big data, spark, hadoop
1.big data, spark, hadoop - 1
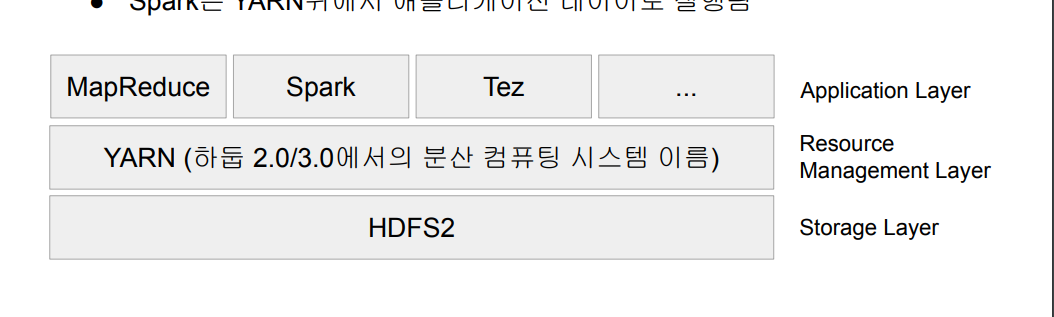
들어가기 앞서서.. 빅데이터 처리를 위해 하둡이라는 오픈소스가 등장 분산 파일 시스템과 분산 컴퓨팅 시스템으로 구성 HDFS와 맵리듀스/YARN 맵리듀스 프로그래밍의 제약성으로 인해 SQL이 재등장 Spark는 대세 대용량 데이터 분산 컴퓨팅 기술
2.big data, spark, hadoop - 2
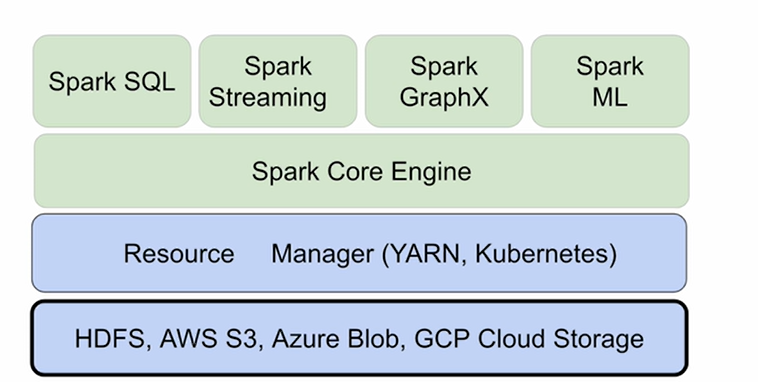
파일 시스템을 별도로 가지고 있진 않지만, 기존에 있는 분산 파일 시스템을 사용HDFS,S3,Azure Blob,GCP Cloud Storage가 있음 (내부 데이터)YARN이나 Kubernetes같은 Resource Manager를 사용그위에 Spark가 사용됨.보
3.big data, spark, hadoop - 3
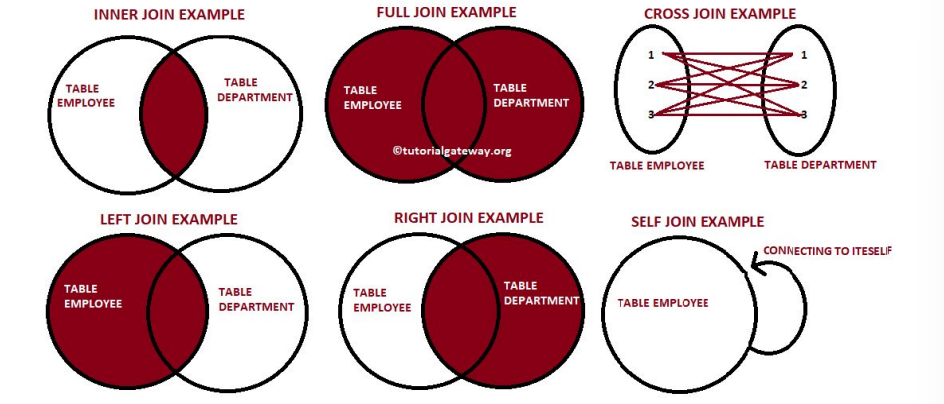
Spark SQL
4.big data, spark, hadoop - 4
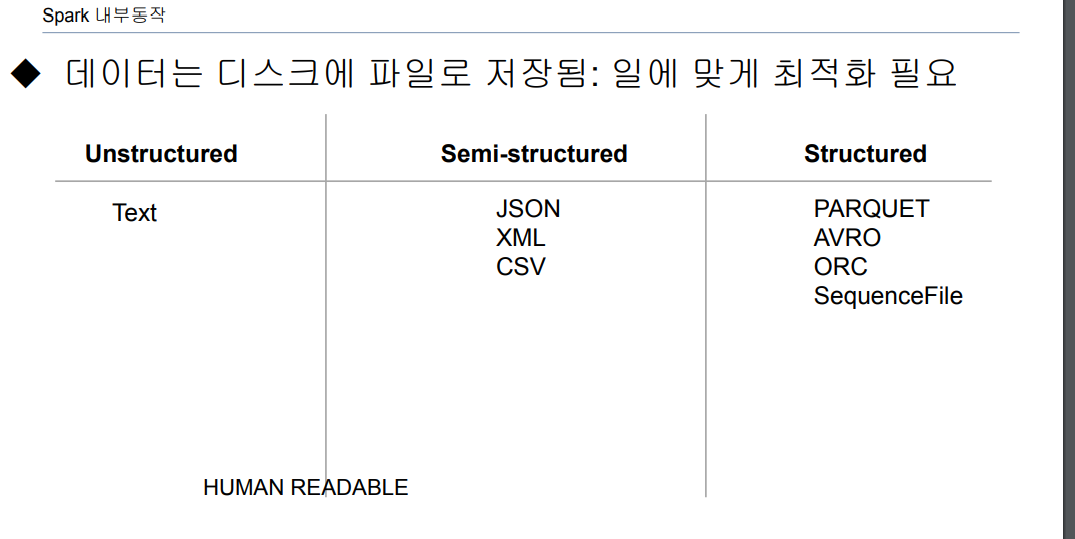
test
5.big data, spark, hadoop - 5
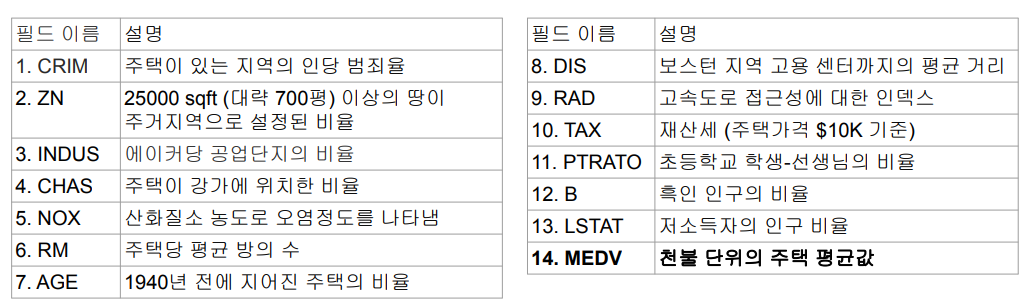
머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리Classification, Regression, Clustering, Collaborative Filtering, DimensionalityReduction딥러닝 지원은 아직 미약spark.mllib vs s
6.spark 고급,spark ML - 1

spark 기타 기능 및 메모리 관리 Shuffling시 Skew 처리 방식과 Spark ML에 대한 파트 Broadcast Variable이란? 룩업 테이블등을 브로드캐스팅하여 셔플링을 막는 방식으로 사용 대부분 룩업 테이블을 executor로 전송하는 데 사용.
7.spark 고급,spark ML - 2

어느 시스템이건, 반복되어서 사용하는 데이터가 있다면 메모리에 두는 것이 좋음그 방법이 spark에서의 사용하는 것이 Cashnig과 Persiststorage Memory pool에 할당이 되는데, 모든 데이터 프레임을 여기에 cashing을 할 수 없음.Cashin
8.spark 고급,spark ML - 3
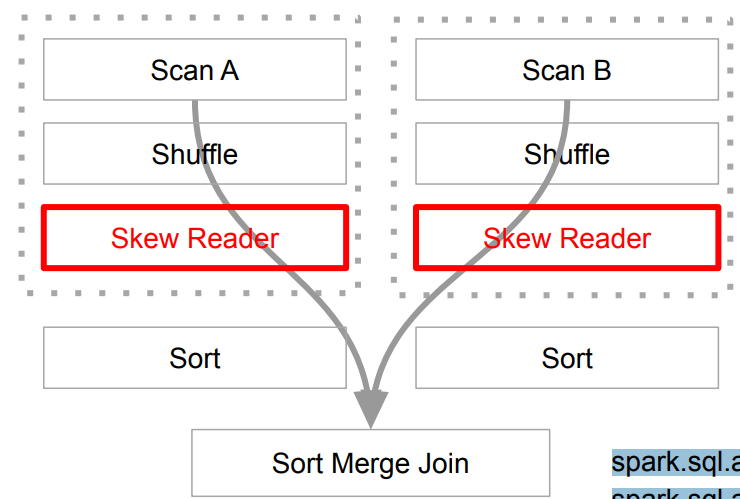
skew 파티션이 무엇인가?파티션들이 한 쪽으로 쏠린 문제(파티션 중 하나가 매우 크다는 의미임)분산 환경의 software라면 겪을 수 밖에 없는 문제임.Skew 파티션으로 인한 성능 문제를 해결하기 위함.한 두개의 오래 걸리는 태스크들로 인한 전체 job/stage
9.spark 고급,spark ML - 4
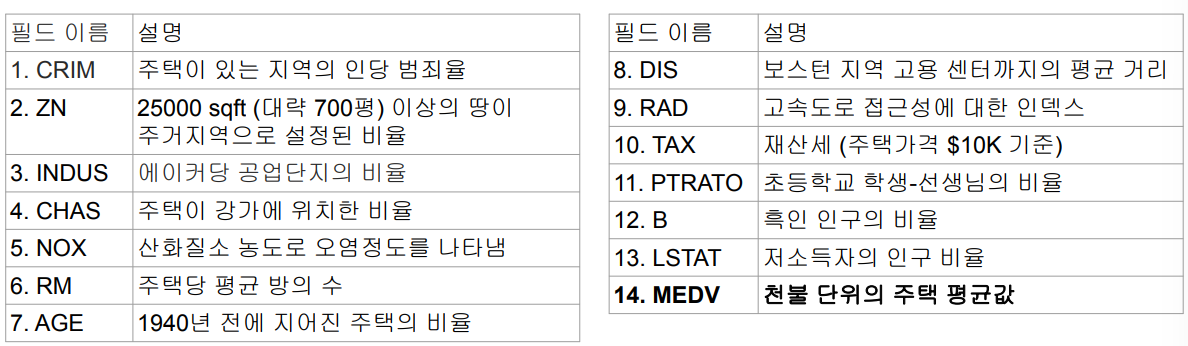
머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리ClassificationRegressionCluseteringCollaborative FilteringDimensionality Reduction아직 딥러닝은 지원이 미약함(위 사항은 다 머신러닝)여기에는 R