
numpy는 데이터를 다룰 때 절대 빼먹을 수 없는 라이브러리 입니다.
데이터는 흔히 2차원의 행렬로 나타낼 수 있습니다.
Tabular 데이터인 경우도 row와 column 형태의 2차원 행렬로 나타낼 수 있고(물론 인코딩을 시킨 후의 형태입니다.)
비정형 데이터인 경우에도 결국 행렬로 표현이 가능하죠. 이미지 같은 경우는 각 픽셀의 값을 행렬로서 모델에 input으로 넣습니다.
이토록 행렬이 많이 사용되는 데이터분야에서 행렬의 계산들을 하나하나 구현하기에는 너무나도 귀찮습니다. 그래서 나온 것이 numpy 입니다.
List
솔직히 생겨먹은 건 list나 numpy의 array나 똑같이 생겼습니다.
둘 다 대괄호([])로 묶여있고 이 대괄호를 겹쳐서 표현하면 그걸 행렬이라고 하니까요.
근데 왜 파이썬에서 기본적으로 제공해주는 list를 쓰지 않고 numpy를 쓰느냐?가 바로 오늘 포스팅의 주제입니다.
그 차이를 알려면 list가 어떤 방식으로 작동하는지 알아야겠죠?
먼저 list는 메모리 효율적이지 못합니다.
Sequence가 들어올 때 동적 할당을 하기도 하고 메모리에 Sequcne를 할당할 때 그대로 메모리에 가져다가 두는 것이 아닌 "주소"를 할당합니다.
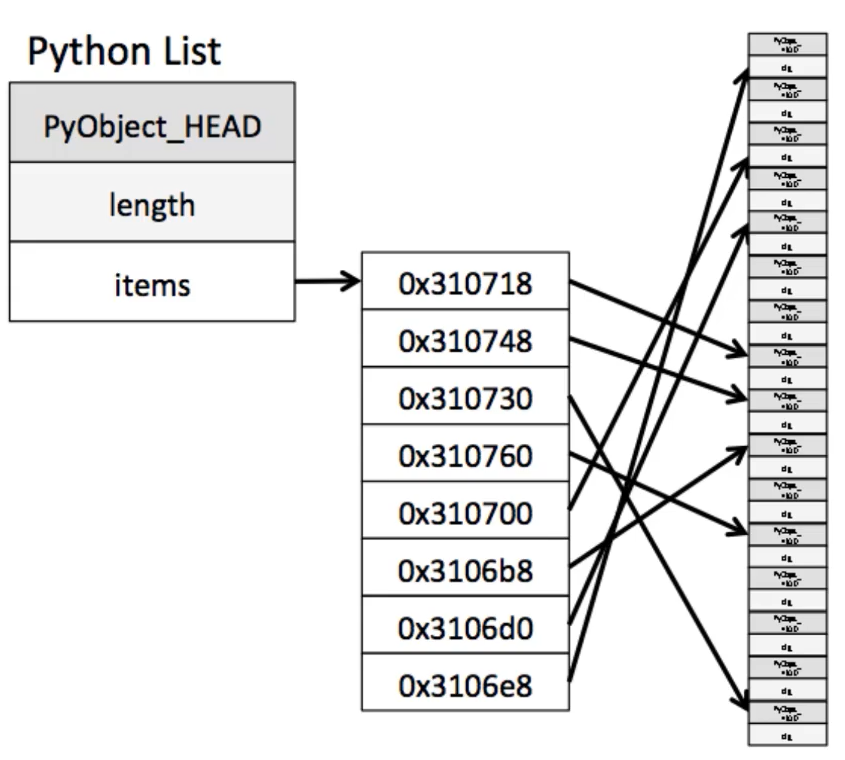
우리가 직관적으로 상상했던 것과는 달리, 차례대로 메모리에 넣는 것이 아니라 어느 공간에 할당을 하게 되고, 메모리에 어디 있는지 나타내주는 "주소"를 담게 됩니다.
이제 그럼 리스트에서 한 값을 뽑아오려면
"주소가 이거니까... 여깄네...!" 하고 뽑아오는 겁니다. 도서관에서 책 하나하나를 찾아서 뽑아오는 것과 같죠.
이렇게 설계한 이유는 다양한 데이터타입을 허용하기 때문입니다.
때문에 조금 느리지만 여러 데이터타입을 한 list 안에 넣을 수가 있게 되고, 변형도 쉽다는 특징이 있죠.
Numpy

list에서는 한 배열 안에 여러가지 데이터 타입을 넣을 수 있었습니다.
lst = [1,2,0.5,0.4,'Code','list']이런 식으로 넣어도 문제 없이 lst 객체에 Sequence를 할당할 수 있죠.
그러나 Numpy는 한 가지 데이터 타입만을 허용합니다.
int만 있거나 float만 있거나 str만 있거나 해야한다는 겁니다.
바로 이 점에서 꽤나 큰 차이를 만들어냅니다.
동일한 데이터타입을 저장하면 굳이 메모리 주소를 할당할 필요가 없습니다.
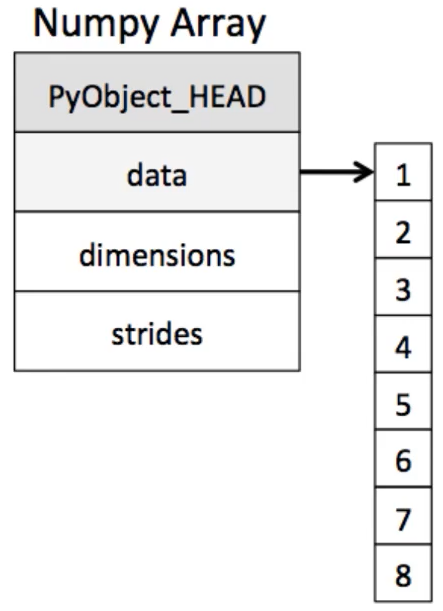
그냥 들어온 그대로 메모리에 할당시켜버리면 끝!
아까 list는 도서관에서 이 책좀 꺼내주세요~ 하면 아 네~ 하고 주소 보고 아 여깄넹 하고 가져오는 거라면
numpy의 array는 바로 그냥 읏-차 하고 주루룩 줄 수 있는 겁니다.
때문에 일단 넘파이는 데이터 접근성 면에서 속도적 우위를 가집니다.
또한 메모리를 사용하는 공간이 일정하기 때문에 찾기도 쉽죠.
메모리를 사용하는 특징 때문에 numpy가 좀 더 빠른 것이고, RAM만 여유롭다면 훨씬 시원시원하게 사용가능한 겁니다.
이제 왜 numpy를 쓰는지 알겠죠?
