Dynamically Optimizing skew joins
Dynamically Optimizing skew joins은 무엇인가?
먼저 왜 필요한가?
- skew 파티션이 무엇인가?
- 파티션들이 한 쪽으로 쏠린 문제(파티션 중 하나가 매우 크다는 의미임)
- 분산 환경의 software라면 겪을 수 밖에 없는 문제임.
- Skew 파티션으로 인한 성능 문제를 해결하기 위함.
- 한 두개의 오래 걸리는 태스크들로 인한 전체 job/stage 종료 지연
- 이 때 disk spill이 발생한다면 더 느려지게 됨.
- AQE의 해법
- 먼저 skew 파티션의 존재 여부 파악
- 다음으로 skew 파티션을 작게 나눔
- 다음으로 상대 조인 파티션을 중복하여 만들고 조인 수행
Dynamically optimizing skew joins 동작 방식
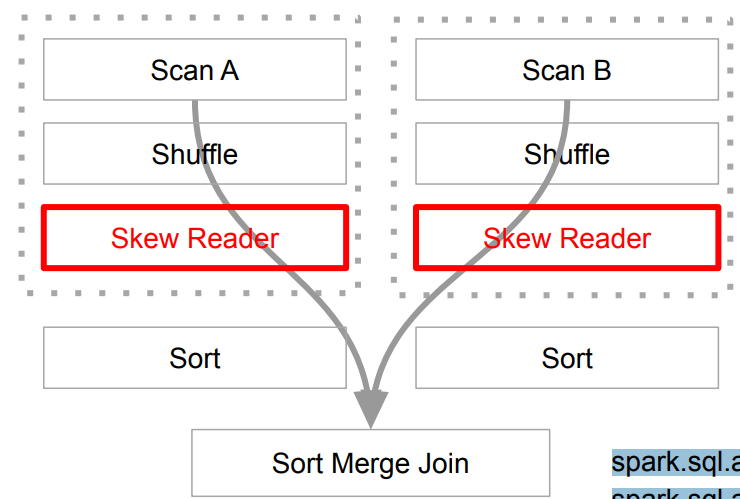
spark.sql.adaptive.skewJoin.skewedPartitionFactorspark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes
- Leaf Stage 실행
- 한 쪽에 skew partition이 보이는 경우, skew reader를 통해 작은 다수의 partition으로 재구성
- 조인 대상이 되는 반대편 파티션은 앞서 다수의 부분 파티션 쪽으로 중복해서 파티션을 생성.

- Table A - MAP1,MAP2, MAP3
- 각각의 테이블 A에서 매핑된 데이터 부분이 나와 있음.
- 각각의 부분은 Part.A0,part.A1,PART.A2,PART.A3로 나뉘어져 있음.
- JOIN 과정
- PART.A0,PART.A1,PART.A2,PART.A3가 각각 PART.B0,PART.B1,PART.B2,PART.B3와 조인됨.
- TABLE B - MAP 1, MAP 2에 대응되는 데이터 파티션이 있음.
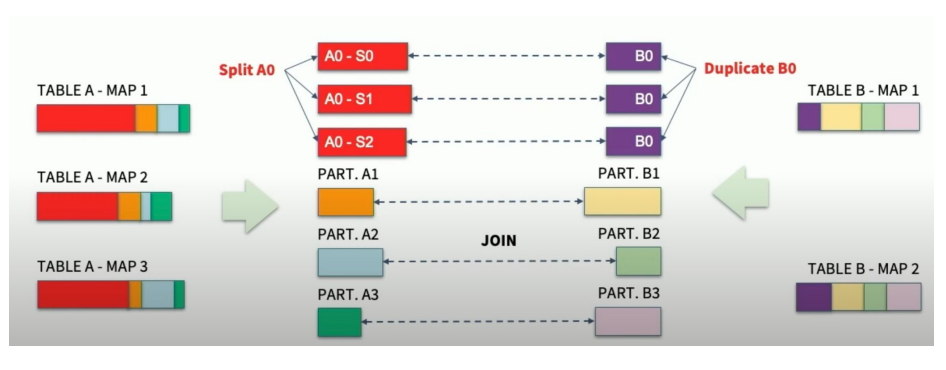
1.SPLIT A0
- 첫 번째 그림에서 PART.A0에 해당하는 부분을 3개로 split함.
- 이로 인해 각 조인 작업이 균형 있게 분배됨.
2. Duplicate B0
- part.B0도 여러 부분으로 복제되어 나뉘어짐.
- 이는 중복된 b0와의 조인을 통해 각 파티션이 보다 균형 있게 분산되도록 함.
Dynamically optimizing skew join 환경 변수들.(spark 3.3.1)
| 환경 변수 이름 | 기본값 | 설명 |
|---|---|---|
| spark.sql.adaptive.skewJoin.enabled | True | 이 값과 spark.sql.adaptive.enabled가 true인 경우, Sort Merge Join 수행시 skew된 파티션들을 먼저 크기를 줄이고 난 다음에 조인 수행 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 5 | 파티션의 크기가 중간 파티션 크기보다 5배 이상 크고 spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes의 값보다 크면 skew 파티션으로 간주 |
| spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes | 256MB | 파티션의 크기가 이 값보다 크고 중간 파티션 크기보다 5배 이상 크면 skew 파티션으로 간주. 이 값은 spark.sql.adaptive.advisoryPartitionSizeInBytes보다 커야함 |
데모
테이블 생성
CREATE TABLE items
USING parquet
AS
SELECT id,
CAST(rand() * 1000 AS INT) AS price
FROM RANGE(30000000);
CREATE TABLE sales
USING parquet
AS
SELECT CASE WHEN rand() < 0.8 THEN 100 ELSE CAST(rand() * 30000000 AS INT) END AS item_id,
CAST(rand() * 100 AS INT) AS quantity,
DATE_ADD(current_date(), - CAST(rand() * 360 AS INT)) AS date
FROM RANGE(1000000000);
optimizing join sql query
SELECT date, sum(quantity) AS q
FROM sales
GROUP BY 1
ORDER BY 2 DESC;
- group by를 통해 날짜별로 데이터를 집계하고, order by를 통해 결과를 내림차순 함.
- 이 과정에서 파티션 간 데이터 이동이 최소화되도록함.
SELECT date, sum(quantity * price) AS total_sales
FROM sales s
JOIN items i ON s.item_id = i.id
WHERE price < 10
GROUP BY 1
ORDER BY 2 DESC;
- 이 쿼리는
sales테이블과items테이블을 조인
Salting을 통한 Data Skew 처리
- AQE가 나오기 전에 data skew 처리 방식 중의 하나가 Salting이었음.
- 굳이 AQE 냅두고 사용할 필요는 없는데, AQE만으로도 Skew Partition 이슈가 사라지지 않으면 사용이 필요할 수도 있으므로 간략하게만 설명하고자 함.
원리
- 기본 원리는 key-value에 임의의 값을 추가하여 데이터 분포를 보다 균등하게 만드는 것임.
동작 방식
- Salted key 생성
- 원래의 key-value에 salt 값을 추가하여 새로운 키 값을 생성 함.
- 예시) 원래 키가 id인 경우 id에 0,12 등을 결합하여 새로운 salted_id를 생성함.
- 원래의 key-value에 salt 값을 추가하여 새로운 키 값을 생성 함.
- 데이터 분산
- Salted 키를 기준으로 데이터를 분산.
- 이 과정에서 동일한 원래 키 값을 가진 데이터가 여러 파티션에 분산되므로 특정 파티션에 데이터가 집중되는 문제를 피할 수 있음.
- join 시 Salting 적용
- 조인 연산을 수행할 때도 동일한 salt 값을 사용하여 데이터가 제대로 매칭 되도록함.
- 예를 들어
sales테이블과items테이블을 조인할 때salted_item_id를 사용하여 조인함.
예시
데이터 생성
CREATE TABLE items
USING parquet
AS
SELECT id,
CAST(rand() * 1000 AS INT) AS price
FROM RANGE(30000000);
CREATE TABLE sales
USING parquet
AS
SELECT CASE WHEN rand() < 0.8 THEN 100 ELSE CAST(rand() * 30000000 AS INT) END AS item_id,
CAST(rand() * 100 AS INT) AS quantity,
DATE_ADD(current_date(), - CAST(rand() * 360 AS INT)) AS date
FROM RANGE(1000000000);
Salted key 생성
SELECT item_id, quantity, date, CONCAT(item_id, '-', CAST(rand() * 10 AS INT)) AS salted_item_id
FROM sales;
조인 시 Salting 적용
SELECT date, sum(quantity * price) AS total_sales
FROM (
SELECT item_id, quantity, date, CONCAT(item_id, '-', CAST(rand() * 10 AS INT)) AS salted_item_id
FROM sales
) s
JOIN (
SELECT id, price, CONCAT(id, '-', CAST(rand() * 10 AS INT)) AS salted_id
FROM items
) i
ON s.salted_item_id = i.salted_id
WHERE price < 10
GROUP BY 1
ORDER BY 2 DESC;
All about Partitions
- 사실 셔플링 후 생기는 파티션만 중요한 것이 아니라 데이터 로딩과 저장 시 파티션의 수도 중요함.
세 종류의 Partition
- 입력 데이터를 로드할 때 파티션 수와 크기
- 병렬 처리 극대화를 위해 적절한 파티션 수 설정이 중요
- 셔플링 후 만들어지는 파티션 수와 크기
- 셔플 과정에서 재분배되는 데이터를 최적화 하기 위해 적절한 파티션 수 설정이 중요
- 데이터를 최종적으로 저장할 때 파티션 수와 크기
- 저장 성능과 이후 읽기 성능을 최적화하기 위해 적절한 파티션 수 설정이 중요
- 각 단계에서 파티션의 크기는 128MB 에서 1GB 사이가 적당함.
입력 데이터를 로드할 때 파티션 수와 크기
- 기본적으로는 파티션의 최대 크기에 의해 결정
- ` spark.sql.files.maxpartitionbytes (128MB)
- 결국 해당 데이터가 어떻게 저장되었는지에 연관이 많음.
- 파일 포맷이 무엇이고 압축은 되었는지, 압축이 되었다면 어떤 알고리즘인지.
- 결국 Splittable한가? -> 한 큰 파일을 다수의 파티션으로 나눠 로드할 수 있는가?
입력 데이터 파티션 수와 크기를 결정해주는 변수들
데이터 처리에서 입력 데이터의 파티션 수와 크기를 적절히 설정하는 것은 매우 중요함. 이를 결정하는 주요 변수들은 다음과 같음:
(1) 버킷 방식으로 저장된 데이터를 읽는 경우
- 버킷 수와 기준 컬럼들:
- 데이터를 버킷 단위로 저장하면, 저장된 버킷 수와 버킷 기준 컬럼들이 데이터 읽기 시 파티션 수를 결정함.
(2) 읽어들이는 데이터 파일이 splittable한지 여부
- splittable한 파일 포맷:
- PARQUET/AVRO: 항상 splittable하여 병렬 처리에 유리함.
- JSON/CSV: 한 레코드가 여러 줄에 걸쳐 있다면 splittable하지 않음. 압축시 bzip2를 사용해야만 splittable함.
(3) 입력 데이터의 전체 크기 (모든 파일 크기의 합)
- 파일 크기와 수:
- 입력 데이터를 구성하는 파일의 전체 크기와 파일 수는 파티션 수를 결정하는 데 중요한 요소임.
(4) 리소스 매니저에게 요청한 CPU 수
- CPU 리소스:
- 요청한 executor 수와 각 executor 별 CPU 수는 병렬 처리 시 사용할 수 있는 리소스의 양을 결정함.
관련 환경 변수들
| 환경 변수 이름 | 기본값 | 설명 |
|---|---|---|
| spark.sql.files.maxPartitionBytes | 128MB | 파일 기반 데이터 소스(Parquet, JSON, ORC 등)에서 데이터프레임을 만들 때 한 파티션의 최대 크기임. |
| spark.sql.files.openCostInBytes | 4MB | 파일 기반 데이터 소스에서 입력 데이터를 읽기 위해 몇 개의 파티션을 사용할지 결정하는 데 사용됨. 대부분의 경우 별 의미 없는 변수이지만, 코어별 입력 데이터 크기가 이 값보다 작은 경우 파티션의 크기를 이 크기로 맞춰서 만듦. |
| spark.sql.files.minPartitionNum | Default parallelism | 파일 기반 데이터 소스에서 파일을 읽어들일 때 최소 몇 개의 파티션을 사용할지 결정하는 변수임. 설정되어 있지 않다면 기본값은 spark.default.parallelism과 동일함. |
| spark.default.parallelism | - | RDD를 직접 조작하는 경우 의미가 있는 변수로, 셔플링 후 파티션의 수를 결정함. 클러스터 내 총 코어 수에 해당함. |
요약
- 입력 데이터 파티션 수와 크기는 데이터 파일 포맷, 파일의 크기, 리소스 매니저에게 요청한 CPU 수, 그리고 관련 환경 변수들에 의해 결정됨.
- splittable한 파일 포맷(예: Parquet, Avro)은 병렬 처리가 용이하며, JSON/CSV와 같은 포맷은 splittable하지 않을 수 있음.
- 환경 변수를 적절히 설정하면 데이터 로드, 셔플링 후, 저장 시의 파티션 수와 크기를 효과적으로 관리할 수 있음.
- spark.sql.files.maxPartitionBytes와 spark.sql.files.openCostInBytes는 파일 기반 데이터 소스의 파티션 크기와 개수를 조정하는 데 중요한 역할을 함.
- spark.default.parallelism은 셔플링 후 파티션 수를 결정하는 데 사용됨.
이 정보를 기반으로 입력 데이터의 파티션 수와 크기를 적절히 조정하면, 데이터 처리 성능을 최적화할 수 있음.
셔플링 후 만들어지는 파티션 수와 크기
-
spark.sql.shuffle.partitions- 기본 값은 200이나 워크로드의 크기와 복잡성에 따른 이 값을 조정하는 것이 필요.
-
AQE를 꼭 사용 -
적절한 파티션 수 설정
-
셔플 파티션 수를 너무 적게 설정하면, 각 파티션의 크기가 커져 네트워크 병목 발생 가능.
-
반대로 셔플 파티션 수가 너무 많으면 그것 또한 곤란.
-
적절한 파티션 수를 설정하기 위해 전체 데이터 크기와 클러스터의 리소스를 고려해야함.
-
데이터를 저장할 때 파티션 수와 크기
- 3가지 방식이 존재
- 기본
- bucketBy
- PartitionBy
- 파일 크기를 레코드 수로도 제어 가능.
spark.sql.files.maxPrecodsPerFile- 기본 값은 0이며 레코드 수로 제약하지 않는다는 의미
3가지 방식 - 기본
- 각 파티션이 하나의 파일로 쓰여짐
- 적당한 크기와 수의 파티션을 찾는 것이 중요
- 작은 크기의 다수의 파티션이 있다면 문제
- 큰 크기의 소수의 파티션도 문제(splittable하지 않는 포맷으로 저장된 경우)
- Repartition 혹은 coalesce를 적절히 사용
- 이 경우 AQE의 Coalescing이 도움이 될 수 있음.
- PARQUET 포맷 사용
- Snappy compression 사용
3가지 방식 - bucketBy
- 데이터 특성을 잘 아는 경우 특정 ID를 기준으로 나누어 테이블로 저장함.
- 버킷 수와 기준 ID를 지정하여 데이터를 나누어 저장함.
- 이렇게 저장된 데이터는 이후 로딩하여 사용할 때 처리 시간이 단축됨.
예제
# 데이터프레임을 특정 키로 bucket 처리하여 테이블로 저장
df.write.mode("overwrite").bucketBy(3, "key").saveAsTable("table_name")
- 버킷의 수와 기준이 되는 키(컬럼)을 지정
- 예를 들어 위 코드는 3개의 버킷으로 나누고 key 컬럼을 기준으로 데이터를 저장하려고함.
3가지 방식 - partitionBy
- 큰 로그 파일을 데이터 생성시간 기반으로 많이 읽는 경우에 유용함.
- 데이터를 연도-월-일 폴더 구조로 저장하여 스캔 과정을 줄이거나 없앰.
- 데이터 관리를 용이하게 함.
- 하지만 카디널리티가 높은 컬럼을 파티션 키로 사용하면 너무 많은 파일이 생성될 수 있음.
예제
# DataFrame을 특정 컬럼으로 파티셔닝하여 테이블로 저장
df.write.mode("overwrite").partitionBy("order_month").saveAsTable("order")
- order_month 컬럼을 기준으로 데이터를 파티셔닝하여 저장하는 예제
# DataFrame을 여러 컬럼으로 파티셔닝하여 테이블로 저장
df.write.mode("overwrite").partitionBy("year", "month", "day").saveAsTable("appl_stock")
- 이건 다중 컬럼.
- 파티션 수는 자동으로 결정됨.
partitionBy와 BucketBy를 동시에 사용하는 경우
1. partitionBy 후에 BucketBy 사용
- partitionBy
- 데이터를 특정 컬럼을 기준으로 데릭토리 구조로 나누어 저장.
- 이는 주로 필터링 패턴을 기준으로 데이터를 분할하여 스캔 범위를 줄이고 쿼리 성능을 향상 시킴.
- bucketBy
- 데이터를 특정 컬ㄹ럼을 기준으로 버킷으로 나누어 저장
- 이는 주로 groupping이나 join pattern을 기준으로 데이터를 분할하여 조인 성능을 향상.
- 합쳐서 사용
- partitionBy를 먼저 적용하여 데이터를 큰 범주로 나눈 다음, 각 파티션 내에서 bucketBy를 사용하여 세부적으로 나눔.
- 아래 코드는 부서별로 데이터를 파티셔닝하고, 각 부서 내에서 직원 ID를 기준으로 버킷팅하는 것.
# 데이터프레임을 부서별로 파티셔닝한 후 직원 ID 기준으로 버킷팅하여 저장
df.write.mode("overwrite").partitionBy("dept").bucketBy(5, "employeeId").saveAsTable("employee_data")

개인공부용(업데이트 중단)