Kafka
- 분산 이벤트 스트리밍 플랫폼
기본구조

1). 카프카 클러스터
- 카프카 클러스터는 여러개의 브로커로 이루어져 있다
- 브로커는 각각의 서버라고 보면 된다
- 브로커들이 메시지들을 나눠서 저장하고 이중화처리도 하고 장애가 발생하면 대처도 한다
- 카프카 클러스터를 관리하는 용도로 주키퍼가 필요하다
- 주키퍼 안에 카프카 클러스터와 관련된 정보가 들어가게 되고 관리된다
- 데이터 이동에 필요한 핵심 역할을 맡는다
(1). 프로듀서
- 카프카 클러스터에 메시지를 보내는 것을 프로듀서라고 한다
(2). 컨슈머
- 메시지를 카프카에서 읽어오는 역할을 한다
2). 토픽과 파티션
- 토픽은 메시지를 구분하는 단위: 폴더와 비슷하다
- 여러 메시지가 있을 때 어떠한 종류인지 구분할 필요가 있는데 그런 용도이다
- 한 개의 토픽은 한 개이상의 파티션이 있다
- 파티션은 메시지를 저장하는 물리적인 파일이다
- 프로듀서는 메시지를 저장할 때
어떤 토픽에 저장해줘라는 요청을 한다- 컨슈머는
어떤 토픽에서 메시지를 읽어올래라는 요청을 한다- 파티션은 추가만 가능한 파일이고 저장 위치를 알 수 있어서 순서대로 읽는다
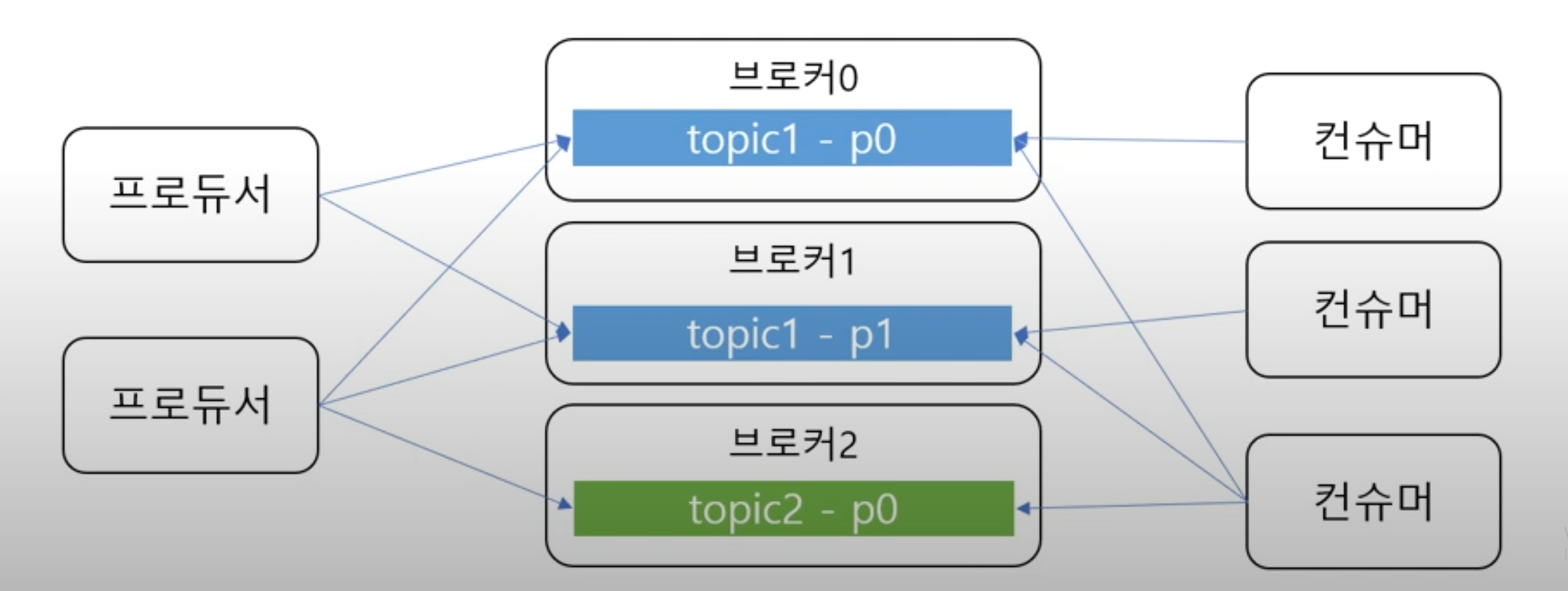
(1). 토픽이 여러 파티션으로 구성될 수 있는데 프로듀서는 어떤 파티션에 메시지를 저장하냐
라운드 로빈으로 돌아가면서 저장을 하거나
프로듀서는 카프카에 메시지를 전송할 때 토픽의 이름뿐만 아니라 키도 지정할 수 있다
같은 키를 갖는 메시지는 같은 파티션에 저장이 된다
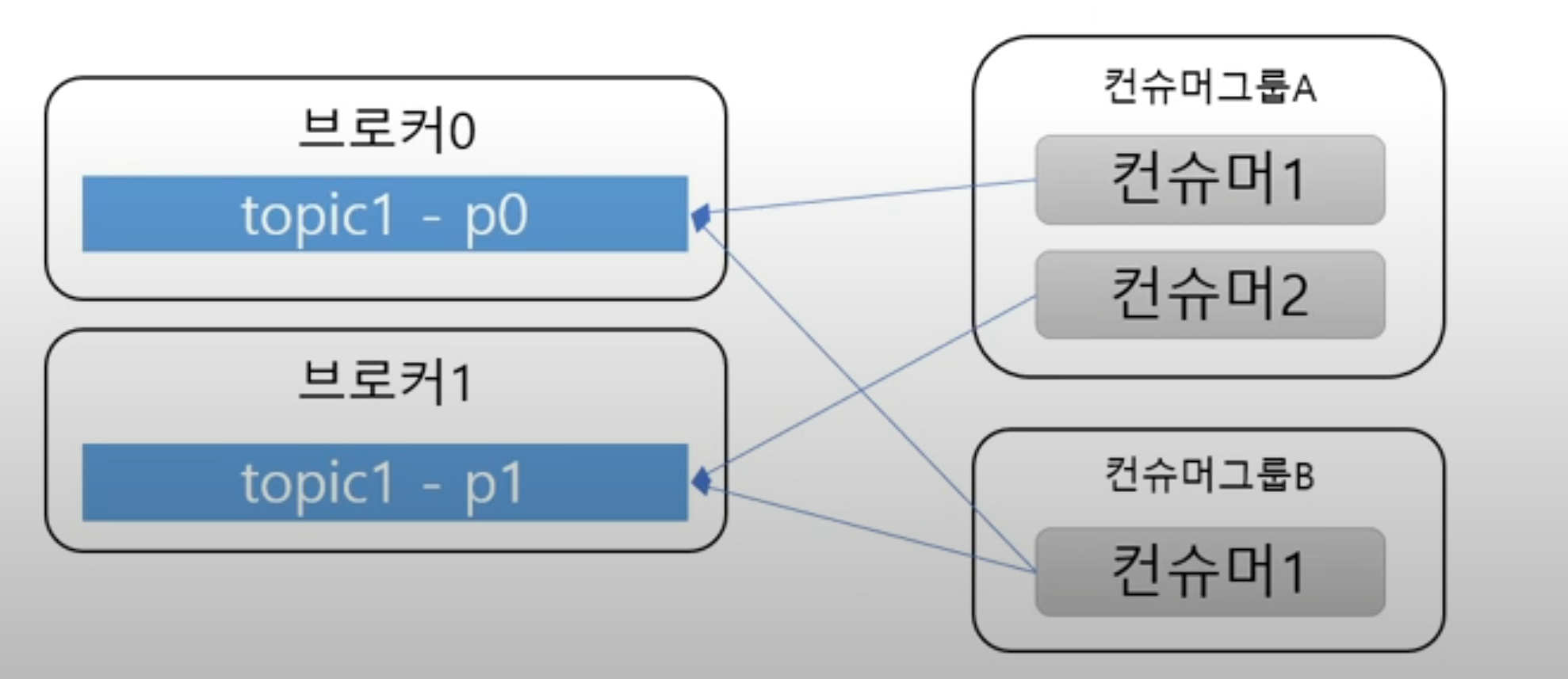
(2). 컨슈머 그룹
- 브로커에 연결할 때 어떤 컨슈머그룹에 속할지 지정을 해야한다
- 컨슈머는 컨슈머 그룹에 속하게 되는데
- 한 개의 파티션은 컨슈머그룹의 한 개만 컨슈머만 연결이 가능하다
- 즉 컨슈머그룹에 속한 컨슈머들을 한 파티션을 공유할 수 없다
- 그래서 한 커슈머그룹 기준으로 파티션 메시지는 순서대로 처리가 가능해진다
3). 브로커, 복제, ISR(In-Sync-Replication)
- 브로커는 카프카가 설치되어 있는 서버 단위를 말한다
- 보통 3개 이상의 브로커를 구성하여 사용하는 것을 권장한다
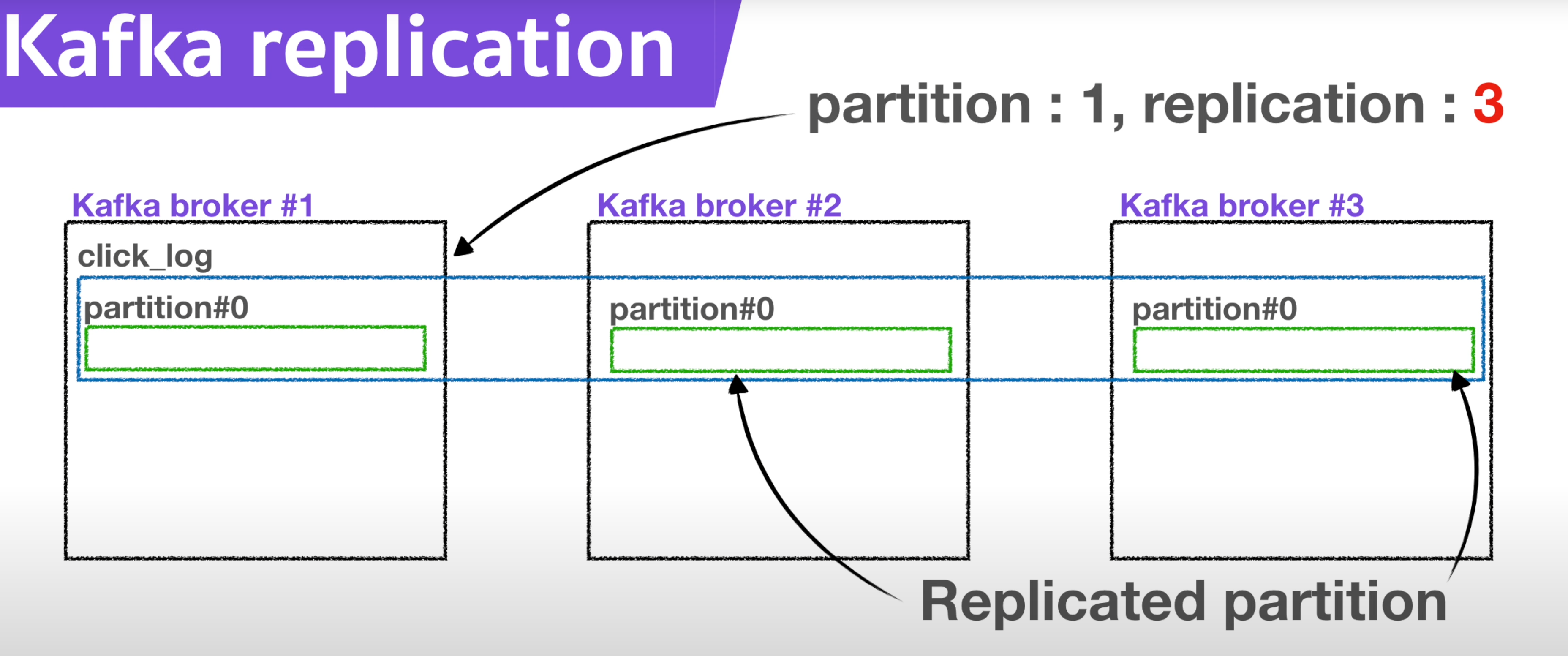
- 파티션이 1개이고 리플리카가 1인 토픽이 존재한다면 3대의 브로커중 1대의 브로커에만 저장된다
- 브로커의 개수에 따라 리플리카의 최대 개수도 정해진다. 브로커가 3대라면 리프리카 최대 개수도 3
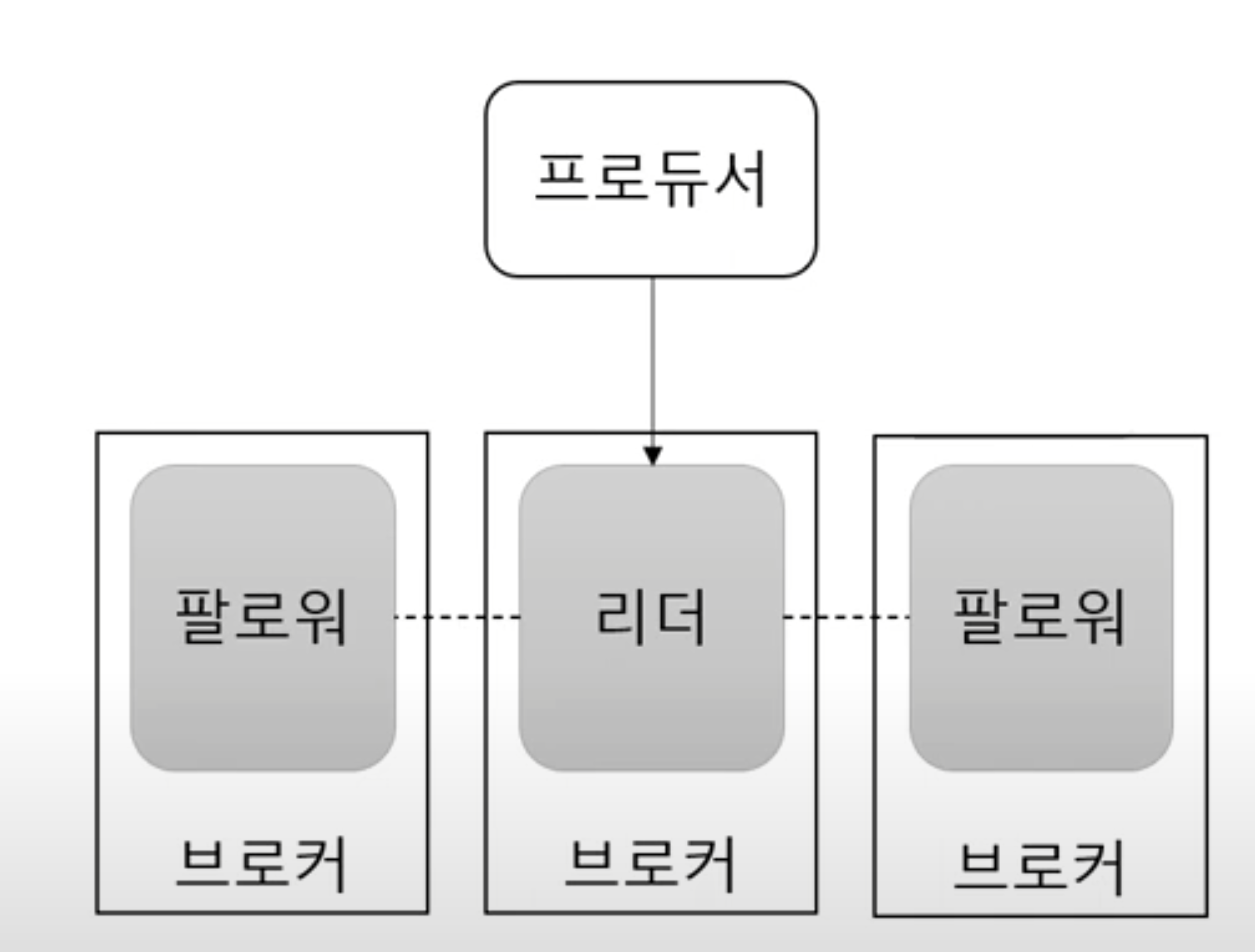
- 리더와 팔로워 전부를 부르는 명칭은 ISR이다
성능
파티션 파일은 OS 페이지캐시 사용
- 파티션에 대한 파일 IO를 메모리에서 처리한다
- 단 서버에서 페이지캐시를 카프카만 사용해야 성능에 유리하다
Zero Copy
- 디스크 버퍼에서 네트워크 버퍼로 직접 데이터 복사한다
컨슈머 추적을 위해 브로커가 하는 일이 비교적 단순
- 메시지 필터, 메시지 재전송과 같은 일을 브로커가 하지 않는다 (프로듀서, 컨슈머가 직접 해야함)
- 브로커는 컨슈머와 파티션 간 매핑을 관리하는 역할
묶어서 보내고 묶어서 받는 게 가능하다 (batch)
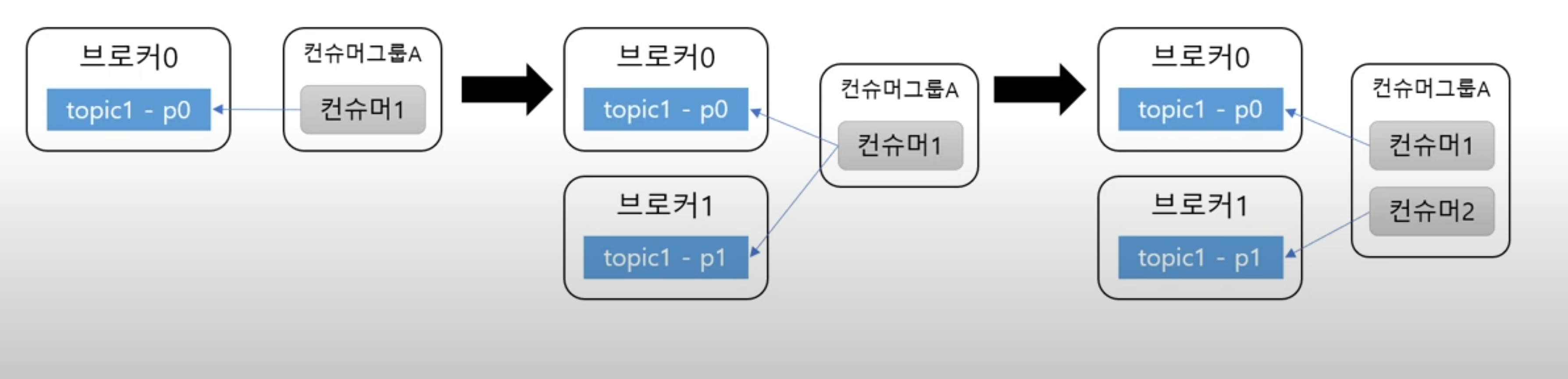
처리량 증대(확장)가 쉽다
- 용량의 한계가 온다면 브로커를 추가하고 파티션을 추가하면 된다
- 컨슈머가 느리다면 컨슈머 추가와 파티션을 추가하면 된다
장애 발생시
카프카는 장애발생 시 복구를 위해 리플리카를 사용한다
- 리플리카: 파티션의 복제본 -> 복제수만큼 파티션의 복제본이 각 브로커에 생긴다
리더와 팔로워로 구성되어 있어 장애에 대응한다
- 프로듀서와 컨슈머는 리더를 통해서만 메시지를 처리한다
- 팔로워는 리더로부터 복제하고 리더 브로커 장애 시 다른 팔로워가 리더가 된다
프로듀서 알아보기
// properties를 이용해서 producer가 사용할 속성을 지정해준다
// 설정 정보이다
// 브로커 목록이나 키나 밸류를 직렬화, ack, batchSize를 지정한다
Properties prop = new Properties();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// 이를 토대로 kafkaProducer 메서드를 제공한다
KafkaProducer<Integer, String> producer = new KafkaProducer<>(prop);
// send 메서드에 ProducerRecord를 전달한다
// ProducerRecord가 브로커에 전달할 메시지가 된다
// ProducerRecord는 2가지 방법으로 전달할 수 있다
// 1. 토픽이름과 키 밸류로 전달을 한다
// 2. 토픽이름과 밸류만 사용한다
producer.send(new ProducerRecord<>("topicname", 1,"value"));
producer.send(new ProducerRecord<>("topicname", "value"));
// 다 사용했다면 닫아준다
producer.close();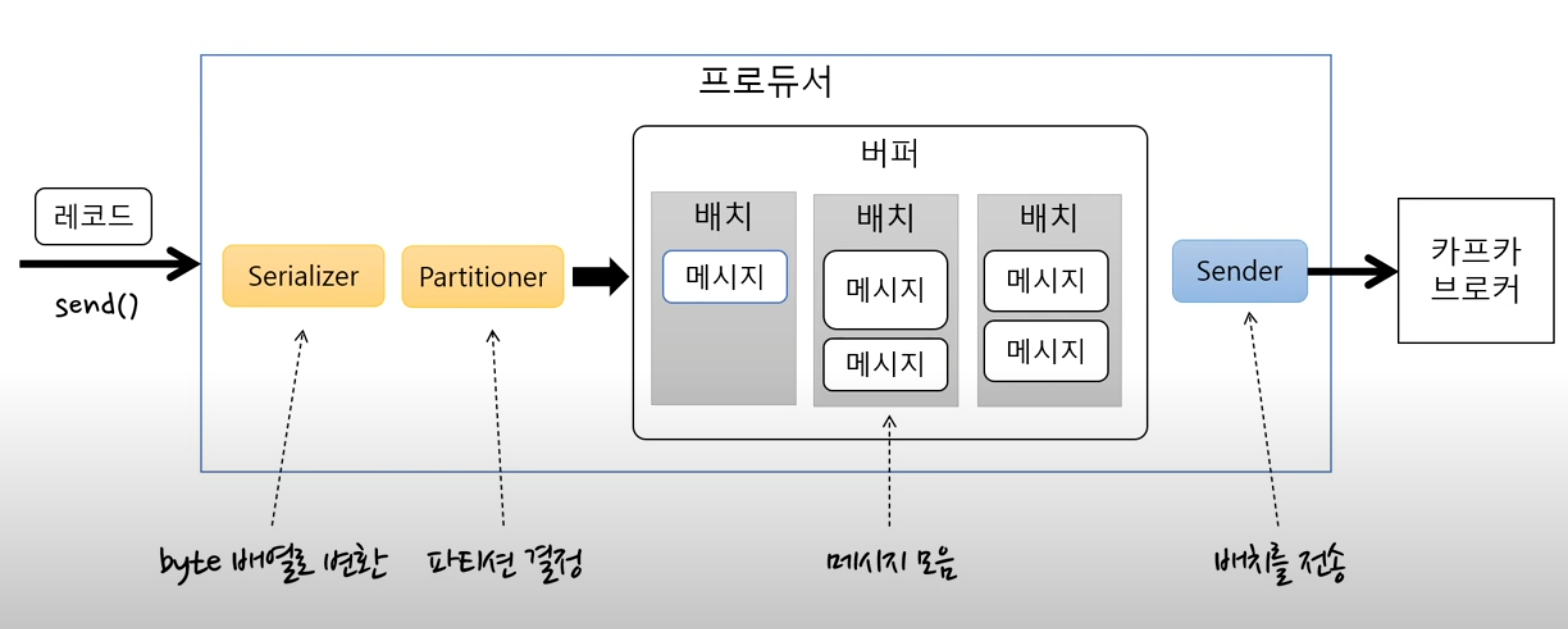
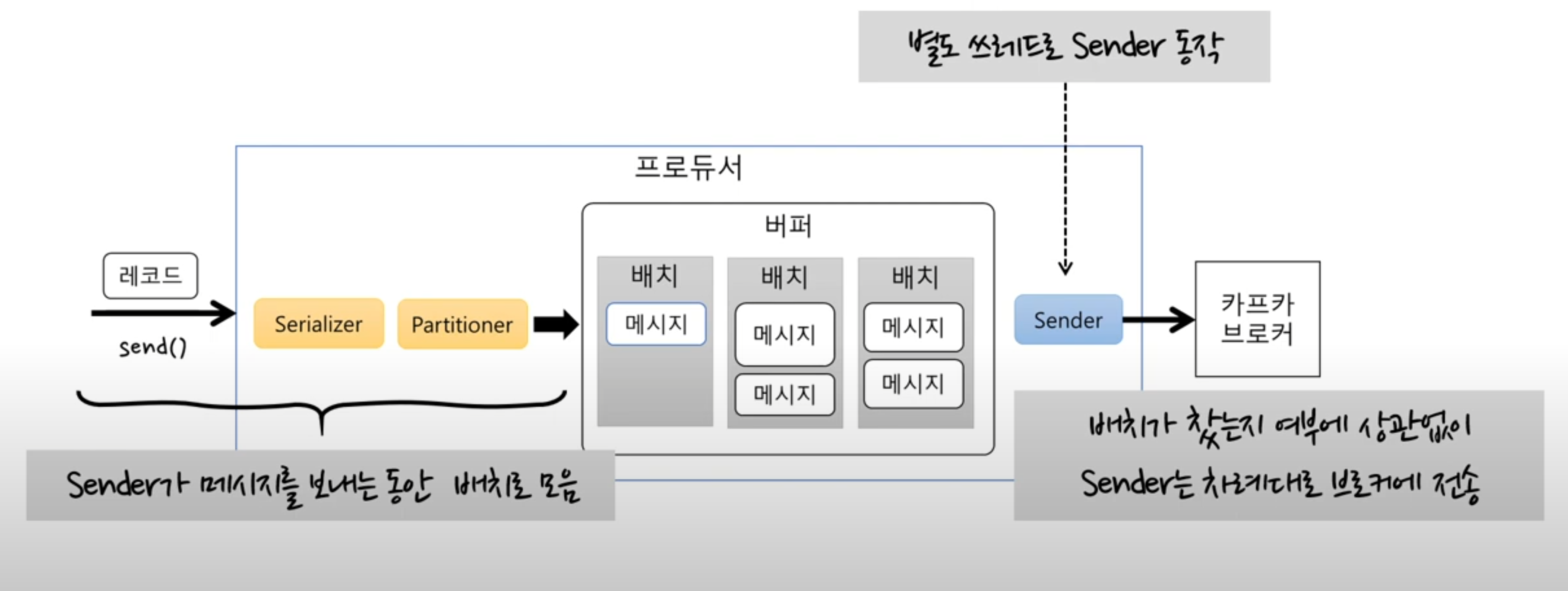
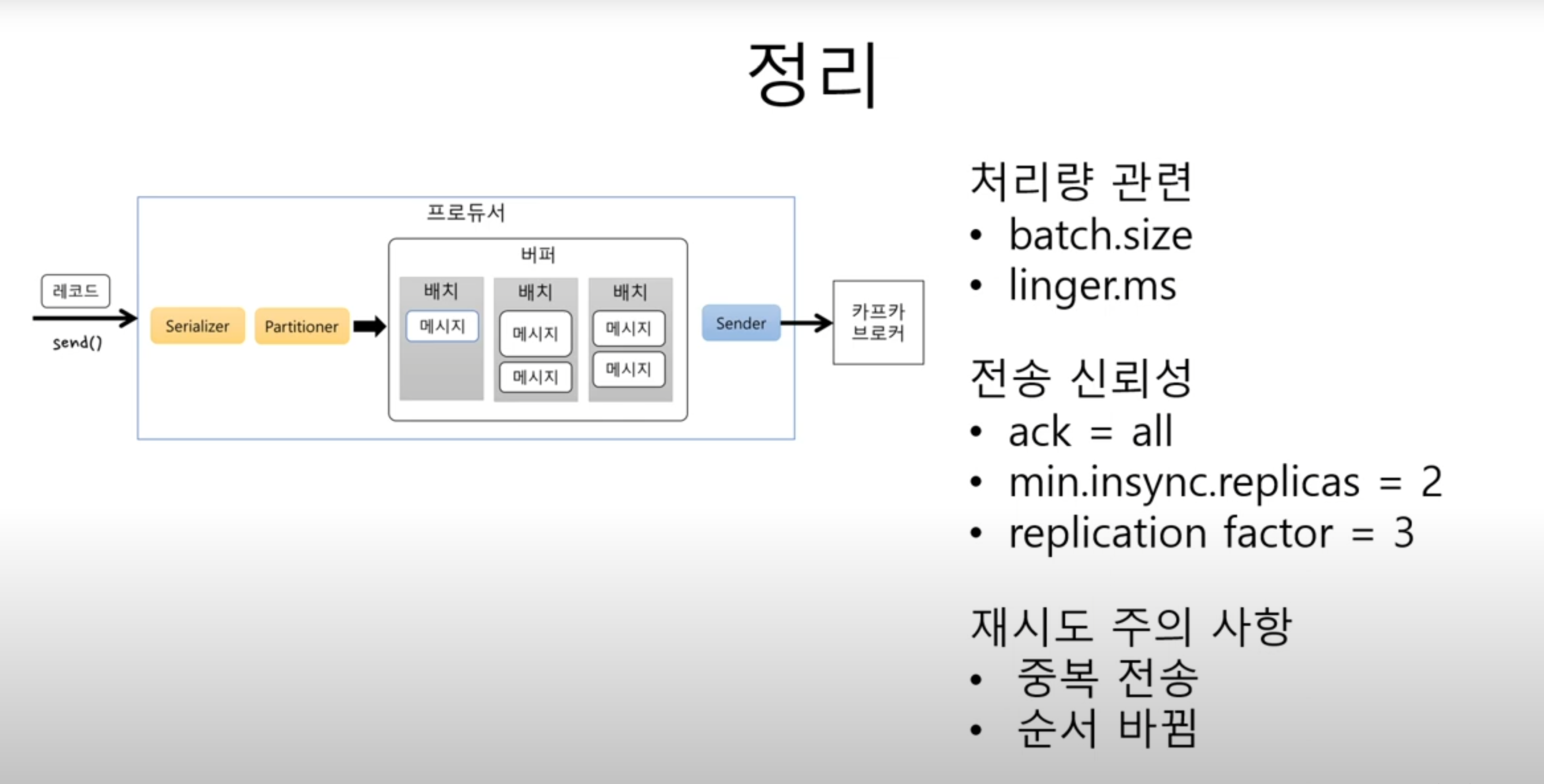
구체적으로 말하면
- send로 보내면 직렬화를 통해 byte 배열로 변환을 한다 -> 어떤 토픽의 파티션으로 보낼지 지정
- 변환된 바이트배열을 버퍼에 저장한다
- 바로 저장하는 게 아니라 배치로 모은다
- sender는 sender대로 배치에서 메시지를 꺼내고 계속 보내고
- send메서드는 send대로 배치에 계속 누적해서 메시지를 쌓는다
- 두 개가 서로 다른 쓰레드로 동작하기 때문에 성능상으로 좋다
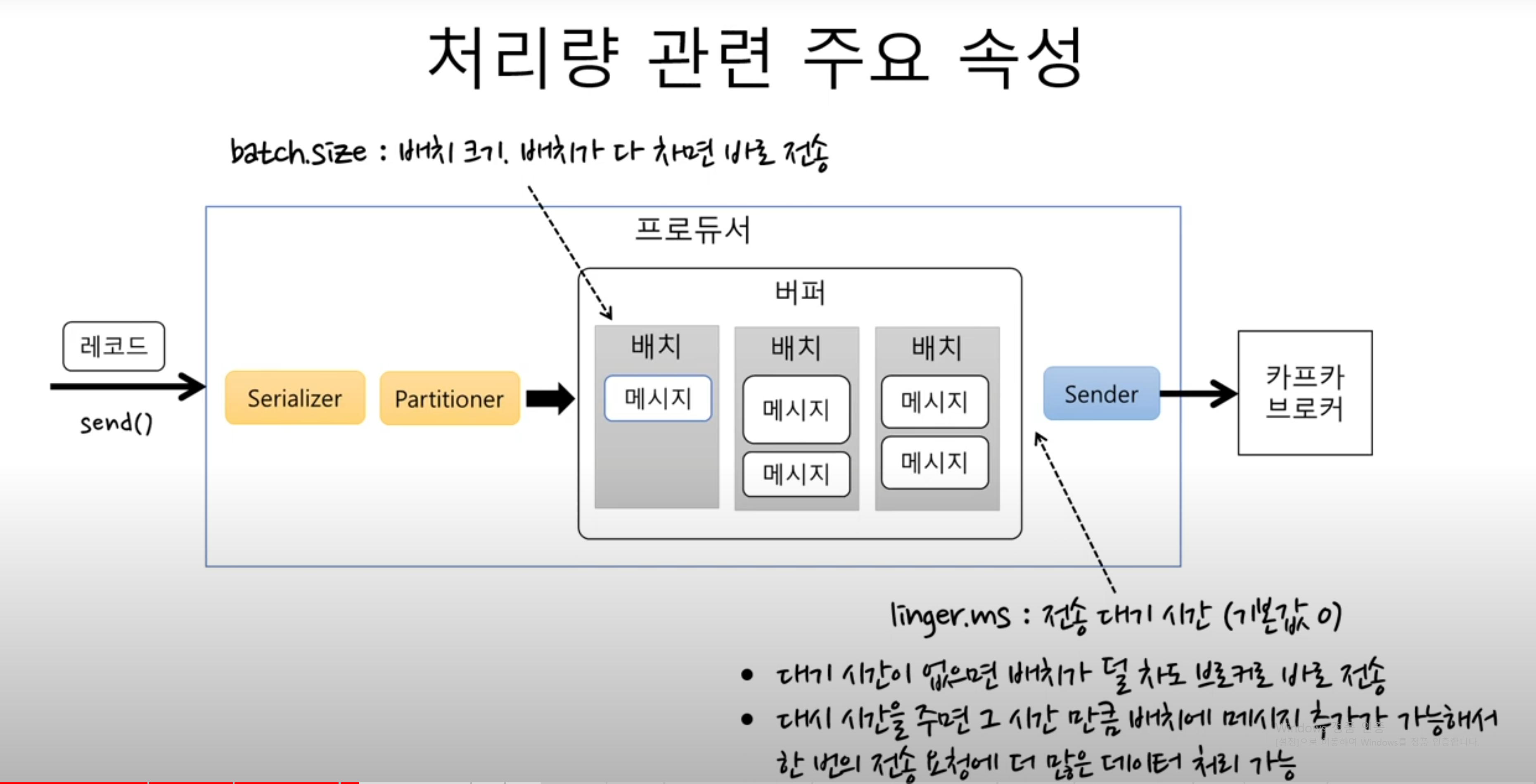
처리량 주요 속성
- 배치의 크기를 지정해서 배치가 다 차면 바로 전송한다
- 배치사이즈가 너무 작으면 전송횟수가 많아지기 때문에 처리량이 떨어지게 된다
- linger.ms : 전송 대기시간 (기본값 0)
- 대기시간을 주면 그 시간만큼 기다렸다 배치를 전송한다
전송 확인
producer.send(new ProducerRecord<>("topicname", "value"));는 전송 실패했는지 알 수 없다
전송 실패했는지 알기 위해서는 Future를 사용하면 된다
- 배치 효과가 떨어지기 때문에 처리량 저하, 처리량이 낮아도 되는 경우에만 사용
- 하나 보내고 알아내고 하나 보내고 알아내고 하기 때문에 배치에 1개씩만 쌓이게 된다
Future<RecordMetadata> future = producer.send(new ProducerRecord<>("topicname", "value"));
try{
RecordMetadata metadata = future.get(); // 블로킹
} catch (ExecutionException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}또 다른 방법은 Callback을 사용하면 된다
- Exception이 날라오면 처리에 실패했다는 뜻이니까 재시도 로직이나 다양한 처리를 할 수 있다
- 이 방식은 블로킹이 아니기때문에 배치에 데이터가 계속 쌓일 수 있다
- 즉 처리량 저하가 없다
producer.send(new ProducerRecord<>("simple", "value"),
new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
}
});프로듀서는 전송 보장을 위해서 ack를 사용한다
- ack = 0이면 성공 실패 서버응답을 기다리지 않는다
- 전송 보장도 안한다
- ack = 1은 파티션의 리더에 저장되면 응답을 받는다
- 리더 장애시에는 메시지 유실 가능성이 있다
- ack = all (또는 -1)은 모든 리플리카에 저장되면 응답을 받는다
- 브로커 min.insync.replicas 설정에 따라 달라진다
- min.insync.replicas(브로커 옵션)
- ack옵션이 all일때 저장에 성공했다고 응답할 수 있는 동기화된 리플리카 최소 개수
Ex): 리플리카 개수 3, ack = all, min.insync.replicas= 2
-> 리더에 저장하고 팔로워 중 한 개에 저장하고 성공 응답
에러 유형
1. 전송과정에서 실패
- 전송 타임 아웃(일시적인 네트워크 오류 등)
- 리더 다운에 의한 새 리더 선출 진행 중
- 브로커 설정 메시지 크기 한도 초과
- 등등
2. 전송 전에 실패
- 직렬화 실패, 프로듀서 자체 요청 크기 제한 초과
- 프로듀서 버퍼가 차서 기다린 시간이 최대 대기 시간 초과
- 등등
3. 실패 대응
- 재시도: 기본적으로 재시도를 한다. 다만 너무 빨리하거나 무한 재시도는 하면 안된다
- 기록: 추후 처리를 위해 어딘가에 저장을 해놓는다
- 전송했지만 ack를 늦게 보내서 또 재전송을 하는 중복 데이터 전송가능성이 있을 수 있다
-> enable.idempotence를 통해 중복 가능성을 줄이거나, 재시도 시간을 늘려야 한다
컨슈머 알아보기
// properties를 이용해서 producer가 사용할 속성을 지정해준다
// 설정 정보이다
// 브로커 목록이나 키나 밸류를 역직렬화, ack, batchSize를 지정한다
Properties prop = new Properties();
prop.put("bootstrap.servers", "localhost:9092");
prop.put("key.serializer", "org.apache.kafka.common.serialization.StringDeSerializer");
prop.put("value.serializer", "org.apache.kafka.common.serialization.StringDeSerializer");
// 위에 있는 설정을 토대로 consumer 객체를 생성
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
// 토픽 구독
consumer.subscribe(Collections.singleton("simple"));
// 특정 조건을 충족하는 동안 브로커로부터 메시지를 읽어온다
while (조건) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value() + ":" + record.topic() + "." + record.partition() + "." + record.offset());
}
}
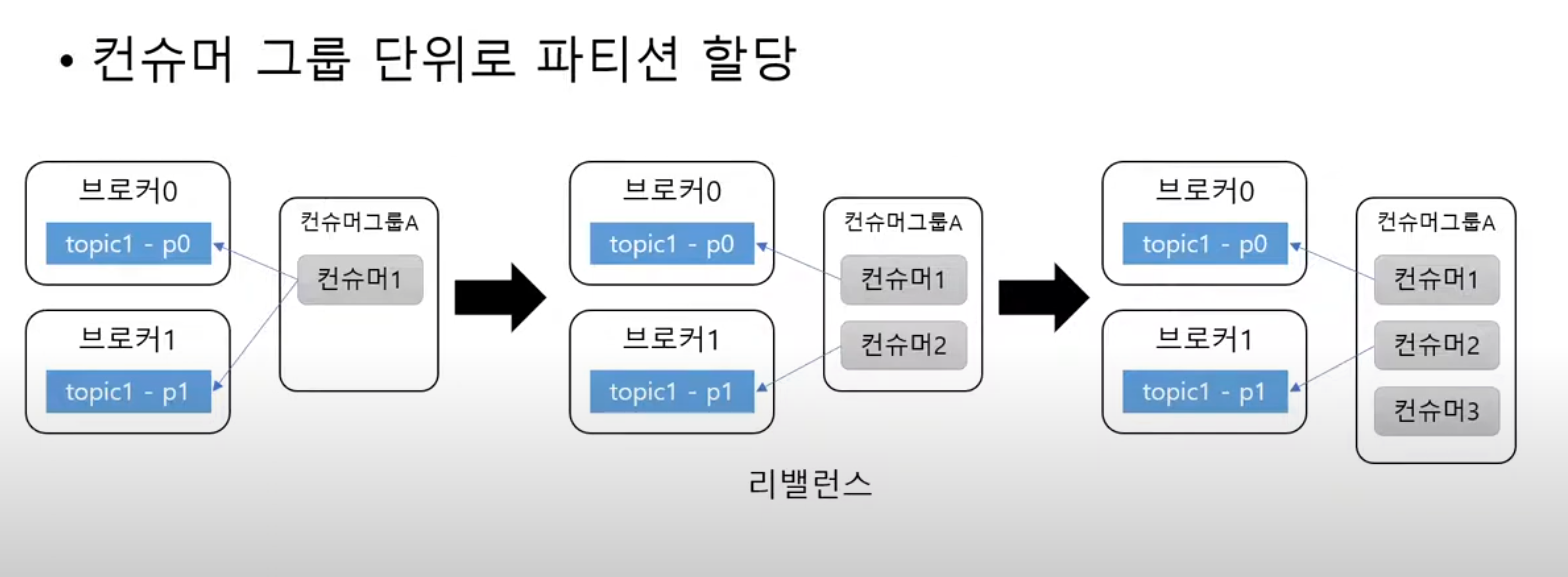
consumer.close();토픽 파티션은 그룹 단위로 할당된다
- 그룹은 앞서 지정된 그룹아이디를 통해 할당된다
- 파티션 개수과 컨슈머 그룹은 밀접한 관련이 있다
- 파티션 개수 < 컨슈머 그룹의 컨슈머 개수 이면은 컨슈머가 놀아버린다
커밋과 오프셋
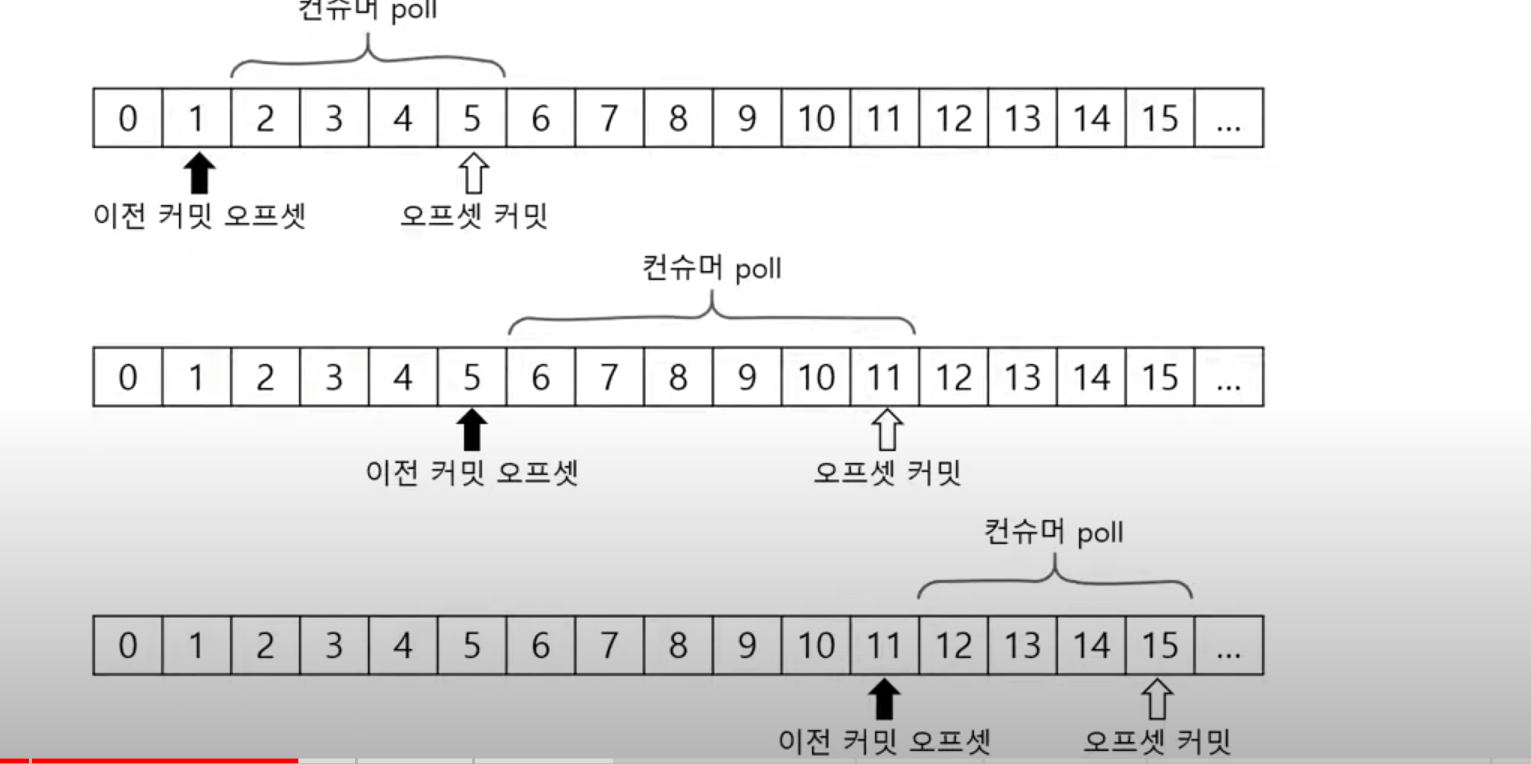
- consumer.poll()메서드는 이전에 커밋한 오프셋이 있으면 그 이후의 오프셋을 읽어온다
- 그리고 마지막 읽어온 오프셋 커밋한다
- 한 마디로 어디까지 읽었는지 확인하고 그 후에 계속 읽고 마지막에 있는 곳을 표시한다
- 책 읽을 때 책갈피랑 비슷한 개념
커밋된 오프셋이 없는경우
- 처음 접근하거나 커밋한 오프셋이 없는 경우에는 auto.offset.reset 설정을 사용한다
- earliest: 맨 처음 오프셋 사용
- latest: 가장 마지막 오프세 사용(기본값)
- non: 컨슈머 그룹에 대한 이전 커밋이 없으면 익셉션 발생
컨슈머 설정
조회에 영향을 주는 주요 설정
- fetch.min.bytes: 조회시 브로커가 전송할 최소 데이터 크기
- 기본값: 1
- poll 메서드를 사용하면 이 값 이상의 데이터가 쌓일 때까지 기다린다
- 이 값이 크면 대기 시간은 늘지만 처리량이 증가
- fetch.max.wait.ms: 데이터가 최소 크기가 될 때까지 기다릴 시간
- 기본값: 500
- 브로커가 리턴할 때까지 대기하는 시간으로 poll()메서드의 대기시간과 다름
- max.partition.fetch.bytes: 파티션당 서버가 리턴할 수 있는 최대 크기
- 기본값: 1048576 (1MB)
자동 커밋/ 수동 커밋
커밋에는 수동과 자동이 있다
- enable.auto.commit 설정
- true: 일정 주기로 컨슈머가 읽은 오프셋을 커밋
- false: 수동으로 커밋 진행
- auto.commit.interval.ms : 자동 커밋 주기
- 기본 값: 5000(5초)
- poll(), close() 메서드 호출 시 자동 커밋 실행
수동 커밋은 동기/ 비동기 커밋이 있다
재처리와 순서
- Kafka는 동일한 메시지를 조회할 수 있다
- 그래서 컨슈머는 멱등성을 고려해야 한다
- 데이터 특성에 따라 타임스탬프, 일련 번호등을 활용해서 중복처리를 고려해야 한다
세션 타임아웃, 하트비트, 최대 poll 간격
- 컨슈머는 하트비트를 전송해서 연결을 유지한다
- 브로커는 일정시간 컨슈머로부터 하트비트가 없으면 컨슈머를 그룹에서 빼고 리밸런스 진행
- 관련 설정
- session.timeout.ms: 세션 타임 아웃 시간 (기본값 10초)
- heartbeat.interval.ms: 하트비트 전송 주기 (기본값 3초)
- heartbeat의 시간은 session의 1/3 이하를 추천한다 (
- max.poll.interval.ms : poll() 메서드의 최대 호출 간격
- 이 시간이 지내도록 poll()하지 않으면 컨슈머를 그룹에서 빼고 리밸런스 진행
