
3주차: 트리와 재귀
출처
📚 쉽게 배우는 자료구조 with 파이썬
📚 이것이 자료구조+알고리즘이다 with C언어
✏️ 기존에 공부했던 내용
💻 스택 - 상속 구현 참고한 블로그

트리
데이터를 색인(indexing)할 때 검색 트리를 사용하여 레코드에 효율적으로 접근할 수 있다.
이진 검색 트리
가장 원시적으로 색인을 만든다면 배열에 키를 정렬시켜 index로 삼을 수 있다. 그러나 n개의 키가 정렬된 상태로 이루어진 배열 인덱스는 검색에 평균 O(logn), 삽입과 삭제에 O(logn)이 들어 색인의 크기가 커지면 비효율적이다.
이진 검색 트리는 이보다 개선된 검색방법으로, 검색과 삽입 삭제가 모두 O(logn)의 시간 안에 이루어진다.
검색 트리
트리는 루트로 시작되어 노드들로 이어나간다. 한 노드에서 나갈 수 있는 최대 노드의 수를 n이라고 할 때, 이 트리는 n진 트리가 된다.
검색 트리는 저장 장소에 따라 내장 검색 트리와 외장 검색 트리로 나뉜다.
- 내장 검색 트리: 검색트리가 메인 메모리 내에 존재. 내장메모리에서 검색트리 전체를 수용할 수 있으면 메모리에 한 번만 탑재한 후 내장 검색 트리로 사용할 수 있음.
- 외장 검색 트리: 검색 트리가 외부(주로 디스크)에 존재. 공간이 부족할 경우 검색 트리를 디스크에 저장해야 하는데, 이 경우 디스크 접근시간이 검색 효율을 좌우한다.
이진 검색 트리
이진 검색 트리의 특징
- 각 노드는 모두 다른 키값을 하나씩 갖는다
- 최상위 레벨에 루트 노드가 있고, 각 노드는 최대 2개의 자식노드를 갖는다
- 임의노드의 키값은 자신의 왼쪽 아래에 있는 모든 노드의 키값보다 크고, 오른쪽 노드의 키값보다 작다. (크기: 왼 < 중간 < 오)
검색 트리는 높이가 효율성에 큰 영향 미친다. 노드의 개수와 그 값들이 모두 같아도 데이터를 삽입하는 순서에 따라높이가 달라질 수 있다. 이후에서 자세히 설명.
이진 검색 트리 알고리즘과 구현
👉 이진 검색 트리는 주로 검색, 삽입, 삭제의 세 가지 기능을 가진다.
이진 검색 트리의 ADT
- __root: 이진 검색 트리의 루트 노드
- search(x), insert(x), delete(x), isEmpty, clear()
우선 이 기능들을 의사 코드 (pseudo code)로 나타내보자.
1. 검색
이진 검색 트리에서 키가 x인 노드를 검색하고자 할 때, 존재하면 해당 노드를 리턴하고 실패하면 null을 리턴한다. 해당 노드를 리턴할 수도 있고, 필요에 따라 노드 안에 있는 특정 정보를 리턴하도록 할 수도 있다.
어떤 노드의 왼쪽 자식과 오른쪽 자식은 각각 '왼자식'과 '오른자식'으로 줄여서 부르도록 하고, 서브트리는 좌서브트리와 우서브트리로 부르도록 하자.
✔️ 검색 알고리즘은 다음과 같이 재귀적으로 구성한다.
search(t,x): <-t: 루트노드 레퍼런스, x: 찾고자 하는 값
if (t=null || t.item = x)
return t
else if ( x < t.item)
return search(t.left, x)
else
return search(t.right, x)루트 노드 t의 키값과 찾고자 하는 키 x가 주어진다.
- if: 루트노드의 키값이 x값과 같으면 그 값을 반환하고, t가 null 이면 null을 반환한다.
- else if: x가 t보다 작으면 좌서브 트리로 가서 x를 찾고,
- else: 크면 우서브 트리로 가서 x를 찾는다.
⭕️ 검색 성공 : search(*,x)를 재귀적으로 수행하다 x와 같은 값을 가진 노드를 만나면 해당 노드의 레퍼런스를 리턴한다.
❌ 검색 실패: 리프 노드까지 간 후에 찾는 값이 없거나, 분기하려는 방향의 자식이 null이면 실패라고 판정한다.
2. 삽입
원소 x를 이진 검색 트리에 삽입하려면 우선 트리 안에 x를 키값으로 가진 노드가 없어야 한다. 값 포함 여부를 알기 위해서는 x값으로 실패하는 검색을 전체적으로 한 번 수행하면 된다. 즉, 검색과 똑같은 과정을 수행하다 리프 노드에 이르거나 null을 만난다면 x를 매달면 된다.
insert(x):
root <- insertItem(root,x)
insertItem(t,x):
if (t=null)
n.item <-x; n.left<-null; n.right <-null
return n
else if (x < t.item)
t.left <- insertItem(t.left,x)
return t
else
t.right <- insertItem(t.right,x)
return t
- insert(x): 원소가 아무것도 없는 빈 트리일 경우, null로 되어 있는 루트의 레퍼런스를 갱신해주기 위함.
- n : 새 노드
- else if: t.left가 insertItem의 리턴값을 기다리고 있음.
- else: t.right
❗️트리의 효율성
원소를 삽입하는 순서에 따라 이진 검색 트리의 모양이 결정된다.
다음은 동일한 값을 가졌지만 순서가 다른 리스트를, 그 순서에 따라 이중 트리구조로 삽입한 그림이다.
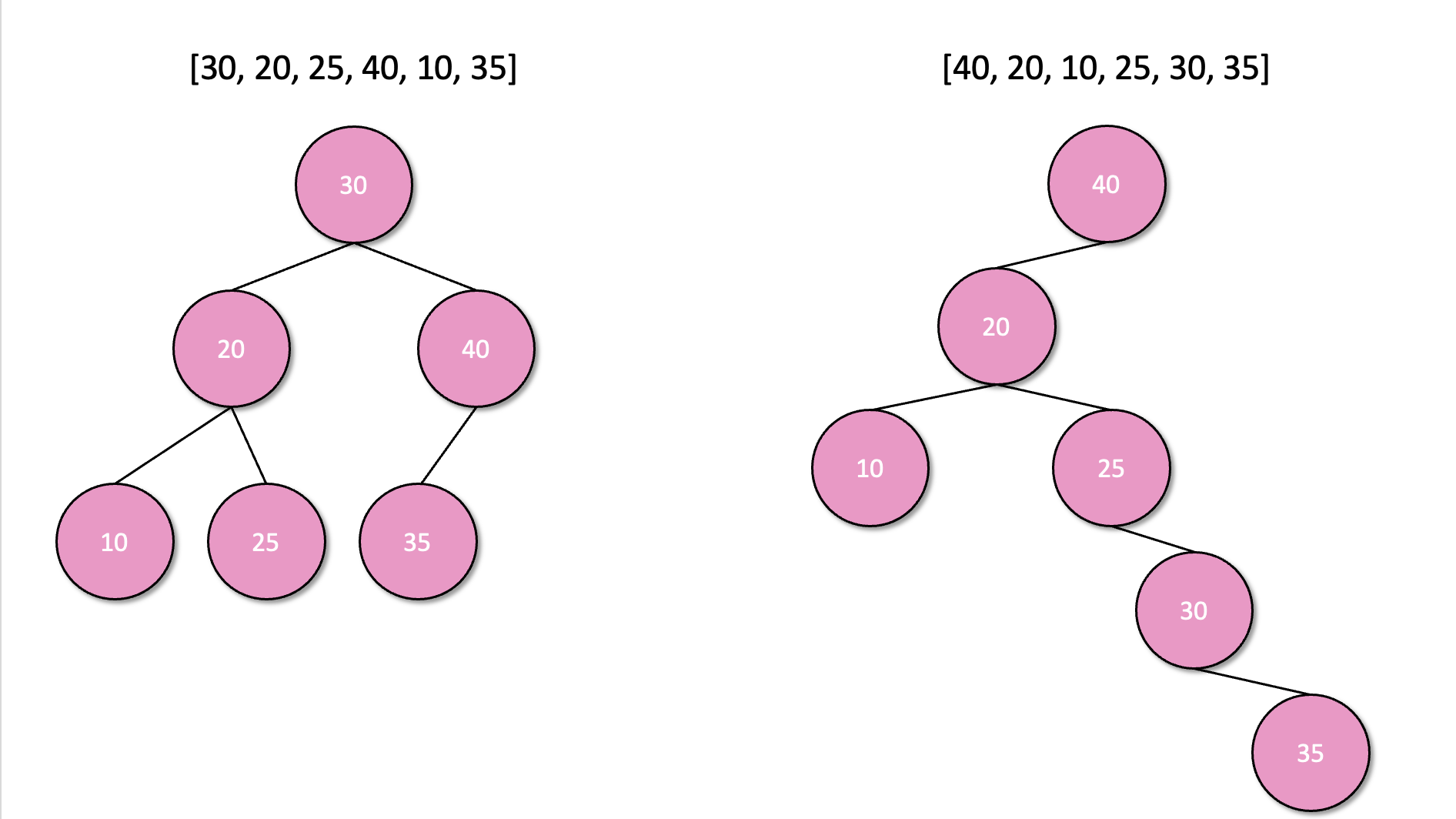
왼쪽은 좌우의 균형이 잘 맞아 높이가 3으로 끝나는 반면, 오른쪽은 높이가 5나 된다. 이진 트리의 모양에 따라, 검색 효율이 배열과 연결 리스트보다 좋을 수도 나쁠 수도 있다.
n개의 원소로 이진 트리를 만들 때, 가장 이상적으로 균형이 잡힌 이진 트리의 검색 시간은 최악의 경우 O(log n) 이다. 반대로 가장 나쁘게 기울면 평균 검색시간은 O(n) 이 된다.
가능한 모든 삽입 순서에 따른 이진 검색 트리를 모두 고려하면 평균 검색시간은 O(log n) 이다. 삽입은 실패검색 후 상수시간의 후처리를 하므로, 점근적 수행시간은 검색과 동일하다.
3. 삭제
삭제는 검색, 삽입보다 과정이 복잡하다. 이진 검색 트리에서 노드 r을 삭제한다면, 다음과 같이 세 가지 케이스에 따라 다르게 처리해야 한다.
- Case1: r이 리프 노드인 경우
- Case2: r의 자식노드가 1개인 경우
- Case3: r의 자식노드가 2개인 경우
1번 케이스의 경우, r을 그냥 삭제해도 아무런 지장이 없다.
2번 케이스의 경우, r의 자식을 r의 부모에 직접 갖다 붙인다.
3번 케이스의 경우, r의 오른쪽 서브 트리의 최소 원소 노드 s를 찾고, s를 기존 r의 자리로 복사하고 s를 삭제한다.
많이 복잡하지만, 일단 재귀적으로 나타내 보면 다음과 같다.
delete(t,x):
if (t=null)
error("Item not found")
else if (x=t.item)
t <- deleteNode(t)
return t
else if (x<t.item)
t.left <- delete(t.left,x)
return t
else
t.right <- delete(t.right,x)
return t
deleteNode(t):
if (t.left=null && t.right=null)
return null
else if (t.left=null)
return t.right
else if (t.right=null)
return t.left
else
(minItem, node) <- deleteMitItem(t.right)
t.item <- minItem
t.right <- node
return t
deleteMinItem(t):
if (t.left = null)
return (t.item, t.right)
else
(minItem, node) = deleteMinItem(t.left)
t.left <- node
return(minItem,t)-
deleteMinItem: t.right이 인자로 대입된다. Case3에서, 삭제하고자 하는 노드의 우서브트리의 최소값을 찾아 (t.left를 따라 내려가다가 t.left를 더이상 가지고 있지 않는 노드를 찾음) t.item으로 저장하고, 그 노드의 우서브트리를 t.right에 저장해 두 값을 반환한다.
-
deleteNode(t) 중 else: Case3 처리과정으로, deleteMinItem에서 가져온 최소값 s를 기존 r노드의 자리에 가져다 붙이고, 그 s에 우서브트리가 있었다면 s 자리로 올려서 기존 s의 부모노드에 가져다 붙인다.
트리의 순회
트리에서 순회란 모든 노드를 방문하는 것을 말한다. 루트가 전위에 있는지, 중위에 있는지, 후위에 있는지에 따라 결정된다. 의사코드와 함께 보면 다음과 같다.
-
전위 순회: 루트 ->좌서브트리 ->우서브트리
preOrder(r): if (r!=null) r.visited = true preOrder(r.left) preOrder(r.right) -
중위 순회: 좌서브트리 -> 루트 -> 우서브트리
inOrder(r): if (r!=null) inOrder(r.left) r.visited = true inOrder(r.right) -
후위 순회: 좌서브트리 -> 우서브트리 -> 루트
postOrder(r): if (r!=null) postOrder(r.left) postOrder(r.right) r.visited = true
