. TimeSiam
Siamese Network 기반의 새로운 자기지도학습 시계열 사전 학습 프레임워크
- 이 섹션에선 TimeSiam이 어떻게 학습을 수행하는지, 기존 방법과 어떤 차별점이 있는지, 그리고 세부적인 구현 방식을 설명한다.
3.1 Pretraining
사전학습은 크게 두 개의 주요 모듈로 구성된다: Siamese Subseries Sampling, Siamese Modeling
(1) Siamese Subseries Modeling
- 기존의 시계열 사전 학습 기법들은 단일 시계열 자체를 학습하는 것에 집중했다.
- 하지만 이런 방식은 서로 다른 타임 스텝 간의 관계(e.g., 시간적 상관관계)를 제대로 반영하지 못하는 한계가 있다.
- 그렇기에 이 한계를 극복하기 위하여 하위 시퀀스 쌍을 샘플링하는 방식을 제안한다.
- TimeSiam의 샘플링 방식:
-
하나의 시계열에서 과거(past)와 현재(current) 하위 시퀀스를 무작위로 샘플링 한다.
-
즉, 하나의 시계열 데이터에서 특정 구간을 과거 시퀀스 (xpast)로, 이후 구간을 현재 시퀀스 (xcurr)로 설정하여 Siamese subseries 를 만든다.
-
각 하위 시퀀스는 길이 T 를 가지며, C 개의 변수(variables, multivariate data) 를 포함한다.
→ 이러한 샘플링 방식은 시계열 데이터의 시간적 관계를 학습할 수 있도록 한다. 즉, 모델이 멀리 떨어진 시점의 데이터 간 관계도 학습할 수 있도록 설계됨
-
(2) Siamese Modeling
-
Siamese Network를 활용하여 과거 하위 시퀀스를 기반으로 현재 하위 시퀀스를 복원하는 방식으로 학습을 진행한다.
-
Lineage Embedding
- 일반적인 시계열 학습에서는 시간적으로 가까운 데이터만을 고려하는 경우가 많다.
- 하지만 TimeSiam은 멀리 떨어진 데이터 간의 관계도 학습할 수 있도록 “계통 임베딩”을 도입했다.
- 각 시퀀스의 시간적 거리를 나타내는 학습 가능한 임베딩을 추가하여, 서로 다른 시간 간격을 구별할 수 있도록 한다.
- 계통 임베딩의 동작 방식:
-
샘플링된 과거 시퀀스 xpast와 현재 시퀀스 xcurr에 계통 임베딩을 추가
-
계통 임베딩은 시간적 거리 d에 따라 변하는 가변적(dynamic) 임베딩을 부여
-
Siamese 네트워크는 이러한 정보를 활용하여 시계열의 시간적 관계를 학습
→ 이를 통해 서로 다른 시간 간격을 가진 하위 시퀀스를 효과적으로 구별하고, 다양한 시간적 종속성을 학습할 수 있다.
-
-
Encoding Process
- 샘플링된 데이터는 Siamese enc를 통해 처리된다.
- 다양한 인코더를 적용할 수 있으며, 대표적으로 PatchTST 및 iTransformer를 사용한다.
- 각 시퀀스를 개별적으로 임베딩하여 특성을 추출
- PatchTST같은 경우, 시계열 데이터를 패치 단위로 나누고, 각 패치를 독립적인 토큰으로 변환
- 계통 임베딩과 결합하여 네트워크에 입력
- Siamese Enc를 통해 과거 시퀀스와 현재 시퀀스의 표현 학습
- 각 시퀀스를 개별적으로 임베딩하여 특성을 추출
-
Reconstruction Process
-
현재 시퀀스를 복원하는 task를 기반으로 학습을 진행한다.
-
구체적인 과정:
- 과거 시퀀스(past subseries)의 정보를 활용하여 현재 시퀀스를 복원하도록 학습
- 디코더(decoder) 는 교차 어텐션(cross-attention)과 자기 어텐션(self-attention) 메커니즘을 적용
- Cross-Attention → 과거 시퀀스의 정보를 현재 시퀀스의 재구성에 활용
- Self-Attention → 현재 시퀀스 내의 패턴을 학습
- 최종적으로, 디코더의 출력을 통해 원래의 시퀀스를 복원하는지 평가
- 재구성 오류를 줄이는 방향으로 모델을 학습
-
손실 함수 (Loss Function)
- TimeSiam은 간단한 L2 Norm(reconstruction loss)을 사용 하여 학습을 진행한다.
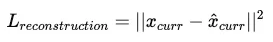
- 즉, 원래의 시퀀스(xcurr)와 모델이 예측한 시퀀스(𝑥̂ curr) 간의 차이를 최소화하도록 학습된다.
- TimeSiam은 간단한 L2 Norm(reconstruction loss)을 사용 하여 학습을 진행한다.
-
3.2 Fine-Tuning
(1) Fixed-Input-Multiple-Lineages
- 전통적인 방법에서는 각 입력 데이터에 대해 하나의 표현만 생성
- 하지만 Timesiam에서는 다양한 계통을 학습했기 때문에, 여러 개의 서로 다른 표현을 생성
- 이렇게 생성된 표현들의 평균을 구하여 최종 출력으로 활용
(2) Extended-Input-Multiple-Lineages
- 기존 사전 학습된 모델은 고정된 길이의 시뭔스를 입력 받아 학습됨
- 그러나 Fine-tuning시 더 긴 데이터 입력을 처리해야 할 수 있음
- Timesiam은 각 부분(sequence segment)마다 서로 다른 계통 임베딩을 적용하여 시간적 일관성을 유지하면서 더 긴 입력 데이터를 활용할 수 있음
→ 그 결과, Timesiam을 이용한 파인튜닝은 기존 방법 대비 일관된 성능 향상을 보이며, in-domain 및 cross-domain 모두에서 효과적임을 입증함
4. Experiments
4.1 Experimental Setup
(1) 데이터셋
- TimeSiam의 성능을 평가하기 위해 13개의 표준 시계열 벤치마크 데이터셋을 사용함
- 이 데이터셋들은 예측 및 분류 두 가지 주요 시계열 분석 작업을 포함
- 사용된 데이터셋:
- 시계열 예측 데이터셋: ETTh1, ETTh2, ETTm1, ETTm2 → 전력 변압기 온도 및 부하 데이터
- Weather → 기상 관측 데이터
- Electricity → 전기 소비량 데이터
- Traffic → 교통량 데이터
- Exchange → 환율 데이터
- TSLD-500M & TSLD-1G → 디양한 도메인의 대규모 시계열 데이터
- 시계열 분류 데이터셋
- AD → 알츠하이머 EEG 데이터
- TDBrain → 신경계 장애 환자 EEG 데이터
- PTB → 심전도(ECG) 데이터
- 시계열 예측 데이터셋: ETTh1, ETTh2, ETTm1, ETTm2 → 전력 변압기 온도 및 부하 데이터
(2) 모델 구성 (BackBone)
- Siamese Enc
- PatchTST
- iTransformer
- TCN
- Baselines:
- 대조 학습(Contrastive Learning) 기반:
- CPC (2018), TNC (2021), TS2Vec (2022), CoST (2022), LaST (2022), TF-C (2022), COMET (2023)
- 마스킹 모델링(Masked Modeling) 기반:
- SimMTM (2023), Ti-MAE (2023), TST (2021), PatchTST (2023)
- 대조 학습(Contrastive Learning) 기반:
4.2 Main Results
- TimeSiam은 예측 및 분류 작업에서 기존의 모든 자기지도 학습 방법을 능가하는 성능을 보였다.
- 시계열 예측 결과:
- TimeSiam은 기존의 마스킹 모델링 및 대조 학습 기반 모델 대비 더 낮은 MSE (Mean Squared Error) 값을 기록 하여, 더 정확한 예측 성능을 보였다.
- 특히, 도메인 내(in-domain) 및 도메인 간(cross-domain) 전이 학습에서도 뛰어난 성능을 발휘 함
- 시계열 분류 결과:
- TimeSiam을 적용한 분류 모델은 F1-score, 정확도(accuracy) 등 모든 지표에서 기존 모델을 뛰어넘는 성능을 기록
- 특히 알츠하이머(AD) 및 심전도(ECG) 데이터셋에서 매우 높은 성능을 기록
4.3 시계열 예측 실험
- In-domain
- PatchTST 및 iTransformer를 활용하여 기존 모델보다 5~7% 향상된 MSE를 기록
- 마스킹 모델링이 대조 학습보다 예측 성능이 우수하지만, TimeSiam이 가장 좋은 성능을 보임
- Cross-domain
- TSLD-1G 데이터셋에서 사전 학습 후, ECL, Traffic 등 다른 도메인에서 파인 튜닝하여 평가
- 기존의 사전 학습 기법 대비 더 나은 성능을 보였으며, 일부 데이터셋에서는 도메인 내 학습보다도 성능이 우수함
- 이는 대규모 데이터에서 학습된 TimeSiam이 강력한 일반화 능력을 갖추고 있음으르 의미
4.4 시계열 분류 실험
- In-domain
- AD, TDBrain, PTB 데이터셋에서 평가한 결과, TimeSiam이 F1-score 및 정확도에서 11.5% 향상된 성능을 기록
- 특히, SimMTM, COMET 등 최신 모델보다도 더 높은 성능을 기록
- Cross-domain
- TSLD-1G에서 사전 학습 후, EEG 및 ECG 데이터에서 파인튜닝
- 도메인 간 실험에서도 가장 높은 정확도를 기록하며, 다양한 데이터 도메인에서의 확장성이 높음을 입증
4.5 Ablation Studies
- Siamese Sampling의 효과
- Lineage Embedding의 효과
- 마스킹 전략 비교
- continuous masking이 channel-wise masking보다 더 높은 성능을 보임
- 하지만 마스킹 비율이 너무 높으면 성능 저하
4.6 Analysis Experiments
- 데이터의 규모가 클수록 성능 향상
- 작은 데이터셋보다 대규모 데이터셋에서 사전 학습한 모델이 더 높은 성능을 기록
- 더 긴 입력 데이터를 사용하면 예측 성능이 향상됨
- Linear Probing 실험
- 사전 학습된 인코더를 고정하고 새로운 classifier를 학습한 경우에도 높은 성능을 유지
5. Conclusion
TimeSiam이라는 새로운 자기지도 학습 기반 시계열 사전 학습 프레임워크를 제안
- 기존의 마스킹 모델링과 대조 학습은 시계열 데이터의 본질적인 특징을 충분히 반영하지 못하는문제를 가지고 있음을 강조
- 이러한 한계를 극복하기 위해 시간적 상관관계 (temporal correlation) 를 강조하는 방식으로 설계되었다.
- TimeSiam의 핵심 특징
- siamese network를 활용하여 서로 다른 시간대의 하위 시퀀스 간 관계를 학습
- 간단한 마스킹 기법을 활용하여 다양한 하위 시퀀스를 생성하고 학습
- 과거 시퀀스로부터 현재 시퀀스를 복원하는 “과거-현재 재구성(past-to-current reconstruction)” 방식을 도임
- Learnable Lineage Embeddings를 추가하여 temporal distance를 명확히 구별할 수 있도록 설계
- TimeSiam의 실험적 성과
- 13개의 벤치마크 데이터셋에서 실험을 수행한 결과, 기존의 최첨단 시계열 사전 학습 방법들을 일관되게 능가하는 성능을 보였다.
- TimeSiam은 시계열 예측 및 분류 작업에서 뛰어난 성능을 발휘했으며, 특히 in-domain, cross-domain 학습에서도 강력한 일반화 성능을 입증
Appendix
출처 없음
- 이건 수정이 필요합니다.
- 감사합니다.
