
안녕하세요:) 개발자 우디입니다! 아래 내용 관련하여 작업 중이신 분들께 도움이되길 바라며 글을 공유하니 참고 부탁드립니다😊
(이번에 벨로그로 이사오면서 예전 글을 옮겨적었습니다. 이 점 양해 부탁드립니다!)
작업 시점: 2020년 하반기 ~ 2021년 4월
배경
데드 바이 데이라이트 게임의 주요 이벤트 추출을 위해 객체탐지 모델 YOLOv5를 학습함
1. 데이터셋 구성하기
-
데이터 준비 및 라벨링 (아래 게시글을 통해 확인해주세요!)
-
데이터셋 구성
-
폴더 구조
-
dataset 폴더 내부를 images, labels, data.yaml로 구성
- images
- labels

- data.yaml
-> yaml은 xml과 json 포맷과 같이 타 시스템 간에 데이터를 주고받을 때 약속된 포맷(규칙)이 정의되어있는 파일 형식. 간단하게 설정 파일이라고 보면 됨.names: - DBD_END - DBD_END_ENG - DBD_START - DBD_START_ENG - DBD_STATE_DEATH_NORMAL - DBD_STATE_DEATH_TWISTED - DBD_STATE_ESCAPE - DBD_STATE_FAINT - DBD_STATE_HOOK nc: 9 train: /content/dataset/train.txt val: /content/dataset/val.txt
- images
-
-
파일 이름 숫자로 맞춰 변경하기 위한 코드
-
파일명을 원하는 숫자로 일괄 변경하기 위해 간단한 코드 작성 (스스로 편한 언어인 JS로 작성)
let fs = require("fs"); let folderPath = "C:/Users/.../labels"; // 윈도우 시 / 이용 let startNum = 1601; // need to be changed fs.readdir(folderPath, (err, fileNameList) => { // console.log(fileNameList); for (let i = 0; i < fileNameList.length; i++) { let currentFileName = fileNameList[i]; let originalExtension = currentFileName.split(".")[1]; let changedFileName = startNum + i; // console.log(`${changedFileName}.${originalExtension}`); fs.rename( `${folderPath}/${currentFileName}`, `${folderPath}/${changedFileName}.${originalExtension}`, (err) => { if (err) { console.log("err", err); } else { console.log("suceess: ", `${changedFileName}.${originalExtension}`); } } ); } });
-
-
2. 데이터셋 업로드 (google colab 활용)
- 구글 드라이브 마운트
### 입력 ### from google.colab import drive drive.mount('/content/drive') ### 출력 ### Mounted at /content/drive ``` - 마운트 이후의 폴더 구조
3. yolo 모델 clone
### 입력 ###
%cd /content
!git clone https://github.com/ultralytics/yolov5.git
### 출력 ###
/content
Cloning into 'yolov5'...
remote: Enumerating objects: 16057, done.
remote: Total 16057 (delta 0), reused 0 (delta 0), pack-reused 16057
Receiving objects: 100% (16057/16057), 14.66 MiB | 25.62 MiB/s, done.
Resolving deltas: 100% (11028/11028), done.-
clone 이후의 폴더 구조
-
필요한 패키지들 설치
### 입력 ### %cd /content/yolov5/ !pip install -r requirements.txt ### 출력 ### /content/yolov5 Collecting gitpython>=3.1.30 (from -r requirements.txt (line 5)) Downloading GitPython-3.1.40-py3-none-any.whl (190 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 190.6/190.6 kB 5.2 MB/s eta 0:00:00 Requirement already satisfied: matplotlib>=3.3 in /usr/local/lib/python3.10/dist-packages (from -r requirements.txt (line 6)) ...생략... Successfully installed Pillow-10.1.0 gitdb-4.0.11 gitpython-3.1.40 smmap-5.0.1 thop-0.1.1.post2209072238 ultralytics-8.0.208-> 라이브러리들이 설치되면서 'already satisfied', 'successfully iinstalled'등의 문구 나오면 성공
4. data.yaml 파일 확인
### 입력 ###
%cat /content/drive/MyDrive/.../dataset/data.yaml
### 출력 ###
names:
- DBD_END
- DBD_END_ENG
- DBD_START
- DBD_START_ENG
- DBD_STATE_DEATH_NORMAL
- DBD_STATE_DEATH_TWISTED
- DBD_STATE_ESCAPE
- DBD_STATE_FAINT
- DBD_STATE_HOOK
nc: 9
train: /content/drive/MyDrive/.../dataset/train.txt
val: /content/drive/MyDrive/.../dataset/val.txt -> 'names'하단에 클래스 명을 적고, 'nc'에 클래스 총 개수를 적음
-> 'train', 'val'은 데이터셋을 각각 학습용, 검증용으로 나누는 것임
5. dataset의 images 데이터 확인
### 입력 ###
%cd /
from glob import glob
img_list = glob('/content/drive/MyDrive/.../dataset/images/*.png')
print(len(img_list))
### 출력 ###
/
1800-> python glob 모듈의 glob 함수는 사용자가 제시한 조건에 맞는 파일명을 리스트 형식으로 반환함.
6. 학습용, 검증용 데이터 셋으로 나눈 후 확인.
### 입력 ###
from sklearn.model_selection import train_test_split
train_img_list, val_img_list = train_test_split(img_list, test_size=0.1, random_state=2000)
print(len(train_img_list), len(val_img_list))
### 출력 ###
1620 180-> 머신러닝 모델을 학습하고 그 결과를 검증하기 위해서는 원래의 데이터를 Training, Validation, Testing의 용도로 나누어 다뤄야 함.
-> Training에 사용한 데이터를 검증용으로 사용하면 시험문제를 알고 있는 상태에서 공부를 하고 그 지식을 바탕으로 시험을 치루는 꼴이므로 제대로 된 검증이 이루어지지 않기 때문임.
-> 딥러닝을 제외하고도 다양한 기계학습과 데이터 분석 툴을 제공하는 scikit-learn 패키지 중 model_selection에는 데이터 분할을 위한 train_test_split 함수가 들어있음.
7. txt 파일에 write 해서 파일 생성하기.
with open('/content/drive/MyDrive/.../dataset/train.txt', 'w') as f:
f.write('\n'.join(train_img_list) + '\n')
with open('/content/drive/MyDrive/.../dataset/val.txt', 'w') as f:
f.write('\n'.join(val_img_list) + '\n')- 이 시점에서의 폴더 구조.
8. data.yaml 파일 불러와서 경로 확인 및 변경
### 입력 ###
import yaml
with open('/content/drive/MyDrive/.../dataset/data.yaml', 'r') as f:
data = yaml.full_load(f)
print(data)
data['train'] = '/content/drive/MyDrive/.../dataset/train.txt'
data['val'] = '/content/drive/MyDrive/.../dataset/val.txt'
with open('/content/drive/MyDrive/.../dataset/data.yaml', 'w') as f:
yaml.dump(data, f)
print(data)
### 출력 ###
{'names': ['DBD_END', 'DBD_END_ENG', 'DBD_START', 'DBD_START_ENG', 'DBD_STATE_DEATH_NORMAL', 'DBD_STATE_DEATH_TWISTED', 'DBD_STATE_ESCAPE', 'DBD_STATE_FAINT', 'DBD_STATE_HOOK'], 'nc': 9, 'train': '/content/drive/MyDrive/.../dataset/train.txt', 'val': '/content/drive/MyDrive/.../dataset/val.txt'}
{'names': ['DBD_END', 'DBD_END_ENG', 'DBD_START', 'DBD_START_ENG', 'DBD_STATE_DEATH_NORMAL', 'DBD_STATE_DEATH_TWISTED', 'DBD_STATE_ESCAPE', 'DBD_STATE_FAINT', 'DBD_STATE_HOOK'], 'nc': 9, 'train': '/content/drive/MyDrive/.../dataset/train.txt', 'val': '/content/drive/MyDrive/.../dataset/val.txt'}-
중간에 발생한 이슈
-
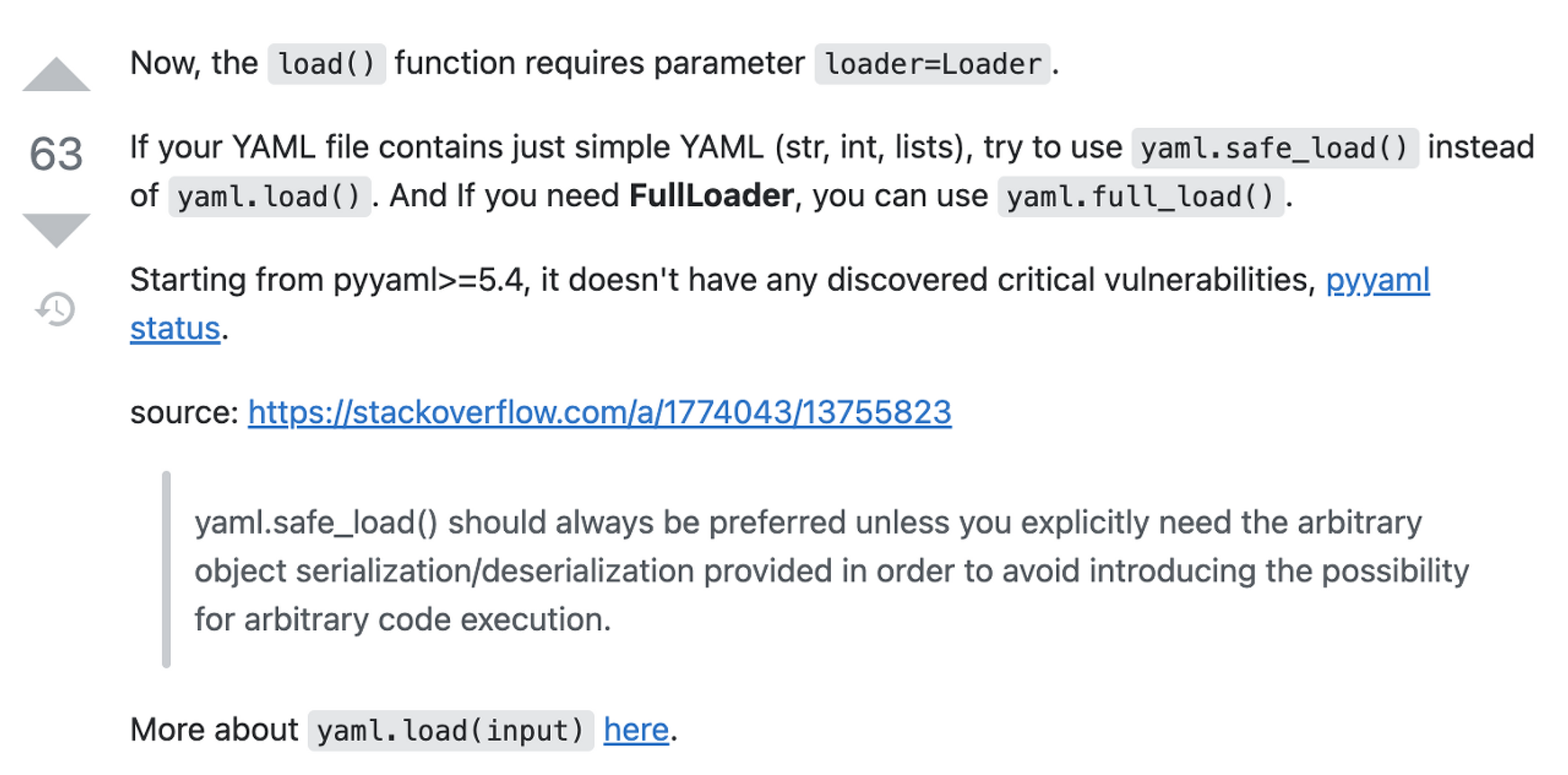
코랩에서 import yaml 후 yaml.load()를 사용하면 아래와 같은 에러가 뜸
load() missing 1 required positional argument: 'Loader'- 버전 문제였던 것으로 보임 -> 버전을 강제로 변경
# 코랩 기준 !pip install pyyaml==5.4.1-
full_load 로 사용
### 변경 전 ### config = yaml.load(f) ### 변경 후 ### config = yaml.full_load(f) -
참고 자료
-
9. 데이터 학습 진행
### 입력 ###
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 50 --data /content/drive/MyDrive/.../dataset/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name dbd_yolov5s_result
### 출력 ###
/content/yolov5
01:46:50.783316: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
01:46:50.783378: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
01:46:50.783423: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
train: weights=yolov5s.pt, cfg=./models/yolov5s.yaml, data=/content/drive/MyDrive/.../dataset/data.yaml, hyp=data/hyps/hyp.scratch-low.yaml, epochs=50, batch_size=16, imgsz=416, rect=False, resume=False, nosave=False, noval=False, noautoanchor=False, noplots=False, evolve=None, bucket=, cache=None, image_weights=False, device=, multi_scale=False, single_cls=False, optimizer=SGD, sync_bn=False, workers=8, project=runs/train, name=dbd_yolov5s_result, exist_ok=False, quad=False, cos_lr=False, label_smoothing=0.0, patience=100, freeze=[0], save_period=-1, seed=0, local_rank=-1, entity=None, upload_dataset=False, bbox_interval=-1, artifact_alias=latest
github: up to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v7.0-240-g84ec8b5 Python-3.10.12 torch-2.1.0+cu118 CUDA:0 (Tesla T4, 15102MiB)
hyperparameters: lr0=0.01, lrf=0.01, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0, copy_paste=0.0
Comet: run 'pip install comet_ml' to automatically track and visualize YOLOv5 🚀 runs in Comet
TensorBoard: Start with 'tensorboard --logdir runs/train', view at http://localhost:6006/
Downloading https://ultralytics.com/assets/Arial.ttf to /root/.config/Ultralytics/Arial.ttf...
100% 755k/755k [00:00<00:00, 24.1MB/s]
Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt...
100% 14.1M/14.1M [00:00<00:00, 147MB/s]
Overriding model.yaml nc=80 with nc=9
from n params module arguments
0 -1 1 3520 models.common.Conv [3, 32, 6, 2, 2]
1 -1 1 18560 models.common.Conv [32, 64, 3, 2]
2 -1 1 18816 models.common.C3 [64, 64, 1]
3 -1 1 73984 models.common.Conv [64, 128, 3, 2]
4 -1 2 115712 models.common.C3 [128, 128, 2]
5 -1 1 295424 models.common.Conv [128, 256, 3, 2]
6 -1 3 625152 models.common.C3 [256, 256, 3]
7 -1 1 1180672 models.common.Conv [256, 512, 3, 2]
8 -1 1 1182720 models.common.C3 [512, 512, 1]
9 -1 1 656896 models.common.SPPF [512, 512, 5]
10 -1 1 131584 models.common.Conv [512, 256, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 361984 models.common.C3 [512, 256, 1, False]
14 -1 1 33024 models.common.Conv [256, 128, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 90880 models.common.C3 [256, 128, 1, False]
18 -1 1 147712 models.common.Conv [128, 128, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 296448 models.common.C3 [256, 256, 1, False]
21 -1 1 590336 models.common.Conv [256, 256, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 1182720 models.common.C3 [512, 512, 1, False]
24 [17, 20, 23] 1 37758 models.yolo.Detect [9, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [128, 256, 512]]
YOLOv5s summary: 214 layers, 7043902 parameters, 7043902 gradients, 16.0 GFLOPs
Transferred 342/349 items from yolov5s.pt
AMP: checks passed ✅
optimizer: SGD(lr=0.01) with parameter groups 57 weight(decay=0.0), 60 weight(decay=0.0005), 60 bias
albumentations: Blur(p=0.01, blur_limit=(3, 7)), MedianBlur(p=0.01, blur_limit=(3, 7)), ToGray(p=0.01), CLAHE(p=0.01, clip_limit=(1, 4.0), tile_grid_size=(8, 8))
train: Scanning /content/drive/MyDrive/.../dataset/train... 1620 images, 0 backgrounds, 0 corrupt: 100% 1620/1620 [17:03<00:00, 1.58it/s]
train: New cache created: /content/drive/MyDrive/.../dataset/train.cache
val: Scanning /content/drive/MyDrive/.../dataset/val... 180 images, 0 backgrounds, 0 corrupt: 100% 180/180 [01:52<00:00, 1.60it/s]
val: New cache created: /content/drive/MyDrive/.../dataset/val.cache
AutoAnchor: 2.45 anchors/target, 1.000 Best Possible Recall (BPR). Current anchors are a good fit to dataset ✅
Plotting labels to runs/train/dbd_yolov5s_result/labels.jpg...
Image sizes 416 train, 416 val
Using 2 dataloader workers
Logging results to runs/train/dbd_yolov5s_result
Starting training for 50 epochs...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
0/49 1.54G 0.08087 0.00846 0.03428 9 416: 100% 102/102 [04:01<00:00, 2.37s/it]
Class Images Instances P R mAP50 mAP50-95: 100% 6/6 [00:10<00:00, 1.81s/it]
all 180 223 0.000367 0.135 0.000401 6.04e-05
...생략...
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
48/49 1.56G 0.008084 0.002433 0.0009116 4 416: 100% 102/102 [03:39<00:00, 2.15s/it]
Class Images Instances P R mAP50 mAP50-95: 100% 6/6 [00:09<00:00, 1.52s/it]
all 180 223 0.865 0.985 0.948 0.853
Epoch GPU_mem box_loss obj_loss cls_loss Instances Size
49/49 1.56G 0.007965 0.002411 0.0007792 8 416: 100% 102/102 [03:39<00:00, 2.15s/it]
Class Images Instances P R mAP50 mAP50-95: 100% 6/6 [00:07<00:00, 1.24s/it]
all 180 223 0.866 0.981 0.946 0.86
50 epochs completed in 3.222 hours.
Optimizer stripped from runs/train/dbd_yolov5s_result/weights/last.pt, 14.3MB
Optimizer stripped from runs/train/dbd_yolov5s_result/weights/best.pt, 14.3MB
Validating runs/train/dbd_yolov5s_result/weights/best.pt...
Fusing layers...
YOLOv5s summary: 157 layers, 7034398 parameters, 0 gradients, 15.8 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100% 6/6 [00:13<00:00, 2.23s/it]
all 180 223 0.866 0.981 0.946 0.861
DBD_END 180 14 0.958 1 0.995 0.987
DBD_END_ENG 180 26 0.978 1 0.995 0.995
DBD_START 180 24 0.976 1 0.995 0.918
DBD_START_ENG 180 14 0.925 1 0.995 0.943
DBD_STATE_DEATH_NORMAL 180 34 0.993 1 0.995 0.926
DBD_STATE_DEATH_TWISTED 180 25 0.79 0.903 0.897 0.773
DBD_STATE_ESCAPE 180 47 0.934 0.979 0.993 0.869
DBD_STATE_FAINT 180 16 0.52 0.949 0.814 0.625
DBD_STATE_HOOK 180 23 0.717 1 0.834 0.709
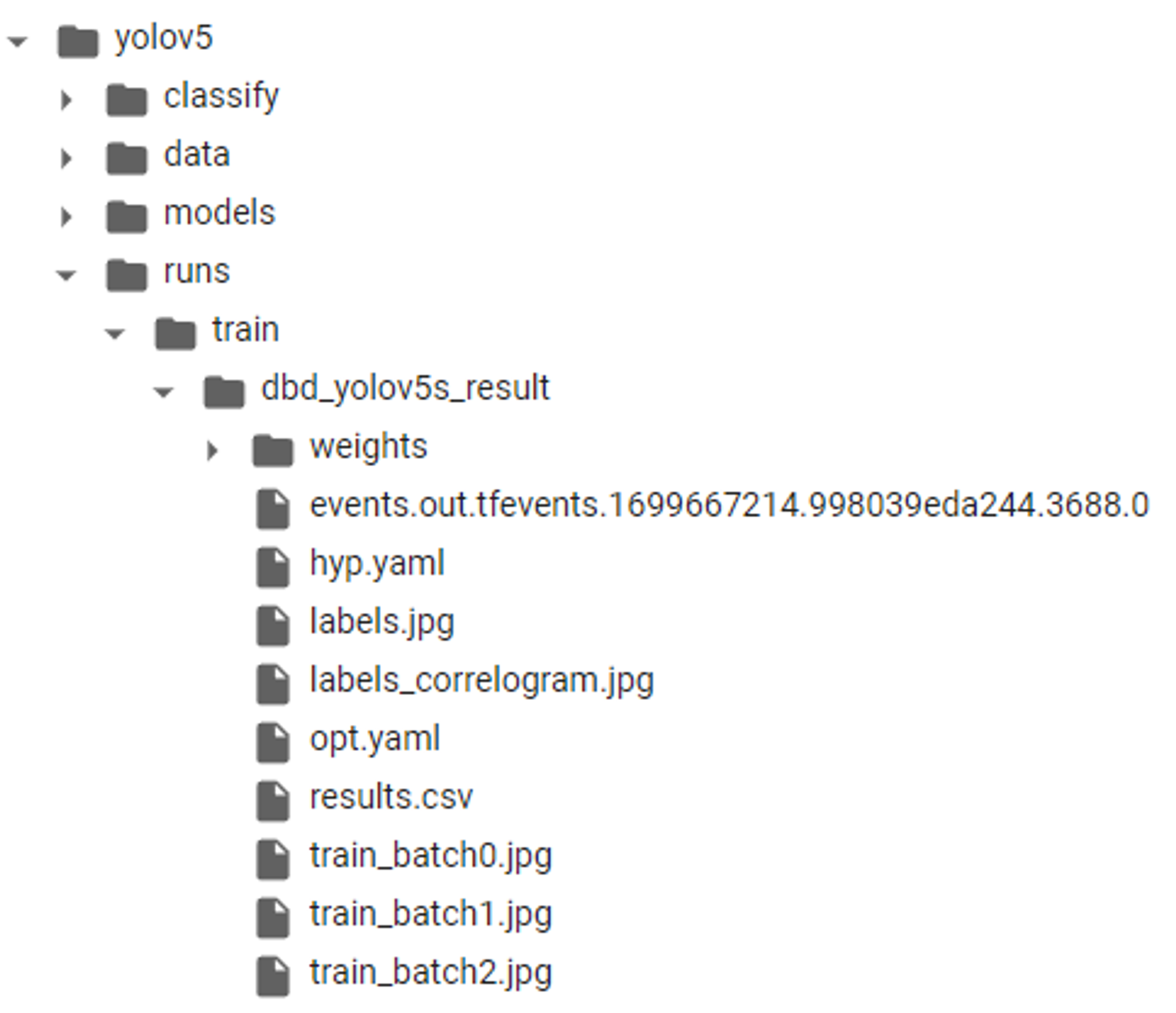
Results saved to runs/train/dbd_yolov5s_result-> 'runs/train/.../' 이 경로에 가면 학습된 모델 파일 확인 가능
- 이 시점에서의 폴더 구조
10. 학습된 모델 추론 테스트
### 입력 ###
from IPython.display import Image
import os
val_img_path = val_img_list[39]
!python detect.py --weights /content/yolov5/runs/train/dbd_yolov5s_result/weights/best.pt --img 416 --conf 0.5 --source "{val_img_path}"
### 출력 ###
detect: weights=['/content/yolov5/runs/train/dbd_yolov5s_result/weights/best.pt'], source=/content/drive/MyDrive/.../images/550.png, data=data/coco128.yaml, imgsz=[416, 416], conf_thres=0.5, iou_thres=0.45, max_det=1000, device=, view_img=False, save_txt=False, save_csv=False, save_conf=False, save_crop=False, nosave=False, classes=None, agnostic_nms=False, augment=False, visualize=False, update=False, project=runs/detect, name=exp, exist_ok=False, line_thickness=3, hide_labels=False, hide_conf=False, half=False, dnn=False, vid_stride=1
YOLOv5 🚀 v7.0-240-g84ec8b5 Python-3.10.12 torch-2.1.0+cu118 CUDA:0 (Tesla T4, 15102MiB)
Fusing layers...
YOLOv5s summary: 157 layers, 7034398 parameters, 0 gradients, 15.8 GFLOPs
image 1/1 /content/drive/MyDrive/.../dataset/images/550.png: 256x416 1 DBD_START, 44.1ms
Speed: 0.4ms pre-process, 44.1ms inference, 1.6ms NMS per image at shape (1, 3, 416, 416)
Results saved to runs/detect/exp-> 'runs/detect/exp' 여기 경로에 가면 모델 돌린 결과물 확인 가능
작업 과정에서 발생한 이슈들
- 데이터의 양이 많다보니 데이터셋 준비 및 모델 학습 과정에서 다소 많은 시간이 걸렸음.
-> 잘못된 부분이 있을 경우 처음부터 다시 해야할 수 있으니 yaml 파일, 데이터셋 등등 꼼꼼하게 확인하는 것이 중요 - 영상의 모든 프레임에 대해 모델을 돌리다보니 용량 문제가 발생
-> 초당 1개의 프레임만 추론 진행 + 이미지 해상도 낮춤의 방식으로 해결 - 데이터셋이 많아지면 코랩에서 학습하는 것에 한계가 있어서, aws S3에 업로드 후 EC2 활용하여 학습 진행.
-> 4000장 정도 까지는 코랩에서 간단하게 진행 가능한 듯 보이나, 5000~1만장 정도가 되면 AWS나 로컬 하드웨어를 활용하는 것이 좋아 보임.
