
CSV
CSV : 쉼표로 필드를 구분한 텍스트 파일
엑셀 양식으로 데이터셋이 주어질 때 가장 흔히 사용되는 데이터셋입니다.
ML 프로젝트 할 때 보통 Tabular 데이터를 다루는데, 가장 많이 보게될 데이터 형식이죠.
데이터들이 모두 ,로 구분 되어 있다는 것이 가장 포인트죠.
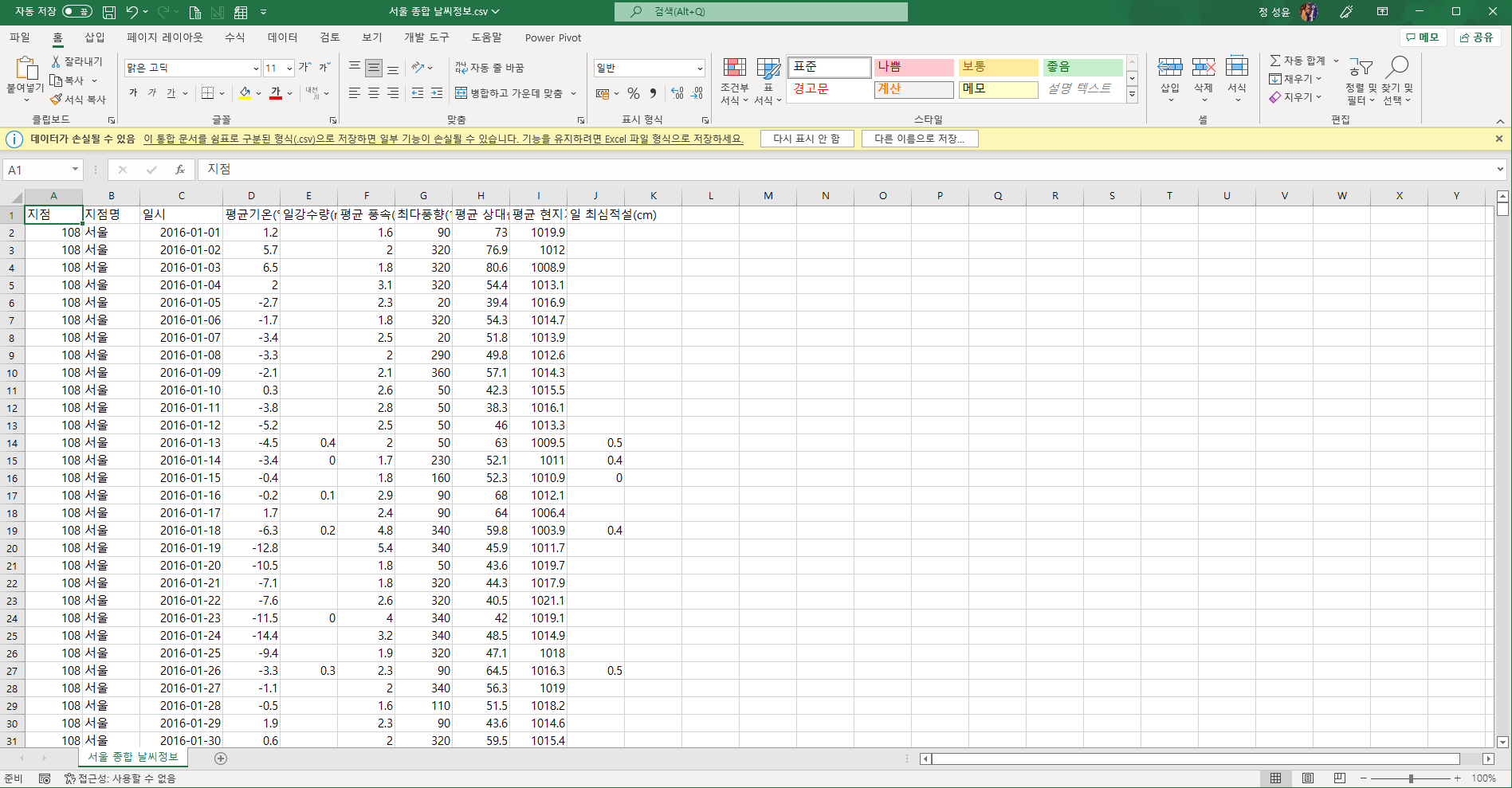
근본이 쉽표로 구분되어 있는 텍스트 파일이기 때문에 일반적으로 python 에서 제공하는 txt 파일 읽는 방법으로 해도 됩니다.

두 파일 모두 같은 데이터를 담고 있습니다. 엑셀도 쉼표로 구분되어 있는 데이터를 보기 좋게 나타낸 것에 불과합니다.
txt 파일 다루듯이 다룰 수 있다고는 하지만... "굳이"라는 말이 바로 떠오르죠?
때문에 실질적으로 csv를 다루실 때는 pandas를 통해 dataframe 형식으로 바꿔서 읽어오실 겁니다.
import pandas as pd
df = pd.read_csv("{File Path}")
df
이런 식으로 작성해주시면 csv 파일을 간단하게 읽고 다루실 수 있습니다.
HTML
우리가 지금도 사용하고 있는 웹을 구성하는 뼈대와 같습니다. 프레임이죠!
지금 보고 계신 사이트에서 F12를 누르시면 개발자 도구라고 프론트엔드 하시는 분들은 익숙하실 법한 코드들이 쫙 뜨는데, 그것의 뼈대라고 생각하시면 됩니다.
아니 나는 AI 하러 왔는데 왜 웹 구조를 알고 있어야함?
우리가 데이터를 가져오는 곳이 웹이기 때문이죠. 크롤링을 할 때 컴퓨터한테
"야 네이버 들어가서 버스 검색한 다음에 버스 이미지 싹 다 긁어와!" 라고 시켜야 하는데
컴퓨터는 우리의 언어를 이해할 수 없으니(NLU의 빠른 발전을 기원합니다...)
하나하나 명령해줘야 합니다.
슈퍼에서 과자 사오라는 심부름을 시킬 때 아이한테
"집을 나가서 10걸음 걸어서 오른쪽으로 꺾어서~~~ 카드는 뭘 내밀고 어디에 넣어서 ~~ 다시 돌아와"
이런 식으로 명령 해줘야합니다.
이제 왜 웹의 구조를 알아야하는지 아셨죠?
<!doctype html>
<html>
<head>
<title>{TITLE}</title>
</head>
<body>
<p>{Contents}</p>
</body>
</html>보통 아주 크게는 이런 식으로 구성되어 있습니다.
물론 안에는 attributes, css 와 같은 구성요소도 알아야 웹의 요소를 제대로 긁어올 수 있지만
그러면 짤막 시간이 아니라 크롤링 시간이 돼야겠죠?
HTML은 웹의 뼈대 라고 생각하고 넘어가도 될 거 같습니다.
XML
eXtensible Markup Language 의 약자입니다.
딥러닝을 하다보면 Object Detection Task를 하게 되시는데, 이때 Label 파일이 XML 아니면 json, yaml 중에 하나로 되어있습니다.
그 중 XML은 컴퓨터간에 정보를 주고 받기에 매우 유용한 저장 방식으로 평가 받고 있죠.
근데 그 형태를 보시면 HTML과 매우 유사하단 것을 확인할 수 있습니다.
<?xml version = {version}?>
<고양이>
<이름>뿡뿡이</이름>
<나이>100</나이>
</고양이>이런식으로 각 정보가 태그로서 구분되고 있죠.
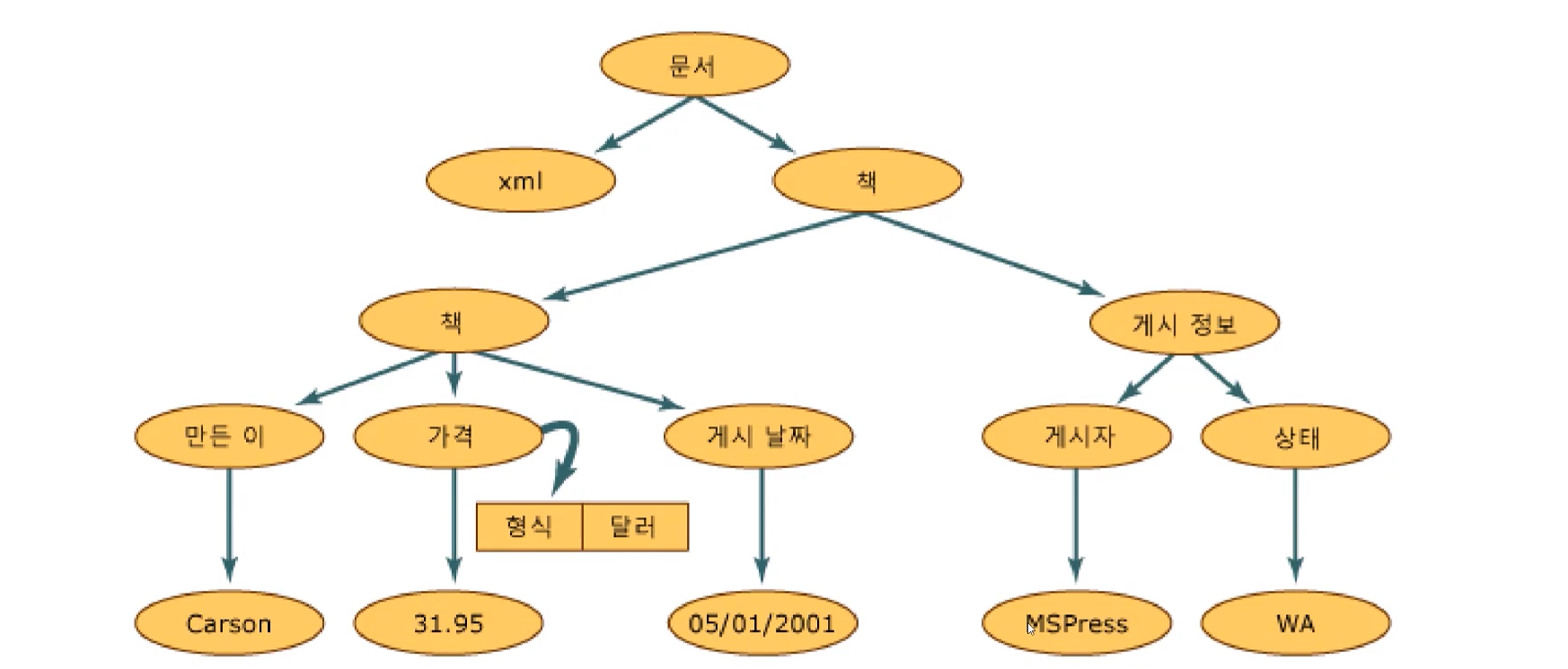
그려보면 이런 식으로 되어있는 구조임을 확인할 수 있습니다.
이런 식으로 되어있는 자료들을 쉽게 가져오기 위해 정적 사이트인 경우엔 Beautifulsoup을 이용해서 가져오게 됩니다. 하지만 이거까지 말하게 되면.. 크롤링 포스팅이 될 수 있기 때문에 패스~
JSON
JavaScript Object Notation의 약자입니다.
이름에서도 알 수 있듯 JS에서 사용하는 데이터 객체 표현 방식이죠
아주 이해하기 쉽고, 같은 정보를 담고 있어도 용량이 적다는 것이 매우 큰 장점입니다!
때문에 많은 정보를 담아야 하는 Label 파일 같은 경우엔 json으로 되어 있는 경우가 많습니다ㅎㅎ
예시로 제가 실제로 프로젝트에 사용하던 json 파일 하나를 보여드리겠습니다.
{
"version": "4.5.6",
"flags": {},
"shapes": [
{
"label": "Zebra_Cross",
"points": [
[
252.7777777777778,
739.7222222222223
],
[
1920.0,
1080.0
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
},
{
"label": "R_Signal",
"points": [
[
1720.9549071618037,
486.2068965517241
],
[
1757.6322801827232,
564.8085071434278
]
],
"group_id": null,
"shape_type": "rectangle",
"flags": {}
}
],
"imagePath": "MP_KSC_000003.jpg",
"imageData": null,
"imageHeight": 1080,
"imageWidth": 1920
}어...? 이거,,,,?
네 맞습니다. 파이썬의 가장 기본적인 자료유형인 dictionary와 매우 유사하죠!!
위의 예시에선 class에 해당하는 BBox의 정보를 표시하기 위해 json으로 저장한 모습입니다.
dict와 비슷하게 Key : value 로 데이터를 표시합니다. 데이터를 추출할 때도
json['{key}'] = value 로 수정하거나 추출할 수 있기 때문에 굉장히 편하게 다룰 수 있습니다.
JSON과 비슷한 유형으로 yaml 이라는 파일 형식이 있는데 둘이 굉장히 유사합니다.
yaml도 dict : key 형식으로 되어있기 때문에 비슷하게 사용합니다.
이제 괜히 처음 보는 데이터 파일에 쫄 필요 없겠죠?
